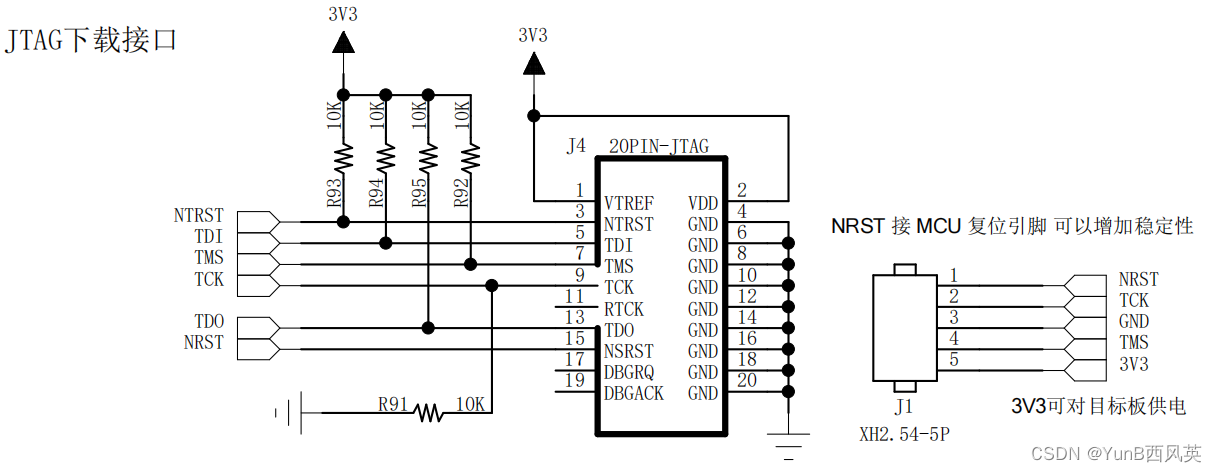
一、简介
数据库索引是现代数据库中高效数据检索的一个重要工具。它在优化查询性能和加快数据检索操作方面发挥着重要作用。这里我们深入了解下数据库索引其内部工作原理、优点和局限性。
二、数据库
1、SQL 数据库
为了理解索引,先说一句数据库,数据库是可靠地插入、存储、更新、检索和删除数据的一种有组织的方式。它们的工作方式是将有关各种实体的信息存储在表中,每个表由行和列组成:

2、表结构和列
在表中,数据被组织成行,每行代表一个记录或条目。另一方面,列定义这些记录的各种属性或属性。为了说明这一点,让我们看下面这个包含三列的简单表:ID、电子邮件和名称。

从我们的需求考虑触发,列大概就需要以下3种类型之一:
- 主键 – 每个表只有一个,它通过唯一值标识表的每个条目
- 唯一列 – 每个表零、一个或多个,它定义了一个恰好对每一行唯一的属性
- 非唯一列 – 每个表零、一个或多个,它定义了一个可以重复的属性
因此,每个用户都由他的ID标识,具有唯一的电子邮件地址,并且还具有其他用户可能碰巧相同的名称。
三、索引
让我们接着聊聊索引。当我们为列编制索引时,我们就可以更快地进行搜索,需要为此付出的代价是创建额外的数据结构。这使得对大量数据的所有搜索都明显加快。
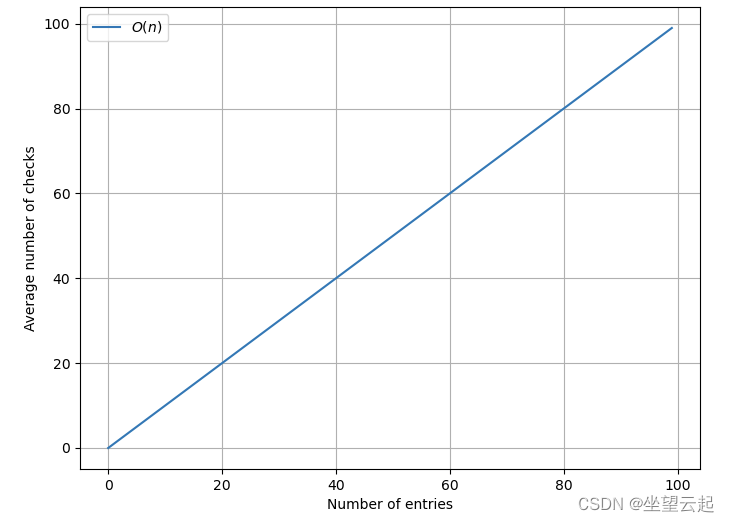
1、搜索非唯一列
假设我们要查找名为“Michael”的用户。由于多个用户可以具有此名称,因此我们需要遍历表中的所有行,以确保找到所有行。
如果有n行,我们需要平均花费O(n)时间才能找到答案。
下图显示了我们在标准列中找到项目的速度:
2、搜索唯一列
假设我们要查找具有“michael.scott@gmail.com”电子邮件地址的用户。由于电子邮件应该是唯一的,因此我们可以在找到具有所需值的行后立即停止搜索。
如果有n行,我们需要平均花费时间,才能找到答案。
下图显示了我们在唯一列中找到项目的速度:

3、 搜索主键
假设我们要查找 ID 等于 4291 的用户。仅仅因为 ID 是主键,我们搜索步骤明显减少。事实上,如果有n行,我们需要花费平均时间以找到答案。最后,下图显示了使用主键列进行搜索的性能:

对比以上这3种情况,我们可以看看下表:

是其中最快的,而且对于大型数据库来说,它与其他2个版本之间的差异变得天文数字。 这可能是等待查询几秒钟而不是几个小时之间的区别。
4、搜索索引列
索引的思想是使通过特定列的搜索与通过主键的搜索一样快。
假设检查数据库中是否存在电子邮件地址是我们经常执行的操作,然后我们应该对其进行优化。我们不希望将主键 ID 替换为电子邮件列,因为我们希望允许用户更改其电子邮件地址而不会丢失其标识。
在此情况下,解决方案就是在电子邮件列上创建数据库索引。
下表显示了我们需要进行的平均检查次数与查询中使用的列类型之间的时间差异:

四、性能
介绍在确定特定列是否需要索引时应考虑的几个性能注意事项。
我们将从以下用户表开始,该表最初没有应用索引:

1、索引多列
索引的主要目的是大大提高数据库检索的性能。但是,需要做出权衡。虽然每个涉及具有索引的列的查询都快得多,但每个数据库插入、更新或删除都会变慢。我们拥有的索引越多,修改条目所需的时间就越多,不仅如此,每个条目占用的空间要多得多。
考虑到这一点,我们可以考虑索引“电话”和“电子邮件”列(下图中加粗显示),因为这些列在用户登录时非常有用:

我们不应该做的是索引“名称”和“地址”列。这是典型的矫枉过正,因为使用他的地址或名字快速找到用户可能不是一个现实的应用程序需求。
2、索引低基数列
在基数较低的列(意思是与记录总数相比,它们他们只具有少量非重复值,比如Male和Female)创建索引意义不大。在这种情况下,索引可能不会提供显著的性能改进,因为它无论如何都会导致扫描表的大部分。在决定是否创建索引之前,评估列的基数和唯一性非常重要。
因此,在“性别”列上索引我们的表格将非常无效,因为它只有两个可能的值:Male和Female。
五、小结
通过创建高效的数据结构并在搜索期间利用它们,索引可显著降低查询的时间复杂度。它允许快速访问特定记录,尤其是在涉及唯一或主键列的情况下。