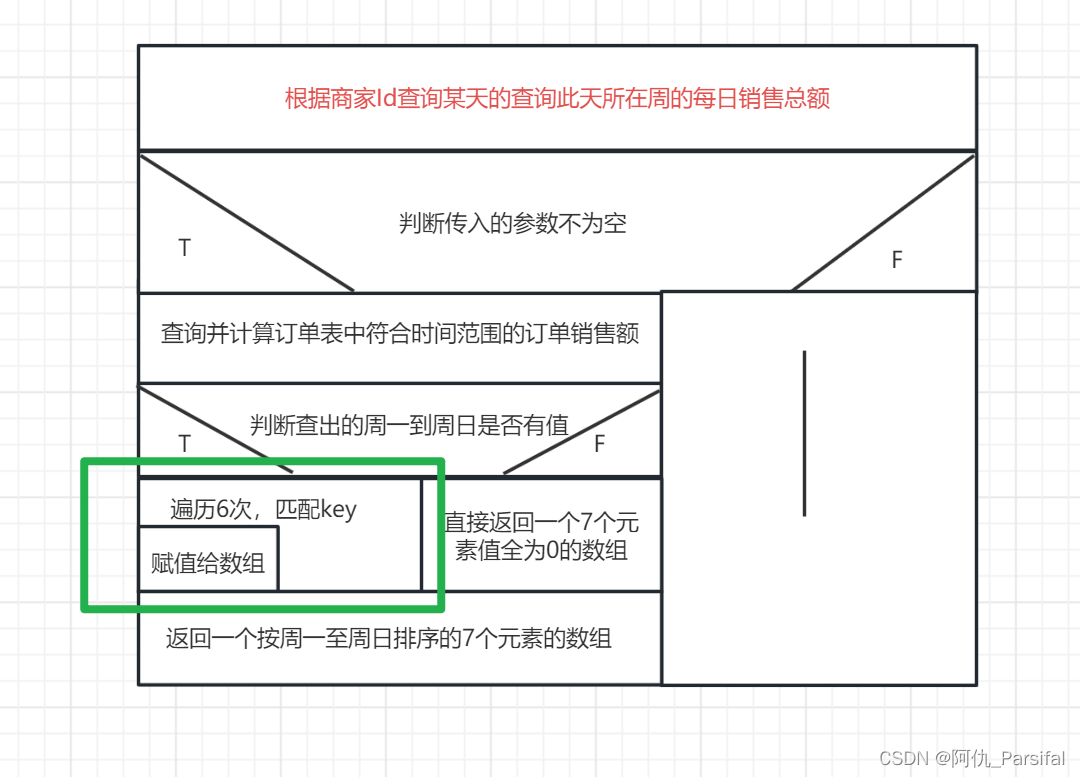
容量单位从小到大的顺序依次为:TB、PB、EB、ZB。
.
用于设置环境变量的文件是 .bash_profile
.
将HDFS文件下载到本地的命令是 hadoop fs -get。
.
不需要Java环境的支持是 MySQL
.
通配符是用于模糊匹配的特殊字符,可以在关键字查询中使用。在MySQL中,通配符主要有两种:% 和 _ 。其中,% 代表匹配任意多个字符(包括0个字符),_ 则代表匹配单个字符。
.
HBase 、Redis 和 MongoDB 都是常见的NoSQL数据库(非关系型数据库)
传统的关系型数据库:Oracle、MySQL、SQL Server
.
将 MySQL 中的数据传递到 HDFS,使用 Sqoop 的 import 命令。
.
Crontab、Oozie、Azkaban 都是常见的任务调度工具,可以用于执行定时、周期性或事件触发的任务。
虽然 Hive 可以通过编写脚本实现定时任务调度,但它本身并不是一个专门用于任务调度的工具。
.
Echarts:基于JavaScript的数据可视化图表库。由百度开发,现已成为Apache顶级项目。支持丰富的图表类型。
Echarts主要用于数据可视化,而不是数据的分析处理。
.
HBase 可以有列,可以没有列族(column family)。
.
HDFS 中的 block 默认保存 3 个备份。
.
Hadoop作者:Doug cutting
.
HDFS2.7.*以后 默认 Block Size 大小是 128MB
.
HDFS是一个分布式文件系统,它能够存储大规模数据,并通过多台机器之间的数据复制来提供高可靠性和高可用性的数据访问。
MapReduce是一种分布式计算模型,它能够高效处理大规模数据集。MapReduce将数据划分成一系列的键值对,并通过Map和Reduce两个阶段完成数据的处理和计算。
Yarn是一个资源管理器,它为分布式计算框架提供统一的资源管理和调度服务。通过Yarn,用户可以高效地利用集群中的计算资源,运行各种复杂的分布式计算任务,例如MapReduce、Spark、Flink等分布式计算框架。Yarn将集群中的计算资源划分为资源池,并为不同的应用程序分配和管理资源。
.
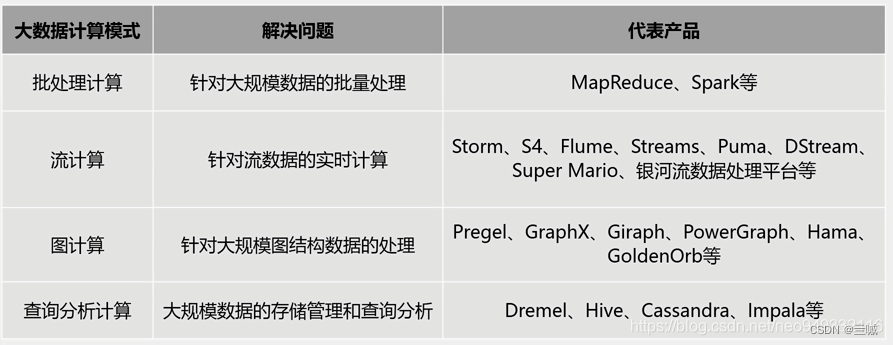
.
大数据、云计算和物联网是三个密切相关的概念。大数据需要云计算提供的计算和存储资源进行处理和分析,而物联网需要大数据和云计算提供的技术支持进行设备互联和数据传输。三者相互依存、相互促进,是数字化转型和智能化发展的重要基础。
.
Hadoop生态系统中的五个重要组件:
1、HDFS:Hadoop分布式文件系统,用于存储大规模数据集。
2、MapReduce:Hadoop分布式计算框架,用于处理大规模数据集。
3、YARN:Hadoop的资源管理系统,用于管理计算集群的资源分配和任务调度。
4、HBase:Hadoop生态系统中的分布式NoSQL数据库,用于存储非结构化和半结构化数据。
5、Hive:Hadoop生态系统中的数据仓库系统,用于查询和分析大规模数据集。
.
HBase是一个分布式的、面向列的、基于列族存储的NoSQL数据库,具有以下特点:
1、海量存储,可以存储大批量的数据
2、列(簇)式存储,数据是基于列族进行存储的
3、极易扩展,可以通过增加服务器来提高集群的存储能力
4、高并发,支持高并发的读写请求
5、稀疏,可以指定任意多的列,在列数据为空的情况下,不会占用存储空间
.
Hadoop的安装步骤:
1、下载Hadoop:从官方网站上下载适合自己操作系统的Hadoop安装包,并解压到本地目录。
2、解压 Hadoop 至本地。
3、配置环境变量:将Hadoop的bin目录添加到系统的PATH环境变量中,以便在终端中可以直接运行Hadoop命令。
4、配置Hadoop:修改Hadoop的配置文件,包括core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml等。这些文件中包含了Hadoop的各种配置参数,需要根据实际情况进行修改。
5、格式化HDFS:在Hadoop集群中的一个节点上运行hdfs namenode -format命令,格式化HDFS文件系统。
6、启动Hadoop:在Hadoop集群中的一个节点上运行start-all.sh命令,启动Hadoop的各个组件,包括HDFS、YARN、MapReduce等。
7、验证Hadoop:在浏览器中打开Hadoop的Web界面,可以查看Hadoop的运行状态和资源使用情况,并提交MapReduce任务进行测试验证。
.
Eclipse下开发web项目的步骤:
1、创建Web项目:在Eclipse中选择File -> New -> Dynamic Web Project,输入项目名称、目标运行时环境和项目位置等信息,创建Web项目。
2、配置项目:在项目的Properties中配置Web项目的相关信息,包括Servlet版本、部署描述符、Java Build Path等。
3、添加Servlet:在项目中创建Servlet类,实现Servlet接口,处理HTTP请求和响应,可以使用Eclipse的Servlet模板来快速生成代码。
4、编写JSP页面:在项目中创建JSP页面,使用HTML和Java代码来组织页面,可以使用Eclipse的JSP模板来快速生成代码。
5、部署项目:在Eclipse中右键点击项目,选择Run As -> Run on Server,选择目标服务器和端口号,将Web项目部署到服务器上运行。
6、调试项目:在Eclipse中可以使用调试器来调试Web项目,包括设置断点、单步执行、查看变量值等操作。
7、导出WAR包:在Eclipse中可以将Web项目导出为WAR包,以便在其他环境中部署和运行。
.
叙述大数据分析处理的完整过程及每个过程采用的技术:
1、数据采集:在数据采集阶段,需要从各种来源(如传感器、社交媒体、日志文件等)收集大量的数据,并将其存储在数据仓库或数据湖中。常用的数据采集技术包括Kafka、Flume、Logstash等。
2、数据清洗:在数据清洗阶段,需要对采集到的数据进行去重、过滤、转换、归一化等处理,以便后续的数据分析。常用的数据清洗技术包括Hadoop MapReduce、Pig、Spark等。
3、数据存储:在数据存储阶段,需要将清洗后的数据存储在数据仓库或数据湖中,以便后续的数据处理和分析。常用的数据存储技术包括Hadoop HDFS、HBase、Cassandra、MongoDB等。
4、数据处理:在数据处理阶段,需要对存储在数据仓库或数据湖中的数据进行处理和分析,以提取有价值的信息。常用的数据处理技术包括Hadoop MapReduce、Spark、Hive、Impala等。
5、数据可视化:在数据可视化阶段,需要将处理后的数据以图表、报表等形式展示出来,以便用户进行交互式的分析和探索。常用的数据可视化技术包括Tableau、D3.js、Echarts等。
6、数据挖掘:在数据挖掘阶段,需要利用机器学习、人工智能等技术,对数据进行深度挖掘,以发现数据中隐藏的规律和趋势。常用的数据挖掘技术包括TensorFlow、Scikit-learn、Weka等。
.
程序要在hadoop集群环境下运行需要先打包再提交运行,写出提交命令:
hadoop jar student1.jar Student1Driver <input_path> <output_path>;
.
利用 Hive 实现加载数据的命令:
LOAD DATA INPATH ‘/path/to/student_scores.txt’ OVERWRITE INTO TABLE student_scores;
将/student_scores.txt文件中的数据加载到student_scores表中,并覆盖原有的数据。