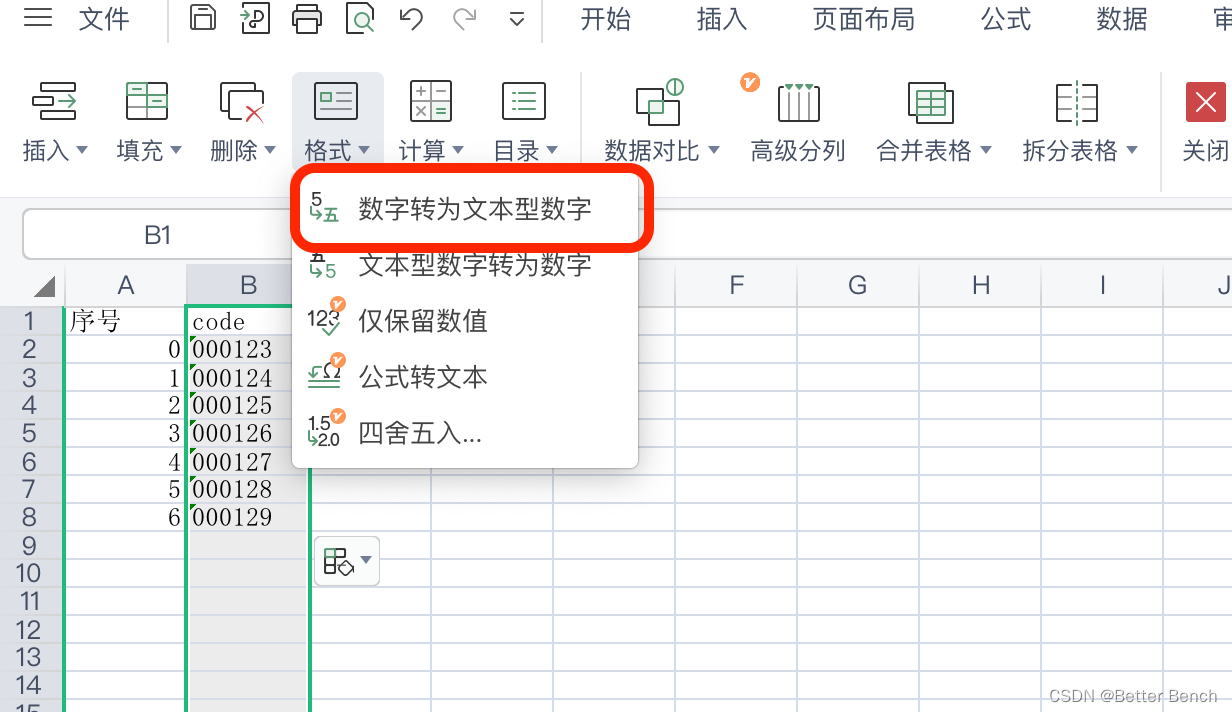
1. 写在前面
c++在线编译工具,可快速进行实验: https://www.bejson.com/runcode/cpp920/
这段时间打算重新把c++捡起来, 实习给我的一个体会就是算法工程师是去解决实际问题的,所以呢,不能被算法或者工程局限住,应时刻提高解决问题的能力,在这个过程中,我发现cpp很重要, 正好这段时间也在接触些c++开发相关的任务,所有想借这个机会把c++重新学习一遍。 在推荐领域, 目前我接触到的算法模型方面主要是基于Python, 而线上的服务全是c++(算法侧, 业务那边基本上用go),我们所谓的模型,也一般是训练好部署上线然后提供接口而已。所以现在也终于知道,为啥只单纯熟悉Python不太行了, cpp,才是yyds。
和python一样, 这个系列是重温,依然不会整理太基础性的东西,更像是查缺补漏, 不过,c++对我来说, 已经5年没有用过了, 这个缺很大, 也差不多相当重学了, 所以接下来的时间, 重温一遍啦 😉
资料参考主要是C语言中文网和光城哥写的C++教程,然后再加自己的理解和编程实验作为辅助,加深印象,当然有些地方我也会通过其他资料进行扩充。 关于更多的细节,还是建议看这两个教程。
今天这篇文章整理C++关于输入和输出的操作,也就是我们所熟知的"流"操作, 我发现学习哪个语言,都需要学习它的I/O操作, 毕竟这是我们读数据和写数据的前提呀, C++也不例外,通常,我们在C++中使用cin输入流实现数据输入, cout输出流实现数据输出(输入和输出流本质上是已经定义好的类对象), 但是, 这只是流里面的冰山一小小角, 其实C++输入流和输出流不仅实现基本的输入输出操作, 通过类内部成员函数, 还可以满足特殊场景的输入输出需求, 这又是一个很长很长的故事…
主要内容:
- C++输入流和输出流
- C++输出单个字符(put)和字符串(write)
- C++的tellp和seekp方法详解
- C++ cout的格式化输出
- C++输入输出重定向
- C++管理输出缓冲区
- C++读取单个字符(get)和读入字符串(getline)
- C++跳过指定字符(ignore)及查看输入流中的下一个字符(peek)
- C++ cin如何判断输入结束?
- C++处理输入输出错误
- 小总
Ok, let’s go!
2. C++输入流和输出流
C语言有一套完成数据读写的解决方案:
- scanf()、gets()等函数从键盘读取数据, printf()、puts()等向屏幕输出数据
- fscanf()、fgets()等函数读取文件中数据,fprintf()、fputs()向文件写入数据
这套I/O方案在C++也同样适用,不过C++还独立开发了一套全新I/O解决方案, 这套解决方案是我们所说的"流类"组成的类库。 整个流类以及它们的关系如下:

这些流类的功能也可以见名知意:
- istream: 接收从键盘输入的数据
- ostream: 数据输出到屏幕
- ifstream: 读文件中的数据
- ofstream: 向文件写数据
- iostream: istream和ostream类功能合体,既可以从键盘输入,也可以输出到屏幕
- fstream: ifstream和ofstream类功能合体,既能读取文件数据,又能向文件写数据
之前学习的cin是istream对象, cout是ostream对象, 它们都声明在<iostream>中。除了cout, 头文件中还声明了2个对象,叫做cerr和clog, 它们用法和cout一样,只不过cerr常用来输出警告和错误信息, clog常用来输出程序执行中的日志信息。区别如下:
- cout除了可以将数据输出到屏幕,还可以通过重定向,实现数据输出到指定文件; 而cerr和clog不支持重定向,只能将数据输出到屏幕
- cout和clog都有缓冲区, 它们输出数据时, 会先将数据放到缓冲区,等缓冲区满或手动换行时(换行符
\n),才会将数据全部显示到屏幕;cerr没有缓冲区,会直接将数据输出到屏幕。
其他的,这哥仨无不同。
std::cout << "cout:" << "wuzhongqiang" << std::endl;
std::cerr << "cerr:" << "wuzhongqiang" << std::endl;
std::clog << "clog:" << "wuzhongqiang" << std::endl
注意, 这里的cin, cout, cerr, clog等不是C++关键字,而是流对象。 另外,这里既然谈到了缓冲区, 我有些好奇,所以就先对缓冲区进行了下学习。
缓冲区,又称缓存,是内存空间的一部分。 即在内存空间中预留一定存储空间,用来缓冲输入和输出数据的。根据其对应是输入还是输出设备, 分为输入和输出缓冲区。
缓冲区有三种类型:
- 全缓冲: 当填满标准I/O缓存后才进行实际I/O操作,典型代表是对磁盘文件读写
- 行缓冲: 当在输入和输出遇到换行符时, 执行真正的I/O操作。典型代表是键盘输入数据, 我们输入的数据先存放在缓冲区,等按下回车换行时,才进行实际I/O操作。
- 既然说到cin上,就顺便解释下标准输入缓冲区, 这个放在上大学的时候,是没理解的了。
- 当我们从键盘输入字符串的时候, 需要敲一下回车键才能将这个字符串送入缓冲区, 而这个回车键,会转换成一个
'\n', 也被存储在cin缓冲区,并且这个东西也被当成一个字符。- cin读取数据时,是从缓冲区读取, 缓冲区为空, cin的成员函数会阻塞等待数据到来, 而一旦缓冲区有数据,就触发成员函数去读取数据
- 不带缓冲: 就像上面的cerr这种的,有出错信息尽快抛出来
缓冲区会刷新的四种情况: 缓冲区满,执行flush, 执行endl, 关闭文件

当然, 上面提到cin, cout, cerr和clog都是类对象,其实istream和ostream还提供了很多实用的函数, 供这几个类对象调用。 下面盘点下, 这些我们在日常中也常用,但其实有时候并不知道他们的区别。
cin对象常用的一些成员方法以及功能:
| 成员方法名 | 功能 |
|---|---|
| getline(str, n, ch) | 从输入流中接收 n-1 个字符给 str 变量,当遇到指定 ch 字符时会停止读取,默认情况下 ch 为 ‘\0’ |
| get() | 从输入流中读取一个字符,同时该字符会从输入流中消失 |
| gcount() | 返回上次从输入流提取出的字符个数,该函数常和 get()、getline()、ignore()、peek()、read()、readsome()、putback() 和 unget() 联用 |
| peek() | 返回输入流中的第一个字符,但并不提取 |
| putback() | 将字符c置入输入流 |
| ignore(n, ch) | 从输入流中逐个提取字符,但提取出的字符被忽略,不被使用,直至提取出 n 个字符,或者当前读取的字符为 ch |
| operator>> | 重载>>运算符,用于读取指定类型的数据, 并返回输入流对象本身 |
cout哥仨常用的一些成员方法及功能
| 成员方法名 | 功能 |
|---|---|
| put() | 输出单个字符 |
| write() | 输出指定字符串 |
| tellp() | 用于获取当前输入流指针的位置 |
| seekp() | 设置输出流指针位置 |
| flush() | 刷新输出流缓冲区 |
| operator<< | 重载<<运算符,使其用于输出其后指定类型数据 |
看个例子:
int main()
{
char url[10] = {0};
// 读取一行字符串
cin.getline(url, 10);
// 输出上面读取字符个数
cout << cin.gcount() << endl;
// 输出出来
cout.write(url, 10);
return 0;
}
// 此时输入hello world
// 给到url的是hello wor cin.gcount=9, 把9个字符给到url
3. C++输出单个字符(put)和字符串(write)
3.1 put()函数
put()成员函数用于向输出流缓冲区添加单个字符, 函数原型如下:
ostream&put(char c);
可以看到, 该函数返回一个ostream类的引用对象, 可以理解为cout的引用,所以这玩意可以拼接输出:
cout.put(c1).put(c2).put(c3);
应用实例:
cout.put('a'); // a
cout.put(65+32); // a
cout.put(97); // a
cout.put(71).put(79).put(79). put(68).put('\n'); // GOOD
除了使用cout.put()函数输出一个字符外,可以用putchar()函数输出, 这个是C语言中使用的,在<stdio.h>中定义, C++保留了这个函数, 在<iostream>头文件中定义。
OK, 这个put()函数,看似很简单, 但我有个问题,就是为啥要有这玩意呢? 你要说输出单个字符, 我cout<<难道实现不了吗? 这个问题, 勾起了我的好奇心, 首先, cout.put()是可以将字符的ASCII码转成字符直接输出的, 下面可以看这两个的不同:
cout << 71 << endl; // 71
cout.put(71) << endl; // G
int b = 'a';
cout << b << endl; // 97
cout.put(b) << endl; // a
当然,为了这个问题, 我还特意查了下《C++ Primer Plus》,发现put()函数其实和历史有关,在C++2.0之前版本中, C++语言用int值表示字符串常量,比如下面这句话,是没法输出字符的:
cout << 'W' << endl; // 87
char ch = 'W'; // 在早期版本中, 会从常量'W'中复制左边8位给到ch
'W’的编码87会存储在一个16位或者32位的单元中, 而char变量一般占8位。 所以对于cout, ch和’W’是天壤之别的,虽然存储的值可能相同。 所以那时候,如果想打印出字符来, 就需要
cout.put('W') << endl; // W
不过C++2.0之后, C++字符常量存储已经改成了char类型,不是int类型了,所以cout可以正确处理字符常量。 put()函数我感觉用的并不是很多了现在。
3.2 write()函数
write()方法用于向输出缓冲区添加指定的字符串, 格式:
ostream&write(const char * s,streamsize n); // s用于指定某个长度至少为n的字符数组或字符串, n表示输出前n个字符
这个函数同样返回了一个ostream类的引用对象,可以连着输出:
cout.write(c1, 1).write(c2.2).write(c3.3);
下面演示一下这个方法, 这个函数感觉还是很强大的, 在C++没有切片的情况下,不一定能直接想到cout<<的替代方法。比如下面这个:
#include <iostream>
#include <iostream>
#include <cstring>
using namespace std;
int main(){
const char * w1 = "hello";
const char * w2 = "world";
int len = strlen(w1);
for (int i = 0; i < len+5; i++){
cout.write(w1, i);
cout << endl;
}
return 0;
}
// 输出结果
h
he
hel
hell
hello
hello
hellow
hellowo
hellowor
如果不用python的这种切片, 这种对一个字符串,先输出前1个字符,再输出前2个字符,依次类推输出, 用cout<<一时还想出怎么搞,但write()函数就可以轻松搞定。
但通过这个例子, 至少有两点能够看出来, 第一个就是write()方法不会遇到空字符自动停止打印字符,而只是打印指定数目的字符,即使超出字符串的边界。看循环边界的len+5, 这显然已经超出了w1的范围, 但还是会打印, 打印到w2里面去了。 当然,这是我故意这么写的, 之所以用const限制,就是因为这样能使得w1和w2在内存中能连着放, 可以看的清晰些, 这是第二点。
当然, write()方法, 也可以用于数值数据:
int main(){
long val = 2397923872389;
cout.write((char *) &val, sizeof(long)); // 厦O.
return 0;
}
这里会发现输出的是乱码, 这是因为这个强转操作, 不会将数字转成相应的字符, 而是传输内存中的位表示,4字节的long值,将作为4个独立字节传输。 输出设备把每个字节的ASCII码进行解释,所以,可能出来乱码。 但write()方法确实给数值数据存储在文件中提供了一种简洁, 准确的方式, 后面会整理, 但这个方法确实是很重要的一个方法。
4. C++的tellp和seekp方法详解
cout输出普通数据(也包括cout.put()和cout.write()), 数据都会先放到流缓冲区, 待缓冲区刷新,数据才会输出到指定位置。
ostream类中的tellp()和seekp()成员方法, 是帮助我们修改暂存在输出流缓冲区里面的数据的。
4.1 tellp()成员方法
tellp()用于获取当前输出缓冲区中最后一个字符所在的位置, 语法如下:
streampos tellp();
tellp()不需要传任何参数, 会返回一个streampos类型值。
streampos是fpos类型的别名,通过自动类型转换,可直接赋值给一个整形变量。即可以用一个整形变量接收该函数返回值。
注意,当输出流缓冲区中没有任何数据时,该函数返回的整形值为 0;当指定的输出流缓冲区不支持此操作,或者操作失败时,该函数返回的整形值为 -1
下面我做了一个实验:
#include <iostream>
#include <fstream>
#include <cstring>
int main()
{
std::ofstream outfile;
outfile.open("test.txt");
const char *str = "hello world";
for (int i = 0; i < strlen(str); i++){
outfile.put(str[i]);
// 获取当前输出流
long pos = outfile.tellp();
std::cout << pos << " "; // 1 2 3 4 5 6 7 8 9 10 11
}
return 0;
}
程序每次向输出缓冲区放入字符, pos都表示当前字符的位置。
这里另外想补充的一点,就是,一开始上面这个程序我尝试, 输出屏幕的时候进行定位,发现会报错。 结果搜了下, 感觉这个函数是用于在文件操作中定位内置指针位置的,一般在写文件的时候用。 另外,还有个和他类似的函数叫tellg(), 这个是用于读文件的时候获取内置指针的位置。
总而言之:当我们读取一个文件,并要知道内置指针的当前位置时,应该使用tellg();当我们写入一个文件,并要知道内置指针的当前位置时,应该使用tellp().
4.2 seekp()成员方法
seekp()方法用于指定下一个进入输出缓冲区的字符所在的位置。
比如上面的hello world输出的时候,我们知道最后一个d的位置是11, 此时,如果继续向缓冲区存入数据, 则下一个字符所在位置应该是12, 但借助这个方法,我们可以手动指定下一个字符存放的位置。
seekp() 方法有如下 2 种语法格式:
//指定下一个字符存储的位置
ostream& seekp (streampos pos);
//通过偏移量间接指定下一个字符的存储位置
ostream& seekp (streamoff off, ios_base::seekdir way);
##
off: 相对于way位置的偏移量, 可以是正数可以是负数
way: 指定偏移位置,即从哪里计算偏移量, 三种选择
ios::beg: 文件开头开始计算
ios::end: 文件末尾开始计算
ios::cur: 当前位置开始计算
seekp()返回的是引用形式的ostream对象,所以这东西还可以查看缓冲区里面某一位置上的字符
cout.seekp(pos);
看下面的例子:
int main() {
//定义一个文件输出流对象
std::ofstream outfile;
//打开 test.txt,等待接收数据
outfile.open("test.txt");
const char *str = "hello world";
//将 str 字符串中的字符逐个输出到 test.txt 文件中,每个字符都会暂时存在输出流缓冲区中
for (int i = 0; i < strlen(str); i++){
outfile.put(str[i]);
}
std::cout << outfile.tellp() << std::endl; // 11
outfile.seekp(6);
// 等价于 outfile.seekp(6, ios::beg) outfile.seekp(-6, ios::cur) outfile.seekp(-6, ios::end)
std::cout << "新插入的位置: " << outfile.tellp() << std::endl; // 新插入的位置: 6
const char *newstr = "C++";
outfile.write(newstr, 3);
std::cout << outfile.tellp() << std::endl; // 9
// 关闭文件之前, 刷新outfile输出缓冲区, 使所有字符由缓冲区流入test.txt文件
outfile.flush();
// 读入看看
std::ifstream File("test.txt");
char s[10];
File.read(s,9);
std::cout << File.tellg() << std::endl; // 9
std::cout.write(s, 10); // hello C++
return 0;
}
这里首先发现的第一个事情, tellp()是输出缓冲区末尾的位置, 这个末尾的意思不是最后一个字符位置其实,一开始缓冲区没有数据的时候, 此时tellp()指向0位置, 当插入一个字符之后, tellp()就后移了一下到了1位置,依次类推。当把hello world这11个字符全部插入, tellp()指向了第11个位置, 但注意hello world存放到了0~10. 所以准确的说,这个tellp()应该是最后一个字符的后面一个待插入字符位置。 这样,上面的结果才能说得通。
第二个点,就是tellg()函数, 这里也演示了一下用法, 这个是在文件输入中获取当前的指针位置,由于hello C++也是存储到了0~8,所以tellg()这里和tellp()一样,其实也是最后一个字符后面一个位置。
5. C++ cout格式化输出
某些实际场景中, 可能需要一定的格式输出数据, 比如保留几位小数等, C语言里面的printf()在输出数据时, 可以通过设定一些合理格式控制符, 来达到指定格式输出数据的目的。 比如%.2f, %#X表示十六进制等, 具体可以看这篇文章
C++的cout在输出数据时, 实现格式化输出的方式更加多样, 一方面cout作为ostream类的对象, 该类中提供一些成员方法,可实现对输出数据格式化, 另一方面, C++专门提供了一个<iomanip>头文件, 这里面包含大量格式控制符。但这个没有涉及到原理性的东西,并且没有必要死记硬背, 会查即可,所以这个在这里也不整理, 可以直接看文档
6. C++输入输出重定向
什么是重定向? 默认情况下, cin只能接收从键盘输入的数据, cout也只能将数据输出到屏幕上。 但通过重定向, cin可以将指定文件作为输入源, cout可以将原本要输出到屏幕上的数据写到指定文件。
C++实现重定向常用方式有3种:
6.1 freopen()函数实现重定向
这个函数的定义在<stdio.h>头文件,C语言标准库中的函数,专门用于重定向输入流(scanf(),gets())和输出流(printf,puts)。 但这个函数也可以对C++中的cin和cout重定向。
#include<iostream>
using namespace std;
int a[100];
int main(){
// 标准输入流重定向到abc.in文件中
freopen("abc.in","r",stdin);
// 标准输出流重定向到abc.out文件中
freopen("abc.out","w",stdout);
int n;
cin>>n;
for(int i=1; i<=n; i++)
cin>>a[i]; // 这个在abc.in文件中读取
for(int i=n; i>=1; i--)
cout<<a[i]<<" "; // 输出到abc.out文件中
// 关闭重定向
fclose(stdin);
fclose(stdout);
return 0;
}
6.2 rdbuf()函数实现重定向
rdbuf()函数定义在<ios>头文件, 专门用于实现C++输入输出流重定向。
语法格式有两种:
streambuf *rdbuf() const; // 返回一个指向当前缓冲区的类
streambuf *rdbuf(streambuf *sb); // 将sb指向的缓冲区设置为当前流的新缓冲区,并返回一个指向旧缓冲区的对象
第二个函数好好理解下, 是sb指向的缓冲区设置为当前流的新缓冲区,但返回的是一个指向原先缓冲区的对象。streambuf是C++标准库中用于表示缓冲区的类,该类的指针对象用于代指某个具体的流缓冲区。
看个例子:
#include <iostream>
#include <fstream>
using namespace std;
int main()
{
// 打开in.txt文件,等待读取
ifstream fin("in.txt");
// 打开out.txt 文件, 等待写入
ofstream fout("out.txt");
streambuf *oldcin;
streambuf *oldcout;
char a[100];
// 用rdbuf()重新定向, 返回旧输入流缓冲区指针
oldcin = cin.rdbuf(fin.rdbuf());
cin >> a; // 从input.txt文件读入
// 用rdbuf()重新定向, 返回旧输出流缓冲区指针
oldcout == cout.rdbuf(fout.rdbuf());
cout << a << endl; // 写入out.txt
// 还原标准输入输出流, 恢复键盘输入和输出
cin.rdbuf(oldcin);
cout.rdbuf(oldcout);
// 打开的文件要手动关闭
fin.close();
fout.close();
return 0;
}
6.3 控制台实现重定向
这个的意思是在控制到执行.exe的时候, 通过后面添加参数的方式实现重定向。
比如写个程序:
#include <iostream>
#include <string>
using namespace std;
int main()
{
string name, url;
cin >> name >> url;
cout << name << '\n' << url;
return 0;
}
此时编译链接, 会生成一个demo.exe的可执行文件。 然后再控制台执行这个可执行文件的时候,后面指定上参数:
C:\Users\mengma>D:\demo.exe <in.txt >out.txt
执行后会发现,控制台没有任何输出。这是因为,我们使用了"<in.txt"对程序中的 cin 输入流做了重定向,同时还用 ">out.txt"对程序中的 cout 输出流做了重定向。
7. C++管理输出缓冲区
每个输出流都管理一个缓冲区,用来保存程序读写的数据。比如下面代码:
cout << "hello world";
字符串可能立即打印,也有可能os先保存到缓冲区,然后再打印。
有了缓冲机制,os可以将程序多个输出操作组合成单一的系统级写操作。 这样可以带来性能提升,因为写操作可能很耗时。
导致缓冲区刷新(数据真正写到输出设备或文件)的原因如下:
- 程序正常结束,作为
main()函数的return操作的一部分, 缓冲刷新被执行。 - 缓冲区满时, 需要刷新缓冲区
- 使用操纵符如endl来显式刷新缓冲区
- 在每个输出操作之后,可以用操纵符unitbuf设置流的内部状态,来清空缓冲区。 默认情况下,对cerr是设置unitbuf的,因此写到cerr得的内容都是立即刷新
- 一个输出流可能被关联到另一个流。这种情况下,当读写被关联的流时, 关联到的流的缓冲区会被刷新。 默认情况下,cin和cerr都关联到cout。 因此读cin或者写cerr都会导致cout的缓冲区被刷新。
后三个详细理解下。
7.1 操纵符显示刷新
之前使用过操作符endl, 它完成换行并刷新缓冲区的工作。 IO库中还有两个类似操作符flush和ends:
- flush刷新缓冲区,但不输出任何额外的字符。 值得一提,cout 所属 ostream 类中还提供有
flush()成员方法,它和 flush 操纵符的功能完全一样,仅在使用方法上(cout.flush())有区别。 - ends向缓冲区插入一个空字符, 然后刷新缓冲区
比如:
cout << "hi!" << endl; //输出hi和一个换行,然后刷新缓冲区
cout << "hi!" << flush; //输出hi,然后刷新缓冲区,不附加任何额外字符 等价于cout << "hi!"; cout.flush();
cout << "hi!" << ends; //输出hi和一个空字符,然后刷新缓冲区
7.2 unitbuf操作符
如果想在每次输出操作后都刷新缓冲区,我们可以使用 unitbuf 操作符,它告诉流在接下来的每次写操作之后都进行一次 flush 操作。而 nounitbuf 操作符则重置流, 使其恢复使用正常的系统管理的缓冲区刷新机制:
cout << unitbuf; //所有输出操作后都会立即刷新缓冲区
//任何输出都立即刷新,无缓冲
cout << nounitbuf; //回到正常的缓冲方式
如果程序异常终止, 输出缓冲区是不会被刷新的。
当调试一个已经崩溃的程序时,需要确认那些你认为已经输出的数据确实已经刷新了。否则,可能将大量时间浪费在追踪代码为什么没有执行上,而实际上代码已经执行了,只是程序崩溃后缓冲区没有被刷新,输出数据被挂起没有打印而已。
7.3 关联输入和输出流
当一个输入流被关联到一个输出流时, 任何试图从输入流读取数据的操作都会先刷新关联的输出流。 标准库的cout和cin关联在一起,所以执行:
cin >> name;
会导致cout的缓冲区被刷新。
交互式系统通常应该关联输入流和输出流。这意味着所有输出,包括用户提示信息,都会在读操作之前被打印出来。
tie()函数可以用来绑定输出流:
ostream* tie ( ) const; //返回指向绑定的输出流的指针。
ostream* tie ( ostream* os ); //将 os 指向的输出流绑定的该对象上,并返回上一个绑定的输出流指针。
我们可以将一个istream对象关联到另一个ostream, 也可以将一个ostream关联到另一个ostream。
cin.tie(&cout); //仅仅是用来展示,标准库已经将 cin 和 cout 关联在一起
//old_tie 指向当前关联到 cin 的流(如果有的话)
ostream *old_tie = cin.tie(nullptr); // cin 不再与其他流关联
//将 cin 与 cerr 关联,这不是一个好主意,因为 cin 应该关联到 cout
cin.tie(&cerr); //读取 cin 会刷新 cerr 而不是 cout
cin.tie(old_tie); //重建 cin 和 cout 间的正常关联
在这段代码中,为了将一个给定的流关联到一个新的输出流,我们将新流的指针传递给了 tie()。为了彻底解开流的关联,我们传递了一个空指针。每个流同时最多关联到一个流, 但多个流可以同时关联到同一个ostream。
8. C++读取单个字符(get)和读入字符串(getline)
上面整理的输出, 下面我们看输入部分。
int get();
get()函数是istream类的成员函数, 用于从输入流中读入一个字符,返回该值字符的ASCII码。如果碰到输入的末尾, 就返回EOF。
EOF是End of File的缩写。 istream类从输入流读取数据的成员函数, 在把输入数据都读取完后,再进行读取就返回EOF。 EOF是iostream类中定义的一个整型常量,值为-1
这个让我想起了这个语句:
int c;
while (c = cin.get() != EOF){
cout.put(c);
}
get()函数不会跳过空格,制表符,回车等特殊字符,所有字符都能被输入。
如果要读取文件的字符, 可以使用上面重定向的知识:
int c;
freopen("test.txt", "r", stdin);
while ((c=cin.get()) != EOF){
cout.put(c);
}
那么,如果想读入一行字符串怎么办呢?
这时候,就可以用getline()函数。
istream &getline(char *buf, int bufSize); // 从输入流读取bufSize-1个字符到缓冲区buf,或遇到\n位置。 函数会自动在buf读入数据的结尾添加\0
istream &getline(char *buf, int bufSize, char delim); // 这个是读到delim字符位置, 而不是读到\n了,并且\n和delim字符都不会读入到buf,但会被从输入流中取走
两个函数返回值就是函数所作用的对象的引用。如果输入流中\n或delim之前的字符个数达到bufSize, 就会导致读入出错,结果是: 虽本次读入已经完成,但之后的读入会失败。
从输入流读入一行,可以用上面第一个, cin>>str这个不行,因为这种读法遇到行中的空格或制表符就会停止,因此不能保证str读入的是整行。 像get, getline这种,也称为非格式化输入方法。因为它们只是读取字符输入,并不会跳过空白,也不会转换数据格式。
下面看一个例子:
char szBuf[20];
int n = 120;
// 如果输入流中一行字符超过5个,就会出错
if (!cin.getline(szBuf, 6))
cout << "error" << endl;
cout << szBuf << endl;
// 测试下还能不能读入了
cin >> n;
cout << n << endl;
// clear能清楚cin内部的错误,使之恢复正常
cin.clear()
cin >> n;
cout << n << endl;
测试一:

这个没有任何问题, 因为一开始ab cd,这一行输入流中字符没超过5, getline不会出错,下面的都能正常读入。
测试二:

这个就出问题了, 第一行的输入ab cd123456k是不符合cin.getline(szBuf, 6)的,所以这个会直接保存,但是呢? 这个函数依然会把ab cd四个字符读入给到szBuf。但后面n这个就不能正常读入了,所以n这个直接是输出默认值120. 当执行cin.clear()之后, 消除错误,恢复正常,此时又能正常读入, 但此时从错误出开始, 读入了123456, 因为n定义的是整数,所以k不会被读进来。
可以用 getline() 函数的返回值(为 false 则输入结束)来判断输入是否结束。例如,要将文件 test.txt 中的全部内容(假设文件中一行最长有 10 000个字符)原样显示
const int MAX_LINE_LEN = 10000; //假设文件中一行最长 10000 个字符
int main()
{
char szBuf[MAX_LINE_LEN + 10];
freopen("test.txt", "r", stdin); //将标准输入重定向为 test.txt
while (cin.getline(szBuf, MAX_LINE_LEN + 5))
cout << szBuf << endl;
return 0;
}
程序每次读入文件中的一行到 szBuf 并输出。szBuf 中不会读入回车符,因此输出 szBuf 后要再输出 endl 以换行。
9.C++跳过指定字符ignore及查看输入流中的下一个字符peek
ignore()是istream类成员函数,原型
istream & ignore(int n =1, int delim = EOF);
此函数的作用是跳过输入流中的 n 个字符,或跳过 delim 及其之前的所有字符,哪个条件先满足就按哪个执行。两个参数都有默认值,因此 cin.ignore() 就等效于 cin.ignore(1, EOF), 即跳过一个字符。
该函数常用于跳过输入中的无用部分,提取有用部分。
int n;
cin.ignore(5, 'A');
cin >> n;
cout << n;
// 输入abcde34 跳过5个字符, n=34
// 输入abA67 先遇到了A, 跳过abA, n=67
peek()函数是istream类成员函数,原型:
int peek();
这个函数返回输入流中的下一个字符,但并不会将该字符重输入流中取走。 类似于栈的gettop()。
cin.peek()不会跳过输入流中的空格,回车符。输入流已经结束的情况下, cin.peek()返回EOF。
在输入数据的格式不同,需要预先判断格式再决定如何读取输入时,peek() 就能起到作用。
比如编写一个日期转换函数, 输入是若干个日期, 每行一个,有中式格式"2011.12.24"也有西式格式"Dec 24 2011",而输出全部转成"yyyy-mm-dd"的格式。
这时候在读入之前,就需要先试探一下是大写字母开头,还是数字开头,先把西式和中式分开, 然后再cin了。 具体代码如下:
#include <iostream>
#include <iomanip>
#include <string>
using namespace std;
string Months[12] = { "Jan","Feb","Mar","Apr","May","Jun","Jul","Aug", "Sep","Oct","Nov","Dec" };
int main()
{
int c;
// 先进行试探 取输入流中第一个字符先看看
while ((c = cin.peek()) != EOF){
cout << char(cin.peek()) << " ";
int year, month, day;
// 美国日期格式
if (c >= 'A' && c <= 'Z'){
string sMonth;
cin >> sMonth >> day >> year;
// 转成中式月份
for (int i=0; i<12; i++){
if (sMonth == Months[i]){
month = i + 1;
break;
}
}
}else{
// 中国日期格式
cin >> year;
cin.ignore() >> month; // ignore忽略.
cin.ignore() >> day;
}
cin.ignore(); // 跳过末尾的'\n'
cout << setw(4) << year << "-" << setfill('0') << setw(2) << month << "-" << setw(2) << day << endl;
}
}
结果如下:

10. C++ cin如何判断输入结束?
cin 可以用来从键盘输入数据;将标准输入重定向为文件后,cin 也可以用来从文件中读入数据。在输入数据的多少不确定,且没有结束标志的情况下,该如何判断输入数据已经读完了呢?
文件末尾,还是 Ctrl+Z 或者 Ctrl+D,它们都是结束标志;cin 在正常读取时返回 true,遇到结束标志时返回 false,我们可以根据 cin 的返回值来判断是否读取结束。
int main()
{
int n;
int maxN = 0;
while (cin >> n){ //输入没有结束,cin 就返回 true,条件就为真
if (maxN < n)
maxN = n;
}
cout << maxN <<endl;
return 0;
}
cin>>n的返回值的确是 istream & 类型的,而 while 语句中的条件表达式的返回值应该是 bool 类型、整数类型或其他和整数类型兼容的类型,istream & 显然和整数类型不兼容,为什么while(cin>>n)还能成立呢?
这是因为,istream 类对强制类型转换运算符 bool 进行了重载,这使得 cin 对象可以被自动转换成 bool 类型。所谓自动转换的过程,就是调用 cin 的
operator bool()这个成员函数,而该成员函数可以返回某个标志值,该标志值在 cin 没有读到输入结尾时为 true,读到输入结尾后变为 false。
如果cin在读取过程中发生了错误, cin>>n表达式也会返回false,比如一个int型的n,输入进去的是个字母。
11. C++处理输入输出错误
这一块目前用的不多, 详细的可以去中文网的文档中看,这里简单整理下C++中会把输入输出时发生的错误归为四类,称为流状态,并且用四个标志位来表示,而每个标志位都对应着检测函数。
| 检测函数 | 对应的标志位 | 说明 |
|---|---|---|
| good() | goodbit | 操作成功,没有发生任何错误 |
| eof() | eofbit | 到达输入末尾或文件末尾 |
| fail() | failbit | 发生某些意外错误,比如要读入一个数字,却读入了字符 |
| bad() | badbit | 发生严重错误,比如磁盘读故障 |
这时候,我们想让程序更加鲁棒的话,就应该考虑到这些问题,并及时采取相应的方案,下面是一个简单例子:
//从 ist 中读入整数到 v 中,直到遇到 eof() 或终结符
void fill_vector(istream& ist, vector<int>& v, char terminator){
for( int i; ist>>i; ) v.push_back(i);
//正常情况
if(ist.eof()) return; //发现到了文件尾,正确,返回
//发生严重错误,只能退出函数
if (ist.bad()){
error("cin is bad!"); //error是自定义函数,它抛出异常,并给出提示信息
}
//发生意外情况
if (ist.fail()) { //最好清除混乱,然后汇报问题
ist.clear(); //清除流状态
//检测下一个字符是否是终结符
char c;
ist>>c; //读入一个符号,希望是终结符
if(c != terminator) { // 非终结符
ist.unget(); //放回该符号
ist.clear(ios_base::failbit); //将流状态设置为 fail()
}
}
}
12. 小总
这里依然是一张思维导图拎起来:



![[算法前沿]--019-医学AIGC大模型的构建](https://img-blog.csdnimg.cn/f55dacddfa08465a8bc64edd8cb461a2.png)