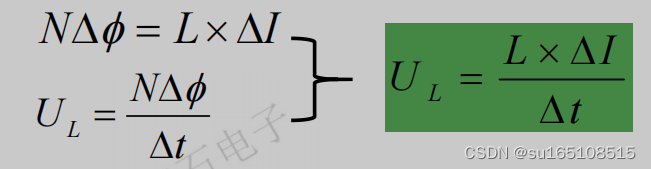Few-shot Image Generation via Adaptation-Aware Kernel Modulation
公众号:EDPJ
目录
0. 摘要
1. 简介
2. 相关工作
3. 通过源-目标域接近度的视角重新审视 FSIG
3.1 源-目标域邻近度分析
3.2 临近假设松弛下的 FSIG 方法
4. 自适应感知核调制
5. 实证研究
5.1 实验/结果
5.2 分析
6. 讨论
附录
A. 重要性探测:详细信息
A.1 计算开销
A.2 使用秩受限操作的内核调制 (KML)
A.3 使用代理向量的 Fisher 信息近似
E. 讨论:什么形式的视觉信息被高 FI 内核编码?
G 讨论:源和目标之间的接近度可以放宽多少?
参考
S. 总结
S.1 主要思想
S.2 方法
0. 摘要
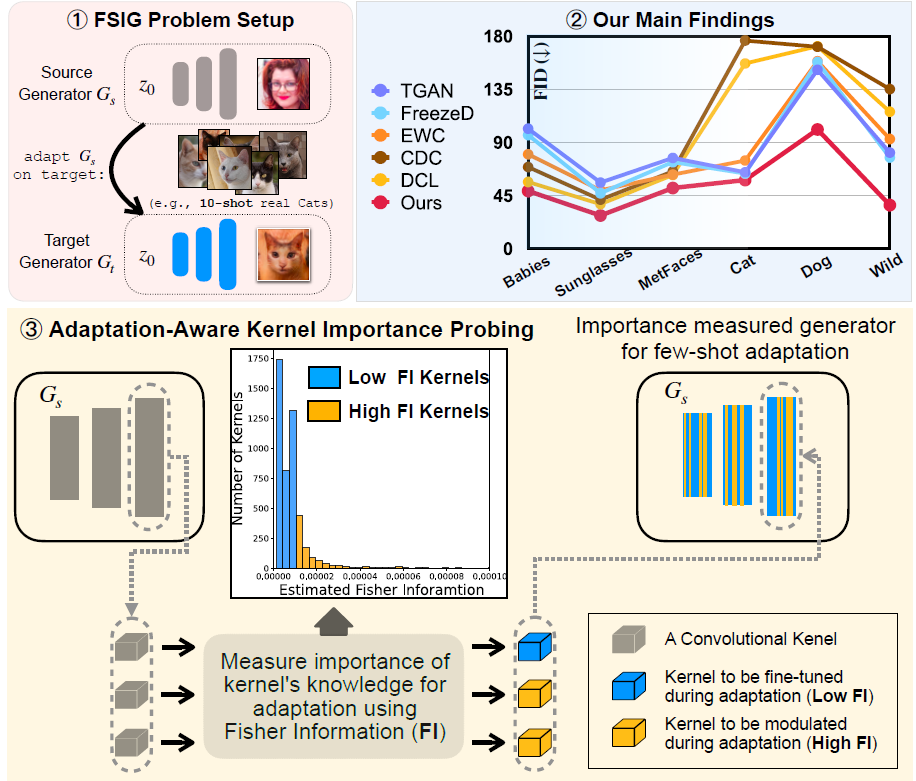
Few-shot image generation (FSIG) 旨在学习,在给定域的极其有限数量的样本(例如 10 个训练样本)的情况下,生成新的和多样化的样本。 最近的工作已经使用迁移学习方法解决了这个问题,利用在大规模源域数据集上预训练的 GAN,并根据非常有限的目标域样本使该模型适应目标域。 最近的 FSIG 方法的核心是知识保存标准,其目的是选择源模型知识的一个子集以保存到适应模型中。 然而,现有方法的一个主要局限是它们的知识保留标准仅考虑源域/源任务,而在选择源模型的知识时没有考虑目标域/自适应任务,这让人怀疑它们对源域和目标域不同接近度设置的适用性。 我们的工作有两个贡献。 作为我们的第一个贡献,我们回顾了最近的 FSIG 作品和他们的实验。 我们的重要发现是,在放宽源域和目标域之间接近假设的设置下,现有的最先进 (SOTA) 方法在知识保存中仅考虑源域的性能并不比基线微调好。 为了解决现有方法的局限性,作为我们的第二个贡献,我们提出了自适应感知核调制 (Adaptation-Aware kernel Modulation,AdAM) 来解决不同源-目标域接近度的一般 FSIG。 广泛的实验结果表明,所提出的方法在不同距离的源/目标域中始终如一地实现 SOTA 性能,包括当源域和目标域相距较远时具有挑战性的设置。
1. 简介
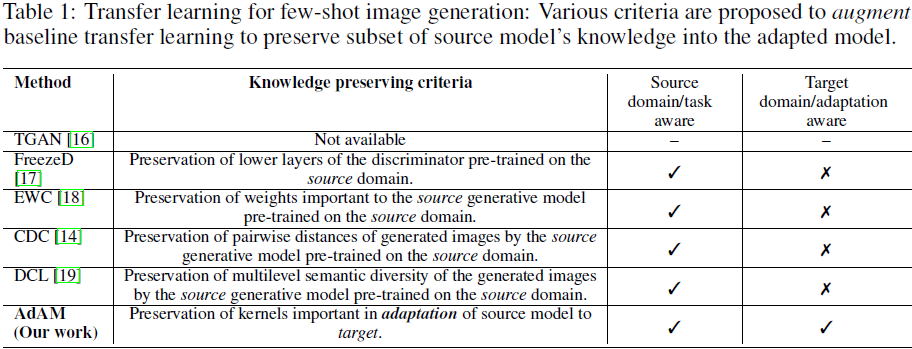
使用迁移学习的 FSIG。 由于只提供了非常有限的样本来定义底层分布,因此预训练 GAN 的标准 fine-tune 会遇到模式崩溃问题:自适应模型只能生成与给定的 few-shot 目标样本非常相似的样本。 因此,最近的工作提出用不同的标准来增强标准微调,以小心地将源模型知识的子集保留到适应的模型中。 已经提出了各种标准(表 1),这些知识保存标准已成为最近 FSIG 研究的核心。 一般来说,这些标准旨在保留源模型知识的子集,这些知识被认为对目标域样本生成有用,例如,提高目标样本生成的多样性。
研究差距。现有方法的一个主要限制是它们在将源模型的知识子集保留到自适应模型中时仅考虑源域。 特别是,这些方法在选择源模型的知识时没有考虑目标域/适应任务(表 1)。 例如,EWC 应用 Fisher Information 完全基于预训练的源模型来选择重要的权重,并且它旨在保留这些选定的权重,而不管自适应中的目标域。 与 EWC 类似,CDC 提出了一个额外的约束来保留源模型生成图像的成对距离,并且没有考虑目标域/自适应。 最近作品中的这些目标/自适应-无关 的知识保存标准提出了关于它们在不同源/目标域设置中的适用性的问题。 应该注意的是,现有的 FSIG 作品(在非常有限的目标样本下)主要集中在源域和目标域非常接近(语义上)的设置,例如人脸(FFHQ)-婴儿脸或 Cars-Abandoned Cars。当源域/目标域相距较远时(例如,人脸 (FFHQ) →动物面孔),它们的性能尚不清楚。
贡献。 在本文中,我们采取了重要的一步来解决 FSIG 的这些研究空白。 具体来说,我们的工作有两个贡献。
作为我们的第一个贡献,我们重新审视了现有的最先进 (SOTA) 算法及其实验。 重要的是,我们观察到,当在实验设置中放宽近距离假设并且源/目标域更加分离时,现有 SOTA 方法的性能并不比基线微调方法好。 我们的观察表明,当源域和目标域相距较远时,最近在知识保存中仅考虑源域/源任务的方法可能不适合一般 FSIG。 为了验证我们的主张,我们引入了不同源/目标域的额外实验,定性和定量地分析它们的接近度,并在统一框架下检查现有方法。
根据我们的分析,作为我们的第二个贡献,我们提出了一种自适应感知核调制方法来解决不同源/目标域接近度的一般 FSIG。 与保留对源任务重要的知识的现有作品形成鲜明对比的是,我们的方法旨在保留对目标域和适应任务重要的源模型知识的子集。 更具体地说,我们提出了一种重要性探测算法来识别编码重要知识以适应目标域的内核。 然后,我们使用参数有效的秩受限核调制来保留这些核的知识。
2. 相关工作
Few-shot 图像生成。 传统的 few-shot 学习旨在学习用于分类、分割或检测任务的判别分类器。 不同的是,few-shot 图像生成 (FSIG) 旨在为给定极其有限的样本(例如,10 张照片)学习新的和多样化的样本生成器。
迁移学习已应用于 FSIG。
- Transferring GAN (TGAN) 应用简单的 GAN 损失来微调生成器和鉴别器的所有参数。
- FreezeD 在微调期间修复了一些高分辨率鉴别器层。
为了增强和改进简单的微调,最近的工作侧重于保留源模型中的特定知识。
- 弹性权重整合 (Elastic weight consolidation,EWC) 识别源模型的重要权重并尝试保留这些权重。
- 跨域对应 (Cross-domain Correspondence,CDC) 保留生成图像与源模型的成对距离,以减轻模式崩溃。
- 对偶对比学习 (Dual Contrastive Learning,DCL) 应用互信息最大化来保留源模型生成的图像的多层次多样性。
我们观察到当源域和目标域相距较远时,这些 SOTA 方法表现不佳。 因此,他们提出的源知识保存标准可能无法推广。 根据我们的分析,我们提出了一种自适应感知知识选择,它对于具有不同接近度的源/目标域更具普遍性。
3. 通过源-目标域接近度的视角重新审视 FSIG
我们仔细检查了现有 FSIG 方法的实验设置,并观察到 SOTA 方法主要侧重于自适应与源域(语义上)接近的目标域:人脸(FFHQ)→ 小孩脸; 人脸 (FFHQ) → 太阳镜; Cars → 废弃的汽车; 教堂 → 鬼屋。 这就提出了一个问题,即现有的源-目标域设置是否足以代表一般的 FSIG 场景。 特别是,现实世界的 FSIG 应用可能不包含始终接近源域的目标域(例如:人脸(FFHQ)→ 动物面孔)。 受此启发,我们对源-目标域接近度进行了深入的定性和定量分析,其中我们引入了远离源域的目标域。
3.1 源-目标域邻近度分析
为了放宽近距离假设并研究一般 FSIG 问题,我们引入了更远的目标域,即 Cat、Dog 和 Wild(来自 AFHQ,由 15,000 张分辨率为 512 × 512 的高质量动物面部图像组成)用于我们的分析。
表征源域目标域接近度。 鉴于深度神经网络特征在表示有意义的语义概念方面取得的广泛成功,我们将源域和目标域的 Inception-v3 和 LPIPS 特征可视化以定性表征域接近度。 此外,我们使用 FID 和 LPIPS 距离来定量表征源-目标域的接近度。 我们注意到 FID 涉及分布估计(一阶、二阶矩),而 LPIPS 计算源/目标域之间的成对距离(学习嵌入)。

分析。 特征可视化和 FID/LPIPS 测量结果如上图所示。我们的结果定性(第 1、2 列)和定量(第 3 列)表明现有作品中使用的目标域(婴儿 [3]、太阳镜 [3]、MetFaces [36])特别靠近源域(FFHQ),我们另外引入的目标域(Dog、Cat 和 Wild [5])远离源域,从而放宽了现有 FSIG 作品中的近距离假设。
3.2 临近假设松弛下的 FSIG 方法
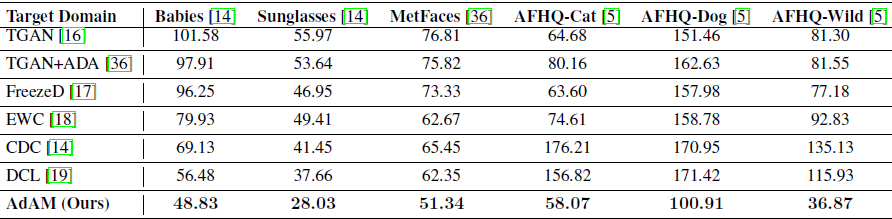
受我们在第 3.1 节中的分析的启发,我们通过放宽源域和目标域之间的接近假设来研究现有 FSIG 方法的性能。 我们研究了这些 FSIG 方法在与源域不同距离的目标域中的性能,其中包括我们另外引入的目标域:Dog、Cat 和 Wild。完整的结果可以在上表中找到。

我们进一步分析了 SOTA FSIG 方法生成的图像,并观察到这些方法由于在知识保存中仅考虑源域/任务而无法很好地适应距离远的目标域。 这可以从图 3 中清楚地观察到。我们注意到 TGAN(简单基线)也遭受严重的模式崩溃。 鉴于我们的调查发现了 SOTA FSIG 方法中的一个重要问题,我们在第 4 节中解决了这个问题。图 3(最后一行)显示了我们提出的方法的一部分结果。
4. 自适应感知核调制
与 SOTA FSIG 方法相比,我们提出了一种自适应感知 FSIG,它在决定要保留源模型知识的哪一部分时也考虑了目标域/自适应任务。 在 CNN 中,每个核负责知识的特定部分(例如,图样或纹理)。 GAN 中的生成器和鉴别器也观察到类似的行为。 因此,在这项工作中,我们在核级别做出这种知识保存决策,即将知识保存转化为从 Ds 自适应 Dt 时核是否重要的决策问题。
我们的 FSIG 算法有两个主要步骤:
- 第一步,重要性探测,我们使用参数有效设计使模型适应目标域进行有限次数的迭代,在此适应过程中,我们测量每个单独核对目标域的重要性。重要性检测的输出是单个核的重要/不重要的决定。
- 第二步,自适应,我们保留重要内核的知识并更新不重要核的知识。

用于 FSIG 的提议的重要性探测。有两个重要的设计考虑因素:在 (i) 极其有限的目标数据和 (ii) 低计算开销下进行探测。
在重要性探测阶段,我们将源模型调整到目标域,进行有限次数的迭代并使用一些可用的目标样本。 在这个简短的适应步骤中,我们测量了核对适应任务的重要性。 为了衡量重要性,我们使用 Fisher information (FI),它在处理自适应任务时提供了该核的信息知识。 然后,基于 FI 测量,我们将核分为重要/不重要。 然后在第二步的自适应中使用这些核的重要性决策。
在自适应阶段,我们建议应用核调制来实现对重要核的约束更新,以及对不重要核的简单微调。 正如将要讨论的那样,调制是秩受限(rank-constrained)的并且具有受限的自由度; 因此,它能够保留重要核的知识。 另一方面,简单的微调对于更新不重要核的知识具有很大的自由度。 此外,秩受限核调制是参数有效的。 因此,我们还在探测步骤中应用这种秩受限核调制来确定核的重要性。
核调制(Kernel ModuLation,KML)。 核调制用于自适应步骤,以将重要核的知识保存到自适应模型中。 此外,它还在探测步骤中用作参数有效技术来确定核的重要性。KML 被提出用于多模态 few-shot 分类(FSC)。 特别是,在 few-shot 约束下,KML 对于不同模式的不同分类任务之间的知识迁移是有效的。 因此,在我们的工作中,我们将 KML 应用于有限目标域样本下不同域的不同生成任务之间的知识迁移。
具体来说,在 CNN 的每个卷积层中,该层的第 i 个核 W_i 与该层的输入特征 X 卷积以产生第 i 个输出通道(特征图)Y_i,即:
![]()
![]()
![]()
![]()
其中 b_i ∈ R 表示偏置项。然后,KML 通过将调制矩阵 Mi 加上一个全 1 矩阵 J 来调制 W_i:
![]()
![]()
![]()
其中 ⊙ 表示 Hadamard 乘法。 在等式 1 中,使用 J 允许学习残差形式(residual format)的调制矩阵。 因此,调制权重被学习为围绕预训练核的扰动,这有助于保存源知识。 如果是最优的,精确的预训练内核也可以迁移到目标模型。 [29] 中的 KML 判别版本与我们的版本之间存在一些重要差异,详情请参阅补充。
此基线 KML 为核的每个系数学习一个单独的调制参数。 因此,在最近的 GAN 架构中使用时可能会出现参数爆炸(例如,StyleGAN-V2 中超过 58M 的参数)。 为了解决这个问题,我们不是学习调制矩阵,而是学习它的低秩版本。 更具体地说,对于 CNN 中的一个 Conv 层,总计有 d_out 个核需要被调制,我们学习两个代理向量
![]()
而不是学习
![]()
并使用这些向量的外积构建调制矩阵,即
![]()
此外,由于我们使用 KML 进行自适应知识保存,因此我们在自适应过程中冻结了基础核 W_i。 因此,可训练参数为 m1,m2。 这显着减少了可训练参数的数量,并且在抑制重要内核的更新方面具有更好的性能(见补充)。 正如稍后将讨论的那样,d_out 的值等于探测阶段一层中的内核总数 (c_out),对于自适应阶段,它由我们的探测方法的输出 (d_out + c_out) 决定。
重要性探测。对于探测,我们建议将 KML 应用于所有内核(在生成器和鉴别器中)以识别哪些调制内核对自适应任务很重要。 为了衡量调制内核的重要性,我们将 Fisher information (FI) 应用于调制参数。 在我们的 FSIG 设置中,对于具有参数 Θ 的调制 GAN,Fisher 信息 F 可以计算为:

其中 L(x|Θ) 是使用判别器的输出计算的二元交叉熵损失,x 包括 few-shot 目标样本和 GAN 生成的假样本。 然后,可以通过对该矩阵内参数的 FI 值进行平均来计算调制矩阵的 FI F(M_i) 。 由于我们使用低秩估计来构建调制矩阵,因此我们可以通过代理向量的 FI 值来估计 F(M_i)。 特别地,考虑低秩近似中的外积,我们有
![]()
然后我们将参数 m1 和 m2 的 FI 的未加权平均值作为 F(M_i) 的估计(补充中的详细信息):
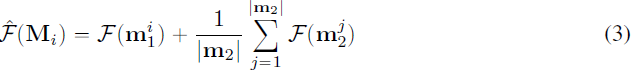
在为生成器和鉴别器中的所有调制矩阵计算 ^F(M_i) 之后,我们使用这些值的 t% 分位数作为阈值(分别用于生成器和鉴别器)来决定内核的调制对于自适应目标域重要或不重要。 如果确定内核的调制很重要(在探测阶段),则在主要自适应阶段使用 KML 对内核进行调制; 否则,内核在自适应阶段使用简单的微调进行更新。 在所有设置中,我们执行 500 次迭代探测。 我们注意到在探测中只有调制参数 m1、m2 是可训练的,并且 FI 仅在它们上计算,因此探测是一个非常轻量级的步骤并且可以以最小的开销执行(补充中的详细信息)。 探测步骤的输出是对单个内核应用内核调制或简单微调的决定。 然后,根据这些决定,执行自适应。
5. 实证研究
5.1 实验/结果

定性结果。 我们使用我们提出的 AdAM 沿基线和 SOTA FSIG 方法在自适应前和后生成的图像,用于两个目标域,婴儿和猫,它们与 FFHQ 的接近程度不同。 结果分别显示在上图的顶部和底部。 通过保留对目标域很重要的源域知识,我们提出的自适应感知 FSIG 方法可以为婴儿和猫域生成具有高度多样性的高质量图像。 我们还包括 FID 和 Intra-LPIPS(用于测量多样性)以定量表明我们提出的方法优于 SOTA FSIG 方法。 我们在补充中展示了更多生成的样本。
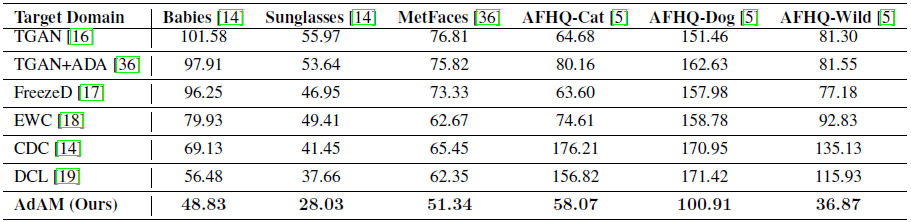 定量结果。 我们在表 2 中显示了完整的 FID 分数。我们为 FSIG 提出的 AdAM 在与源 (FFHQ) 的不同接近度的所有目标域中实现了 SOTA 结果。 我们强调它是通过保留对目标域适应很重要的源域知识来实现的(第 4 节)。 我们还将 Intra-LPIPS 报告为多样性的指标,如图 4 所示。
定量结果。 我们在表 2 中显示了完整的 FID 分数。我们为 FSIG 提出的 AdAM 在与源 (FFHQ) 的不同接近度的所有目标域中实现了 SOTA 结果。 我们强调它是通过保留对目标域适应很重要的源域知识来实现的(第 4 节)。 我们还将 Intra-LPIPS 报告为多样性的指标,如图 4 所示。
5.2 分析
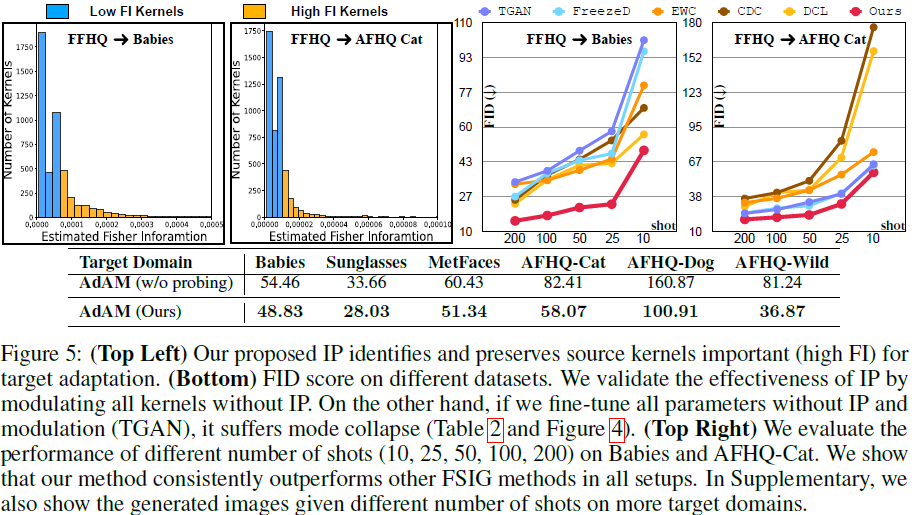
重要性探测的消融研究。 重要性探测(表示为“IP”)的目标是识别对 few-shot 目标自适应很重要的内核,如图 5(上)所示。 为了证明我们设计选择的有效性,我们进行了一项消融研究,该研究丢弃了 IP 阶段,并将所有内核视为对目标自适应同样重要。 因此,我们在没有任何知识选择的情况下简单地调制所有内核。 从图 5(底部)可以看出,知识选择在自适应中起着至关重要的作用。 具体来说,当目标域远离源域时,知识保存的重要性更加明显。
目标样本数(shot)。 目标域训练样本的数量是影响 FSIG 性能的重要因素。 一般来说,更多的目标域样本可以更好地估计目标分布。 我们研究了我们提出的方法在不同数量的目标域样本下的有效性。 结果如图 5 所示,我们表明我们提出的自适应感知 FSIG 方法在所有设置中始终优于现有方法。
6. 讨论
结论。专注于 FSIG,我们做出了两个贡献。
- 首先,我们重新审视当前的 SOTA 方法及其实验。 我们发现,当源域和目标域距离较远时,SOTA 方法在设置中表现不佳,因为现有方法仅考虑源域/任务来保存知识。
- 其次,我们提出了一种新的 FSIG 方法,它是目标/自适应感知 (AdAM)。 我们提出的方法在不同源-目标域接近度的所有设置中优于以前的工作。
更广泛的影响。 我们的工作有助于在样本收集具有挑战性的应用中生成合成数据,例如稀有动物物种的照片。 这是对许多以数据为中心的应用程序的重要贡献。 此外,使用少量数据样本的生成模型的迁移学习可以实现数据和计算高效的模型开发。 我们的工作对环境可持续性和减少温室气体排放产生了积极影响。 虽然我们的工作针对具有有限数据的生成应用程序,但它同时引起了人们对此类方法被用于恶意目的的担忧。 鉴于罪犯检测器最近取得的成功,我们使用 Color-Robust 罪犯检测器对我们的婴儿和猫数据集进行了一项简单的研究。 我们观察到该模型分别达到了 99.8% 和 99.9% 的平均精度 (AP),表明可以成功检测 AdAM 样本。 我们还指出,我们的工作为在更广泛的背景下改进知识迁移方法提供了机会。
限制。 虽然与以前的工作相比,我们的实验范围很广,但在实际应用中,有许多可能的目标域无法包含在我们的实验中。 然而,由于我们的方法是目标/适应感知的,我们相信我们的方法可以比与目标无关的现有 SOTA 更好地适用性。
附录
A. 重要性探测:详细信息
A.1 计算开销
我们提出的重要性探测 (IP) 算法是轻量级的,用于测量源 GAN 中每个内核对目标域的重要性。 即:与需要 ≈ 110 分钟的自适应步骤(FFHQ→Cat 适应实验的 3 次运行的平均值)相比,提议的重要性探测只需要 8 分钟。 这是通过两种设计选择实现的:
- 在 IP 期间,仅更新调制参数。 鉴于我们的调制设计是低秩 KML,与实际源 GAN 相比,可训练参数的数量要少得多。 即:我们提出的 IP 中可训练参数的数量仅为 0.1M,而源 GAN 包含 30.0M 可训练参数。
- 我们提出的 IP 执行有限次数的迭代以衡量目标域的重要性。 即:IP 阶段只需要 500 次迭代即可获得良好的适应性能。
表 S1 中提供了有关我们提出的方法和现有 FSIG 工作的可训练参数数量和计算时间的完整详细信息。 可以观察到,我们提出的方法(IP 和自适应)在可训练参数和计算时间方面优于现有的 FSIG。
A.2 使用秩受限操作的内核调制 (KML)
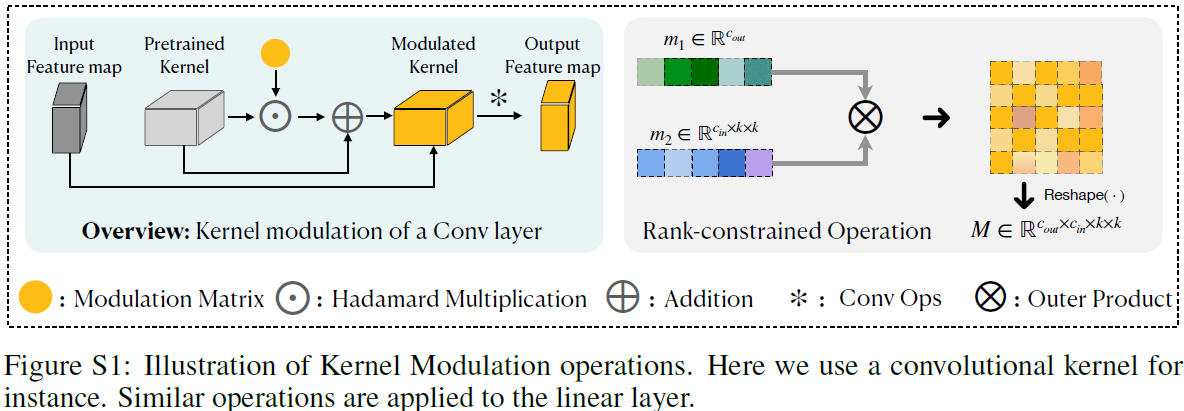
在这里,我们展示了 KML 的更多细节,作为对主要论文的补充,如图 S1。
A.3 使用代理向量的 Fisher 信息近似
回想一下主要论文的第 4 节,我们考虑使用代理向量的外积对调制矩阵进行低秩近似:
![]()
为了计算调制矩阵的 FI,我们从该矩阵中每个元素的 FI 开始。 考虑
![]()
通过简单应用微分链式法则可以推导出以下等式:

我们使用梯度的平方来估计 FI。 因此,使用这些变量的 FI 可以得到以下等式:

那么调制矩阵 M_i = [m_i1, mi_2, . . . ] 的 FI 可计算为:
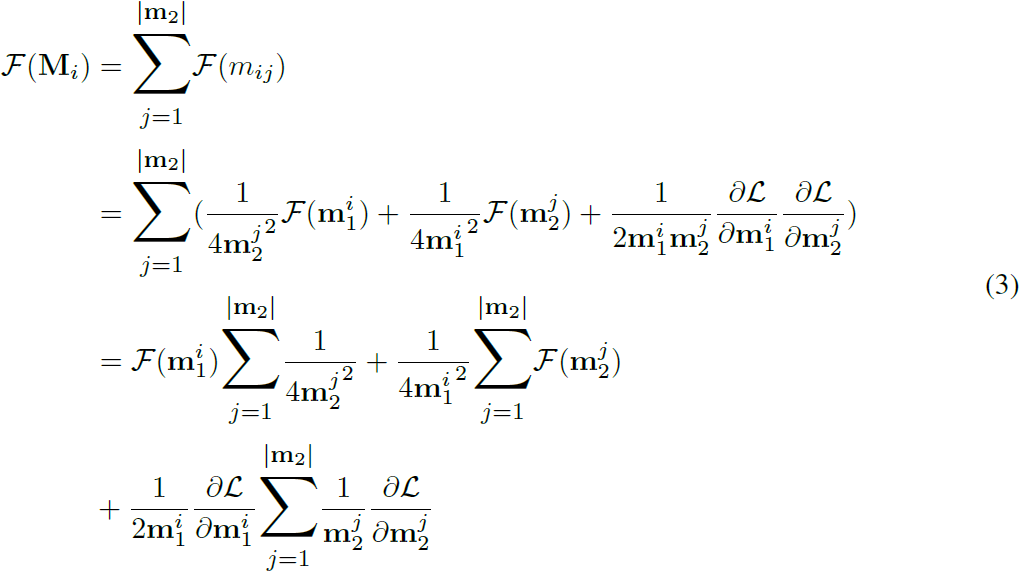
我们凭经验观察到,丢弃(i)交叉项(ii)等式 3 中的系数不影响最终自适应模型的 FID。 因此,估计可以更简单和更轻量级。 特别是,我们的工作中使用了以下(更简单的)F(M_i) 估计版本:
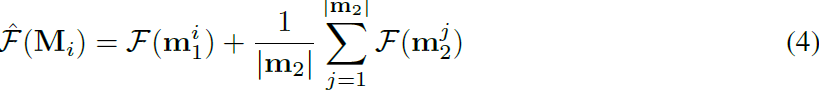
请注意,^F(M_i) 通过其构造参数的加权平均值直观地估计调制矩阵的 FI,这些构造参数对应于它们在计算 Mi 时的出现频率。
E. 讨论:什么形式的视觉信息被高 FI 内核编码?
在本节中,我们试图发现由我们的重要性探测方法识别的特定高 FI 内核编码/生成的视觉信息的形式。 这是一个复杂的问题,据我们所知,可视化生成模型/GAN 的方法在可视化的概念方面仍然相当受限。 然而,我们利用 GAN 解剖 (Dissection) 方法,一种更成熟的可视化方法来可视化高 FI 内部表示。
实验设置:我们使用 Church 作为源域,因为官方 GAN Dissection 方法更适合基于场景的图像生成模型(这是由于 GAN Dissection 中语义分割流程的限制)。 我们使用 2 个目标域:鬼屋(近域)和宫殿(远域)。 跟随官方 GAN 解剖实现,我们使用 ProGAN 模型。
结果。
- 为教堂 → 鬼屋自适应可视化高 FI 内核:内核的 FI 估计结果和高 FI 内核学习的几个不同的语义概念如下第一图。 在如下第一图中,我们可视化了高 FI 内核的四个示例:(a)、(b)、(c)、(d) 分别对应概念 建筑、建筑、树木和木材。 使用 GAN Dissection,我们观察到大量高 FI 内核对应于有用的源域概念,包括建筑物、树木和木材(纹理),这些概念在自适应鬼屋目标域时被保留下来。 我们注意到这些保留的概念对目标域的自适应很有用。
- 可视化用于教堂→宫殿自适应的高 FI 内核:内核的 FI 估计结果和高 FI 内核学习的几个不同的语义概念如下第二图。 在如下第二图中,我们可视化了高 FI 内核的四个示例:(a)、(b)、(c)、(d) 分别对应概念 草、草、建筑物和建筑物。 使用 GAN Dissection,我们观察到大量高 FI 内核对应于有用的源域概念,包括草地和建筑物,这些概念在自适应 Palace 目标域时被保留下来。 我们注意到这些保留的概念对目标域(宫殿)的自适应很有用。

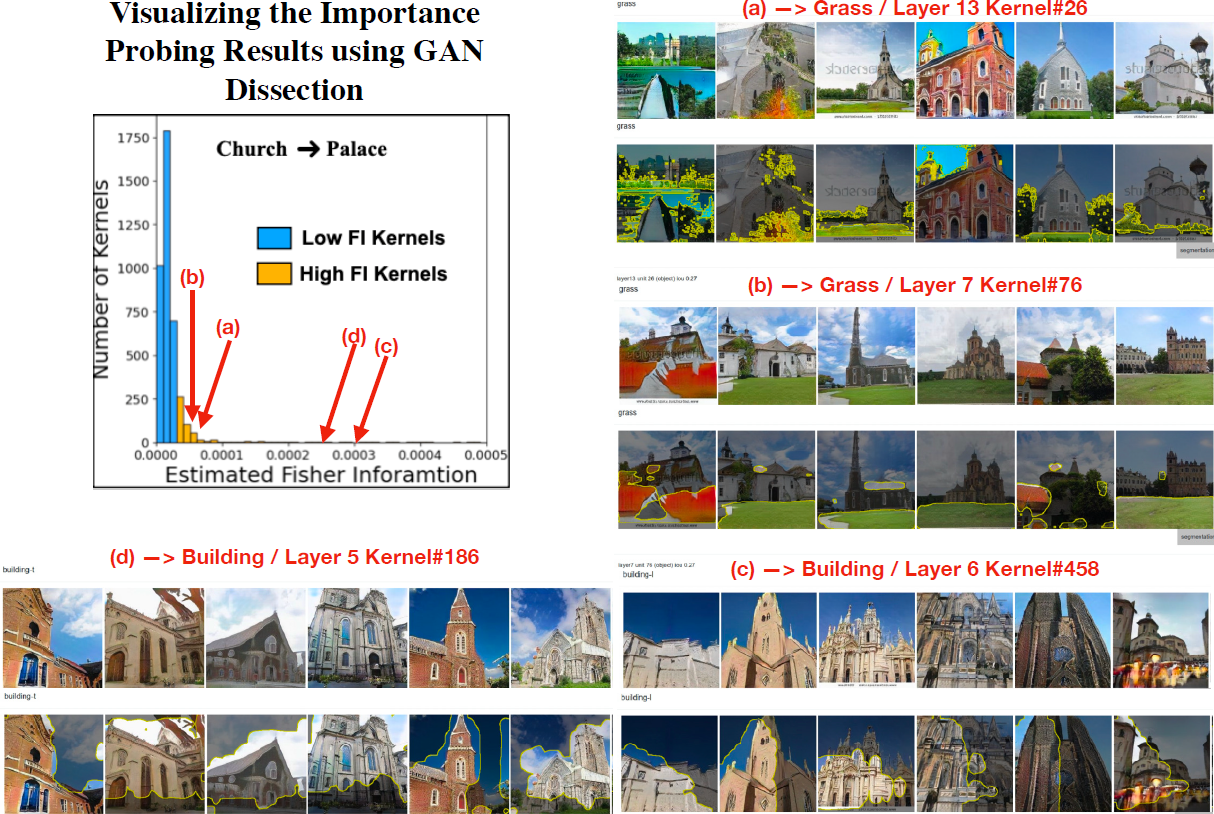
GAN 解剖/未来工作的局限性:尽管 GAN 解剖可以揭示高 FI 内核保留的有用语义概念,但 GAN 解剖方法受到用于语义分割的数据集的限制。 因此,这种方法无法揭示语义分割数据集中不存在的概念(他们使用 Broaden Dataset)。 因此,使用 GAN 解剖,我们目前无法发现和可视化我们的高 FI 内核保留的更细粒度的概念。 我们希望在未来的工作中进一步解决这个问题。
G 讨论:源和目标之间的接近度可以放宽多少?
在本节中,我们将探讨实验设置中源域和目标域之间的接近限制。 首先,我们注意到源域 S 和目标域 T 之间接近度的上限可能取决于 (a) 来自目标域的可用样本(shot)的数量,以及 (b) 用于知识迁移的方法。
(a) 受限于目标域样本数量的接近度界限。 在本文中,我们专注于 few-shot 设置,例如 10 shot。 然而,随着更多的目标域样本可用,S 和 T 之间的接近度可以进一步放松,并且接近度界限会增加,即对于 S 上的给定生成模型,我们可以学习更远的 T 的自适应模型。 直观地,增加目标域样本的数量可以为 T 提供更多不同的知识,因此,对可推广到 T 的 S 知识的依赖性降低(随着 S 和 T 的距离越来越远,这种依赖性会降低)。 在有大量目标域样本可用的极限情况下,S 的知识并不重要,S 和 T 之间的邻近约束可以完全放宽(忽略)。
(b) 受限于知识迁移方法的接近度界限。 给定在 S 上预训练的生成模型和来自 T 的一定数量的可用样本,用于知识迁移的方法起着至关重要的作用。 如果该方法在识别从 S 到 T 的合适的可迁移知识方面表现出色,则可以放宽 S 和 T 之间的接近度,并且接近度界限会增加。 在我们的工作中,我们的第一个贡献是揭示现有的 SOTA 方法(基于与目标域无关的方法)不足以识别从 S 到 T 的可转移知识。因此,当 S 和 T 之间的接近度放松时,性能正如第 3 节、第 5 节中所讨论的那样,自适应后的模型非常糟糕。 因此,我们的第二个贡献是提出一种目标感知方法,该方法可以识别从 S 到 T 的更有意义的可迁移知识,从而放宽接近度界限。
在本节中,我们提供了两个非常远的域之间的自适应实验结果:FFHQ→汽车,仅使用 10 shot,旨在回答两个主要问题:(1)对于 FSIG 任务,是否存在从 FFHQ 到汽车的可迁移知识? (2) 我们提出的方法与此设置中的其他方法相比如何? 为此,除了论文中讨论的迁移学习方法外,我们还添加了仅使用相同的 10 个汽车样本从头开始训练的结果。 定量结果见表 S8。
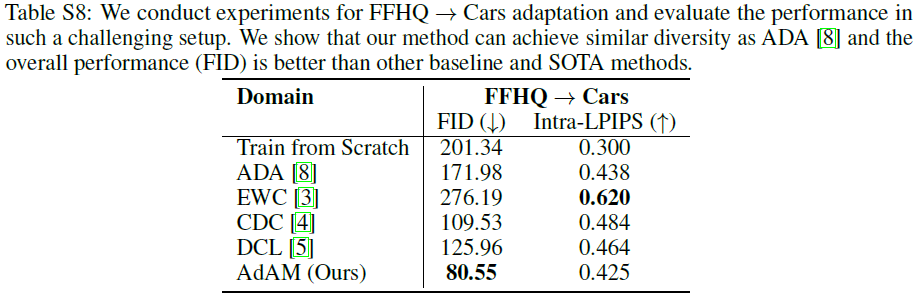
结果表明,即使域 FFHQ 和域 Cars 是分开的,仍然有从 FFHQ 到 Cars 的有用和可迁移的知识(例如低级边缘,形状),因此,与从头开始训练的方法相比,使用建议的方法在自适应的模型中可获得更好的性能(FID,Intra-LPIPS)。 此外,与其他基线和 SOTA 方法相比,我们提出的方法可以识别和迁移更有意义的知识,从而导致生成的图像具有更低的 FID 和更高的多样性。
参考
[29] Milad Abdollahzadeh, Touba Malekzadeh, and Ngai-Man Man Cheung. Revisit multimodal meta-learning through the lens of multi-task learning. Advances in Neural Information Processing Systems, 35, 2021.
Zhao Y, Chandrasegaran K, Abdollahzadeh M, et al. Few-shot image generation via adaptation-aware kernel modulation[J]. Advances in Neural Information Processing Systems, 2022, 35: 19427-19440.
S. 总结
S.1 主要思想
Few-shot 域自适应的核心是知识保存:选择源模型知识的一个子集保存到目标模型。 现有知识保留仅考虑源域,没有考虑目标域,当源域目标域距离较远时,现有方法性能并不好。例如:人物-动物(远)的自适应结果 vs 人物-人物(近)的域自适应结果,已有的一些知识保留方法在前者的性能并不好。
作者提出自适应感知核调制 (Adaptation-Aware kernel Modulation,AdAM) 来解决不同源-目标域接近度的通用 few-shot 域自适应。
S.2 方法
本文使用的方法分为两步:1)基于核调制检测 kernel 对目标域的重要性 2)基于重要性执行如下操作:
- 对于重要的 kernel 使用核调制进行约束更新
- 对不重要的 kernel 进行微调