本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章中,我不仅会讲解多种解题思路及其优化,还会用多种编程语言实现题解,涉及到通用解法时更将归纳总结出相应的算法模板。
为了方便在PC上运行调试、分享代码文件,我还建立了相关的仓库:https://github.com/memcpy0/LeetCode-Conquest。在这一仓库中,你不仅可以看到LeetCode原题链接、题解代码、题解文章链接、同类题目归纳、通用解法总结等,还可以看到原题出现频率和相关企业等重要信息。如果有其他优选题解,还可以一同分享给他人。
由于本系列文章的内容随时可能发生更新变动,欢迎关注和收藏征服LeetCode系列文章目录一文以作备忘。
二维矩阵 grid 由 0 (土地)和 1 (水)组成。岛是由最大的4个方向连通的 0 组成的群,封闭岛是一个 完全 由1包围(左、上、右、下)的岛。请返回 封闭岛屿 的数目。
示例 1:
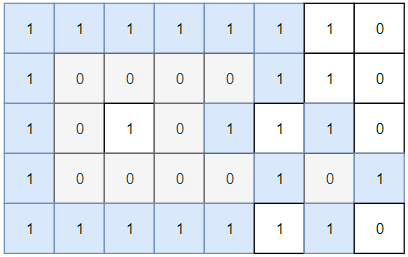
输入:grid = [[1,1,1,1,1,1,1,0],[1,0,0,0,0,1,1,0],[1,0,1,0,1,1,1,0],[1,0,0,0,0,1,0,1],[1,1,1,1,1,1,1,0]]
输出:2
解释:
灰色区域的岛屿是封闭岛屿,因为这座岛屿完全被水域包围(即被 1 区域包围)。
示例 2:
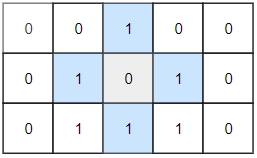
输入:grid = [[0,0,1,0,0],[0,1,0,1,0],[0,1,1,1,0]]
输出:1
示例 3:
输入:grid = [[1,1,1,1,1,1,1],
[1,0,0,0,0,0,1],
[1,0,1,1,1,0,1],
[1,0,1,0,1,0,1],
[1,0,1,1,1,0,1],
[1,0,0,0,0,0,1],
[1,1,1,1,1,1,1]]
输出:2
提示:
1 <= grid.length, grid[0].length <= 1000 <= grid[i][j] <= 1
本题为「200. 岛屿数量」的变形题目,解法几乎一样,本质是均为遍历图中的连通区域,唯一不同的是本题中的岛屿要求是「封闭」的,根据题意可以知道「封闭岛屿」定义如下:完全由 1 1 1 包围(左、上、右、下)的岛。
设矩阵的行数与列数分别为 m , n m,n m,n ,如果从一个 0 0 0(岛屿格子)出发,向四方向的陆地格子移动,可以移动到网格图的边界(最外面一圈的格子,即第 0 0 0 行、第 0 0 0 列,第 m − 1 m - 1 m−1 行、第 n − 1 n - 1 n−1 列),那么这个 0 0 0 所处的岛屿就不是封闭的;反之,如果无法移动到网格图边界,就是封闭的,说明这个岛屿的上下左右都有 1 1 1(水域格子)包围住。
从这个角度出发,网格图的行数小于 3 3 3 行或列数小于 3 3 3 列,就不存在封闭岛屿。下面分为从里到外和从外到里两种写法。
解法1 DFS+出界标记
从不在边界的 0 0 0 出发,DFS访问四方向的 0 0 0 。DFS之前,设置全局变量 c l o s e d closed closed 为 t r u e true true 。如果DFS中到达边界,设置 c l o s e d closed closed 为 f a l s e false false ,意味着当前遍历的岛屿不是封闭岛屿。注意把访问过的 0 0 0 改成 1 1 1 ,避免重复访问。
还要注意,每次DFS应当把「这个岛屿的非边界格子」都遍历完。如果在中途退出DFS,会导致某些格子没有遍历到,那么在后续以这个格子为起点DFS时,可能会误把它当作封闭岛屿上的格子,从而算出比预期结果更大的值。
递归结束时,如果 c l o s e d closed closed 仍然为 t r u e true true ,说明当前遍历的是一个封闭岛屿,答案加一。
class Solution {
private boolean closed;
private void dfs(int[][] g, int i, int j) {
if (i == 0 || i == g.length - 1 || j == 0 || j == g[i].length - 1) {
if (g[i][j] == 0) closed = false; // 到达边界
return;
}
if (g[i][j] != 0) return;
g[i][j] = 1; // 标记(i,j)被访问,避免重复访问
dfs(g, i - 1, j);
dfs(g, i + 1, j);
dfs(g, i, j - 1);
dfs(g, i, j + 1);
}
public int closedIsland(int[][] grid) {
int m = grid.length, n = grid[0].length, ans = 0;
if (m < 3 || n < 3) return 0; // 特判
for (int i = 1; i + 1 < m; ++i) {
for (int j = 1; j + 1 < n; ++j) {
if (grid[i][j] == 0) {
closed = true;
dfs(grid, i, j);
if (closed) ++ans;
}
}
}
return ans;
}
}
复杂度分析:
- 时间复杂度: O ( m n ) O(mn) O(mn),其中 m m m 和 n n n 分别为 g r i d grid grid 的行数和列数。
- 空间复杂度: O ( m n ) O(mn) O(mn)。递归最坏需要 O ( m n ) O(mn) O(mn) 的栈空间(想象一个蛇形的 0 0 0 连通块)。
解法2 DFS+先外后内
做法2是,既然关键是「边界」,那么不妨从边界(的 0 0 0 即岛屿格子)出发,先标记所有非封闭岛屿。标记完后,网格图内部的 0 0 0 就一定在封闭岛屿上,每次从一个新的 0 0 0 出发进行DFS,就是一个新的封闭岛屿。
从网格图的第一行、最后一行、第一列和最后一列的所有 0 0 0 出发,DFS访问四方向的 0 0 0 ,并把这些 0 0 0 标记成「访问过」。代码实现时可以直接把 0 0 0 修改成 1 1 1 。注意,此时将网格图外作为边界!
然后从剩下的 0 0 0 出发,按照同样的方式DFS访问四方向的 0 0 0 ,同时把 0 0 0 改成 1 1 1 。每次从一个新的 0 0 0 出发(起点),就意味着找到了一个新的封闭岛屿,答案加一。
class Solution {
private boolean closed;
private void dfs(int[][] g, int i, int j) {
if (i < 0 || i >= g.length || j < 0 || j >= g[i].length || g[i][j] != 0)
return; // 到达边界
g[i][j] = 1; // 标记(i,j)被访问,避免重复访问
dfs(g, i - 1, j);
dfs(g, i + 1, j);
dfs(g, i, j - 1);
dfs(g, i, j + 1);
}
public int closedIsland(int[][] grid) {
int m = grid.length, n = grid[0].length, ans = 0;
if (m < 3 || n < 3) return 0; // 特判
for (int i = 0; i < m; ++i) {
// 如果是第一行和最后一行,访问所有格子
// 否则,只访问第一列和最后一列的格子
int step = (i == 0 || i == m - 1) ? 1 : n - 1;
for (int j = 0; j < n; j += step)
dfs(grid, i, j);
}
for (int i = 1; i + 1 < m; ++i) {
for (int j = 1; j + 1 < n; ++j) {
if (grid[i][j] == 0) {
dfs(grid, i, j);
++ans; // 一定是封闭岛屿
}
}
}
return ans;
}
}
复杂度分析:
- 时间复杂度: O ( m n ) O(mn) O(mn),其中 m m m 和 n n n 分别为 grid \textit{grid} grid 的行数和列数。
- 空间复杂度: O ( m n ) O(mn) O(mn)。递归最坏需要 O ( m n ) O(mn) O(mn) 的栈空间(想象一个蛇形的 0 0 0 连通块)。
解法3 并查集
本题也可用并查集解决。由于岛屿由相邻的陆地连接形成,因此封闭岛屿的数目为不与边界相连的陆地组成的连通分量数。连通性问题可以使用并查集解决。假设可以对每个连通区域进行标记,如果该连通区域与边界连通,则该连通区域一定不是「封闭岛屿」,否则该连通区域为「封闭岛屿」。
并查集初始化时,每个「不在边界上的陆地元素」分别属于不同的集合,为了方便处理,将所有在边界上的陆地元素归入同一个集合,称为边界集合,初始化时就将边界上的为 0 0 0 的元素全部纳入到集合 0 0 0 中。边界上的陆地元素的状态是与边界连通,其余单元格的状态都是不与边界连通,集合个数等于不在边界上的陆地元素个数。
初始化之后,遍历每个元素(一定要遍历最后一行和最后一列),如果一个位置 ( x , y ) (x,y) (x,y) 是陆地元素、且其上边相邻位置 ( x − 1 , y ) (x - 1, y) (x−1,y) 或左边相邻位置 ( x , y − 1 ) (x, y - 1) (x,y−1) 是陆地元素,则将两个相邻陆地元素所在的集合做合并。因为所有在边界上的陆地元素都属于边界集合,每次合并都可能将一个「不在边界上的陆地元素」合并到边界集合。
遍历结束之后,利用哈希表,统计所有陆地元素构成的连通集合的数目为 t o t a l total total ,此时还需要检测边界集合 0 0 0 是否也包含在 total \textit{total} total 中,如果 total \textit{total} total 包含边界集合 0 0 0 中,则返回 total − 1 \textit{total} - 1 total−1 ,否则返回 total \textit{total} total 。
class Solution {
public int closedIsland(int[][] grid) {
int m = grid.length, n = grid[0].length;
UnionFind uf = new UnionFind(m * n);
for (int i = 0; i < m; ++i) { // 第一列和最后一列
if (grid[i][0] == 0) uf.merge(i * n, 0);
if (grid[i][n - 1] == 0) uf.merge(i * n + n - 1, 0);
}
for (int j = 1; j < n - 1; ++j) { // 第一行和最后一行
if (grid[0][j] == 0) uf.merge(j, 0);
if (grid[m - 1][j] == 0) uf.merge((m - 1) * n + j, 0);
}
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
if (grid[i][j] == 0) { // 如果一个陆地上和左有陆地,则连通
if (i > 0 && grid[i - 1][j] == 0)
uf.merge(i * n + j, (i - 1) * n + j);
if (j > 0 && grid[i][j - 1] == 0)
uf.merge(i * n + j, i * n + j - 1);
}
}
}
var cnt = new HashSet<Integer>();
for (int i = 0; i < m; ++i)
for (int j = 0; j < n; ++j)
if (grid[i][j] == 0)
cnt.add(uf.find(i * n + j));
int total = cnt.size();
if (cnt.contains(uf.find(0))) --total;
return total;
}
}
class UnionFind {
private int[] parent;
private int[] rank;
public UnionFind(int n) {
this.parent = new int[n];
for (int i = 0; i < n; ++i) parent[i] = i;
this.rank = new int[n]; // 每个集合的秩
}
public void merge(int x, int y) {
int rx = find(x), ry = find(y);
if (rx != ry) {
if (rank[rx] > rank[ry]) parent[ry] = rx;
else if (rank[rx] < rank[ry]) parent[rx] = ry;
else { // 高度相同时
parent[ry] = rx;
++rank[rx]; // 高度+1
}
}
}
public int find(int x) {
return (parent[x] != x) ? (parent[x] = find(parent[x])) : parent[x];
}
}
复杂度分析:
- 时间复杂度: O ( m n × α ( m n ) ) O(mn \times \alpha(mn)) O(mn×α(mn)) ,其中 m m m 和 n n n 分别是矩阵的行数和列数, α \alpha α 是反阿克曼函数。并查集的初始化需要 O ( m × n ) O(m \times n) O(m×n) 的时间,然后遍历 m × n m \times n m×n 个元素,最多执行 m × n m \times n m×n 次合并操作,这里的并查集使用了路径压缩和按秩合并,单次操作的时间复杂度是 O ( α ( m × n ) ) O(\alpha(m \times n)) O(α(m×n)) ,因此并查集合并的操作的时间复杂度是 O ( m n × α ( m n ) ) O(mn \times \alpha(mn)) O(mn×α(mn)) ,总时间复杂度是 O ( m n + m n × α ( m n ) ) = O ( m n × α ( m n ) ) O(mn + mn \times \alpha(mn)) = O(mn \times \alpha(mn)) O(mn+mn×α(mn))=O(mn×α(mn)) 。
- 空间复杂度: O ( m n ) O(mn) O(mn) ,其中 m , n m,n m,n 分别为矩阵的行数与列数。并查集需要 O ( m n ) O(mn) O(mn) 的空间用来存储集合关系。