近日,语音技术领域旗舰会议INTERSPEECH 2023公布了本届论文审稿结果,阿里巴巴达摩院语音实验室有17篇论文被大会收录。

01
论文题目:FunASR: A Fundamental End-to-End Speech Recognition Toolkit
论文作者:高志付,李泽瑞,王嘉明,罗浩能,石宪,陈梦喆,李亚滨,左玲云,杜志浩,肖彰宇,张仕良
论文单位:阿里巴巴集团
核心内容:本文开源了一个名为FunASR的开源语音识别工具包,旨在桥联学术研究和工业应用。FunASR提供了在大规模工业语料库上训练的模型,并能够在工业应用中部署这些模型。其旗舰模型Paraformer是一个非自回归的端到端语音识别模型,已在一个人工标准的普通话语音识别数据集上进行了训练,数据集包含约6万小时的语音。为了提高Paraformer的性能,我们在标准Paraformer骨干结构上增加了时间戳预测和热词定制功能。此外,为了方便模型部署,我们开源了一种基于前馈顺序记忆网络(FSMN-VAD)的语音活动检测模型和一种基于可控时间延迟变压器(CT-Transformer)的文本后处理标点符号模型,两者均在工业语料库上进行了训练。这些功能模块为构建高精度的长音频语音识别服务提供了坚实的基础。与其他在开放数据集上训练的模型相比,Paraformer表现出更为优异的性能。
论文预印版下载地址:
https://arxiv.org/abs/2305.11013
项目开源地址:
https://github.com/alibaba-damo-academy/FunASR

图示. a)Paraformer模型结构;b)Paraformer-TP时间戳模型结构;c)Paraformer-Contextual热词模型结构;
02
论文题目:An Enhanced Res2Net with Local and Global Feature Fusion for Speaker Verification
论文作者:陈亚峰,郑斯奇,王绘,程路遥,陈谦,祁家俊
论文单位:阿里巴巴集团,中国科学技术大学
核心内容:有效融合多尺度特征对于提高说话人识别性能至关重要。现有的大多数方法通过简单的操作,如特征求和或拼接,并采用逐层聚合的方式获取多尺度特征。本文提出了一种新的架构,称为增强式Res2Net(ERes2Net),通过局部和全局特征融合提高说话人识别性能。局部特征融合将一个单一残差块内的特征融合提取局部信号;全局特征融合使用不同层级输出的不同尺度声学特征聚合全局信号。为了实现有效的特征融合,ERes2Net架构中采用了注意力特征融合模块,代替了求和或串联操作。在VoxCeleb数据集上进行的一系列实验展现了ERes2Net识别性能的优越性。
论文预印版下载地址:
https://arxiv.org/pdf/2305.12838.pdf
项目开源地址:
https://github.com/alibaba-damo-academy/3D-Speaker

图示:增强式Res2Net结构示意图
03
论文题目:CAM++: A Fast and Efficient Network for Speaker Verification Using Context-Aware Masking
论文作者:王绘,郑斯奇,陈亚峰,程路遥,陈谦
论文单位:阿里巴巴集团
核心内容:在说话人识别领域中,主流的说话人识别模型大多是基于时延神经网络或者二维卷积网络,这些模型获得理想性能的同时,通常伴随着较多的参数量和较大的计算量。如何兼具准确识别和高效计算,是当前说话人识别领域的研究热点之一。因此我们提出高效的说话人识别模型CAM++。该模型主干部分采用基于密集型连接的时延网络(D-TDNN),每一层的输入均由前面所有层的输出拼接而成,这种层级特征复用可以显著提高网络的计算效率。同时,D-TDNN的每一层都嵌入了一个轻量级的上下文相关的掩蔽(Context-aware Mask,CAM)模块。CAM模块通过全局和段级的池化操作,提取不同尺度的上下文信息,生成的mask可以去除掉特征中的无关噪声。TDNN-CAM形成了局部-段级-全局特征的统一建模,可以学习到特征中更加丰富的说话人信息。CAM++前端嵌入了一个轻量的残差二维卷积网络,可以捕获更加局部和精细的频域信息,同时还对输入特征中可能存在的说话人特定频率模式偏移具有鲁棒性。VoxCeleb和CN-Celeb公开数据集上的实验结果显示,对比主流的ECAPA-TDNN和ResNet34模型,CAM++具有更高的识别准确率,同时在计算量和推理速度上有着明显的优势。
论文预印版下载地址:
https://arxiv.org/abs/2303.00332
项目开源地址:
https://github.com/alibaba-damo-academy/3D-Speaker

图示:CAM++模型结构示意图
04
论文题目:BAT: Boundary aware transducer for memory-efficient and low-latency ASR
论文作者:安柯宇,石宪,张仕良
论文单位:阿里巴巴集团
核心内容:最近,RNN-T由于其优越的识别性能和流式友好的特性受到越来越多的关注。然而,训练时大量的时间和计算资源开销限制了RNN-T的使用。此外,RNN-T倾向于访问更多的上下文以获得更好的性能,这导致了流式识别时更高的发射延迟(emission latency)。在本文中,我们提出了Boundary aware transducer(BAT),用于降低RNN-T训练时的显存开销和推理时的发射延迟。在BAT中,我们用CIF在线生成的对齐对RNN-T损失计算的lattice进行裁剪。CIF模块引入的额外计算很少,且可以与RNN-T模型联合优化。大量实验表明,与RNN-T相比,BAT显著减少了训练中的时间和内存消耗,并在流式ASR的推理中实现了良好的CER-latency trade-off。
论文预印版下载地址:
https://arxiv.org/abs/2305.11571

图示:左)所提出的BAT的模型结构图;右)BAT利用CIF提供的对齐信息裁剪RNN-T网格的示意图
05
论文题目:Accurate and Reliable Confidence Estimation Based on Non-Autoregressive End-to-end Speech Recognition System
论文作者:石宪,罗浩能,高志付,张仕良,鄢志杰
论文单位:阿里巴巴集团
核心内容:置信度估计是语音识别的下游任务之一,为识别结果提供准确的置信度数值是被许多应用所依赖的功能。在端到端语音识别系统中,为实现置信度预测功能往往在decoder之后引入一个估计模块,通过BCE loss的训练使其能够产生与decoder输入等长的置信度数值。上述方式存在的缺陷在于模型无法在输入文本的长度与标准文本不等时捕捉这种差距。
本文提出一种基于非自回归端到端模型Paraformer的置信度估计方案(cif-aligned confidence estimation module,CA-CEM),利用Paraformer中Predictor产生的与输出文本等长的acoustic embedding通过新引入的aligner模块与decoder输出进行注意力,建立起输入文本与标准文本之间的联系,从原理上规避了当输入文本存在插入与删除错误时置信度估计不可靠的缺陷。在Aishell-1的两个置信度估计测试集中,CA-CEM在多个指标上超越了基线AED-CEM模型。
论文预印版下载地址:
https://arxiv.org/abs/2305.10680

(a)Paraformer模型结构;(b)基线AED-CEM模型结构,通过引入estimator模块实现与decoder输出等长的置信度序列;(c)本文提出的CA-CEM模型结构,通过aligner模块进行输入文本与理想文本之间的注意力,从而实现了准确且可靠的置信度估计;
06
论文题目:MMSpeech: Multi-modal Multi-task Encoder-Decoder Pre-training for Speech Recognition
论文作者:周晓欢,王嘉明,崔泽宇,张仕良,鄢志杰,周靖人,周畅
论文单位:阿里巴巴集团
核心内容:本文提出了一种新颖的多模态多任务编码器-解码器预训练框架(MMSpeech),旨在使用无监督的语音和文本数据来提高中文语音识别(ASR)的准确性。语音-文本联合预训练的主要困难在于语音和文本模态之间的显著差异,特别是对于中文语音和文本。与其他拥有字母写作系统的语言(例如英文)不同,中文使用表意文字系统,其中字符和声音之间没有紧密的映射关系。
为此,本文提出将音素模态引入到预训练中,从而帮助获取中文语音和文本之间的模态不变信息。本文提出的MMSpeech预训练框架,总共包括五个自监督/有监督任务,同时利用了语音和文本数据。具体而言,本文利用无标签的语音和文本数据,引入了自监督语音到编码(S2C)和音素到文本(P2T)任务。为了让编码器可以更好地学习语音表征,本文引入了自监督掩码语音预测(MSP)和有监督音素预测(PP)任务,以学习语音到音素的映射。此外,本文还额外引入了下游的有监督语音到文本(S2T)任务,这可以进一步提高预训练性能,帮助模型在没有微调的情况下,也可以实现不错的识别效果。在AISHELL1上的实验表明,本文提出的方法相比其他预训练方法,性能相对提高了40%以上。
论文预印版下载地址:
https://arxiv.org/abs/2212.00500

图 1. MMSpeech整体结构图。其中的S2T任务用于最终的语音识别,其余的任务用于辅助预训练。蓝线和红线分别表示语音和文本数据流。
07
论文题目:Personality-aware Training based Speaker Adaptation for End-to-end Speech Recognition
论文作者:谷悦,杜志浩,张仕良,陈谦,韩纪庆
作者单位:阿里巴巴集团,哈尔滨工业大学
核心内容:现实场景中训练与测试的不匹配会严重影响语音识别系统的性能,自适应方法可以缓解由上述不匹配导致的识别性能下降问题。但由于成本控制和隐私保护,充足的带标注的目标说话人数据很难获取。考虑到用于训练语音识别模型的数据规模较大并且包含许多说话人,很可能训练集包含一些和目标说话人的声学特性相似的语句,这些语句可以作为目标说话人数据的补充,用于对通用的语音识别系统进行说话人自适应,也就是个性化自适应。
因此,本文提出基于个性化声学先验的模型自适应(Personality-Aware Training,PAT)方法及其两种嵌入表示提取器(Embedding Extractor)实现方法。UPAA首先训练两种声学特性提取器:说话人嵌入表示提取器(Speaker Embedding Extractor) 和韵律嵌入表示提取器(Prosody Embedding Extractor),然后引入对比的思想,对比锚点和训练样本的声学特性嵌入表示的相似性,加强与锚点具有相似声学特性的训练样本的损失来微调语音识别模型。实验结果表明在开源数据MagicData上,相较于基线系统,本文提出的PAT方法在使用10分钟伪标签和真实标签自适应数据在CER指标上分别实现6.35%和11.86%的相对改进。
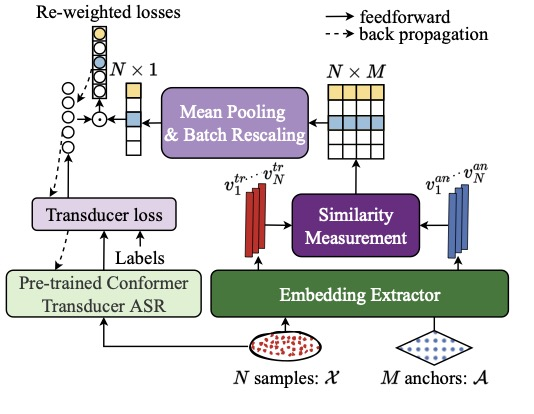
图示:所提出的PAT自适应训练框架
08
论文题目:Semantic VAD: Low-Latency Voice Activity Detection for Speech Interaction
论文作者:史莫晗,苏钰淳,左玲云,陈谦,张仕良,张结,戴礼荣
论文单位:阿里巴巴集团,中国科学技术大学,天津大学
核心内容:在语音交互场景下,语音活动检测(Voice Activity Detection, VAD)常被用作前端来对长音频进行切分。然而,传统的VAD算法通常需要等待的尾部静音达到预设的阈值时间后才进行分割,导致延迟较高,影响用户体验。
因此,本文提出了一种语义VAD方法进行低延迟切分。与现有方法不同的是,在语义VAD中增加了帧级标点符号预测任务;另外,除了常用的语音和非语音二分类之外,还将人工设定的尾部端点纳入VAD分类的类别中;为了增强模型的语义建模能力,我们在还在损失函数中加入了语音识别(Automatic Speech Recognition, ASR)损失进行辅助训练。在内部数据集上的实验结果表明,与传统的VAD方法相比,该方法降低了53.3%的平均延迟,而对于下游的语音识别任务并没有显著的性能退化。
论文预印版下载地址:
https://arxiv.org/abs/2305.12450
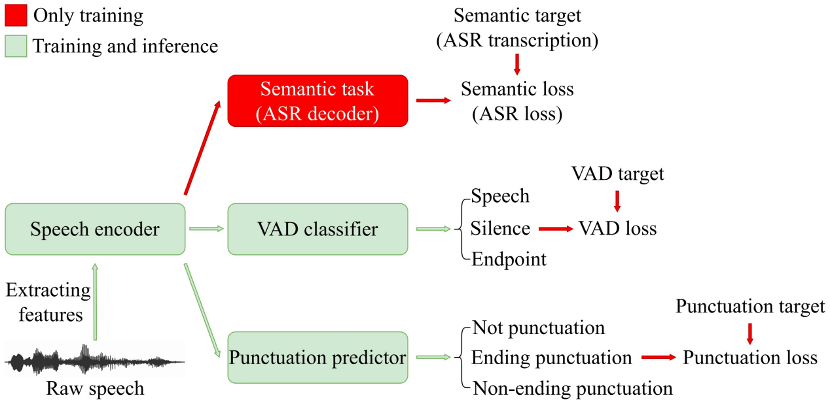
图示:论文提出的semantic VAD的示意图
09
论文题目:CASA-ASR: Context-Aware Speaker-Attributed ASR
论文作者:史莫晗,杜志浩,陈谦,俞帆,李泱泽,张仕良,张结,戴礼荣
作者单位:阿里巴巴集团,中国科学技术大学
核心内容:说话人相关语音识别的目标是解决多说话人场景下“谁说了什么”的问题。原有的端到端(End to End, E2E)SA-ASR方法由于缺乏对上下文信息的感知而表现不佳,因此本文基于E2E SA-ASR提出了一种带有上下文感知的SA-ASR(Context-Aware Speaker-Attributed ASR, CASA-ASR)方法。具体而言,在CASA-ASR中,使用上下文文本编码器来整合整个语句的语义信息,并使用上下文相关打分器,通过与上下文的说话人进行对比来对说话人的可辨别性进行建模。此外,为了充分利用上下文建模能力,进一步提出了两阶段解码策略,从而获得更好的识别性能。
在AliMeeting语料库上的实验结果表明,所提出的方法在说话人相关字错误率(Speaker Dependent Character Error Rate, SD-CER)指标优于E2E SA-ASR方法,达到了较好的性能。
论文预印版下载地址:
https://arxiv.org/abs/2305.12459

图示:所提出的CASA-ASR的整体结构
10
论文题目:Rethinking the visual cues in audio-visual speaker extraction
论文作者:李俊杰,葛檬,潘泽煦,曹瑞,王龙标,党建武,张仕良
论文单位:阿里巴巴集团,天津大学
核心内容:音视频说话者提取(AVSE)算法利用并行视频录制来探索两个视觉线索,即说话者身份和同步。由于视觉线索对抗声学噪声的稳健性,AVSE相比仅使用音频的算法具有更好的性能。然而,AVSE中的视觉前端通常是从预训练模型的某个部分中提取的,或者是端到端训练的,因此不清楚从每个视觉线索中学习了哪些信息,以及学习了多少信息。
因此,如何更有效地利用视觉线索仍然是一个未解决的问题。我们提出了两种不同的训练策略来解耦学习两个视觉线索。实验结果表明,两个视觉线索都是有用的,而同步线索作用更为重要。我们还提出了一个更可解释的模型,称为解耦音视频说话者提取模型(DAVSE),以利用两个视觉线索。
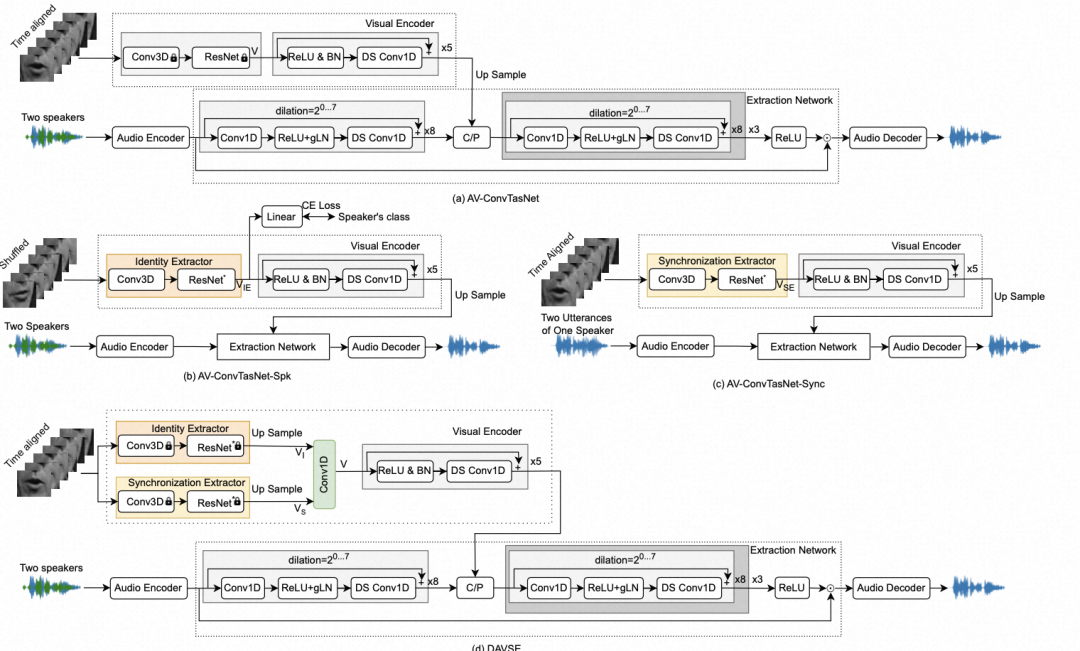
图示:所提出的音视频说话者提取模型
11
论文题目:BA-SOT: Boundary-Aware Serialized Output Training for Multi-Talker ASR
论文作者:梁宇颢,俞帆,李泱泽,郭鹏程,张仕良,陈谦,谢磊
论文单位:阿里巴巴集团,西北工业大学
核心内容:最近提出的序列化输出训练(SOT)通过生成由一个特殊标记分隔的说话人转录,简化了多说话人自动语音识别(ASR)。然而频繁的说话人切换会使说话人变化预测变得困难。为了解决这个问题,我们提出了边界感知序列化输出训练(BA-SOT),它通过说话人切换检测任务和边界约束损失明确地将边界知识纳入解码器。
我们还引入了一个两阶段的连接主义时间分类(CTC)策略,使用字符级的SOT CTC恢复时间背景信息。除了常用的字符错误率(CER),我们还引入了句子相关的字符错误率(UD-CER)来进一步衡量说话人切换预测的精度。与原始SOT相比,BA-SOT的CER/UD-CER相对降低了5.1%/14.0%,利用预训练的ASR模型作为BA-SOT模型的初始化,可以将CER/UD-CER进一步降低8.4%/19.9%。
论文预印版下载地址:
https://arxiv.org/abs/2305.13716
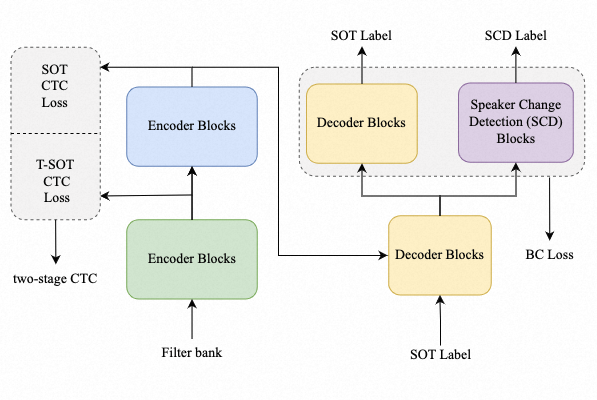
图示:所提出的BA-SOT结构示意图
12
论文题目:Adapter-tuning with Effective Token-dependent Representation Shift for Automatic Speech Recognition
论文作者:黄殿文,张冲,张芮熙,马煜坤,Trung Hieu Nguyen,倪崇嘉,赵胜奎,陈谦,王雯,庄永祥,马斌
论文单位:阿里巴巴集团,南洋理工大学,新加坡国立大学
核心内容:语音自监督预训练模型可有效提升模型在语音低资源任务上的效果。但是,微调整个模型计算量较大并且无法扩展到多任务,例如个性化语音识别系统。最近有些学者尝试训练 adapter 来解决这个问题,但由于在语音相关任务上存在任务域可迁移性的问题,他们训练的 adapter 效果始终无法达到全模型微调的效果。
因此我们提出引入一种轻量化简单有效的Token-dependent Bias Adapter-tuning (TBA) 方法来增强语音识别中传统的adapter tuning的效果,模型结构对比见图 1。如图 2 所示,TBA通过在预训练模型中间特征层中加入一种特定标记表征转移偏差,可更好地将预训练模型网络中冻结部分隐层特征映射到目标任务域。我们将提出的TBA这种轻量化方法在10 小时和100小时Librispeech数据集上实验验证,在仅用10%可训练参数的情况下,TBA和HuBERT全模型微调效果相对差距缩小至3%;并在仅用 15%可训练参数的情况下,在dev-clean和 test-clean测试集上效果超过 HuBERT全模型微调的效果。
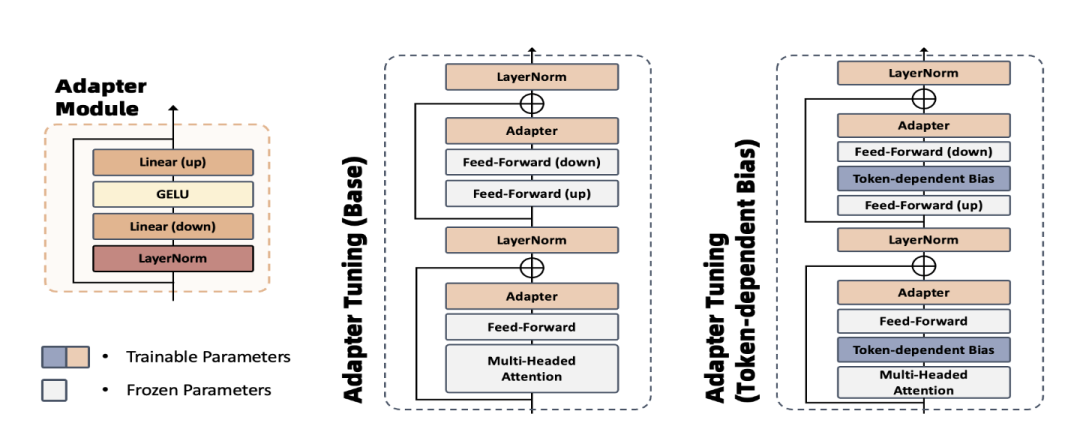
图 1. Token-dependent Bias Adapter-tuning 和传统 Adapter Tuning模型结构对比

图 2. 本图展示了TBA中通过引入与标记相关的偏差,由线性全连接预测层来根据特定标记计算权重的偏差,这里的偏差b是可训练矢量, α是每个特定标记t通过预测得到的权重。
13
论文题目:Dual Acoustic Linguistic Self-supervised Representation Learning for Cross-Domain Speech Recognition
论文作者:杨钊,黄殿文,张冲,伏晓,姜锐,惠维,马煜坤,倪崇嘉,庄永祥,马斌,赵季中
论文单位:阿里巴巴集团,西安交通大学,南洋理工大学
资源链接:
https://github.com/Mashiro009/DKU_WWS_MISP
核心内容:语音文本联合表征学习模型利用经过充分预训练的声学和语言学表征,可以提升跨模态语音识别任务的性能。然而,对于带有口音和噪声等场景下,基于语音文本联合表征学习的语音识别模型的潜力仍未被充分探索。
为了解决这一问题,我们提出了一种端到端的语音文本联合表征学习模型,名为Dual-w2v-BART(详细架构如图 1 所示)。我们的Dual-w2v-BART模型通过在解码器中利用交叉注意机制,并利用配对的语音-文本双输入,将来自wav2vec2.0的声学预训练表征和BART模型的语言学信息有效地结合。为了增强模型在口音和噪声方面的鲁棒性,我们提出了一种以文本为中心的表征一致性学习模块,有助于在表示相同内容的不同模态输入之间更好地增强相似性。在带有口音和噪声场景下的语音识别任务上实验显示,与基准模型和其他模型相比,Dual-w2v-BART有效地降低了识别错误率,展示了方法的有效性。
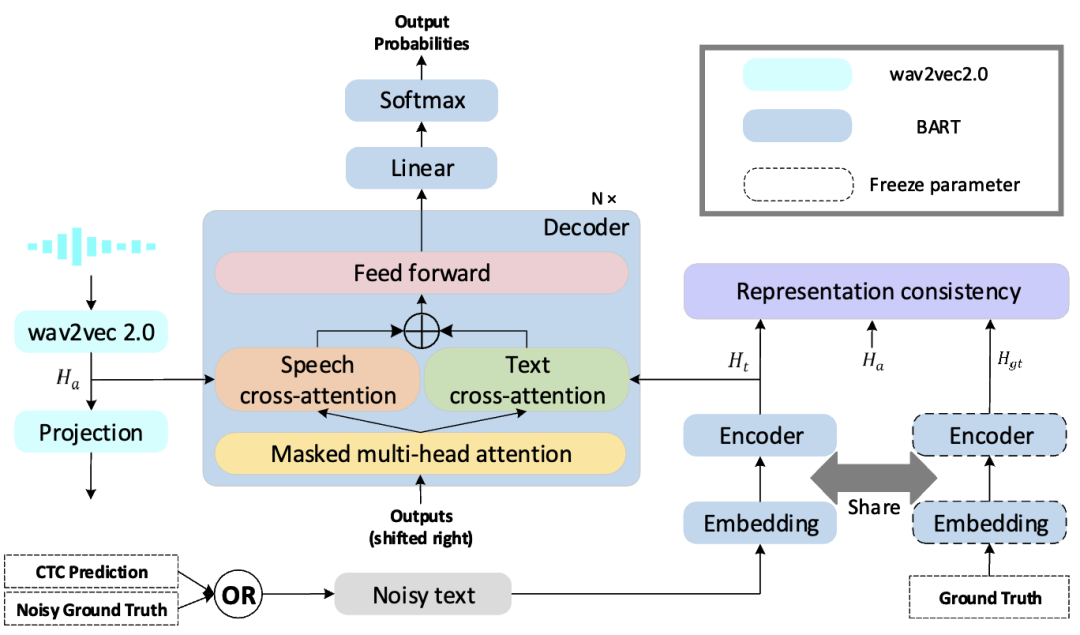
图 1. Dual-w2v-BART模型由wav2vec2.0 作为声学编码器,BART encoder 作为文本编码器和一个解码器,通过两个平行交叉注意力模块连接组成。通过使用表征一致性单元(representation consistency unit)和基准值来增加语音和文本表征之间的相似度。同时我们还设计了一种新的采样训练策略来减轻由于领域迁移导致的CTC预测中间结果不准确带来的影响。
14
论文题目:Dual-Memory Multi-Modal Learning for Continual Spoken Keyword Spotting with Confidence Selection and Diversity Enhancement
论文作者:杨钊,黄殿文,李玺喆,张冲,姜锐,惠维,马煜坤,倪崇嘉,赵季中,马斌,庄永祥
论文单位:阿里巴巴集团,西安交通大学,南洋理工大学
核心内容:让语音唤醒(KWS)模型从不断变化的环境中具有持续学习(CL)的能力具有极高的价值,同时也是一个具有挑战性的问题。语音唤醒模型需要同时处理不同人的语音信号声学特性的变化和神经网络灾难性遗忘问题。
为了应对以上问题,我们提出了一个基于回放式持续学习的新型语音唤醒模型(DM3),该模型使用双内存多模态结构(详见图 1)以提高其泛化性和鲁棒性。我们的方法利用短期和长期模型以自适应方式学习近期知识和长期知识,同时还利用了多种语音扰动的一致性,以提高多模态结构的鲁棒性。此外,我们引入了一个利用置信度分数对训练样本进行排序的类别平衡选择策略。实验结果证明,在类别递增学习和领域递增学习的语音唤醒设置中,我们的 DM3 模型优于基线模型。
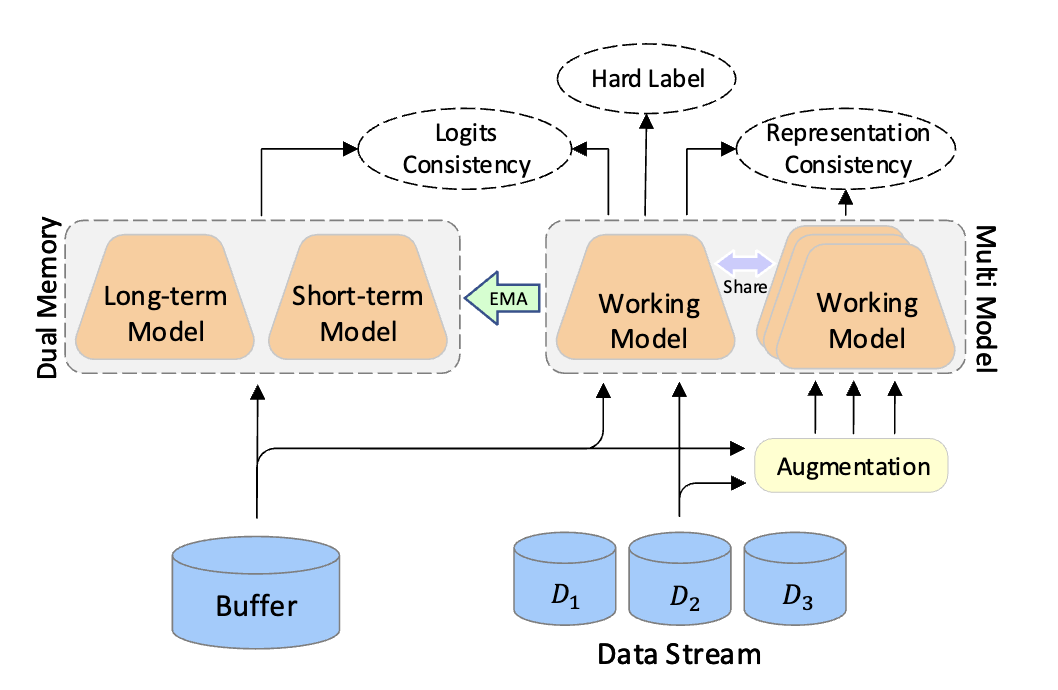
图 1. DM3模型结构示意图。DM3是一个基于连续学习的语音唤醒模型,带有置信度选择和多样性增强模块,由记忆缓冲区、双内存组件和多模态组件组成。
15
论文题目:A Unified Recognition and Correction Model under Noisy and Accent Speech Conditions
论文作者:杨钊,黄殿文,张冲,姜锐,惠维,马煜坤,倪崇嘉,赵季中,马斌, 庄永祥
论文单位:阿里巴巴集团,西安交通大学,南洋理工大学
核心内容:在传统的级联式语音识别系统中,通常使用语音识别模型加后处理模块(如文本纠错,ITN等),然而这种级联式的系统忽略了语音转文字和文本纠错之间的强相关性。
受利用大规模文本数据改进大语言模型建模的研究启发,我们提出了一种统一的语音识别和文本纠错框架(UAC),将语音识别和文本纠错耦合起来,以捕捉更丰富的语义信息,提高语音识别的性能。UAC框架通过在共享编码器中融合单模态映射向量,建立语音表征和文本表征之间的显性联系。此外,所提出的框架灵活适用于同步或异步变体,并可以利用模态和任务标签,来增强其对异构输入的适应性。
详细UAC框架示意图见图 1。在带有口音和噪声场景下语音数据集上的实验结果显示,我们提出的 UAC 框架的识别率相对传统级联式基准系统有明显提升。
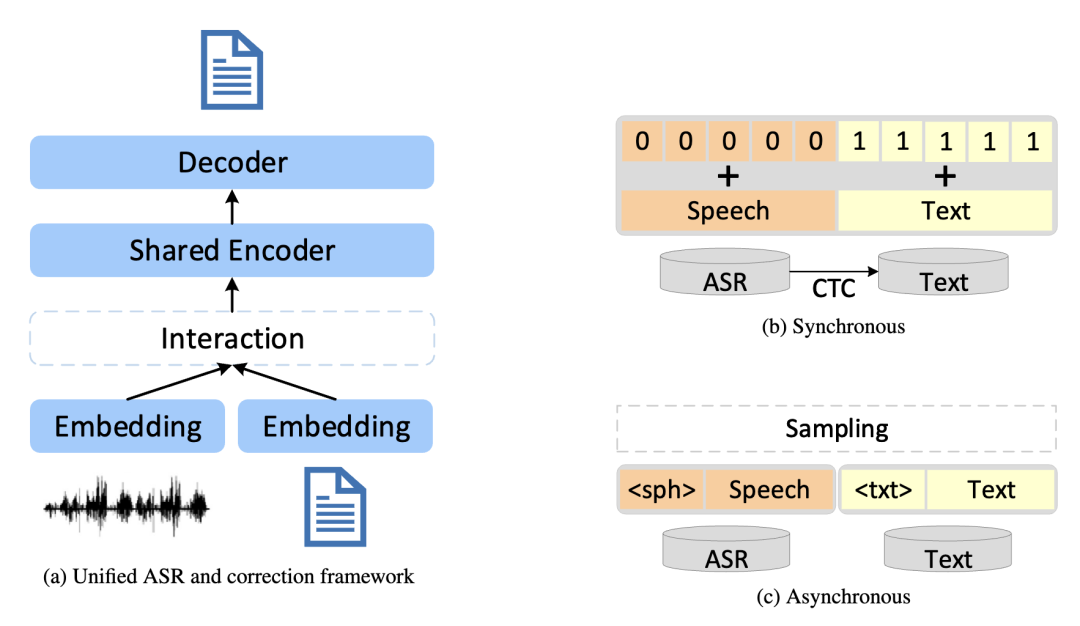
图 1. UAC框架示意图。(a) 统一的 ASR 和文本纠错框架包含四个基本模块:语音特征映射、文本特征映射、共享语音和文本编码器、解码器。(b) 同步模型。 (c) 异步模型。
16
论文题目:ACA-Net: Towards Lightweight Speaker Verification using Asymmetric Cross Attention
论文作者:叶家祺, Tuan Truong, 黄殿文, 张冲, 马煜坤, Trung Hieu Nguyen, 倪崇嘉, 赵胜奎, 庄永祥, 马斌
论文单位:阿里巴巴集团,南洋理工大学
核心内容:ACA-Net是一种轻量级的基于全局上下文感知信息和说话人特征的说话人辨识模型。ACA-Net利用非对称交叉注意力机制 (Asymmetric Cross Attention,即 ACA) 来代替常用的时间池化层,模型示意图见下图。ACA能够通过对key和value 大矩阵进行快速查询,将可变长度序列提取为较小的固定大小的隐层序列。
在ACA-Net中,我们使用ACA构建多层聚合模块(Multi-Layer Aggregation),从可变长度输入生成固定大小的单位向量。通过全局注意力模块,ACA-Net可以作为一个能自适应时序长短变化的高效全局特征提取器。现有说话人辨识模型使用固定函数在时间维度上进行池化,这可能会丢失一部分非平稳信号信息。我们在WSJ0-1talker 数据集上的实验表明,在仅使用 20% 的模型参数量的情况下,ACA-Net较目前最好的基线模型效果相对提升5%。
论文预印版下载地址:
https://arxiv.org/abs/2305.12121
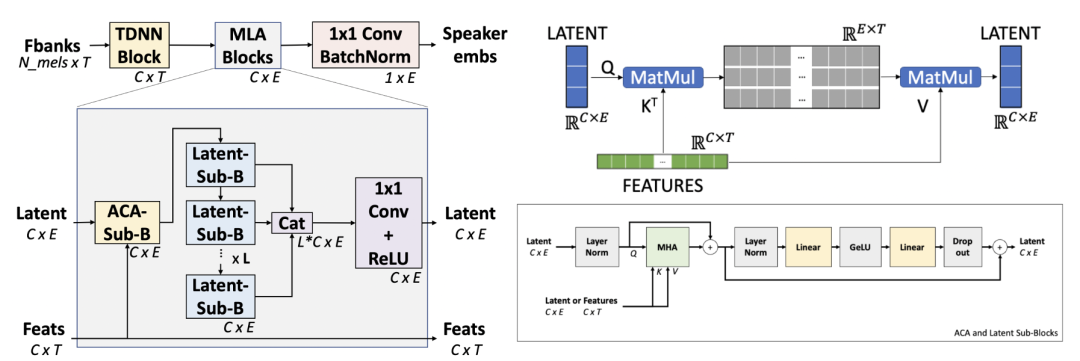
图 1. ACA-Net 模型示意图。
17
论文题目:Small Footprint Multi-channel Network for Keyword Spotting with Centroid Based Awareness
论文作者:黄殿文,肖扬,叶家祺,杨钊,田彪,傅强,庄永祥,马斌
论文单位:阿里巴巴集团,南洋理工大学,西安交通大学
核心内容:通常小型语音唤醒模型在高噪音和远场的场景下的识别能力下降较大。这是因为模型在设计上受到了一些计算资源的限制,例如较小的模型因减少参数量而降低了模型的复杂度,导致在处理带噪和远场音频上有明显的损失。我们在多麦克风阵列唤醒词识别模型提出了一个新型多通道模型 ConvMixer。模型使用卷积神经网络(CNN)与线性混合单元来实现局部-全局依赖关系的表征。这种改进使用了少量的模型参数有效提升了模型效果,以及通过模型对多通道的音频特征做出全局计算分析提高了模型对噪音的鲁棒性。
此外,我们提出了一种基于相似度的端到端训练方法,使用模型隐层特征和唤醒词相对中心距离信息来提减低模型的误判。我们使用来自2021年MISP挑战赛的真实噪声远场数据进行实验,ConvMixer较目前最好的语音唤醒模型(如Minimum Variance Distortionless Response波束形成的Keyword Transformer-1和MatchboxNet)实现了state-of-the-arts的结果。我们的最佳得分0.126 优于大型模型如 3D-ResNet 的得分 0.122,在大小方面更为小型化,仅使用了473K参数量而非其他通用模型的13M 参数量。
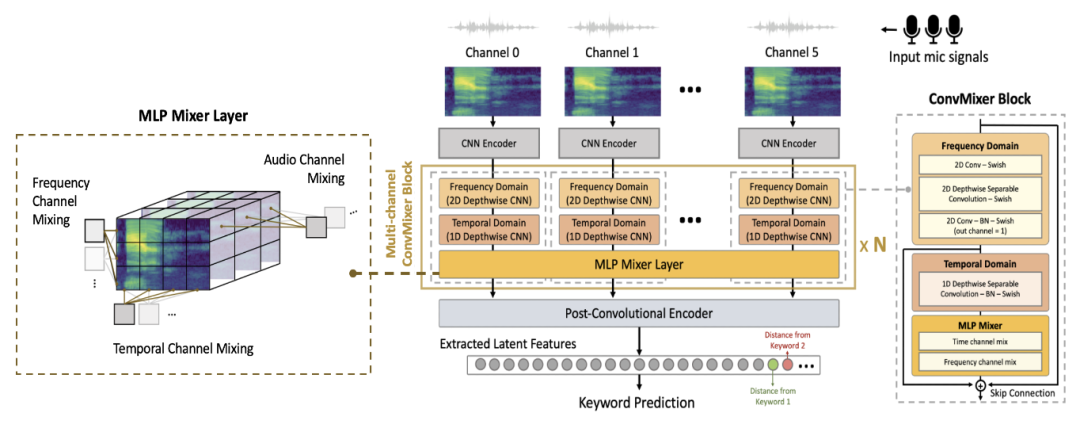
图 1. Multi-channel ConvMixer with Centroid Awareness(6通道)模型示意图。使用N=4的ConvMixer Block去构建模型,模型读取6个通道的语音输入来计算出唤醒词的预测值。