目录
1 关于:re / regex / regular expression
1.1 什么是正则表达式
1.2 在python中安装正则模块
1.2.1 python里一般都默认安装了 re正则模块,可以先查看确认下
1.2.2 如果没有安装,可以按照正则库regex, pip install regex
1.3 在python中导入 re : import re
2 正则表达式的相关符号
2.1 行定位符
2.2 元字符 (注意是 反斜杠\)
2.3 量词 \次数 \限定符号 : * + ? {}
2.4 字符类/字符集合: 中括号 [ ]
2.5 排除字符 [^ ]
2.6 选择字符 |
2.7 转义字符 反斜杠 \
2.8 分组符号 ()
2.9 正则表达式需要用引号"" 包裹起来
2.9.1 如果有特殊符号,表达式前还要注意加 r
2.9.2 无论是正则字符串,还是目标字符串,都记得要加 r
2.10 贪婪模式 / 非贪婪模式
3 正则表达式的方法
3.1 匹配和查找相关
3.2 相同点和差别
3.2.1 返回正则对象
3.2.2 不同的查找方法
3.2.3 不同的查找方法
3.2.4 不同的分割方法
3.3 re.match()
3.3.1 re 里大多数人接触第一个方法
3.3.2 MatchObject 对象的属性/方法
3.3.3 re.match() 和 ^ 其实有点意义重复
3.3.4 使用 re.match() 来测试,数量的不同写法(可以等价)
3.3.5 所以一般返回 re.match() 即可,而不直接返回 re.match().group() ,原因就很明显了
3.3.6 测试正则 re.match()
3.4 re.search()
3.5 Flags标志
3.6 没有 re.find() ,只有 re.findall()
3.7 re.findall()
3.8 re.sub()
3.9 re.finditer
3.10 re.compile()
3.11 re.split()
1 关于:re / regex / regular expression
1.1 什么是正则表达式
- regular expression 正则表达式
- 以下的各种名字都是指的正则表达式
- re
- regex
- regular expression
- 正则表达式是计算机科学的一个概念
- 是一个跨多种编程语言的语言格式,不同的语言里应该都有对应的正则库,而正则的规则是基本相同的。(我猜的 ^ ^ )
1.2 在python中安装正则模块
1.2.1 python里一般都默认安装了 re正则模块,可以先查看确认下
- 查看 regex模块
- pip list
- pip show regex

1.2.2 如果没有安装,可以按照正则库regex, pip install regex
- 导入 re 模块
- 错误写法: pip install re
- 正确写法: pip install regex
1.3 在python中导入 re : import re
- 导入 re 模块
- 模块其实可以认为是一个 .py文件
- 正确写法: import re
2 正则表达式的相关符号
2.1 行定位符
用来描述字符串的边界,1行的边界?全部字符串的边界把? 可以叫做 字符串整体定位符?^ ^
^ #表示字符串开头
$ #表示字符串结尾
2.2 元字符 (注意是 反斜杠\)
\w #匹配 字母,数字,下划线等,还有各自文字,比如汉字
\W #^w 非w
\s # 匹配空格,换行,tab 等几种看不见的内容 也就是:空格 \n \t
\S #^s 非s
\b #begin 单词的开始的意思 如 \bw 匹配单词(不是整个字符串)开始的字母,数字,下划线等,所以 \b不同于 ^
\B #匹配非单词边界,即若某字串出现的单词字串未以空格分割,则不能匹配 ?
\d # 匹配数字
. # 任意字符
三种括号也是有特殊意义的
() #匹配方括号的每个字符,比如(fruit|food)s 表示 fruits|foods
[] # 匹配方括号的任一个字符,比如 [abc] 表示 a,b ,c 都可以
{} # 限定次数符号,看下面
2.3 量词 \次数 \限定符号 : * + ? {}
量词,缺省值
- 如果没有量词,默认就是1个
- \d # 比如\d匹配数字的;量词不写,默认就是1个的意思
其他量词限定
* # 匹配前面的字符0次/无限次
+ # 匹配前面的字符1次/无限次
? # 匹配前面的字符0次/1次
- 但是这里有点注意,?表示量词时是0|1个,
- 常用于 .*? 这种非贪婪模式
- 但是放在其他量词后面表示,非贪婪匹配的意思,尽可能少的匹配
{n} # 匹配前面的字符n次
{n,} # 匹配前面的字符至少n次
{n,m} # 匹配前面的字符 最少n次,最多m次, n-m次之间的都符合
e.g
^/d{8} #匹配8个数字
.*s #非贪婪匹配任意个数字
2.4 字符类/字符集合: 中括号 [ ]
[abcd] # 匹配abcd中的任意一个都可以
[12345] # 匹配1-5中的任意一个都可以
[0-9] # 匹配任意一个数字,等同于\d
[a-z0-9A-Z] # 匹配所有英文字母,数字,几乎等同\w 是\w的子集(不含汉字等)
2.5 排除字符 [^ ]
关键字 ^
/W # 相当于/^w,但是写法不对,必须写在中括号里 [^] 写在外面还是表示字符串开始
[^a-zA-Z] # 相当于非英文字母以外的其他任意字符
2.6 选择字符 |
选择
条件选择 | 表示or的意思
e.g.
^\d{5}|^\d{6}
2.7 转义字符 反斜杠 \
- 转义字符
- 把 普通字符变成特殊意义的字符, n 转成 \n 换行符
- 把 特殊字符变成普通字符, \* 表示 普通字符 * \. 表示 普通字符 .
2.8 分组符号 ()
(fruit|food)s #表示 fruits|foods
([abc]{1,3}){3} #表示 [abc]1到3个,然后再来3个,一会试试
2.9 正则表达式需要用引号"" 包裹起来
2.9.1 如果有特殊符号,表达式前还要注意加 r
- 比如一般的
- ".*?"
- 实际使用时, 如果包含特殊符号,记得使用 r (rawdata)
- r"https://movie.douban.com/apex"
2.9.2 无论是正则字符串,还是目标字符串,都记得要加 r
- 正则字符串
- 目标字符串,
- 都可以加r 表示 不要转义,取原始字符串的意思
2.10 贪婪模式 / 非贪婪模式
贪婪模式
匹配符合条件的最多的字符数
非贪婪模式
匹配符合条件的最少的字符数
非贪婪匹配,如果一直到末尾,往往会匹配一个尽量少的字符串=none 空字符串
?表示量词时是0|1个,但是放在其他量词后面表示,非贪婪匹配的意思,尽可能少的匹配
- .*?
- *?
- ??
- +?
- {n,m}?
例子1:
#E:\work\FangCloudV2\personal_space\2learn\python3\py0005.txt
# re相关
import re
print(re.match(r"aa\d+","aa2323")) #会尽可能多的去匹配\d
print(re.match(r"aa\d+?","aa2323")) #尽可能少的去匹配\d
例子2
#E:\work\FangCloudV2\personal_space\2learn\python3\py0005.txt
# re相关
import re
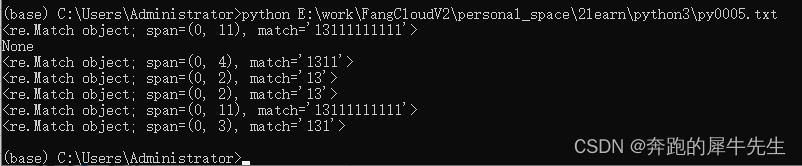
get1 = re.match(r'1[35678]\d{9}','13111111111')
print (get1)
get1 = re.match(r'1[35678]\d{9}','121111111111')
print (get1)
get1 = re.match(r'1[35678]\d{2}','13111111111')
print (get1)
get1 = re.match(r'1[35678]','13111111111')
print (get1)
get1 = re.match(r'1[35678]?','13111111111')
print (get1)
get1 = re.match(r'1[35678]\d{1,9}','13111111111')
print (get1)
get1 = re.match(r'1[35678]\d{1,9}?','13111111111')
print (get1)
3 正则表达式的方法
3.1 匹配和查找相关
- re.match()
- re.search()
- re.findall()
- re.finditer()
- re.sub()
- re.compile()
- re.split()
3.2 相同点和差别
3.2.1 返回正则对象
- re.compile() # 返回一个正则对象
- 其他的方法都返回, MatchObject 对象
- 要么返回列表,可迭代对象
3.2.2 不同的查找方法
- re.match() #从开头查找
- re.search()
- re.findall() # 返回一个列表
- re.finditer() # 返回可迭代对象
3.2.3 不同的查找方法
- re.sub() #替换
3.2.4 不同的分割方法
- re.split() #分割,返回列表对象
3.3 re.match()
3.3.1 re 里大多数人接触第一个方法
- 语法
- re.match(pattern, string , flags=0)
- 必须从字符串开头开始匹配
- 返回一个对象 ! (包括none)
- 返回 : MatchObject 对象,如果找不到则返回none
- none
- <re.Match object; span=(0, 1), match='1'>
3.3.2 MatchObject 对象的属性/方法
因为 re.match()返回的是一个MatchObject 对象,所以他有些特殊的属性
- re.match()
- # 使用正则对目标字符串,匹配后的内容
- 返回的内容,<re.Match object; span=(0, 1), match='1'>
- 类型:Match object;
- span=(0,1) ,而其实就是 span=(start,end)
- match="1" , 其实就是返回匹配后的字符串 "1" 也就是 re.match.group()
- re.match().span() # 返回的是 使用正则对目标字符串匹配后的内容的字符串长度
- re.match().start() # 返回的是 使用正则对目标字符串匹配后的内容的字符串的开始位
- re.match().end() # 返回的是 使用正则对目标字符串匹配后的内容的字符串的结束位
- re.match().string() # 返回的是 要使用正则去匹配的 目标字符串
- re.match().group() # 返回的是 使用正则对目标字符串匹配后的内容--这个字符串str
#E:\work\FangCloudV2\personal_space\2learn\python3\py0005.txt
# re相关
import re
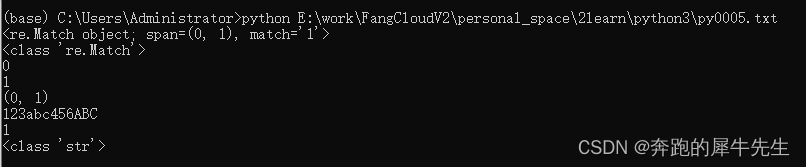
str1=re.match("^\d","123abc456ABC")
print (str1)
print (type(str1))
print (str1.start())
print (str1.end())
print (str1.span())
print (str1.string)
print (str1.group())
print (type(str1.group()))
3.3.3 re.match() 和 ^ 其实有点意义重复
- 用 re.match() 还需要加 ^ ?不需要,都表示从头开始查找了
- 实测也如此
#E:\work\FangCloudV2\personal_space\2learn\python3\py0005.txt
# re相关
import re
print ("#第1次测试")
str1=re.match("^\d","123abc456ABC")
print (str1.group())
str1=re.match("^\d{1}","123abc456ABC")
print (str1.group())
str1=re.match("^\d{1,}?","123abc456ABC")
print (str1.group())
str1=re.match("^\d?","123abc456ABC")
print (str1.group())
print ("#第2次测试")
str2=re.match("\d","123abc456ABC")
print (str2.group())
str2=re.match("\d{1}","123abc456ABC")
print (str2.group())
str2=re.match("\d{1,}?","123abc456ABC")
print (str2.group())
str2=re.match("\d?","123abc456ABC")
print (str2.group())3.3.4 使用 re.match() 来测试,数量的不同写法(可以等价)
比如我只用match()匹配字符串开头的一个数字
以下写法是等价的
- \d #会查找至少1个数字,0个会报错
- \d{1} #会查找至少1个数字,0个会报错
- \d{1,}? #会查找至少1个数字,0个会报错
- 但是这里有点注意,?表示量词时是0|1个,但是放在其他量词后面表示,非贪婪匹配的意思,尽可能少的匹配
下面2个和上面的略有差别
- \d? #如果是0个也可以,返回none ,因为? 本身代表0 或者1
- \d{0,} # 如果是0个也可以,返回none
#E:\work\FangCloudV2\personal_space\2learn\python3\py0005.txt
# re相关
import re
print ("#第1次测试")
str1=re.match("^\d","123abc456ABC")
print (str1.group())
str1=re.match("^\d{1}","123abc456ABC")
print (str1.group())
str1=re.match("^\d{1,}?","123abc456ABC")
print (str1.group())
str1=re.match("^\d?","123abc456ABC")
print (str1.group())
print ("#第2次测试")
str2=re.match("\d","123abc456ABC")
print (str2.group())
str2=re.match("\d{1}","123abc456ABC")
print (str2.group())
str2=re.match("\d{1,}?","123abc456ABC")
print (str2.group())
str2=re.match("\d?","123abc456ABC")
print (str2.group())
print ("#第3次测试")
"""
#这几个找不到会报错
str3=re.match("\d","abc456ABC")
print (str3.group())
str3=re.match("\d{1}","abc456ABC")
print (str3.group())
str3=re.match("\d{1,}?","abc456ABC")
print (str3.group())
"""
str3=re.match("\d?","abc456ABC")
print (str3.group())
str3=re.match("\d{0,}","abc456ABC")
print (str3.group())
3.3.5 所以一般返回 re.match() 即可,而不直接返回 re.match().group() ,原因就很明显了
- re.match() # 返回MatchObject 对象,有可能是<> 有可能是none
- re.match().group() #当MatchObject 对象是none时,这里会报错
- re.match().group() # 如果想这么写,一定考虑好错误处理,当MatchObject为none时做好处理
3.3.6 测试正则 re.match()
- 可以用
- try:
- except Exception as e:
- 暂时先不处理错误而抛出异常!
- Exception 要大写首字母
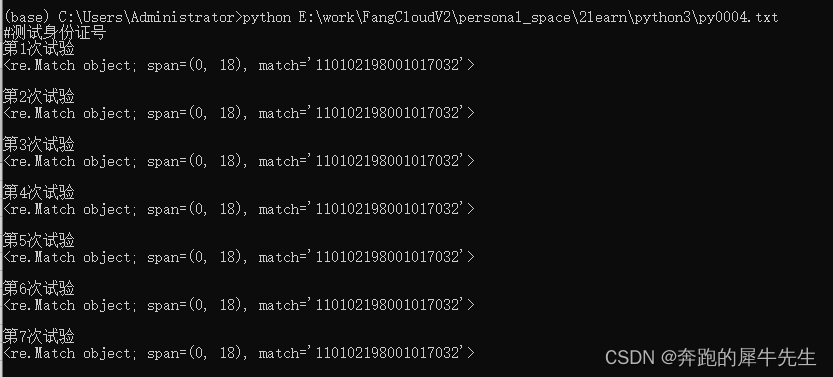
#E:\work\FangCloudV2\personal_space\2learn\python3\py0004.txt
# re相关
import re
i=1
def print_str(strA):
global i
print ("第%s次试验" %i)
i=i+1
try:
print (strA)
print ("")
except Exception as e:
print ("此次有报错",e)
print ("")
print ("#测试身份证号")
#低级错误,半个括号) \d而不是d
str1=re.match("^[0-9]{18}","110102198001017032")
print_str(str1)
str1=re.match("^\d{18}","110102198001017032")
print_str(str1)
str1=re.match("\d{17}(\d|[x])","110102198001017032")
print_str(str1)
str1=re.match("\d{17}(\d?|[x]?)","110102198001017032")
print_str(str1)
str1=re.match("\d{17}\d?","110102198001017032")
print_str(str1)
str1=re.match("^[1-9]\d{16}(\d|[x])","110102198001017032")
print_str(str1)
str1=re.match("^[1-9]\d{16}([0-9]|[x])","110102198001017032")
print_str(str1)
3.4 re.search()
- 语法
- search(pattern, string, flags=0)
- 可以从字符串的任何地方开始查找匹配
- 除了不从 目标字符串开头开始查找,其他和 re.match() 基本一致
- 返回一个对象 ! (包括none)
3.5 Flags标志
在re库中,有一种Flags标志,它可以调整匹配的行为。常用的Flags标志有:
- re.I:忽略大小写匹配
- re.L:做本地化识别(locale-aware)匹配
- re.M:多行匹配,影响 ^ 和 $ 标志
- re.S:使 . 匹配包括换行符在内的所有字符
- re.U:根据Unicode字符集解析字符。这个标志会影响 \w, \W, \b, \B
- re.X:为了增加可读性,忽略空白符号的意义并允许你把横跨多行的正则表达式写成"非括号化"的形式
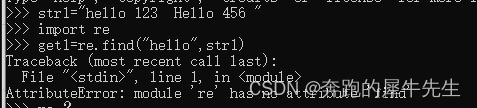
3.6 没有 re.find() ,只有 re.findall()
- 居然没有 re.find()
- 使用此方法会报错!
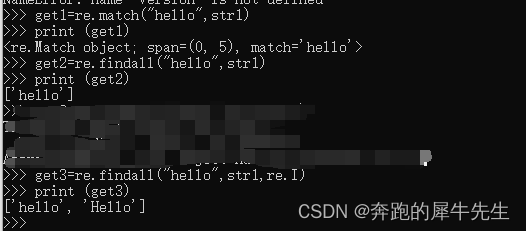
3.7 re.findall()
- 语法
- findall(pattern, string, flags=0)
- 返回一个 列表\
- 比如下面的
- re.findall("",str)
- re.findall("",str,re.I)
3.8 re.sub()
- 语法
- sub(pattern, repl, string, count=0, flags=0)
- 在string内部,按正则 pattern 去替换 repl ,数量为 count 次
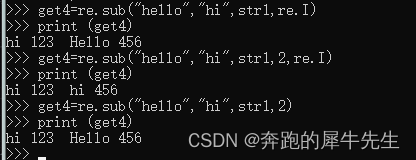
- 如果不指定数量,默认只替换1次
- 如果指定数量,则替换对应次数
- 但是默认不能识别大小写,需要有参数 re.I 才可以
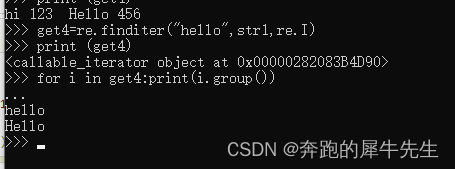
3.9 re.finditer
- 语法
- re.finditer(pattern, string[, flags=0])
- 返回,一个可迭代对象
- <callable_iterator object at 0x00000282083B4D90>
- 虽然直接看不懂
- 但是可以用循环,取出其中内容
3.10 re.compile()
- 编译正则表达式
- compile(pattern, flags=0)
- re.compile() 和前面的 re的各种方法不同,他不是一个方法,而是生成一个正则规则,然后其他正则方法,re.search() re.match() 等使用这个正则去匹配、
- 但是,暂时和直接 用正则规则写一个"" 字符串的正则规则,比较 compile() 生成的有什么区别,暂时不知道,留着待查
#E:\work\FangCloudV2\personal_space\2learn\python3\py0005.txt
# re相关
import re
str1="abcabcabcABC"
str_pattern=re.compile("a.*?c")
re_content=str_pattern.match(str1)
print(re_content.group())
str1="abcabcabcABC"
get1=re.search("a.*?c",str1)
print(get1.group())

3.11 re.split()
- 分隔
- 语法
- split(pattern, string, maxsplit=0, flags=0)
- 按 pattern 去分割 string,
- maxsplit=0, 默认次数为0,即无限次!!!
- 并且返回一个列表!