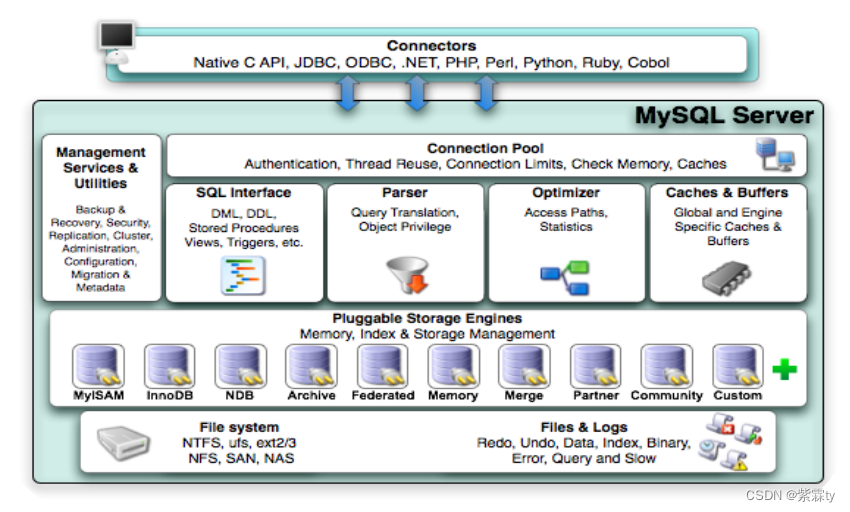
一、MySQL架构
MySQL的连接层处理客户端连接和权限管理,服务层解析和执行SQL语句,引擎层负责数据的存储和检索,存储层处理数据在磁盘上的读写操作。这种架构使得MySQL可以在不同的场景中灵活运行,并根据需求选择合适的存储引擎和配置。
连接层(Connection Layer):
- 连接层是MySQL的最上层组件,负责处理客户端与服务器之间的连接。
- 客户端通过连接层与MySQL服务器建立通信,并发送SQL查询和命令。
- 连接层处理身份验证、会话管理、权限控制等功能。
服务层(Server Layer):
- 服务层是连接层之下的组件,负责解析和执行SQL语句。
- 它接收来自连接层的查询请求,并将其转发给适当的存储引擎进行处理。
- 服务层还处理事务管理、并发控制、缓存、查询优化等任务。
引擎层(Storage Engine Layer):
- 引擎层是MySQL的核心组件,负责处理数据的存储和检索。
- MySQL支持多个存储引擎,如InnoDB、MyISAM、Memory等。
- 不同的存储引擎具有不同的特点和适用场景,例如InnoDB适合事务处理,而MyISAM适合读写较少的应用。
存储层(Storage Layer):
- 存储层是实际存储数据的组件,它由文件系统和物理存储设备组成。
- 存储层负责将数据写入磁盘,并从磁盘读取数据供引擎层使用。
- 存储层可以通过配置和优化来提高数据库的性能和可靠性。
下面是对这些组件的详细描述:
- Connection Pool : 连接池组件
- Management Services & Utilities : 管理服务和工具组件
- SQL Interface : SQL接口组件
- Parser : 查询分析器组件
- Optimizer : 优化器组件
- Caches & Buffers : 缓冲池组件
- Pluggable Storage Engines : 存储引擎
- File System : 文件系统
二、MySQL存储引擎
Oracle,SqlServer等数据库只有一种存储引擎。MySQL提供了插件式的存储引擎架构。所以MySQL存在多种存储引擎,可以根据需要使用相应引擎,或者编写存储引擎。
MySQL 存储引擎是基于表的,而不是基于库的。所以存储引擎也可被称为表类型。
对比各个存储引擎之间的区别, 所示 :
| 特点 | InnoDB | MylSAM | MEMORY | MERGE | NDB |
|---|---|---|---|---|---|
| 存储限制 | 64TB | 有 | 有 | 没有 | 有 |
| 事务安全 | 支持 | 不支持 | 不支持 | 不支持 | 不支持 |
| 锁机制 | 行锁(适合高并发) | 表锁 | 表锁 | 表锁 | 行锁 |
| B树索引 | 支持 | 支持 | 支持 | 支持 | 支持 |
| 哈希索引 | 不支持 | 不支持 | 支持 | 不支持 | 不支持 |
| 全文索引 | 支持(5.6之后) | 支持 | 不支持 | 不支持 | 不支持 |
| 集群索引 | 支持 | 不支持 | 不支持 | 不支持 | 不支持 |
| 数据索引 | 支持 | 不支持 | 支持 | 不支持 | 支持 |
| 索引缓存 | 支持 | 支持 | 支持 | 支持 | 支持 |
| 数据可压缩 | 不支持 | 支持 | 不支持 | 不支持 | 不支持 |
| 空间使用 | 高 | 低 | 无 | 低 | 低 |
| 内存使用 | 高 | 低 | 中等 | 低 | 高 |
| 批量插入速度 | 低 | 高 | 高 | 高 | 高 |
| 支持外键 | 支持 | 不支持 | 不支持 | 不支持 | 不支持 |
1. InnoDB
InnoDB提供了强大的事务支持、并发控制、数据完整性和崩溃恢复机制。它适用于处理高并发的应用程序和要求数据一致性和可靠性的场景,如在线事务处理(OLTP)系统。
-
事务支持:InnoDB是一个支持ACID(原子性、一致性、隔离性和持久性)事务的存储引擎。它可以保证数据的完整性和一致性,并提供了提交、回滚和崩溃恢复等机制。
-
行级锁定:InnoDB使用行级锁定来实现并发控制,这意味着在同一时间可以有多个并发的读写操作。行级锁定减少了锁冲突,提高了并发性能。
-
外键约束:InnoDB支持外键约束,可以在数据库中定义关系,并强制执行引用完整性。这使得在多个表之间建立关联关系变得更加简单和可靠。
查看外键信息: show create table city_innodb ; -
数据完整性:InnoDB支持主键、唯一索引和非空约束等数据完整性约束,可以保证存储的数据的一致性和完整性。
-
缓冲池:InnoDB具有一个称为"缓冲池"(Buffer Pool)的内存区域,用于缓存热数据和索引。通过减少对磁盘的IO操作,可以显著提高性能。
-
支持MVCC:InnoDB使用多版本并发控制(MVCC)来处理并发读写操作。这意味着读操作不会阻塞写操作,并且可以提供一致性的读取快照。
-
崩溃恢复:InnoDB具有强大的崩溃恢复机制。它通过将数据更改写入事务日志(redo log)来确保持久性,并在系统崩溃后可以快速恢复数据的一致性。
-
自适应哈希索引:InnoDB可以自动根据查询模式创建和管理自适应哈希索引,以提高特定查询的性能。
-
存储方式:InnoDB 存储表和索引有以下两种方式
- 使用共享表空间存储, 这种方式创建的表的表结构保存在.frm文件中, 数据和索引保存在 innodb_data_home_dir 和 innodb_data_file_path定义的表空间中,可以是多个文件。
- 使用多表空间存储, 这种方式创建的表的表结构仍然存在 .frm 文件中,但是每个表的数据和索引单独保存在 .ibd 中。

2. MyISAM
MyISAM适用于对读取性能要求较高,而对事务支持和数据一致性要求相对较低的场景。它通常用于一些非关键数据、只读数据或者日志记录等情况下,可以提供较好的性能和存储效率。然而,如果需要事务支持、数据一致性和高并发写入的功能,建议选择其他存储引擎,如InnoDB。
-
高性能:MyISAM存储引擎在读取方面具有较高的性能。它采用了基于表的锁定机制,可以在读操作期间支持高并发性能。
-
全文索引:MyISAM支持全文索引功能,可以进行全文搜索和匹配,适用于处理大量的文本数据。
-
低存储和内存占用:相对于其他存储引擎,如InnoDB,MyISAM在存储和内存占用方面更加高效。它将表的数据和索引分开存储,可以更好地控制磁盘空间的利用。
-
不支持事务:MyISAM存储引擎不支持事务,这意味着它不具备ACID属性。如果需要具备事务支持和数据一致性的功能,应该选择其他存储引擎,如InnoDB。
-
表级锁定:MyISAM使用表级锁定,这意味着在写操作期间会对整个表进行锁定,限制了并发写操作的能力。这可能会导致在高并发写入场景下的性能瓶颈。
-
缓存管理:MyISAM使用键缓存(Key Cache)来管理索引缓存,以提高查询性能。但是,对于大型表或者需要频繁更新的表,缓存管理可能会成为性能瓶颈。
-
不支持外键约束:与InnoDB不同,MyISAM存储引擎不支持外键约束。这意味着无法在数据库层面实现关联完整性。
-
存储方式:每个MyISAM在磁盘上存储成3个文件,其文件名都和表名相同,但拓展名分别是 : .frm (存储表定义)、.MYD(MYData , 存储数据)、.MYI(MYIndex , 存储索引);

3. Memory
Memory存储引擎将表的数据存放在内存中。每个MEMORY表实际对应一个磁盘文件,格式是.frm ,该文件中只存储表的结构,而其数据文件,都是存储在内存中,这样有利于数据的快速处理,提高整个表的效率。MEMORY 类型的表访问非常地快,因为他的数据是存放在内存中的,并且默认使用HASH索引 , 但是服务一旦关闭,表中的数据就会丢失。
-
基于内存:Memory引擎将表的数据完全存储在内存中,不涉及磁盘IO操作。这使得它具有非常高的读取和写入性能,适用于对速度要求极高的场景。
-
临时数据存储:Memory引擎通常用于存储临时数据、缓存或者会话级别的数据。由于数据存储在内存中,它适合处理频繁变动的数据,例如临时计算结果或者中间查询结果。
-
不支持持久化:由于数据仅存在于内存中,Memory引擎不支持数据的持久化存储。一旦MySQL服务器重启或崩溃,存储在Memory引擎中的数据将会丢失。因此,它不适用于需要长期存储和持久性要求的数据。
-
不支持事务和崩溃恢复:Memory引擎不支持事务,也不提供崩溃恢复机制。如果MySQL服务器崩溃或重启,所有存储在Memory引擎中的数据都会丢失。这使得Memory引擎不适合存储关键数据或需要数据持久性和一致性的应用程序。
-
表级锁定:Memory引擎使用表级锁定来控制并发访问,这意味着在写操作期间会对整个表进行锁定。这可能会导致在高并发写入场景下的性能瓶颈。
-
不支持外键约束和索引类型:Memory引擎不支持外键约束和复杂索引类型。它仅支持哈希索引和B树索引的一部分功能。这可能会限制一些数据完整性和查询优化的功能。
4. MERGE
MERGE引擎适用于需要将多个具有相同结构的表合并为一个逻辑表,并进行跨表查询的场景。它可以提供数据分散和查询灵活性,但不支持事务、索引和外键约束。请注意,由于其特殊性和限制性,MERGE引擎的使用应谨慎,并在具体场景中评估其适用性。
-
合并表功能:MERGE引擎允许将多个具有相同结构的MyISAM表合并为一个逻辑表。这意味着您可以在逻辑上将多个表视为一个表,并且可以通过对逻辑表执行查询来同时查询多个实际表的数据。
-
透明性:对于应用程序而言,使用MERGE表和操作合并表与操作普通表并没有明显区别。应用程序无需关注实际的表结构,只需要操作逻辑表即可。
-
数据分散:使用MERGE引擎可以将数据分散到多个物理表中。这在某些场景下可以提高查询性能,特别是在大型表或需要分片存储的场景中。
-
不支持事务:MERGE引擎不支持事务。它的操作是基于每个实际表的操作,而不是整个逻辑表的操作。因此,无法对MERGE表执行事务性操作。
-
不支持索引:MERGE引擎本身不支持创建索引。它依赖于实际表上的索引。如果需要索引支持,必须在实际表上创建索引。
-
不支持外键约束:MERGE引擎不支持外键约束。由于合并表可以包含多个实际表,且每个实际表可能具有不同的数据和约束,因此无法在逻辑层面强制执行外键关系。
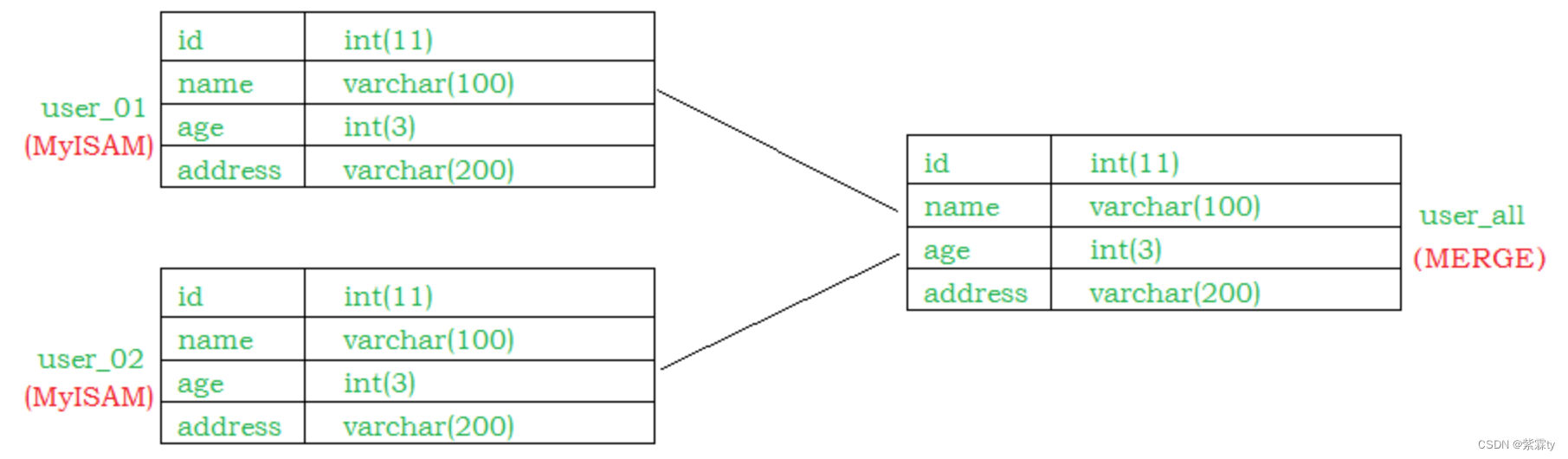
创建MERGE表:
create table order_1990(
order_id int ,
order_money double(10,2),
order_address varchar(50),
primary key (order_id)
)engine = myisam default charset=utf8;
create table order_1991(
order_id int ,
order_money double(10,2),
order_address varchar(50),
primary key (order_id)
)engine = myisam default charset=utf8;
create table order_all(
order_id int ,
order_money double(10,2),
order_address varchar(50),
primary key (order_id)
)engine = merge union = (order_1990,order_1991) INSERT_METHOD=LAST default charset=utf8;
4. MySQL中常见的存储引擎(InnoDB、MyISAM、MEMORY、MERGE和NDB Cluster)以及它们的主要使用场景:
-
InnoDB引擎:适用于大多数应用程序,特别是对事务支持、数据一致性和并发控制有要求的场景。适合用于在线事务处理(OLTP)系统,如电子商务网站、金融应用等。
-
MyISAM引擎:适用于读取频繁、并发写入较少的场景。适合用于静态或只读数据的存储,如新闻网站、日志记录等。不建议在需要事务支持或对数据完整性有严格要求的应用中使用。
-
MEMORY (Heap)引擎:适用于需要非常高的读写性能和临时数据存储的场景。适合用于缓存、会话数据、临时表等。由于数据存在于内存中,不适合存储长期持久的数据或对数据持久性有要求的应用。
-
MERGE引擎:适用于将多个具有相同结构的MyISAM表合并为一个逻辑表,并进行跨表查询的场景。适合用于分散数据到多个物理表中以提高查询性能的场景。
-
NDB Cluster引擎(MySQL Cluster):NDB Cluster引擎适用于分布式环境中的高可用性和高性能应用。它可以提供分片存储、自动分布和数据冗余,适用于需要水平扩展和高容错性的应用,如大规模Web应用、实时数据处理等。