ES默认的analyzer(分词器),对英文单词比较友好,对中文分词效果不好。不过ES支持安装分词插件,增加新的分词器。
1、如何指定analyzer?
默认的分词器不满足需要,可以在定义索引映射的时候,指定text字段的分词器
例子:
PUT /article
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "smartcn"
}
}
}
}
只要在定义text字段的时候,增加一个analyzer配置,指定分词器即可,这里指定的分词器是smartcn,后面会介绍怎么安装smartcn插件。
分词器种类
目前中文分词器比较常用的有:smartcn和ik两种, 下面分别介绍这两种分词器。
smartcn分词器
smartcn是目前ES官方推荐的中文分词插件,不过目前不支持自定义词库。
插件安装方式:
{ES安装目录}/bin/elasticsearch-plugin install analysis-smartcn
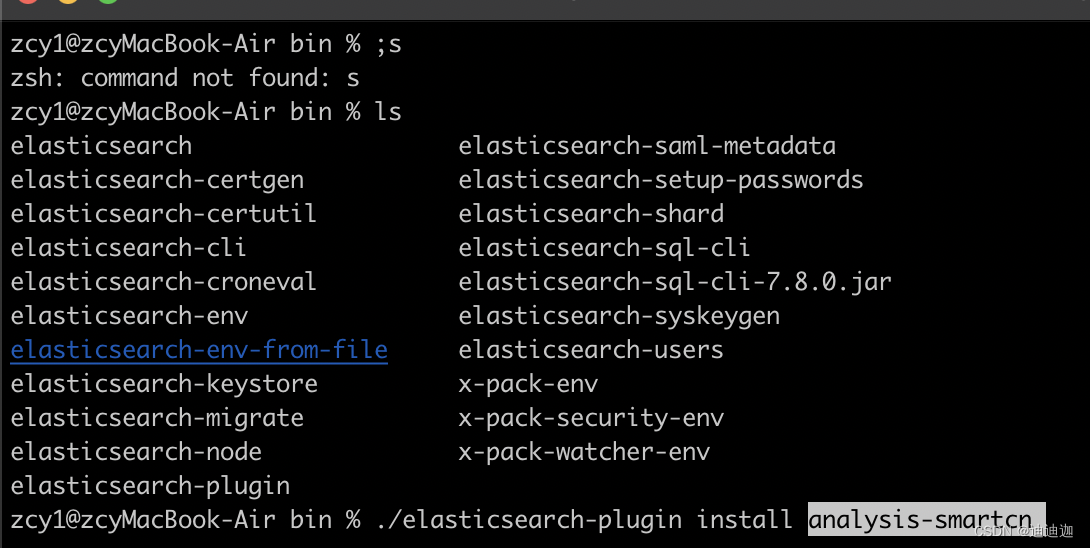
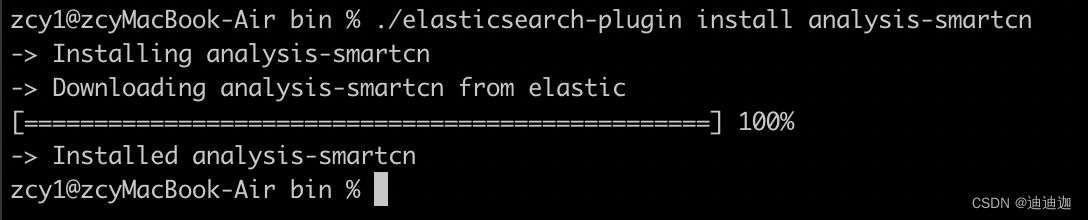
安装完成后,重启ES即可 一定要重启不然找不到分词器!!!。
smartcn的分词器名字就叫做:smartcn
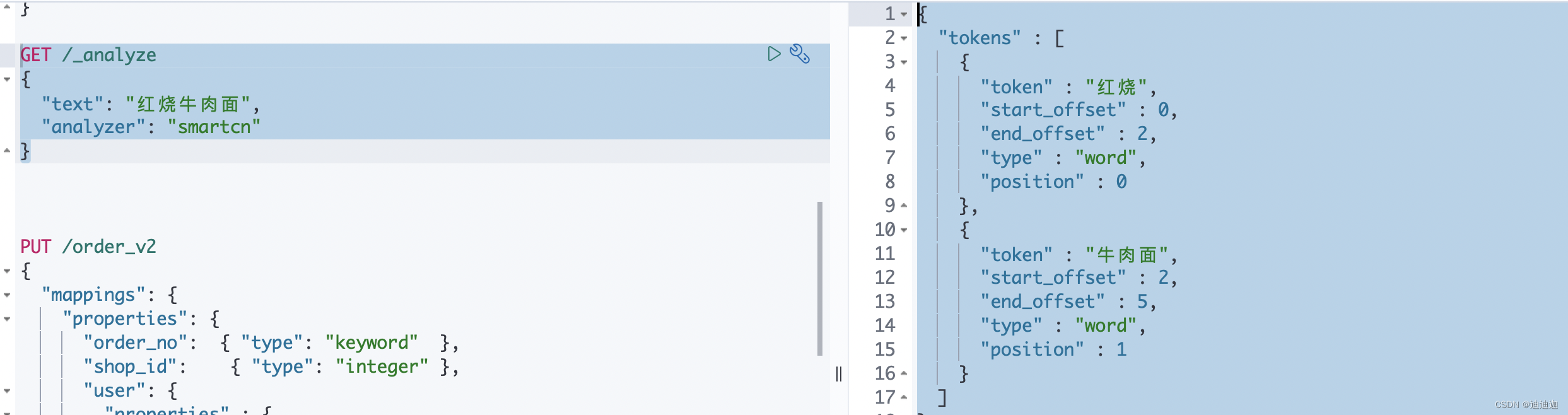
smartcn中文分词效果
GET /_analyze
{
"text": "红烧牛肉面",
"analyzer": "smartcn"
}
{
"tokens" : [
{
"token" : "红烧",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "牛肉面",
"start_offset" : 2,
"end_offset" : 5,
"type" : "word",
"position" : 1
}
]
}
ik分词器
ik支持自定义扩展词库,有时候分词的结果不满足我们业务需要,需要根据业务设置专门的词库,词库的作用就是自定义一批关键词,分词的时候优先根据词库设置的关键词分割内容,例如:词库中包含 “上海大学” 关键词,如果对“上海大学在哪里?”进行分词,“上海大学” 会做为一个整体被切割出来。(需要重启es)
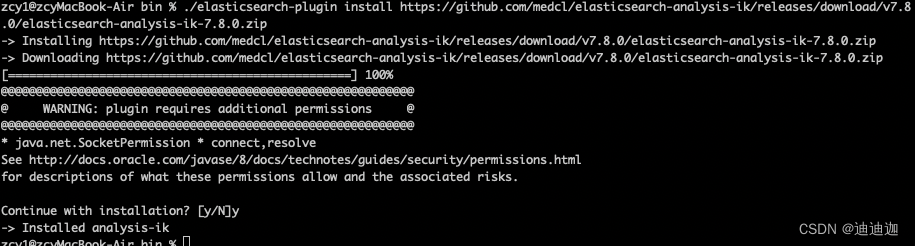
安装ik插件:
// 到这里找跟自己ES版本一致的插件地址
https://github.com/medcl/elasticsearch-analysis-ik/releases
我本地使用的ES版本是7.8.0,所以选择的Ik插件版本地址是:
https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.8.0/elasticsearch-analysis-ik-7.8.0.zip
安装命令
{ES安装目录}/bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.8.0/elasticsearch-analysis-ik-7.8.0.zip
ik中文分词效果
ik分词插件支持 ik_smart 和 ik_max_word 两种分词器
ik_smart - 粗粒度的分词
ik_max_word - 会尽可能的枚举可能的关键词,就是分词比较细致一些,会分解出更多的关键词
例1:
GET /_analyze
{
"text": "上海人民广场麻辣烫",
"analyzer": "ik_max_word"
}
输出:
{
"tokens" : [
{
"token" : "上海人",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "上海",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "人民",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "广场",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "麻辣烫",
"start_offset" : 6,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "麻辣",
"start_offset" : 6,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "烫",
"start_offset" : 8,
"end_offset" : 9,
"type" : "CN_CHAR",
"position" : 6
}
]
}
例2:
GET /_analyze
{
"text": "上海人民广场麻辣烫",
"analyzer": "ik_smart"
}
输出:
{
"tokens" : [
{
"token" : "上海",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "人民",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "广场",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "麻辣烫",
"start_offset" : 6,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 3
}
]
}