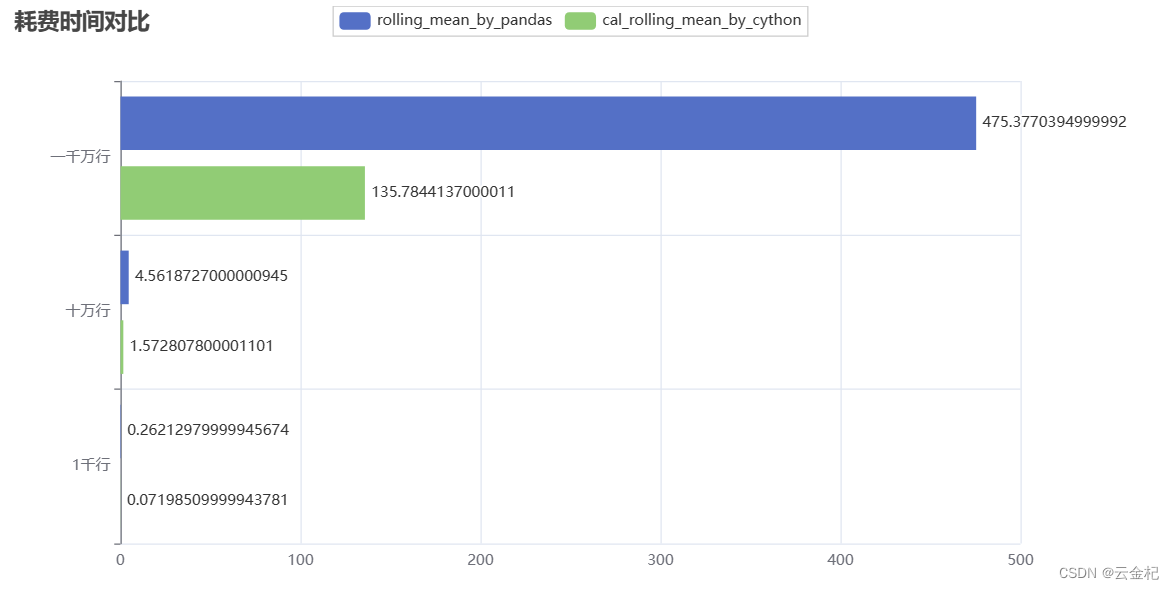
先上图来说明pandas.rolling(n).mean()滚动求均值的方法效率其实并不是最高的,我自己尝试使用cython把滚动求均值的方法重新编译了一下,发现效率总体上是pandas的三倍以上。
总结:pandas比较合适用于普通的研究分析工作,如果用到追求高效率的生产环境中,需要考虑要不要改写具体的函数。
代码:
效率对比代码:
import numpy as np
import pandas as pd
import time
from pyecharts import options as opts
from pyecharts.charts import Bar
from cal_rolling_mean_by_cython import cal_rolling_mean_by_cython
# n_rows = 100
# n_times = 1000
# np.random.seed(1)
# df = pd.DataFrame({i: np.random.randn(n_rows) for i in ['open', 'high', 'low', 'close', 'volume']})
# df['ma_1'] = df['close'].rolling(20).mean()
# df['ma_2'] = cal_rolling_mean_by_cython(df['close'].to_numpy(), 20)
# df = df.dropna()
# a = list(df['ma_1'])
# b = list(df['ma_2'])
# if not a[0] == b[0]:
# print(a[0], b[0])
# print(df[['ma_1', 'ma_2']])
# assert list(df['ma_1']) == list(df['ma_2'])
# 经过验证,发现数据精度存在不同,在无数位小数点之后,存在不一样的情况,如0.22949341595210063 != 0.22949341595210065
def test_func_time(n_rows, n_times=1000):
df = pd.DataFrame({i: np.random.randn(n_rows) for i in ['open', 'high', 'low', 'close', 'volume']})
# 测试np.where的效率
begin_time = time.perf_counter()
for i in range(n_times):
df['ma_1'] = df['close'].rolling(20).mean()
end_time = time.perf_counter()
consume_time_where = end_time - begin_time
print(f"rolling.mean耗费的时间:{consume_time_where}")
# 测试np.select的效率
begin_time = time.perf_counter()
for i in range(n_times):
df['ma_2'] = cal_rolling_mean_by_cython(df['close'].to_numpy(), 20)
end_time = time.perf_counter()
consume_time_select = end_time - begin_time
print(f"cal_rolling_mean_by_cythont耗费的时间:{consume_time_select}")
# assert df['ma_1'].equals(df['ma_2']), "检查错误"
return [consume_time_where, consume_time_select]
if __name__ == '__main__':
r1 = test_func_time(n_rows=1000)
r2 = test_func_time(n_rows=100000)
r3 = test_func_time(n_rows=10000000)
c = (
Bar()
.add_xaxis(["1千行", "十万行", "一千万行"])
.add_yaxis("rolling_mean_by_pandas", [r1[0], r2[0], r3[0]])
.add_yaxis("cal_rolling_mean_by_cython", [r1[1], r2[1], r3[1]])
.reversal_axis()
.set_series_opts(label_opts=opts.LabelOpts(position="right"))
.set_global_opts(title_opts=opts.TitleOpts(title="耗费时间对比"))
#.render("d:/result/夏普率耗费时间对比.html")
.render("./rolling_mean_by_pandas和cal_rolling_mean_by_cython耗费时间对比.html")
)
计算滚动平均的cython代码文件:cal.pyx
#cython: language_level=3
#distutils:language=c
#cython: c_string_type=unicode, c_string_encoding=utf8
import numpy as np
from numpy import NaN as nan
cimport numpy as np
cimport cython
@cython.boundscheck(False)
@cython.wraparound(False)
@cython.cdivision(False)
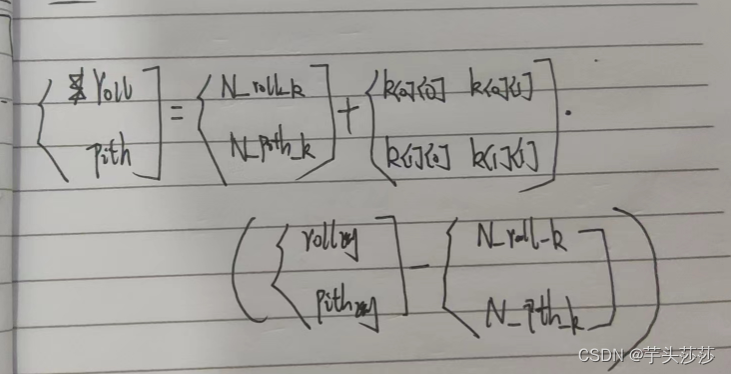
cpdef cal_rolling_mean_by_cython(np.ndarray[np.double_t, ndim=1] arr,int look_back_days):
cdef int data_len = arr.shape[0]
cdef np.ndarray[np.double_t, ndim=1] result = np.empty(data_len)
cdef int i
cdef int j
cdef double sum=0.0
for i in range(look_back_days-1):
result[i] = nan
for i in range(look_back_days-1, data_len):
sum = 0.0
for j in range(i-look_back_days+1,i+1):
sum += arr[j]
result[i] = sum/look_back_days
return result
#def
setup.py
from setuptools import setup, Extension
from Cython.Build import cythonize
import numpy as np
import sys
ext = Extension(
"cal_rolling_mean_by_cython", sources=["cal.pyx"],
include_dirs=[np.get_include()],
language='c'
)
setup(name="cal_rolling_mean_by_cython", ext_modules=cythonize([ext]))