为什么需要共享内存?
共享内存的访问速度比访问全局速度快的多,因此对于多次访问全局内存的程序,特别是需要多次将全局内存的运算结果缓存到全局内存的运算,先将临时结果缓存到共享内存再做计算,会提高运算速度。
1、例如累积归并求和,将一串数字从头加到尾,归并求和算法如下:
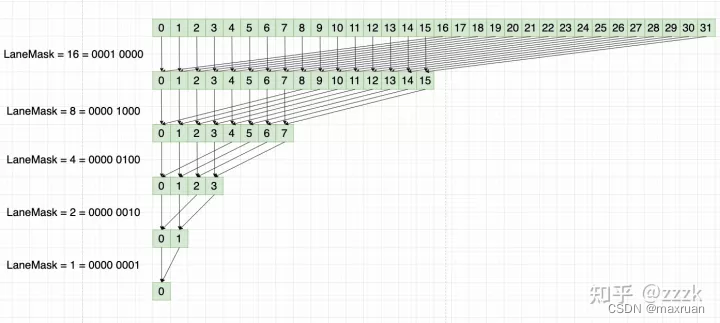
如果使用全局内存,每做一次减半运算,都要访问一半的全局内存,总要访问的全局内存次数为 N + N/2 + N/4 +… + 1 次。因此减少全局内存的访问次数可以提高运算速度。
如果提高呢?那就是第一次先将全局内存复制到共享内存中,这时总需要访问N次全局内存,每个线程只需要访问一次。
2、再如直方图统计:
假设直方图统计的bin个数为256,假设统计N 个数,如果使用全局内存,需要将N个全局内存的数累加到256个全局内存中,那么也就是需要访问了2N次全局内存。如果将256 个bin的内存改为共享内存,那么只需要访问N次的全局内存,运算速度得到提升。
什么是共享内存
对于CUDA,一个grid 有多个Block 块,一个block块多个线程。
共享内存只是 Block 块内的线程共享,不同Block块之间的共享内存是不会共享的。
定义在核函数内,加前关键字为__shared__,例如:
shared int sharedata[thread_perblock];
块内同步
在做共享内存时,一般需要使用线程块内同步__syncthreads(),只是让相同block块中的线程都要达到这个位置后才可往下执行。
如何实现
为了使用共享内存,一般定义共享内存的大小为Block 块中的线程个数。这样每个线程都对应到响应的共享内存中。使用线程id 进行对应。
int thread_id = threadIdx.x;
对于不同块中的共享内存,之间不存在共享,因此全局映射到共享内存方式如下:
int tid = threadIdx.x + blockDim.x * blockIdx.x;
sharedata[thread_id] = data[tid];
tid 处于哪个Block 中即映射到哪个Block块中的共享内存。
做完映射和对应后即可进行运算,块内运算以块为基本单元,使用id为块内线程id:
例如规约求和:
int mid = thread_perblock / 2; //规约求和, thread_perblock 必须为 2 的 K 次方
while(mid != 0){
if(thread_id < mid){
sharedata[thread_id] += sharedata[thread_id + mid];
}
__syncthreads();
mid /= 2;
}
每做完一轮块内运算进行一次同步,等待块内所有线程执行完。while里即为循环次数。
等所有块执行完后将共享内存的结果再赋值到全局内存,完成整个过程。
out[blockIdx.x] = sharedata[0]; // 不同block中的shareddata 互不干扰
代码
1、归并求和:
#define thread_perblock 8
__global__ void reduce_add(int *data, int *out, int N){
__shared__ int sharedata[thread_perblock];
int tid = threadIdx.x + blockDim.x * blockIdx.x;
int thread_id = threadIdx.x;
printf("tid = %d, %d\n", tid, data[tid]);
while (tid < N) // 数据预处理到共享内存,当数组大于线程数量,需要一个线程处理多个数据,跨度(blockDim.x * gridDim.x)
{
sharedata[thread_id] += data[tid];
tid += blockDim.x * gridDim.x;
}
__syncthreads();// 块内同步
int mid = thread_perblock / 2; //规约求和, thread_perblock 必须为 2 的 K 次方
while(mid != 0){
if(thread_id < mid){
sharedata[thread_id] += sharedata[thread_id + mid];
printf("blockIdx.x = %d, sharedata[%d] = %d , mid = %d\n " ,blockIdx.x, thread_id, sharedata[thread_id], mid);
}
__syncthreads();
mid /= 2;
}
out[blockIdx.x] = sharedata[0]; // 不同block中的shareddata 互不干扰
printf("blockIdx.x = %d, sharedata[0] = %d \n" , blockIdx.x, sharedata[0]);
}
2、直方图统计:
__global__ void histo_kernel(unsigned char *buffer, long size, unsigned int *histo) {
__shared__ unsigned int temp[256];
temp[threadIdx.x] = 0;
//这里等待所有线程都初始化完成
__syncthreads();
int i = threadIdx.x + blockIdx.x * blockDim.x;
int offset = blockDim.x * gridDim.x;
while (i < size) {
atomicAdd(&temp[buffer[i]], 1); // 先在共享内存中操作,减少全局内存访问
i += offset;
}
__syncthreads();//等待所有线程完成计算,统计完一个块
//将每个块结果统计到全局内存
atomicAdd(&(histo[threadIdx.x]), temp[threadIdx.x]);
}