机器学习与深度学习——基于潜在语义分析(LSA)的文档相似度计算
基于潜在语义分析(LSA)是一种使用数学和统计方法来分析文本数据的技术。该技术可用于发现文本之间的关系,以及为文本提供有关其含义的更深层次的信息。
下面是LDA模型的详细描述:
收集语料库:首先需要收集一个包含大量文本数据的语料库。这些文本可以是任何类型的,例如新闻文章、博客、论文等等。
构建词汇表:然后从语料库中提取所有不同的单词,并构建一份称为“词汇表”的列表。此外,还需要将每个单词映射到唯一的ID上。
创建文档-词频矩阵:接下来,需要将文本数据转换为数字形式。为此,可以创建一个称为“文档 - 词频”矩阵的矩阵,其中每行表示一个文档,每列表示一个单词。每个元素表示该单词在该文档中出现的次数。
进行奇异值分解(SVD):接下来,需要对文档 - 词频矩阵进行奇异值分解(SVD)。SVD是一种数学技术,可将矩阵分解为三个矩阵的乘积。这些矩阵包括一个表示文档的矩阵、一个表示主题的矩阵和一个表示单词的矩阵。
选择主题数量:选择要提取的主题数量,该数量通常是根据实验和经验来确定的。
提取主题:使用前面步骤中计算得到的主题矩阵和单词矩阵,可以提取文本数据中存在的主题。每个主题都表示一组相关联的单词,可以用于理解文本含义。
应用模型:基于提取的主题,可以应用该模型来进行各种任务,例如文本聚类、分类和信息检索等。
LDA模型使用SVD技术将文本数据转换为数字形式,并提供有关文本数据之间的相似性和含义的更深层次的见解。
下面我们通过一个案例来更进一步了解和学习LSA。
目的
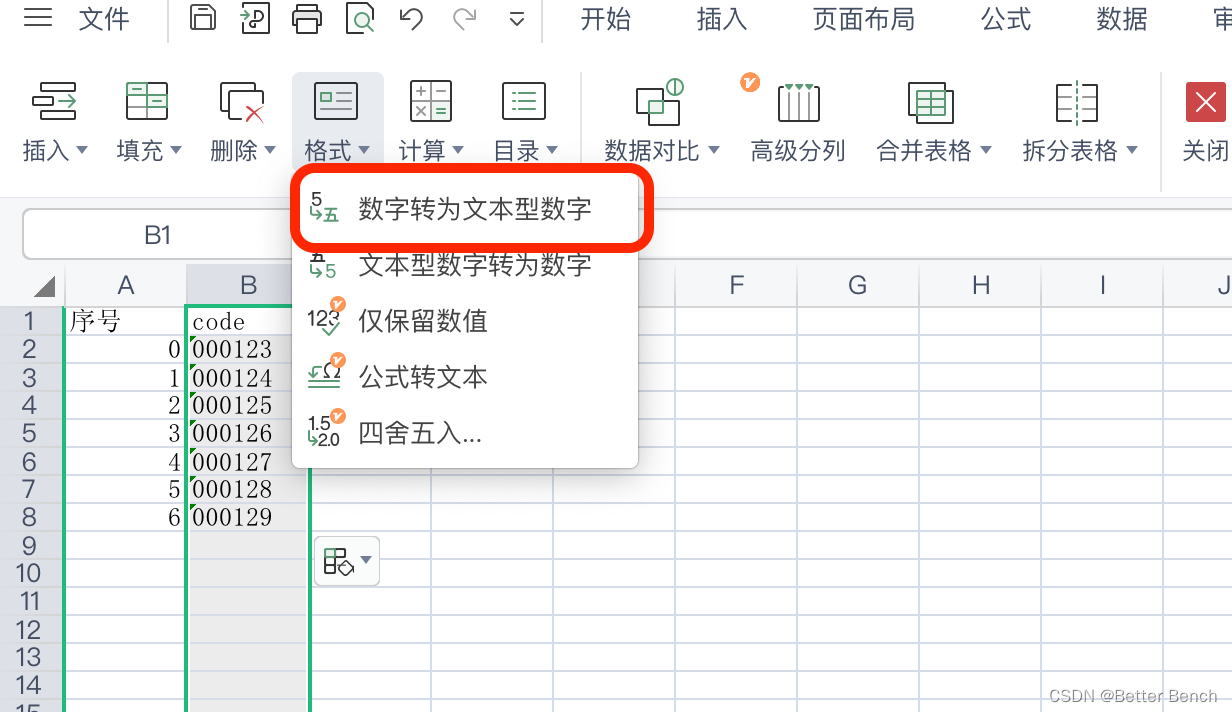
- 使用Jieba库对句子进行中文分词,并输出分词结果
- 基于潜在语义分析(LSA)对18个docx文档进行文本相似度分析
基本思路
1、读取文档集合:从指定目录中读取所有的.docx文件,并将它们的内容存储在docs列表中。
2、对于每个文档,执行预处理操作(例如去除停用词、分词和词干提取等),并使用gensim库创建文档-单词矩阵
3、创建文档-单词矩阵:使用CountVectorizer将文档集合转换为文档-单词矩阵表示形式,其中每个元素表示相应文档中的单词出现次数。
4、训练 LSA 模型:使用TruncatedSVD进行降维操作,将文档-单词矩阵转换为潜在语义空间表示形式。
5、创建索引和相似度矩阵:使用MatrixSimilarity创建相似度矩阵,用于计算文档之间的相似度。
6、使用相似度矩阵计算文档相似度:选择一个目标文档,并计算该文档与其他文档的相似度。
7、输出与目标文档最相似的文档:打印目标文档的内容,然后按相似度从高到低的顺序,打印最相似的前10篇文档的索引、内容和相似度得分。
程序代码
使用LSA模型和相似度矩阵,对给定的18个docx文档集合进行相似度分析
import os
import docx
from gensim import corpora, models, similarities
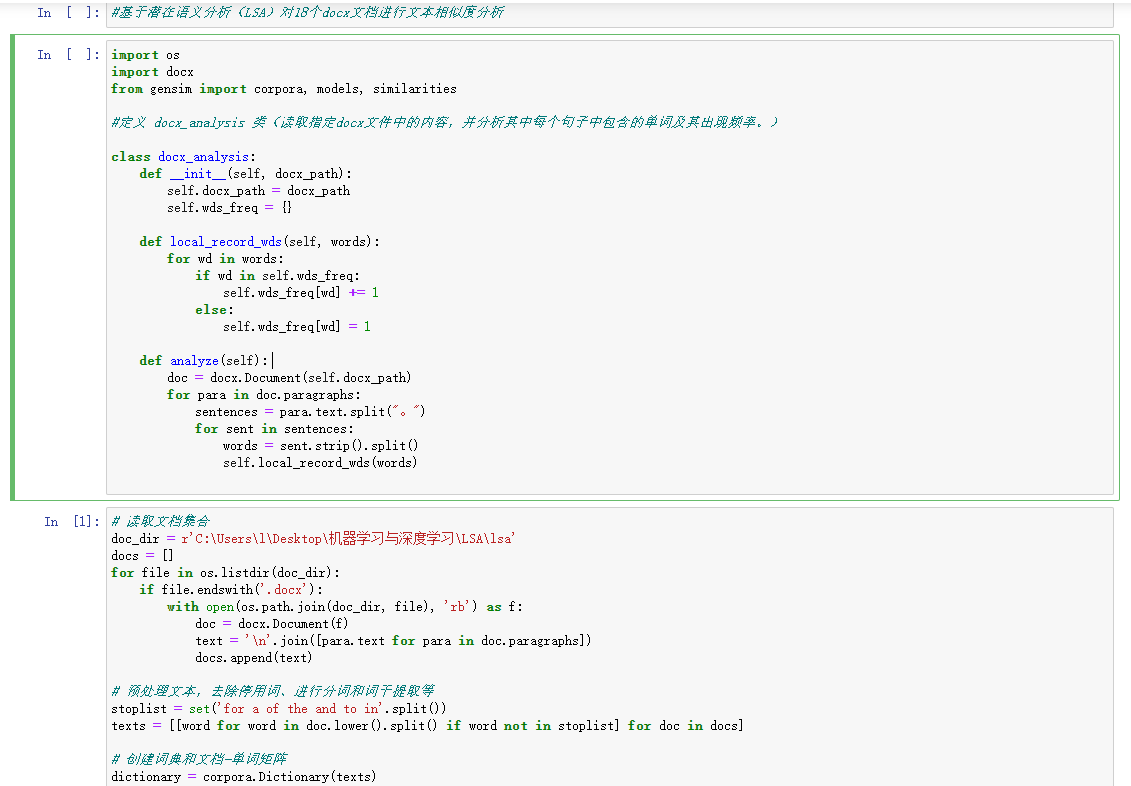
#定义 docx_analysis 类(读取指定docx文件中的内容,并分析其中每个句子中包含的单词及其出现频率。)
class docx_analysis:
def __init__(self, docx_path):
self.docx_path = docx_path
self.wds_freq = {}
def local_record_wds(self, words):
for wd in words:
if wd in self.wds_freq:
self.wds_freq[wd] += 1
else:
self.wds_freq[wd] = 1
def analyze(self):
doc = docx.Document(self.docx_path)
for para in doc.paragraphs:
sentences = para.text.split("。")
for sent in sentences:
words = sent.strip().split()
self.local_record_wds(words)
# 读取文档集合
doc_dir = r'C:\Users\l\Desktop\机器学习与深度学习\LSA\lsa'
docs = []
for file in os.listdir(doc_dir):
if file.endswith('.docx'):
with open(os.path.join(doc_dir, file), 'rb') as f:
doc = docx.Document(f)
text = '\n'.join([para.text for para in doc.paragraphs])
docs.append(text)
# 预处理文本,去除停用词、进行分词和词干提取等
stoplist = set('for a of the and to in'.split())
texts = [[word for word in doc.lower().split() if word not in stoplist] for doc in docs]
# 创建词典和文档-单词矩阵
dictionary = corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
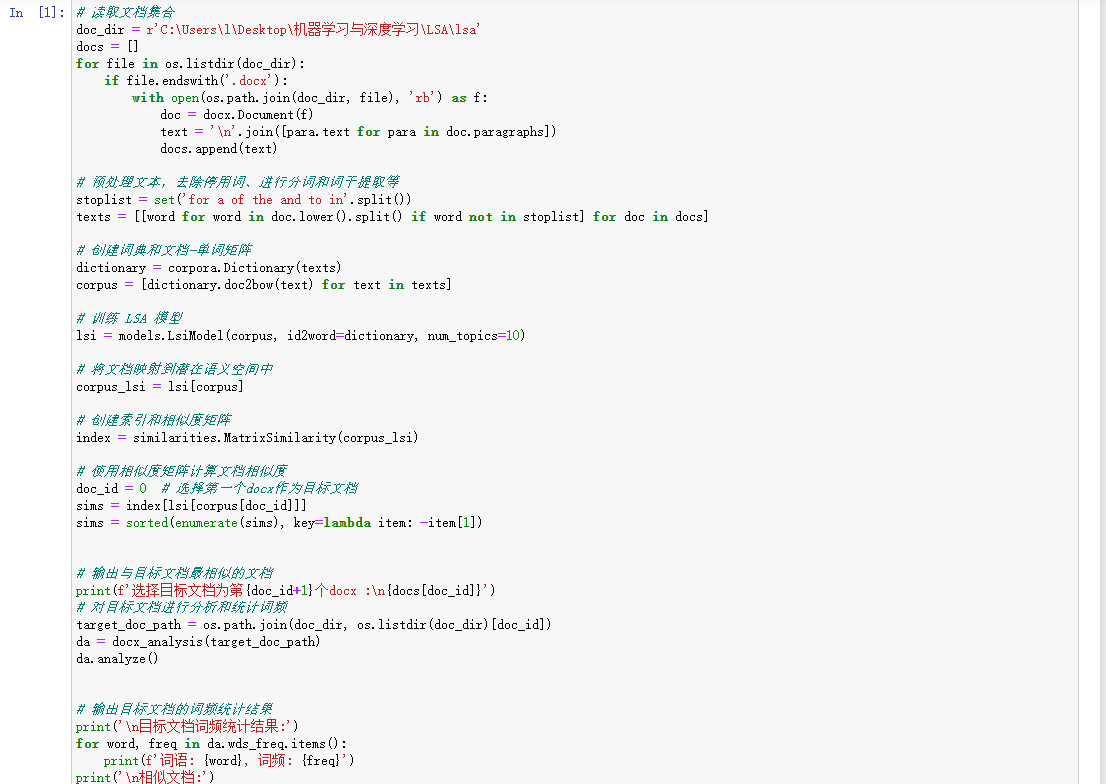
# 训练 LSA 模型
lsi = models.LsiModel(corpus, id2word=dictionary, num_topics=10)
# 将文档映射到潜在语义空间中
corpus_lsi = lsi[corpus]
# 创建索引和相似度矩阵
index = similarities.MatrixSimilarity(corpus_lsi)
# 使用相似度矩阵计算文档相似度
doc_id = 0 # 选择第一个docx作为目标文档
sims = index[lsi[corpus[doc_id]]]
sims = sorted(enumerate(sims), key=lambda item: -item[1])
# 输出与目标文档最相似的文档
print(f'选择目标文档为第{doc_id+1}个docx :\n{docs[doc_id]}')
# 对目标文档进行分析和统计词频
target_doc_path = os.path.join(doc_dir, os.listdir(doc_dir)[doc_id])
da = docx_analysis(target_doc_path)
da.analyze()
# 输出目标文档的词频统计结果
print('\n目标文档词频统计结果:')
for word, freq in da.wds_freq.items():
print(f'词语: {word}, 词频: {freq}')
print('\n相似文档:')
for doc_idx, sim_score in sims[1:11]: # 最相似的前10篇文档
print(f'相似文档索引——{doc_idx}: \n{docs[doc_idx]}文档相似度: {sim_score}')



基于潜在语义分析(LSA)的优点和缺点。
优点:
- LSA假设隐藏在词语中的隐含意思 (也就是潜在语义空间的这些语义维)可以更好地刻画文本真实含义。
- LSA利用潜在的语义结构表示词条和文本,将词条和文本映射到同一个k维的语义空间内,均表示为k个因子的形式,向量的含义发生了很大的变化。它反映的不再是简单的词条出现频率和分布关系,而是强化的语义关系。在保持了原始的大部分信息的同时,克服了传统向量空间表示方法时产生的多义词、同义词和单词依赖的现象。
缺点:
- LSA不是概率模型,缺乏严谨的数理统计基础。
- LSA解决部分一词多义和一义多词问题,也可以用于降维,但LSA不是概率模型,缺乏严谨的数理统计基础。建议考虑隐含狄利克雷分布(Latent Dirichlet allocation,简称LDA),一种主题模型,它可以将文档集中每篇文档的主题按照概率分布的形式给出。







![[算法前沿]--019-医学AIGC大模型的构建](https://img-blog.csdnimg.cn/f55dacddfa08465a8bc64edd8cb461a2.png)