1. string模块介绍
Python中的第三方模块 string 模块解决了一些关于字符串操作的问题。例如,string 模块中可列出所有的大小写英文字母、数字、标点符号、八进制数字字符、十进制数字字符、十六进制数字字符等 Python 中可打印的字符;还可以进行格式化、定制模板等操作。
2. ascii_letters常量,返回所有大小写字母
语法参考
ascii_letters 常量用于返回所有小写字母(az)和所有大写字母(AZ)。该值不会因为语言区域而发生改变。语法格式如下:
string.ascii_letters
参数说明:
- 返回值:返回 26 个大小写英文字母。
锦囊1 获取26个小写英文字母和26个大写英文字母
使用 ascii_letters 常量获取26个小写英文字母(az)和26个大写英文字母(AZ),代码如下:
import string
chars = string.ascii_letters
print(chars)
程序运行结果如下:
abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ
锦囊2 随机生成5组由大、小写字母组成的字符串
使用 ascii_letters常量和Python提供的随机函数随机生成5组由8位大、小写字母组成的字符串,代码如下:
import random, string
# 生成5组随机数
for i in range(5):
#sample()函数从指定的序列中随机截取8个字符
myCode=’’.join(random.sample(string.ascii_letters,8))
print(myCode)
程序运行结果如下:
IdUzNaFj
eDYOEwUx
secCYvkh
ZMLzFfYW
HPWksYmA
锦囊3 随机生成 100 个激活码
激活码一般都是由字母和数字组成的,首先要有一个包含所有字母和数字的字符串,然后从中随机取出几个字母或数字生成激活码(比如优惠券、注册码等),代码如下:
import random, string
def IDstr(num1, len1=8):
f = open(‘./tmp/mycode.txt’, ‘w’)
for i in range(num1):
# 返回大小写字母和数字的组合
chars = string.ascii_letters + string.digits
# choice()函数从任何序列中随机选取8位字符
s = [random.choice(chars) for i in range(len1)]
f.write(‘{0}\n’.format(‘‘.join(s)))
f.close()
# 调用函数,生成100个激活码
IDstr(100)
3. ascii_lowercase常量,返回所有小写字母
语法参考
ascii_lowercase 常量用于返回所有小写字母(a~z),即“abcdefghijklmnopqrstuvwxyz”。该值不会因为语言区域而发生改变。语法格式如下:
string.ascii_lowercase
参数说明:
- 返回值:返回26个小写字母(a~z)。
锦囊1 获取26个小写英文字母
使用ascii_lowercase常量获取26个小写英文字母,代码如下:
import string
chars = string. ascii_lowercase
print(chars)
锦囊2 判断输入字母是否全为小写
通过编写自定义函数,判断输入的字母是否全为小写,代码如下:
import string
# 定义判断小写字母的函数
def check(value):
for letter in value:
if letter not in string.ascii_lowercase:
return False
return True
myval=input(“请输入小写字母:")
print(check(myval))
锦囊3 生成由小写字母和数字随机组成的 10 位密码
使用 ascii_lowercase 常量和 digits 常量并结合随机函数,生成由小写字母和数字随机组成的 10 位密码,代码如下:
import random, string
# 生成由小写字母和数字随机组成的10位密码
passwords = ''.join([random.choice(string.ascii_lowercase + string.digits)for n in range(10)])
print(passwords)
4. ascii_uppercase常量,返回所有大写字母
语法参考
ascii_uppercase 常量用于返回所有大写字母(A~Z),即“ABCDEFGHIJKLMNOPQRSTUVWXYZ”。该值不会因为语言区域而发生改变。语法格式如下:
string.ascii_uppercase
参数说明:
- 返回值:返回所有大写字母(A~Z)。
锦囊1 获取26个大写英文字母
使用ascii_uppercase常量获取26个大写英文字母,代码如下:
import string
chars = string.ascii_uppercase
print(chars)
锦囊2 判断输入字母是否全为大写
自定义函数,判断输入的字母是否全为大写,代码如下:
import string
# 定义判断大写字母的函数
def check(value):
for letter in value:
if letter not in string.ascii_uppercase:
return False
return True
myval=input("请输入大写字母:")
if check(myval)==False:
print("请输入大写字母!")
5. digits常量,返回十进制数字字符串
语法参考
digits 常量用于返回十进制数字字符串(0~9),即“0123456789”。该值不会因为语言区域而发生改变。语法格式如下:
string.digits
参数说明:
- 返回值:返回十进制数字字符串(0~9)。
锦囊1 获取所有的十进制数字字符
使用digits常量获取所有的十进制数字字符(0~9),代码如下:
import string
chars = string.digits
print(chars)
锦囊2 随机抽取8位幸运数字
使用digits常量和随机函数随机抽取8位幸运数字,代码如下:
import random, string
# 生成1组随机数
for i in range(1):
# sample()函数从指定的序列中随机截取8个字符
myCode=’’.join(random.sample(string.digits,8))
print(myCode)
6. hexdigits常量,返回十六进制数字字符串
语法参考
hexdigits 常量用于返回十六进制数字字符串(09、af、A~F),即“0123456789abcdefABCDEF”。该值不会因为语言区域而发生改变。语法格式如下:
string.hexdigits
参数说明:
- 返回值:返回十六进制数字字符串(09、af、A~F)
锦囊1 获取所有十六进制的数字字符
使用 hexdigits 常量获取所有十六进制的数字字符,代码如下:
import string
chars = string.hexdigits
print(chars)
锦囊2 随机获取10位数字字符
使用随机函数和 hexdigits 常量随机获取10位数字字符,代码如下:
import random
import string
password = ''.join([random.choice(string.hexdigits)
for n in range(10)])
print(password)
7. octdigits常量,返回八进制数字字符串
语法参考
octdigits 常量用于返回八进制数字字符串(0~7),即“01234567”。该值不会因为语言区域而发生改变。语法格式如下:
string.octdigits
参数说明:
- 返回值:返回八进制数字字符串(0~7)。
锦囊1 获取所有的八进制数字字符
使用octdigits常量获取所有的八进制数字字符,代码如下:
import string
chars = string.octdigits
print(chars)
锦囊2 随机生成10位八进制数字编码
使用随机函数和octdigits常量随机生成10位八进制数字编码,代码如下:
import random
import string
password = ''.join([random.choice(string.octdigits)
for n in range(10)])
print(password)
8. punctuation常量,返回英文标点符号
语法参考
punctuation常量用于获取在Python语言中被视为标点符号的ASCII字符组成的字符串。语法格式如下:
string.punctuation
参数说明:
- 返回值:返回英文标点符号。
锦囊1 获取所有英文标点符号
使用punctuation常量获取所有英文标点符号,代码如下:
import string
chars = string.punctuation
print(chars)
程序运行结果如下:
!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
锦囊2 滤除垃圾邮件中的“*_/@.”等特殊符号
日常生活中经常会收到一些垃圾邮件,其中包含一些特殊符号,如“*_/@.”等。下面使用maketrans() 方法和 translate() 方法将这些符号删除,代码如下:
import string
temp = ‘想做/ 兼_职/程序员_/ 的 、加,我Q: 400*765@1066.!!??有,惊,喜,哦'
print(temp.translate(str.maketrans(‘‘, ‘‘, string.punctuation)))
程序运行结果如下:
想做 兼职程序员 的 、加我Q: 4007651066!!??有惊喜哦
锦囊3 删除垃圾信息中的“》【】”等特殊符号
日常生活中也经常会收到一些垃圾信息,其中包含一些特殊符号,如“》”“【】”等。下面使用maketrans() 方法和 translate() 方法将这些符号删除,代码如下:
import string
temp1=’【学】【编程】【*】【*】,有需要请加 Q Q :400-675-1066.谢谢!'
str1 = string.punctuation + ‘》【】' # 引入英文符号常量,并附加自定义字符
print(temp1.translate(str.maketrans(‘‘, ‘‘, str1)))
9. printable常量,返回可打印字符
语法参考
printable 常量返回被视为 Python 可打印字符并由 ASCII 字符组成的字符串,它是 digits 常量、ascii_letters 常量、punctuation 常量和 whitespace 常量返回值的总和。语法格式如下:
string.printable16
参数说明:
- 返回值:返回Python的可打印字符。
锦囊1 获取所有可以打印的字符
使用printable常量获取Python的所有可以打印的字符,代码如下:
import string
chars = string.printable
print(chars)
锦囊2 检查字符串中的所有字符是否都是可打印字符
通过printable常量和all()函数检查字符串的所有字符是否都是可打印字符,代码如下:
import string
a1 = 'mingrisoft.com'
b1 = chr(7)
c1 = chr(88)
print(all(c in string.printable for c in a1))
print(all(c in string.printable for c in b1))
print(all(c in string.printable for c in c1))
10. whitespace常量,返回空白符号
语法参考
whitespace 常量返回被 Python 视为空白字符并由 ASCII 字符组成的字符串,其中包括空格符、制表符、换行符、回车符等。语法格式如下:
string.whitespace
参数说明:
- 返回值:返回空白字符。
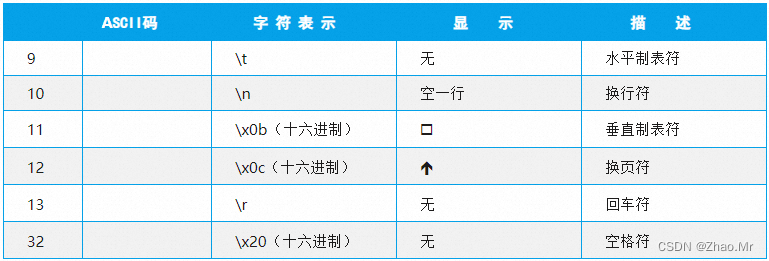
锦囊1 判断输入的字符是否为空白字符
如果输入的是一个字符,则判断该字符是否为空白符,如果为空白符(如空格等)将提示输入无效,代码如下:
import string
while 1:
mystr=input('请输入有效字符:')
if mystr in string.whitespace:
print('输入无效,请重新输入')
else:
print('输入有效!')
break
11. capwords()方法,单词首字母大写
语法参考
capwords() 方法用于将单词首字母转换为大写。语法格式如下:
string.capwords(s, sep=None)
参数说明:
-
s :必选参数,用于指定要转换的字符串。
-
sep :可选参数,为空或为 None,多个空格会被一个空格代替,字符串开头和结尾的空格将会被移除;另外,sep 这个参数是用来分割和组合字符串的。
-
返回值:返回转换后的字符串。
锦囊1 将所有单词的首字母转换为大写形式
导入string模块,并且调用capwords()方法将一段英文励志名言的每个单词的首字母转换为大写形式,代码如下:
import string # 导入字符串模块
cn = ‘没什么是你能做却办不到的事。'
en = “There’s nothing you can do that can’t be done.”
result = string.capwords(en) # 每个单词首字母转换为大写形式
print(cn)
print(‘转换前:‘,en)
print(‘转换后:‘,result)
12. Formatter类,自定义字符串格式化行为
语法参考
string 模块中的 Formatter 类可以使用与内置 format() 函数相同的方法创建并定制自己的字符串格式化行为。语法格式如下:
class string.Formatter
参数说明:
- 返回值:返回 Formatter 类。
锦囊1 直接使用 string.Formatter 类格式化字符串
string.Formatter类可以直接格式化字符串,当然这需要借助它的 format() 方法。下面示例使用Formatter 类的 format()方法实现格式化输出字符串,要求输出两边带星号的字符串,指定长度为8,不够的长度用空格填充并且右对齐,代码如下:
import string
formatter = string.Formatter()
s1='***{:8d}***' # 指定格式右对齐
s2='***{:>15s}***' # 指定格式右对齐
print(formatter.format(s1,1000))
print(formatter.format(s2,'888科技有限公司'))
锦囊2 通过占位符{ }格式化列表中的值
继承string.Formatter类,并重写其方法,在format()方法中传入参数为列表时,应在列表前加上符号“*”,代码如下:
import string
formatter = string.Formatter()
list1 = [400,675,1066]
val = formatter.format('{}-{}-{}', *list1)
print(val)
13. check_unused_args()方法,对未使用参数进行检测
语法参考
check_unused_args()方法用于对未使用的参数进行检测。语法格式如下:decimal
check_unused_args(used_args, args, kwargs)
参数说明:
- used_args :表示格式字符串中实际引用的所有参数键的集合。
- args :任意位置,元组类型。
- kwargs :关键字参数,字典类型。
- 返回值:返回错误提示或是 None。
说明:check_unused_args() 方法如果检查失败,则假定引发异常。
锦囊1 检测参数使用情况
使用check_unused_args()方法对参数使用情况进行检测,代码如下:
import string
formatter = string.Formatter()
data = ('1234567890')
strtmp = '公司简称:{}{:>4s}'
mystr=formatter.check_unused_args(data,{},strtmp)
print(mystr)
14. convert_f ield()方法,根据给定类型转换字段
语法参考
convert_field()方法用于根据给定的转换类型转换字段。语法格式如下:
convert_field(value,conversion)
参数说明:
-
value :表示需要转换的数据。
-
conversion :转换规则,需要转换的类型。
-
返回值:返回转换后的字段。
锦囊1 将数值型数字转换为数字字符串
使用convert_field()方法将数值型数字转换为数字字符串,代码如下:
import string
formatter = string.Formatter()
val=888
str1=formatter.convert_field(val,'s') # 转换为字符串
print(str1)
print(type(str1))
15. format()方法,格式化字符串
语法参考
format()方法是formatter类中的主要方法,它的参数是一个需要格式化的目标字符串,和一组需要填充目标字符串的序列,例如,字典和元组,format()方法是对vformat()方法的封装。语法格式如下:
format(format_string, *args, **kwargs)
参数说明:
-
format_string :表示需要格式化的目标字符串。
-
*args :表示填充目标字符串的序列,是字典或元组。
-
**kwargs :关键字参数。
-
返回值:返回格式化后的字符串。
锦囊1 类型转换
使用format()方法可以实现数据类型的转换,字符串用参数s表示,十进制整型用参数d和n表示,布尔型用参数b表示,八进制用参数o表示,十六进制小写用参数x表示,十六进制大写用参数X表示,ASCII码用参数c表示,浮点型用参数f表示,浮点型(科学计数)用参数e表示。以上格式化后的数据类型都为字符型,代码如下 :
import string
formatter = string.Formatter()
# 类型转换
s1='{:d}' # 十进制
s2='{:o}' # 八进制
s3='{:x}' # 十六进制
s4='{:f}' # 浮点型
s5='{:e}' # 浮点型(科学计数)
s6='{:b}' # 布尔型
s7='{:s}' # 字符串
s8='{:c}' # ASCII码
print(formatter.format(s1, 1000))
print(formatter.format(s2, 1000))
print(formatter.format(s3, 1000))
print(formatter.format(s4, 1000))
print(formatter.format(s5, 1000))
print(formatter.format(s6, True))
print(formatter.format(s7, 'A'))
print(formatter.format(s8, 34))
---------------------------------------------------
s1='{:0>3}'
s2='{:0>5}'
s3='a{:0>6}'
print(formatter.format(s1,1))
print(formatter.format(s2,'08'))
print(formatter.format(s3,886))
---------------------------------------------------
s1='{:%}' # 将小数格式化成百分比
s2='{:.0%}' # 格式化后保留整数百分比
s3='{:.2%}' # 格式化后保留两位小数的百分比
s4='{:10.3%}' # 格式化后保留3位小数的10位百分比
print(formatter.format(s1,0.1314))
print(formatter.format(s2,0.1314))
print(formatter.format(s3,0.1314))
print(formatter.format(s4,0.1314))
---------------------------------------------------
s1='${:.2f}' # 添加美元符号,小数保留两位
s2='¥{:,.2f}' # 添加人民币符号,用千位分隔符进行区分
s3='£{:,.2f}' # 添加英镑符号,用千位分隔符进行区分
s4='€{:.2f}' # 添加欧元符号,保留两位小数
print(formatter.format(s1,0.88))
print(formatter.format(s2,888800))
print(formatter.format(s3,123567))
print(formatter.format(s4,123567))
---------------------------------------------------
list1 = [‘零基础学Python’,’Python编程锦囊’,’Python从入门到项目实践’]
val = formatter.format(‘《{}》《{}》《{}》', *list1)
print(val)
---------------------------------------------------
s1='{:0>5}'
formatter = string.Formatter()
data={'订单编号':[1,2,3],'会员名':['mrsoft','mingri','mr']}
list1=data['订单编号']
for i in list1:
val = formatter.format(s1, i)
print(val)
锦囊2 格式化日期和时间
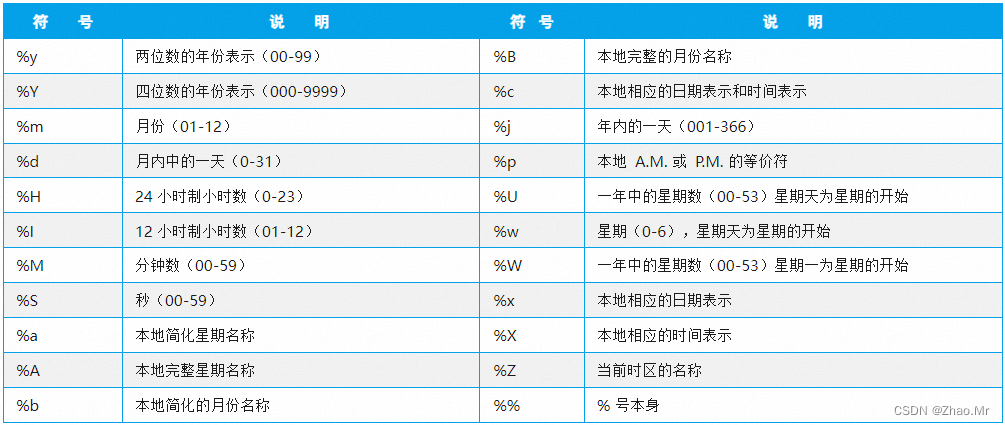
import string
import datetime
formatter = string.Formatter()
d = datetime.datetime.now() # 获取当前系统时间
s1= '{:%Y-%m-%d %H:%M:%S}'
s2='{:%Y-%m-%d %H:%M:%S %a}'
s3=f'{d:%Y}年{d:%m}月{d:%d}日 {d:%H}时{d:%M}分{d:%S}秒'
print(formatter.format(s1,d)) # 四位年
print(formatter.format(s2,d)) # 带星期的日期
print(formatter.format(s3,d)) # 中文年-月-日和时间的显示
锦囊3 格式化csv文件中的数据
import csv
import string
s1='{:0>10}'
formatter = string.Formatter()
with open('./tmp/r1.csv') as myFile: # 打开csv文件
rows=csv.reader(myFile) # 读取csv文件
for row in rows: # 按行读取
if rows.line_num == 1: # 忽略第一行表头
continue
print(formatter.format(s1,row[0])) # 格式化“运单号”
程序运行结果如下:
0007515123
0007515124
16. format_f ield()方法,通过format()函数格式化数据
语法参考
format_field()方法通过调用format()内置函数实现简单的格式化数据的功能。语法格式如下:
format_field(value,format_spec)
参数说明:
-
value :表示要进行格式化的对象。
-
format_spec :格式化规范,字符串类型。
-
返回值:返回格式后的字符串。
锦囊1 字符串对齐后输出
使用format_field()方法实现字符串对齐,代码如下:
import string
formatter = string.Formatter()
val=’888科技’
str1=formatter.format_field(val,’>9’) # 右对齐
print(str1)
str1=formatter.format_field(val,’<9’) # 左对齐
print(str1)
str1=formatter.format_field(val,’^9’) # 中间对齐
print(str1)
str1=formatter.format_field(val,’*^30’) # 利用*符号充当占位符
print(str1)
str1=formatter.format_field(val,’-^20’) # 利用-符号充当占位符
print(str1)
val1=5
str1=formatter.format_field(val1,'0>2') # 数字补0,填充左边,长度为2
print(str1)
str1=formatter.format_field(val1,'x<4') # 数字补x,填充右边,长度为4
print(str1)
str1=formatter.format_field(val1,'x^3') # 数字补x,填充左右,长度为3
print(str1)
17. get_f ield()方法,获取指定字段的数据返回元组
语法参考
get_field() 方法通过给定字段名称返回该字段相关数据(元组)。语法格式如下:
get_field(field_name, args, kwargs)
参数说明:
-
field_name :字段名称,parse() 方法的返回值。
-
args :任意位置,元组类型。
-
kwargs :关键字参数,字典类型。
-
返回值:返回一个元组。
锦囊1 通过指定字段返回该字段相关的数据
使用get_field()方法通过给定字段名称ID来获取该字段相关的数据,代码如下:
import string
formatter = string.Formatter()
data = {'ID':'00001','name':'888科技有限公司'}
fieldname = 'ID'
tuple1=formatter.get_field(fieldname,(),data)
print(tuple1)
18. get_value()方法,获取指定字段的值
语法参考
get_value()方法用于获取指定字段的值。语法格式如下:
get_value(key, args, kwargs)
参数说明:
-
key :表示整数或字符串,如果是整数,表示 args 中位置参数的索引;如果是字符串,表示kwargs 中的关键字参数名。
-
args :任意位置,元组类型。
-
kwargs :关键字参数,字典类型。
-
返回值:返回字符串。
注意:如果索引或关键字引用了一个不存在的项,则将引发IndexError或KeyError错误。
锦囊 获取指定字段的值
使用get_value()方法获取字段ID的值,代码如下:
import string
formatter = string.Formatter()
data = {'ID':'00001','name':'888科技有限公司'}
key = 'ID'
mystr=formatter.get_value(key,(),data)
print(mystr)
19. parse()方法,创建迭代器解析格式字符串
语法参考
parse()方法用于创建迭代器来解析格式字符串。语法格式如下:
parse(format_string)
参数说明:
-
format_string :表示格式字符串。
-
返回值:返回一个由可迭代对象组成的元组,通过 vformat() 方法将字符串分解为文本字面值和替换字段。
锦囊1 分解格式字符串为元组
使用formatter.parse()方法分解格式字符串为元组,代码如下:
import string
formatter = string.Formatter()
strtmp = '公司简称:{}{:>4s}'
strtuple = formatter.parse(strtmp)
# 遍历数据对象
for i, j in enumerate(strtuple):
print(i, j)
程序运行结果如下:
0 ('公司简称:', '', '', None)
1 ('', '', '>4s', None)
20. vformat()方法,执行实际的格式化操作
语法参考
vformat()方法用于执行实际的格式化操作,将格式字符串分解为文本字面值和替换字段。语法格式如下:
vformat(format_string, args, kwargs)
参数说明:
-
format_string :需要格式化的目标字符串。
-
args:任意位置,元组类型。
-
kwargs:关键字参数,字典类型。
-
返回值:返回格式化后的字符串。
说明:vformat()方法被视为一个单独的方法,用于传入一个预定义字母作为参数,而不是使用*args和**kwargs参数将字典解包为多个单独参数并重新打包。
锦囊1 将元组转换为指定格式字符串输出
使用vformat()方法将元组转换为指定格式字符串输出,代码如下:
import string
formatter = string.Formatter()
data = (‘qqqqqq’,’001’)
strtmp = ‘公司简称:{}{:>4s}’
strtmp = formatter.vformat(strtmp,data,{}) # 将元组转换为指定格式的字符串
print(strtmp)
锦囊2 将字典转换为指定格式字符串输出
使用formatter.vformat()方法将字典转换为指定格式字符串输出,代码如下:
import string
formatter = string.Formatter()
data = {'ID':'00001','name':'888科技有限公司'}
mystr = '公司名称:{ID}{name}'
mystr = formatter.vformat(mystr,(),data) # 将字典转换为指定格式的字符串
print(mystr)
21. Template类,创建字符串模板
语法参考
将一个字符串设置为模板,通过替换变量的方法,最终得到想要的字符串。使用参数 template创建的字符串模板可以不编辑应用就改变其中的数据,这种方法比使用 Python 的其他内置字符串格式化工具更为方便。语法格式如下:
class string.Template(template)
参数说明:
-
template :模板字符串,使用“$”符号,或在字符串内使用“${}”,调用时使用 string.substitute()方法。
-
返回值:返回格式化后的字符串。字符串模板支持基于$的替换,使用以下规则:
-
$$ :转义符号,它会被替换为单个的$。
-
$name :替换占位符,它会匹配一个名为“name”的映射键。默认情况下,限制为任意ASCII字母数字(包括下划线)组成的字符串,不区分大小写,以下划线或ASCII字母开头。在$字符之后的第一个非标识符字符将表明占位符的终结。
-
${identifier} :等价于 $identifier。当占位符之后紧跟着有效的但又不是占位符一部分的标识符字符时需要使用,例如,“${noun}ification”。
说明:在字符串的其他位置出现$将导致引发ValueError错误。
锦囊1 创建简单的字符串模板
创建一个简单的字符串模板,输出当日温度和空气质量,代码如下:
from string import Template
import datetime
# 字符串模板
s = Template(‘今日:$date 温度:$TEMP 空气质量:$air’)
print(s.substitute(date=datetime.datetime.now(), TEMP=’22’,air=’优'))
22. template属性,返回字符串模板
语法参考
template 属性用于返回字符串模板,作为构造器的template参数被传入的对象。一般来说,不应该修改它,但并不强制要求只读访问。语法格式如下:
s.template
参数说明:
-
s :表示使用Template类创建的字符串模板。
-
返回值:返回格式化后的字符串。
锦囊1 获取已创建的字符串模板
当设计完成一个字符串模板后,可以通过设置template属性来获取该字符串模板内容,代码如下:
import string
s = string.Template('本书作者 $name, 创作时间 $time') # 使用Template类构造函数
print(s.template)
23. safe_substitute()方法,执行模板(忽略错误格式)
语法参考
safe_substitute()方法的应用类似于substitute()方法,语法格式如下:
safe_substitute(mapping, **kwds)
参数说明:
-
mapping :表示任何类似字典的对象,其键与模板中的占位符匹配。
-
**kwds :关键字参数,其中关键字是占位符。
-
返回值:返回一个新字符串。
safe_substitute() 方法与 substitute() 方法相比被认为是“安全”的,因为它一般情况下都会返回可用的字符串,即使模板中出现包含不合法的或多余的字符等情况时,它也不会出现错误提示;但是从另一方面来说,safe_substitute() 方法也可能是不“安全”的,因为它默默地忽略了模板中的错误格式。例如,即使格式模板中出现包含多余的分隔符、不成对的花括号或不是合法 Python 标识符的占位符等情况时,它都会忽略,不提示错误。
锦囊1 使用 safe_substitute() 方法执行模板
使用 template.safe_substitute() 方法执行替换模板,代码如下:
import string
s = string.Template('本书作者 $name, 创作时间 $time') # 使用Template类构造函数
kewds = {'name':'888科技有限公司', 'time':'2019.8'}
kewds1 = {'name':'time'}
str1 = s.safe_substitute(kewds)
print(str1)
str1 = s.safe_substitute(kewds1)
print(str1)
从运行结果第二行看,当使用 template.safe_substitute() 方法执行替换模板时,即使模板中的参数不全,也不会出现错误,而是直接返回新字符串。
24. substitute()方法,执行替换模板
语法参考
substitute() 方法用于执行替换模板。语法格式如下:
substitute(mapping, **kwds)
参数说明:
-
mapping :表示任意字典类型的对象,其键与模板中的占位符匹配。
-
**kwds :关键字参数,其中关键字是占位符。
-
返回值:返回一个新字符串。
锦囊1 使用 substitute() 方法执行模板
首先定制模板,然后使用 substitute() 方法替换模板内容,代码如下:
import string
myTemplate = string.Template(‘本书作者:$name\n创作时间:$time') # 使用Template类创建模板
print(myTemplate.substitute(name=’88科技’, time=’2019年8月’)) # 替换模板内容
当 template.substitute() 方法执行一个参数不全的字符串模板时,将会引发错误。
锦囊2 替换模板中默认符号并执行模板
模板 myTemplate 中以“$”符号来表示模板中的变量名,当然也可以使用其他符号。下面将“$”符号改为“*”符号,然后通过 substitute() 方法执行模板,代码如下:
from string import Template
class MyTemplate(Template):
delimiter = '*'
s = MyTemplate('*a省*b市*c区')
print(s.substitute(a='陕西',b='西安',c='二道'))