1. json模块介绍
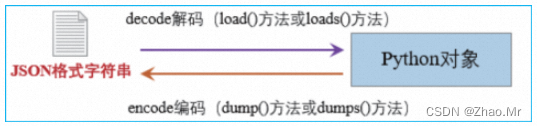
Python 中的json 模块提供了对JSON 的支持,用于将JSON 格式字符串转换为Python 对象。首先需要了解一下什么是JSON。
什么是JSON
JSON 是基于JavaScript 语言的轻量级的数据交换格式,是JavaScript 对象的表示法(JavaScriptObject Notation),它是用来存储和交换文本信息的。信息表示格式为:
-
数据在名称/ 值对中。
-
数据由逗号分隔。
-
大括号保存对象。
-
方括号保存数组。
例如,下面的格式:
{
“login”: [
{“password”: “123456”,”username”: “高猿元"},
{“password”: “123”,”username”: “明日科技"},
{“password”: “111”,”username”: “mrsoft”},
]
}
上述代码中的"username": " 高猿元" 和"password": “123456” 等叫作JSON 对象,它们一般放在大括号{} 中;“login”为JSON 数组,用方括号[] 表示。
json 模块
Python 中的json 模块提供了对JSON 的支持,它既包含了将JSON 格式字符串转换为Python 对象的方法,也提供了将Python 对象转换为JSON 格式字符串的方法
2. dump()方法——转换为JSON格式写入文件
dump() 方法用于将Python 对象转换为JSON 格式字符串后写入到文件中。语法格式如下:
json.dump(obj, fp, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True,cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)
参数说明:
-
obj :表示Python 对象。
-
fp :表示一个支持write() 方法的文件对象。
-
:星号本身不是参数。星号表示其后面的参数都是关键字参数,需要使用关键字参数传值,否则程序会出现错误。
-
skipkeys:默认值为False。如果值为True,则不是基本对象(包括str、int、float、bool、None)的字典的键会被跳过;否则引发一个TypeError 错误信息。
-
ensure_ascii:默认值为True,会将所有输入的非ASCII 字符转义输出;如果值为False,会将输入的非ASCII 字符原样输出。
-
check_circular:表示检验循环引用,默认值为True。如果值为False,则容器类型的循环引用会被跳过并引发一个OverflowError 错误。
-
allow_nan:默认值为True。如果值为False,那么在对JSON 规范以外的float 类型值(nan、inf 和-inf)进行序列化时将会引发一个ValueError 错误;如果值为True,则使用它们的JavaScript 等价形式(NaN、Infinity 和-Infinity)。
-
cls:默认值为None。通过该关键字参数可以指定自定义的JSONEncoder 的子类。
-
indent:默认值为None。选择最紧凑的表达。如果indent 是一个非负整数或者字符串,那么JSON 数组元素和对象成员会被美化输出为该值指定的缩进等级。如果缩进等级为零、负数或者””,则只会添加换行符。当indent 为一个正整数时会让每一层缩进同样数量的空格;如果indent 是一个字符串如换行符、制表符(‘\n’、‘\t’)等,那么这个字符串会被用于每一层。
-
separators:默认值为None。该参数是一个元组,即(‘,’, ‘: ‘),其中包含空白字符。如果想要得到最紧凑的JSON 表达式,应指定该参数为(’,’,‘:’),不要空白字符。
-
default:默认值为None。如果要指定该参数,则该参数应是一个函数。每当某个对象无法被序列化时,它就会被调用。它返回该对象的一个可以被JSON 编码的版本或者引发一个TypeError(传入参数的类型错误)。如果不指定该参数,则会直接引发TypeError。
-
sort_keys:默认值为False。如果值为True,那么字典的输出会以键的顺序排序。
-
**kw:其他关键字参数,用于字典。
-
返回值:返回JSON 格式字符串。
说明:在方法中,如果出现“*”,则表示其后面的参数为命名关键字参数,这是一个特殊的分隔符。在调用时,命名关键字参数必须传入参数名。
定义JSON 格式字符串,然后使用dump() 方法将其写入json 文件,代码如下:
import json
data1 = [{ 'a':'MR-SOFT', 'b':(8, 88), 'c':8.8 ,'d':33}]
with open('aa.json', 'w') as f:
json.dump(data1, f,allow_nan=False,sort_keys=True, indent=4)
注意:命名Python 工程文件时,千万不要使用Python 保留的标识符以免发生命名冲突。例如,不能将Python 工程文件命名为json.py,因为它与Python 系统模块json 命名冲突。
当JSON格式字符串中出现中文时,使用dump()方法会将ASCII码写入到文件中
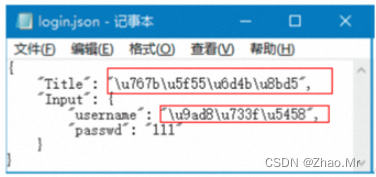
此时,需要将参数ensure_ascii 的值设置为False,代码如下:
import json
data1 = {
“Title”: “登录测试",
“Input”: {
“username”: “高猿员",
“passwd”: “111”
}
}
with open(‘login.json’, ‘w’) as f:
json.dump(data1, f, indent=4,ensure_ascii=False)
如果想将本地文件的数据存入MongoDB 数据库中,该本地文件数据格式必须是.csv 或者.json格式。将.csv 格式文件存入MongoDB 数据库时,列元素之间的顺序会错开,因此需要将.csv 格式文件转换为.json 格式再存入MongoDB 数据库。下面使用dump() 方法将.csv 格式转换为.json 格式,代码如下:
import csv
import json
# 读取csv文件
csvf=open(‘./tmp/mr2.csv’,’r’)
reader=csv.DictReader(csvf)
# 转换为json文件
with open(‘./tmp/mr2.json’,’w’) as f:
for r in reader:
data=json.dump(r,f,ensure_ascii=False,indent=4)
f.write(r’\n’)
修改json 文件的主要思路是:先读取json 文件中的数据,将数据暂存起来,然后再将修改后的数据写入json 文件,代码如下:
import json
with open(‘./tmp/book1.json’,’r’) as f1:
mydict=json.load(f1)
mydict[‘01’]=’零基础学Python’
with open(‘./tmp/book1.json’,’w’) as f2:
json.dump(mydict,f2,ensure_ascii=False)
3. dumps()方法——将Python对象转换为JSON字符串
dumps() 方法用于将Python 对象转换为JSON 格式的字符串。语法格式如下:json.dumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)dumps() 方法的参数与dump() 方法的参数使用方法相同,这里不再赘述。
通过设置dumps() 方法的indent 参数对JSON 格式的字符串内容进行缩进显示,代码如下:
import json
data1 = [{ ‘a’:’MR-SOFT’, ‘b’:(8, 88), ‘c’:8.8 ,’d’:33}]
print(‘正常:',json.dumps(data1,allow_nan=False,sort_keys=True))
print(‘缩进显示:',json.dumps(data1, allow_nan=False, sort_keys=True, indent=2))
程序运行结果如下:
正常: [{"a": "MR-SOFT", "b": [8, 88], "c": 8.8, "d": 33}]
缩进显示: [
{
"a": "MR-SOFT",
"b": [
8,
88
],
"c": 8.8,
"d": 33
}
]
dumps() 方法中separators 参数的作用是去掉“:”“,”后面的空格,从下面的输出结果能看到“:”“,”后面都有个空格,这是为了美化输出结果。但是在传输数据的过程中,越精简越好,冗余的东西全部去掉可以提高程序运行效率。因此可以通过设置separators 参数去掉空格,代码如下:
import json
data = [ { ‘a’:’A’, ‘b’:(2, 4), ‘c’:3.0 } ]
print(‘原数据:’, data)
print(‘转换为JSON格式字符串:’, json.dumps(data))
print(‘转换为JSON格式字符串的长度:’, len(json.dumps(data)))
print(‘去掉空格后的长度:’, len(json.dumps(data, separators=(‘,’,’:’))))
print(‘去掉空格后:’, json.dumps(data, separators=(‘,’,’:’)))
程序运行结果如下:
原数据: [{'a': 'A', 'b': (2, 4), 'c': 3.0}]
转换为JSON格式字符串: [{"a": "A", "b": [2, 4], "c": 3.0}]
转换为JSON格式字符串的长度: 35
去掉空格后的长度: 29
去掉空格后: [{"a":"A","b":[2,4],"c":3.0}]
通过运行结果中字符串的长度和去掉空格后的长度对比可以看出,“:”和“,”符号后面的空格被去掉了。
使用dumps() 方法将Python 字典类型数据转换为JSON 格式的字符串,代码如下:
import json
a = dict(name='sandy', age=17,QQ='null')
print (a)
print (type(a))
b = json.dumps(a)
print (b)
print (type(b))
程序运行结果如下:
{'name': 'sandy', 'age': 17, 'QQ': 'null'}
<class 'dict'>
{"name": "sandy", "age": 17, "QQ": "null"}
<class 'str'>
通过类型函数type() 判断得出:通过dumps() 方法可以将Python 字典类型的数据转换为JSON格式的字符串。
转换后的JSON 格式字符串是以紧凑的形式输出的,而且也没有顺序,因此dumps() 方法提供了一些可选的参数,可以提高输出格式的可读性,如参数sort_keys 可以告诉编码器按照字典排序(a到z)输出,代码如下:
import json
data = [ { ‘a’:’mr’, ‘c’:(66, 88), ‘d’:8.8,’b’:’mrkj’ } ]
print(‘原数据:’, data)
print(‘JSON格式的字符串:’, json.dumps(data))
print(‘排序后:’, json.dumps(data, sort_keys=True))
程序运行结果如下:
原数据: [{'a': 'mr', 'c': (66, 88), 'd': 8.8, 'b': 'mrkj'}]
JSON格式的字符串: [{"a": "mr", "c": [66, 88], "d": 8.8, "b": "mrkj"}]
排序后: [{"a": "mr", "b": "mrkj", "c": [66, 88], "d": 8.8}]
使用dumps() 方法将Python 数组类型数据转换为JSON 格式的字符串,代码如下:
import json
data = [ { 'a' : 1, 'b' : 2, 'c' : 3, 'd' : 4, 'e' : 5 } ]
json = json.dumps(data)
print(json)
程序运行结果如下:
[{"a": 1, "b": 2, "c": 3, "d": 4, "e": 5}]
使用dumps() 方法将列表转换为JSON 格式字符串,代码如下:
import json
l = ['ID',[1,2,3], {'name':'明日科技'}] # 创建一个列表
data = json.dumps(l,ensure_ascii=False) # 将列表转换为JSON格式
print(repr(l))
print(data) # 打印JSON格式
程序运行结果如下:
['ID', [1, 2, 3], {'name': '科技'}]
["ID", [1, 2, 3], {"name": "科技"}]
4. JSONDecoder()方法——返回一系列解码的数据
JSONDecoder() 方法是简单的JSON 解码器。语法格式如下:
class json.JSONDecoder(*,object_hook = None,parse_float = None,parse_int = None,parse_constant = None,strict = True,object_pairs_hook = None )
参数说明:
-
- :星号本身不是参数。星号表示其后面的参数都是关键字参数,需要使用关键字参数传值,否则程序会出现错误。
-
object_hook:可选参数,每一个解码出的对象(即一个字典),返回值会取代原来的字典。
-
parse_float:如果指定了该参数,将使用要解码的每个JSON float字符串调用。默认情况下为float 字符串。可用于为JSON 浮点数使用另一种数据类型或解析器(例如decimal.Decimal)。
-
parse_int:如果指定该参数,将使用要解码的每个JSON int 字符串调用。默认情况下为int字符串。可用于为JSON 整数使用另一种数据类型或解析器(例如float)。
-
parse_constant:如果指定该参数,将为下列字符串之一:‘-Infinity’ ;‘Infinity’ ;‘NaN’。如果遇到无效的JSON 字符串,将引发异常。
-
strict:默认值为True。如果值为False,则字符串中将允许控制字符。此上下文中的控制字符是字符代码在0~31 范围内的控制字符,包括’\t’(制表符)、‘\n’、‘\r’ 和’\0’。
-
object_pairs_hook:可选参数,将使用有序的对象列表对解码的任何对象的结果进行调用,用于实现自定义解码器。如果还定义了object_hook,则object_pairs_hook 优先。
-
返回值:返回一系列解码的数据。
说明:在方法中,如果出现“*”,则表示其后面的参数为命名关键字参数,这是一个特殊的分隔符。在调用时,命名关键字参数必须传入参数名。
使用JSONDecod er() 方法返回一系列解码的数据,代码如下:
import json
a1 = ‘{“a”: 123, “b”: 456, “c”: “明日科技"}’ # 字典
a2=’”\\”mr\\bar”’ # 字符串
# 解码后的数据及数据类型
json_decode = json.JSONDecoder()
print(json_decode.decode(a1))
print(type(json_decode.decode(a1)))
print(json_decode.decode(a2))
print(type(json_decode.decode(a2)))
程序运行结果如下:
{'a': 123, 'b': 456, 'c': '明日科技'}
<class 'dict'>
"mrar
<class 'str'>
在第三行代码中字符串“"\“mr\bar””中包含了\b,那么JSONDecoder() 方法解码后认为它是转义字符“退格键Backspace”。
5. JSONDecodeError()方法——返回解码错误信息
JSONDecodeError() 方法用于返回解码错误信息。语法格式如下:
json.JSONDecodeError(msg,doc,pos)
参数说明:
-
msg:表示未格式化的错误消息。
-
doc :表示正在解析的JSON 文档。
-
pos:表示解析失败的doc 的起始索引。
-
返回值:返回JSONDecodeError 错误信息。
先来看一段代码:
import json
data=”{‘01’:’零基础学Python’}”
data=json.loads(data)
print(data)
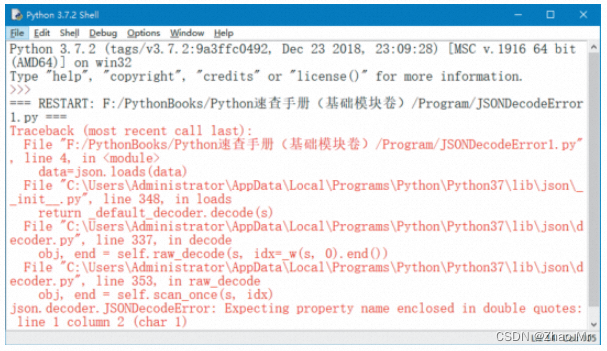
运行程序,出现了JSONDecodeError 错误。现将上述代码稍作修改:
import json
data=’{“01”:”零基础学Python”}’
data=json.loads(data)
print(data)
程序运行结果如下:
{'01': '零基础学Python'}
这里需要注意的是:虽然在Python 中单双引号的作用一样,但是在具体应用中还是有一些不同的地方。
例如,通过Python 获取“饿了么”附近美食时,用到了JSON 模块,将获取的JSON 格式的数据转换成Python 字典,但是运行程序却出现JSONDecodeError 错误
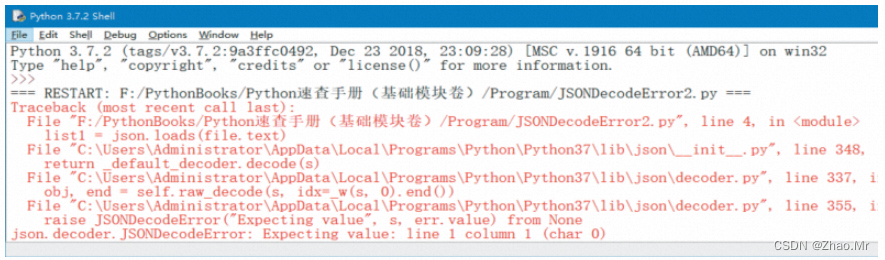
错误提示是在运行第4 行代码中的json 时出错,经检查错误原因是代码中输入的网址不正确,代码中的网址是浏览器中的网址,正确的网址需要通过网页“查看源”或“查看网页源代码”(不同的浏览器叫法不同)获得。
使用JSONDecodeError() 方法拦截JSONDecodeError 错误,提示“获取数据失败!”,代码如下:
import requests,json
try: # 遇错处理语句
# 错误的网址
url = ‘https://www.ele.me/place/wzc1w5gjtp52?latitude=43.879003&longitude=125.424261’
file = requests.get(url,timeout=3) # 向服务器发送请求
list1 = json.loads(file.text) # 读取文本文件转换为json格式
file1 = open(‘好吃的.txt’,’a’) # 将数据写入文本文件
for l in list1:
print(l[‘name’])
file1.write(l[‘name’]+’\n’)
file1.close()
except json.JSONDecodeError: # 拦截错误
print(‘获取数据失败!')
6. JSONEncoder()方法——返回一系列编码的数据
JSONEncoder() 方法用于Python 数据结构的可扩展JSON 编码器。语法格式如下:
class json.JSONEncoder(*,skipkeys = False,ensure_ascii = True,check_circular = True,allow_nan = True,sort_keys = False,indent = None,separators = None,default = None )
参数说明:
-
skipkeys:默认值是False,如果dict和keys内的数据不是Python的基本类型(str、Unicode、int、long、float、bool、None),会出现TypeError 错误。此时设置为True,则会跳过这个错误。
-
ensure_ascii:默认值为True。所有非ASCII 码字符显示为\uXXXX 序列,设置为False,则存入json 的中文即可正常显示。
-
check_circular:默认值为True,则在编码期间将检查列表、dicts 和自定义编码对象的循环引用,以防止无限递归。否则,不会进行此类检查。
-
allow_nan:默认值为True。NaN、Infinity和-Infinity不符合JSON规范,但它们符合JavaScript标准,是常用的扩展。如果无法处理它们就设置allow_nan 为False,但此时序列化NaN 时,就会出现ValueError 错误。
-
sort_keys:将数据根据Keys 的值进行排序,默认值为True。如果为False,则字典的输出将按键排序。
-
indent:应该是一个非负的整数。如果是0 就顶格分行显示,如果为空就是一行最紧凑显示,否则会换行显示,且按照indent 的数值显示前面的空白。
-
seperators:分隔符,实际上是(item_seperator,dict_seperator)的一个元组,默认值为(‘,’ , ‘:’),表示dictionary 内keys 之间用“,”隔开,而key 和value 之间用“:”隔开。
-
default:当default 被指定时,它是一个函数,每当某个对象无法被序列化时它会被调用。它返回该对象的一个可以被JSON 编码的版本或者引发一个TypeError 错误。如果没有被指定,则会直接引发TypeError 错误。
-
返回值:返回一系列编码的数据。
使用JSONEncoder() 方法返回一系列编码的数据并逐个输出,代码如下:
import json
encoder = json.JSONEncoder() # 将数据逐一转换为json字符串
data = [{ ‘a’:’A’, ‘b’:(2, 4), ‘c’:3.0 }]
for part in encoder.iterencode(data):
print(‘数据部分:’, part)
使用JSONEncoder() 方法的encode 参数,将Python 数据结构转换为JSON格式的字符串,代码如下:
import json
# 将字典转换为json字符串
data=json.JSONEncoder(ensure_ascii = False).encode({‘公司信息': [‘科技', ‘mrkj’]})
print(type(data)) # 输出数据类型
print(data)
程序运行结果如下:
<class 'str'>
{"公司信息": ["科技", "mrkj"]}
7. load()方法——从json文件中读取数据
load() 方法用于从json 文件中读取数据。语法格式如下:
json.load(fp, *, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)
参数说明:
-
fp :一个支持read() 方法或包含一个JSON 格式字符串的文本文件或二进制文件。
-
- :星号本身不是参数。星号表示其后面的参数都是关键字参数,需要使用关键字参数传值,否则程序会出现错误。
-
cls:可选参数,实例化的类。
-
object_hook:可选参数,每一个解码出的对象(即一个字典)会取代原来的字典。
-
parse_float:如果指定了该参数,将使用要解码的每个JSON float 字符串调用。默认情况下为float 字符串。此参数用于为JSON 浮点数指定使用另一种数据类型或解析器(例如decimal.Decimal)。
-
parse_int:如果指定该参数,将使用要解码的每个JSON int 字符串调用。默认情况下为int字符串。此参数用于为JSON 整数指定使用另一种数据类型或解析器(例如float)。
-
parse_constant:如果指定该参数,将为下列字符串之一:‘-Infinity’ ;‘Infinity’ ;‘NaN’。如果遇到无效的JSON 字符串,将引发异常。
-
object_pairs_hook:可选参数,将使用有序的对象列表对解码的任何对象的结果进行调用。用于实现自定义解码器。如果还定义了object_hook,则object_pairs_hook 优先。
-
**kw:其他关键字参数,用于字典。
-
返回值:返回字典。
首先使用write() 方法将字典类型数据写入到一个名为mr1.json 的文件中,然后使用load() 函数读取该文件中的数据并输出,代码如下:
import json
with open('./tmp/mr1.json','w+') as f: # 打开json文件
f.write('[{"a": "A", "c": 3.0, "b": [2, 4]}]') # 写入数据
f.flush() # 刷新缓冲区
f.seek(0) # 移动文件,读取指针到指定位置
print(json.load(f)) # 读取数据
程序运行结果如下:
[{'a': 'A', 'c': 3.0, 'b': [2, 4]}]
首先使用open() 方法读取文本文件mr1.txt 中的数据,然后使用load() 函数将其转换为JSON 格式并输出其中的城市名称信息,代码如下:
import json
with open('./tmp/mr1.txt','r') as f: # 打开文本文件
data = json.load(f) # 读取数据
for line in data: # 遍历数据输出城市名称
print(line['city'])
程序运行结果如下:
北京
上海
广州
哈尔滨
下面以追加方式打开该文件,然后添加两条新数据,代码如下:
import json
with open(‘./tmp/77.json’,’a+’) as f: # 以追加方式打开文件
f.seek(0) # 默认偏移量在最后,调整到开头
if f.read() ==’’: # 判断是否为空,如果为空创建一个新字典
data = {}
else:
f.seek(0)
data = json.load(f)
# 追加内容
data[‘04’]=’Python项目开发案例集锦'
data[‘05’]=’Python从入门到精通'
with open(‘./tmp/77.json’, ‘w’) as file:
json.dump(data, file, ensure_ascii=False)
8. loads()方法——将JSON格式转换成 Python字典
loads() 方法用于将JSON 格式字符串转换成Python 字典对象。语法格式如下:
json.loads(s, *, encoding=None, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)
参数说明:
-
s:包含JSON 格式字符串、字节或字节数组的实例。
-
:星号本身不是参数。星号表示其后面的参数都是关键字参数,需要使用关键字参数传值,否则程序会出现错误。
-
encoding:表示编码方式。
-
cls:可选参数,表示实例化的类。
-
object_hook:可选参数,每一个解码出的对象(即一个字典)会取代原来的字典。
-
parse_float:如果指定了该参数,将使用要解码的每个JSON float 字符串调用。默认情况下为float 字符串。此参数用于为JSON 浮点数指定使用另一种数据类型或解析器(例如decimal.Decimal)。
-
parse_int:如果指定该参数,将使用要解码的每个JSON int 字符串调用。默认情况下为int字符串。此参数用于为JSON 整数指定使用另一种数据类型或解析器(例如float)。
-
parse_constant:如果指定该参数,将为下列字符串之一:‘-Infinity’ ;‘Infinity’ ;‘NaN’。如果遇到无效的JSON 字符串,将引发异常。
-
object_pairs_hook:可选参数,将使用有序的对象列表对解码的任何对象的结果进行调用。用于实现自定义解码器。如果还定义了object_hook,则object_pairs_hook 优先。
-
kw:其他关键字参数,用于字典。
-
返回值:返回一个字典。
使用loads() 方法读取json 文件中的数据。例如,读取city.json 文件中的城市信息,代码如下:
import json
with open(‘./tmp/city.json’, ‘r’) as json_file: # 打开json文件
data = json_file.read() # 读取json文件
print(type(data)) # 输出数据类型
result = json.loads(data) # 将json字符串转换为字典
new_result = json.dumps(result,ensure_ascii=False) # 将字典转换为json字符串
print(new_result)
程序运行结果如下:
<class 'str'>
{"cities": [{"city": "北京", "cityid": "101010100"}, {"city": "上海", "cityid":"101020100"}]}
使用loads() 方法将JSON 格式字符串转换为字典类型,代码如下:
import json
with open('./tmp/city.json', 'r') as json_file: # 打开json文件
data = json_file.read() # 读取json文件
val = json.loads(data) # 将json字符串转换为字典
print(type(val)) # 输出数据类型
print(val)
程序运行结果如下:
<class 'dict'>
{'cities': [{'city': '北京', 'cityid': '101010100'}, {'city': '上海', 'cityid': '101020100'}]}



![[架构之路-215]- 架构 - 概念架构 - 模块(Module)、组件(Component)、包(Package)、对象、函数的区别](https://img-blog.csdnimg.cn/img_convert/3345e7c174187e09b1bec471db9c7726.png)