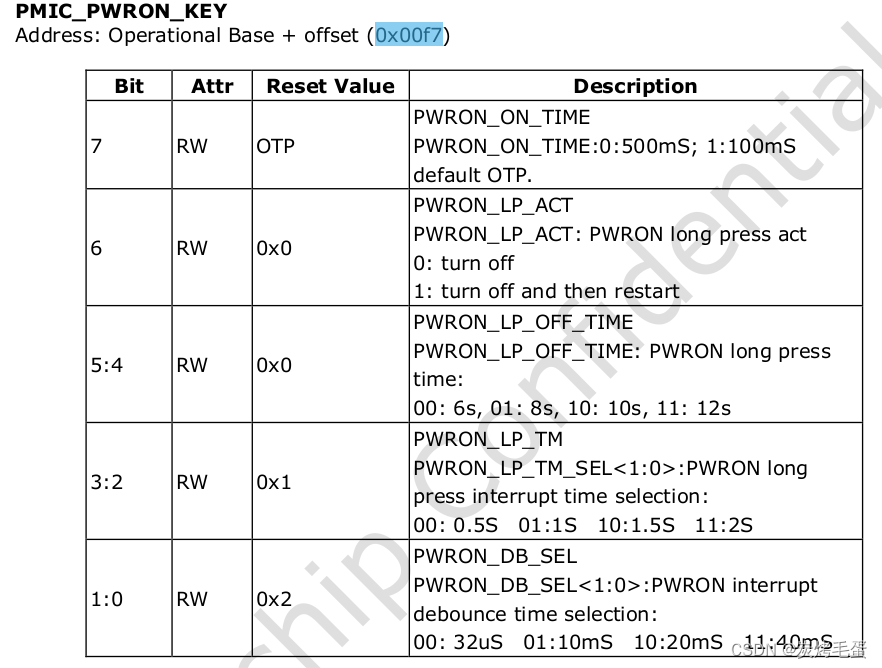
扩缩容和副本均衡
对于集群节点发生变化(扩缩容)时,集群内部的tablet是如何以一定的策略完成数据的重分布,从而达到每个be能够分布尽可能数量相同的tablet。同时,集群内部某些tablet由于某些原因发生损坏时,这些tablet的自动修复工作又是如何进行的呢?为什么通常需要推荐三副本,不采用2副本或者1副本存储?这个和副本自动修复机制有什么关联吗?
一 一来看上面的问题之前,我们先看一下整个tablet管理的流程。下面是一个tablet被工作的流程:
- 首先,所有的tablet副本的元数据管理都在FE节点中的META中,对于这些tablet的状态感知,是靠FE进行的。这里也有一个额外的点,如果tablet的数量很大的话,对于FE的元数据存储会有一定的压力,FE的内存使用会变高。
- 同时,负责检测tablet状态的工作也是由FE进行的,FE会维护一个叫做TabletChecker的常驻后台进程,定期的去检测tablet的状态。
- 其次,负责真正进行tablet调度的是由BE进程维护的TabletScheduler常驻进程,他会不断的接受由FE的TabletChecker发送过来的需要进行调度的tablet的上下文,由TabletScheduler进程决定具体的调度执行策略。
流程图如下:

集群缩容
在了解了tablet调度的大概流程之后,我们来看一下集群在缩容(BE缩容)时,大概发生了一些什么事情吧。
- 用户提交 DECOMMISSION 缩容语句;
- FE在接收到相关请求语句后,会把语句中对应的BE节点下线,同时将这些节点上的所有tablet的状态标记为unhealthy的状态;
- FE维护的后台常驻进程TabletChecker检测到有不健康的副本后,触发tablet调度流程,将这些不健康的tablet的上下文信息发送给TabletScheduler进程;
- TabletScheduler根据副本调度策略,根据已有的BE节点资源情况计算,将对应的tablet的clone task任务发送到对应的BE节点上,进行tablet的clone工作;
- 等到对应的tablet clone任务结束后,对应tablet的副本被补齐之后,FE中meta 维护的对应的tablet的元数据信息就是正常的,此时需要下线的BE节点也就会被DROP掉了;
集群扩容
集群扩容又做了哪些操作呢?
相比较集群缩容,副本均衡的策略主要 依赖于将需要下线的BE节点上的所有的tablet的状态标记为unhealthy来触发tablet的调度流程。
集群扩容主要是基于新增的BE节点的资源状态来触发BE节点的负载均衡的来完成副本调度流程的。
BE节点的负载均衡策略(解释来源Doris官网文档:数据副本管理):
我们用 ClusterLoadStatistics(CLS)表示一个 cluster 中各个 Backend 的负载均衡情况。TabletScheduler 根据这个统计值,来触发集群均衡。我们当前通过 磁盘使用率 和 副本数量 两个指标,为每个BE计算一个 loadScore,作为 BE 的负载分数。分数越高,表示该 BE 的负载越重。
磁盘使用率和副本数量各有一个权重系数,分别为 capacityCoefficient 和 replicaNumCoefficient,其 和衡为1。其中 capacityCoefficient 会根据实际磁盘使用率动态调整。当一个 BE 的总体磁盘使用率在 50% 以下,则 capacityCoefficient 值为 0.5,如果磁盘使用率在 75%(可通过 FE 配置项 capacity_used_percent_high_water 配置)以上,则值为 1。如果使用率介于 50% ~ 75% 之间,则该权重系数平滑增加,公式为:
capacityCoefficient= 2 * 磁盘使用率 - 0.5
该权重系数保证当磁盘使用率过高时,该 Backend 的负载分数会更高,以保证尽快降低这个 BE 的负载。
TabletScheduler 会每隔 20s 更新一次 CLS。
因此,在新加入BE节点后,该BE节点的负载分数就会很低,就会触发负载均衡任务,进行下面的操作。
TabletScheduler 在每轮调度时,都会通过 LoadBalancer 来选择一定数目的健康分片作为 balance 的候选分片。在下一次调度时,会尝试根据这些候选分片,进行均衡调度。
副本修复
副本损坏大部分主要发生在数据导入的过程中,由于某些原因造成某个tablet的副本可能存在损坏,亦或者在频繁的进行异步schema change任务时导致的副本损坏。副本损坏时,FE维护的元数据信息中,对应的tablet的状态会变为unhealthy,此时,集群内部如果是三副本的情况,调度器会找到这个tablet对应的正常的副本,然后执行clone任务,clone完成后,再将这个不正常的副本删除,此时副本修复就完成了。因此,副本修复是需要依赖于集群中对应的tablet是有正常的副本的,否则无法进行正常的副本修复流程,此时可能就需要用户手动将对应tablet所在的分区的数据进行删除重导,重新生成tablet了。
为何要三副本?
结合上面的流程来看,三副本的重要性很大。它主要体现在:
-
提供一定的数据容灾能力。
将一份数据的多个数据副本尽可能的分散在不同的物理机器上,当由于某些问题造成对应机器发生硬件问题时,能够保证集群的数据仍旧可读可写,不影响正常的数据业务。
-
尽可能的负载均衡,利用到集群中的每一个计算节点(BE节点)。
同一份数据会被打散在多台机器上存储,根据一定的负载均衡策略,能够保证每个BE都能够存储大致相同量的数据,在发生计算任务的时候,不会由于数据分布不均匀造成某些BE查询压力过大,导致局部干活,其余看戏的现象。
-
副本修复依赖于三副本
原理同副本修复章节。
-
特殊查询场景加速
colocate join 和replicate join 对于参与join的数据分布的副本数也有一定要求(不一定是三副本)




![[每周一更]-(第50期):Go的垃圾回收GC](https://img-blog.csdnimg.cn/7460d825f5254b5b951e39f88ad755dc.jpeg#pic_center)