前言
指针的主题,我们在初级阶段的《指针》章节已经接触过了。我们直到指针的概念。
1、指针就是个变量,用来存放地址,地址唯一标识一块内存空间。
2、指针的大小是固定的4/8个字节(32为平台/64位平台)
3、指针是有类型的,指针的类型决定了指针的+/-整数的步长,指针解引用操作的时候的权限。
4、指针的运算。
下面内容来高级主题。
1、字符指针
在指针的类型中我们知道有一种指针类型位字符指针char*。
字符指针有两种写法:
- 一般使用:
int main()
{
char ch = 'w';
char* pc = &ch;
*pc = 'q';
return 0;
}
- 另一种使用方式:
#include <stdio.h>
int main()
{
char* p = "abcdef"; //把字符串首字符a的地址,赋值给了p。
printf("%s\n", p); //因为是以`%s`打印,所以只需要给个字符串首地址,即可找到整个字符串。
//因为字符串有`\0`,所以也不会额外打印。
return 0;
}
//注意:以上不是把整个字符串"abcdef"放进p里面了,而是把字符串首字符a的地址,赋值给了p。
//需要和数组区分开:char arr[10] = "abcdef"; 这个是把整个字符串放进数组里面了。
输出:

1.1、小试牛刀,来个例题
#include <stdio.h>
int main()
{
char* p1 = "abcdef";
char* p2 = "abcdef";
//const char* p1 = "abcdef"; 这样写和上面的一样
//const char* p2 = "abcdef";
char arr1[] = "abcdef";
char arr2[] = "abcdef";
if (p1 == p2)
printf("p1==p2\n");
else
printf("p1!=p2\n");
if (arr1 == arr2)
printf("arr1==arr2\n");
else
printf("arr1!=arr2\n");
return 0;
}
输出:

结果分析:实际上p1和p2指向同一个字符串,这个字符串叫做常量字符串,放在内存只读数据区里面。既然这个字符串是常量字符串,它不能被修改,所以在内存中就没必要存在多份,存在一份即可,毕竟它只可读。那p1里面就存放了字符a的地址,p2放的也是a的地址。所以p1==p2。
但是到了下面arr1和arr2的情况就不一样了。因为arr1和arr2是两个独立的数组。arr1有属于自己的一个内存空间,这个空间存放了abcdef,然后arr2也有属于自己的一个内存空间,这个空间也存放了abcdef。
arr1和arr2都是数组名,数组名就是首元素地址。所以arr1里面存放的是属于它的a的地址,同样ar2里面存放的是属于它的a的地址。因为两块空间不一样,所以地址也就不一样。所以arr1 != arr2。
2、指针数组
指针数组,中心在数组。指针数组是一个存放指针的数组。
int* arr1[5]; //整型指针的数组
char* arr2[6]; //一级字符指针的数组
char** arr3[5]; //二级字符指针的数组
2.1、用指针数组模拟二维数组
#include <stdio.h>
int main()
{
int arr1[5] = { 1,2,3,4,5 };
int arr2[5] = { 2,3,4,5,6 };
int arr3[5] = { 3,4,5,6,7 };
int* parr[3] = { arr1,arr2,arr3 };
int i = 0;
for (i = 0; i < 3; i++)
{
int j = 0;
for (j = 0; j < 5; j++)
{
printf("%d ", * (parr[i] + j));
//printf("%d ", parr[i][j]); 一样的效果
}
printf("\n");
}
return 0;
}
输出:

2.2、【补充】指针数组。二级指针
int* arr[10];
int** p = arr; //arr是数组名,是数组首元素地址,是int*变量的地址,所以需要二级指针。
3、数组指针
3.1、数组指针的定义
数组指针是数组还是指针?
答案是:指针。
我们已经熟悉:
整型指针就是:int* p;能够指向整型数据的指针。
浮点型指针就是:float* pf;能够指向浮点型数据的指针。
那数组指针应该是:能够指向数组的指针。
【注:】[]的优先级比*的高。
//这个p1先和[10]结合,p1[10]是个数组呀,然后数组的元素是int*类型的,所以这是个指针数组。
int *p1[10]; == int* p1[10]; //指针数组
//这个p2先和*结合,*p2是个指针变量呀,[10]是个数组,那*p2[10]就代表*p2这个指针指向的是数组,数组元素是int类型的。
int (*p2)[10]; //数组指针--->p2可以指向一个数组,该数组有10个元素,每一个元素是int类型的。
//把int (*p2)[10] 想成int* p; 作类比,慢慢分析。
3.2、&数组名VS数组名
对于下面的数组:
int arr[10];
arr和&arr分别是啥?
我们知道arr是数组名,数组名是数组首元素地址。
场景回顾:
所以得出结论:数组名通常情况下表示数组首元素的地址。
但是又两个例外:
- sizeof(数组名),这里的数组名表示整个数组,计算的是整个数组的大小,单位是字节。
- &数组名,这里的数组名表示整个数组,取出的是整个数组的地址。
除此以上两种情况,其它遇到的数组名都是数组首元素地址。
那下面我们来看看到底数组名和&数组名的区别:
#include <stdio.h>
int main()
{
int arr[10] = { 0 };
printf("%p\n", arr);
printf("%p\n", arr+1);
printf("-------------------------------------\n");
printf("%p\n", &arr[0]);
printf("%p\n", &arr[0]+1);
printf("-------------------------------------\n");
printf("%p\n", &arr);
printf("%p\n", &arr+1);
return 0;
}
输出:

所以可以得出结论,&arr,是直接取出的整个数组的地址。
3.3、写出数组指针
我们可以类比,指向整型数据的指针去写数组指针。
int* p = arr;
int (*parr)[10] = &arr;
//首先(*p)是个指针变量,然后一看后面有个[10],那就说明了:这个指针指向的是数组,所以说是数组指针。
//解读:是数组指针,数组有10个元素,且每个元素是int的。
int (*p)[5]
- p的类型是:int(*)[5]
- p是指向一个整型数组的,数组5个元素 int[5]
- p+1是跳过一个5个int元素的数组。
我们在一组数组指针:
char* arr[5] = {0};
char* (*pc)[5] = &arr;
//注意:这里和上面的不一样,因为arr数组里面是指针,是char*类型的,所以在写数组指针的,应该是char*。也就是说arr数组里面存储的是啥,那数组指针卡面就写什么类型的。
3.4、数组指针的常见用法
数字指针常见用法不是针对一维数组的,至少也是使用二维数组或者三维数组的。
下面来通过传参数组指针的方法遍历二维数组。
#include <stdio.h>
void print1(int(*p)[5], int r, int c)
{
int i = 0;
for (i = 0; i < r; i++)
{
int j = 0;
for (j = 0; j < c; j++)
{
//p现在是二维数组中的第一行地址,如果p+i,就代表是二维数组每一行地址。
//*(p+i),是解引用,p+i得到这一行地址,然后*(p+i)解引用找到这一行,那谁能代表这一行呢?数组名能代表,二数组名又是首元素地址,只能是每一行的首元素地址,也就是,每一行第一列元素的地址。
//*(p+i)+j,代表获得一行中,每一列的元素地址。
//*(*(p+i)+j),解引用,就获得一行中,每一列的元素。
printf("%d ", *(*(p + i) + j));
//printf("%d ", p[i][j]);
}
printf("\n");
}
}
int main()
{
int arr[3][5] = { 1,2,3,4,5,2,3,4,5,6,3,4,5,6,7 };
print1(arr, 3, 5);
return 0;
}
在来看个代码:
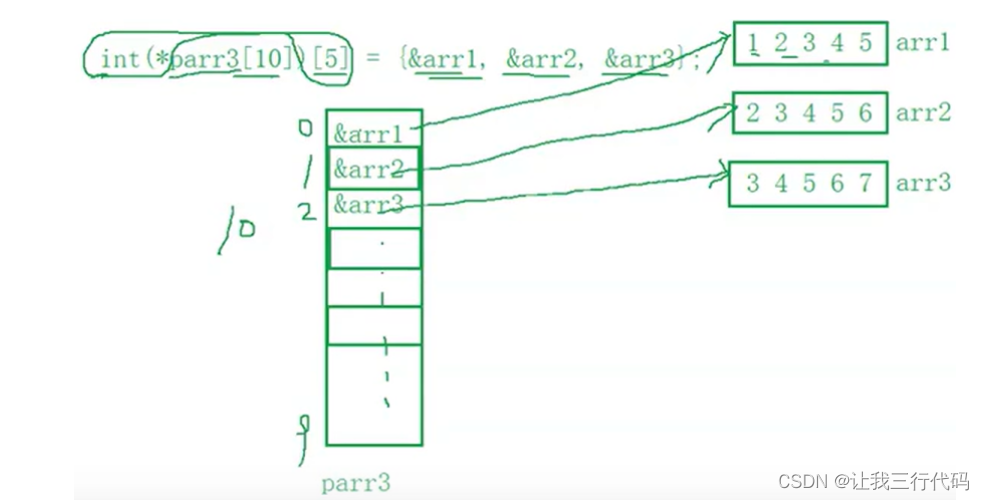
int (*parr3[10])[5]; //parr3是存放数组指针的数组
parr3数组有10个元素,里面存放的是数组指针,并且该数组指针指向的数组有5个int类型的元素。
4、数组传参和指针传参
在写代码时难免要把【数组】或者【指针】传给函数,那函数的参数该如何设计呢?
4.1、一维数组传参
#include <stdio.h>
//ok
void test(int arr[])
{}
//ok
void test(int arr[10])
{}
//ok
void test(int* arr)
{}
//ok
void test2(int* arr2[20])
{}
//ok
void test2(int** arr2)
{}
int main()
{
int arr[10] = { 0 };
int* arr2[20] = { 0 };
test(arr);
test2(arr2);
return 0;
}
4.2、二维数组传参
#include <stdio.h>
//ok
void test(int arr[3][5])
{}
//no
void test(int arr[][])
{}
//ok
void test(int arr[][5])
{}
//no
void test2(int* arr)
{}
//no
void test2(int* arr[5])
{}
//ok
void test2(int (*arr)[5])
{}
//no
void test2(int** arr)
{}
int main()
{
int arr[3][5] = { 0 };
test(arr);
return 0;
}
5、函数指针
学习方法:学习函数指针可以和数组指针进行类比。
数组指针:指向数组的指针就是数组指针。
函数指针:指向函数的指针就是函数指针。
5.1、获取函数地址
有两种方法:Add时函数名
- &Add
- Add
#include <stdio.h>
int Add(int x, int y)
{
return x + y;
}
int main()
{
printf("%p\n", &Add);
printf("%p\n", Add);
return 0;
}
输出:如下就是函数的地址。

5.2、存储函数指针
#include <stdio.h>
int Add(int x, int y)
{
return x + y;
}
int main()
{
//int (*pf)(int, int)中指针是pf,pf的函数指针类型是int (*)(int, int)。
int (*pf)(int, int) = &Add;
return 0;
}
解析:
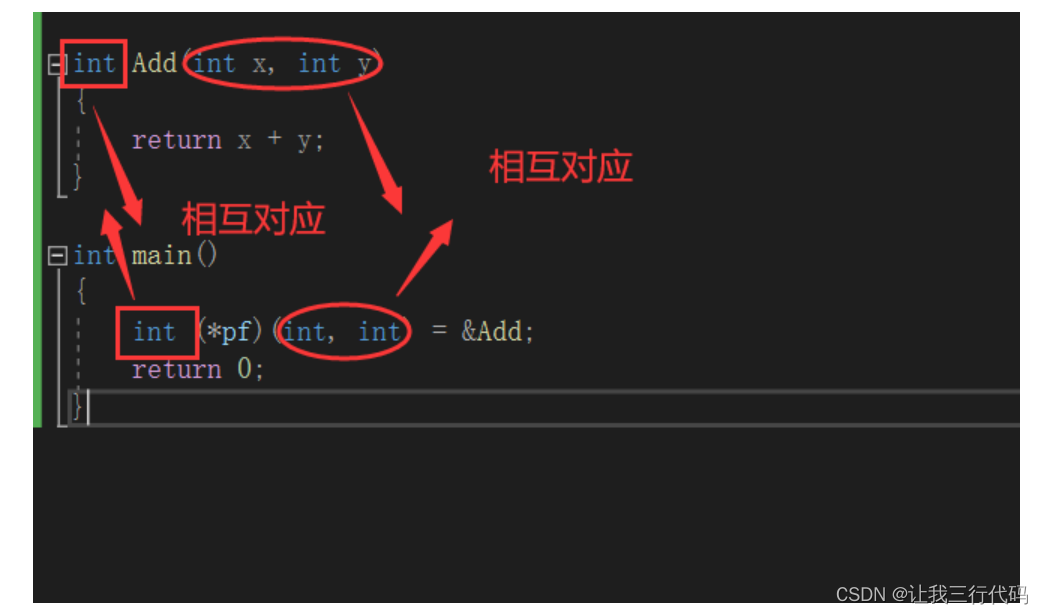
5.3、如何使用函数地址?
知道了如果获取函数地址。那如何使用函数地址呢?
我们先来看一下最基本的指针使用:
int a = 10;
int* pa = &a;
*pa = 20;
printf("%d\n",*pa);
我们得到一个指针,我们对这个指针解引用,就可以访问这个指针所指向的变量,或者打印此变量。
那在看向函数指针,其实也是一样的道理,我们获取到函数指针,无非就是使用此函数指针来调用此函数:
#include <stdio.h>
int Add(int x, int y)
{
return x + y;
}
int main()
{
//获取函数指针。指针pf的函数指针类型是int (*)(int, int)
int (*pf)(int, int) = &Add; //这里的传参写参数类型就可以了,当然也可以写参数:(int x,int y)
//使用函数指针,来调用函数。
int ret = (*pf)(2, 3);
//int ret = pf(2, 3); 这样写也行,其实这里的*就是个摆设,只不过是让初学者看着跟合理而已。让初学者认为这里需要*来解引用而已。
printf("%d\n", ret);
return 0;
}
输出:

那下面再来看一下函数指针的具体用处:
#include <stdio.h>
int Add(int x, int y)
{
return x + y;
}
//下面传的是Add函数名,所以这里用函数指针来接受。
void calc(int (*pf)(int, int))
{
int a = 3;
int b = 2;
int ret = pf(a, b);
printf("%d\n", ret);
}
int main()
{
calc(Add); //将Add函数名传递给calc()函数。
return 0;
}
输出:

5.4、看两个有趣的代码
出自书籍《C陷阱和缺陷》
5.4.1、第一个代码
int main
{
(*(void(*)())0) ();
return 0;
}
分析:(关键突破点是0)
- void(*)() 表示没有参数并且返回值是void的函数的地址
- (void(*)())0 ()0其实是个强制类型转换,是把0强制类型转换为()里面的值。而()里面的值就是上面所说的函数地址,所以这一部分代码意思就是,把0请值类型转换为一个没有参数且返回值是coid的函数的地址。
- *(void(*)())0 *()表示解引用,是对0地址处的函数进行接应用,就相当于是:(*pf)这个效果
- (*(void(*)())0) () 调用函数,并且不需要传参调用。
__总结:__以上代码是一次函数调用,调用的是0作为地址处的函数。
1、把0强制类型转换为:无参、返回类型是void的函数的地址。
2、调用0地址处的这个函数。
5.4.2、第二个代码
int main()
{
void (* signal(int,void(*)(int)))(int);
return 0;
}
分析:
signal(int,void(*)(int)) 是一个函数声明,signal()是个函数,第一个参数是int类型的,第二个参数void(*)(int)返回值函数指针类型,所以signal()第二个参数是函数指针类型的,该函数指针指向的函数参数是int类型的,并且返回值为void。然后signal()函数的返回值也是个函数指针,且该函数指针指向的函数参数是int类型的,并且返回值为void。
代码简化:这样写太复杂了,我们可以进行代码简化。
我们写来知道个关键字:typedef,类型重命名关键字
typedef unsigned int uint
其实我们可以把void(*)(int)给重命名以下,要不然嵌套这个看着太复杂了
//错误示范
typedef void(*)(int) pf_t; 这样的类型重命名是错误的,它和上面的不一样,只能这样下,如下:
typedef void(* pf_t)(int); 可以这样写
//如下简化:
#include <stdio.h>
int main()
{
typedef void(* pf_t)(int);
//void (*signal(int, void(*)(int)))(int); 替换为如下写法:
pf_t signal(int, pf_t);
return 0;
}
5.5、函数指针的用途
或许我们有疑问?在使用函数指针的时候我们直接函数名调用不就行了吗?为什么需要费那么大功夫,使用函数指针呢?其实每一个东西出现都有它的用处。
那下面通过写一个简易计算器来体会一下函数指针。
说明:计算器有加法、减法、乘法、除法。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
void menu()
{
printf("***********************************\n");
printf("*********1.Add 2.Sub********\n");
printf("*********3.Mul 4.Div********\n");
printf("**************0.exit**************\n");
printf("***********************************\n");
}
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
void calc(int(*pf)(int, int))
{
int x = 0;
int y = 0;
printf("请输入2个操作符:>");
scanf("%d %d", &x, &y);
int ret = (*pf)(x, y);
printf("%d\n", ret);
}
int main()
{
int input = 0;
do
{
menu();
printf("请选择:>");
scanf("%d", &input);
switch (input)
{
case 1:
calc(Add);
break;
case 2:
calc(Sub);
break;
case 3:
calc(Mul);
break;
case 4:
calc(Div);
break;
case 0:
printf("退出\n");
break;
default:
printf("请重新选择\n");
break;
}
} while (input);
return 0;
}
6、函数指针数组
数组是一个存放相同类型数据的存储空间,那我们已经学习了指针数组。
比如:
int* arr[10] = {0};
//数组的每一个元素都是int*类型的。
同指针数组一样,函数指针数组,是有一个数组,里面专门用来存放函数指针的。
6.1、写处函数指针数组
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
int main()
{
int (*pf)(int, int) = Add; //pf是函数指针
//同样的arr数组中的每个元素的类型是:int(*)(int,int)。
int (*arr[4])(int, int) = { Add,Sub,Mul,Div }; //函数指针数组
return 0;
}
6.2、使用函数指针数组
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
int main()
{
int (*pf)(int, int) = Add; //pf是函数指针
int (*arr[4])(int, int) = { Add,Sub,Mul,Div }; //函数指针数组
int i = 0;
for (i = 0; i < 4; i++)
{
int ret = arr[i](8, 4); //就直接遍历每一个元素,对应的就是每一个函数
printf("%d\n", ret);
}
return 0;
}
输出:

6.3、函数指针数组的用途
还那上面计算器的功能进行说明:
如果以后我们想要给计算器添加新功能,只需要把函数指针放在函数指针数组里面就行了。
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
void menu()
{
printf("***********************************\n");
printf("*********1.Add 2.Sub********\n");
printf("*********3.Mul 4.Div********\n");
printf("**************0.exit**************\n");
printf("***********************************\n");
}
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
int main()
{
int input = 0;
int x = 0;
int y = 0;
int ret = 0;
//这种实现叫做:转移表
int (*arr[5])(int, int) = { 0,Add, Sub, Mul, Div };
do
{
menu();
printf("请选择:>");
scanf("%d", &input);
if (input == 0)
{
printf("推出计算器\n");
}
else if (input >= 1 && input <= 4)
{
printf("请输入2个操作符:>");
scanf("%d %d", &x, &y);
ret = arr[input](x, y);
printf("%d\n", ret);
}
else
{
printf("输入错误\n");
}
} while (input);
return 0;
}
7、指向函数指针数组的指针
指向函数指针数组的指针是一个指针。
指针指向一个数组,数组的元素都是函数指针。
如何定义?
#include <stdio.h>
int main()
{
//函数指针数组
int (*pfarr[])(int, int) = { 0,Add,Sub,Mul,Div };
//指向函数指针数组的指针
int (*(*ppfarr)[5])(int, int) = &pfarr;
return 0;
}
8、void*类型的指针
int main()
{
int a = 10;
char* pa = &a; //这个就不对,因为&a是int*类型的不能用char*类型的指针去接受
void* pv = &a; //这个可以,因为void*是无具体类型的指针,可以接受任意类型的地址。
//void*是无具体类型的指针,所以不能解引用操作,也不能+-整数。
return 0;
}
9、回调函数+冒泡排序
回调函数就是一个通过函数指针调用的函数。如果你把函数的指针(地址)作为一个参数传递给另一个函数,当这个指针被用来调用其所指向的函数时,我们就说这是回调函数。回调函数不是由该函数的实现方法直接调用,而是在特定的事件或条件发生时由另外的一方调用,用于对该事件或条件进行相应。
回调函数机制:
1、定义一个函数(普通函数即可);
2、将此函数的地址注册给调用者;
3、特定的事件或条件发生时,调用者使用函数指针调用回调函数。
冒泡排序上面我们写过,如下代码:
#include <stdio.h>
void bubble_sort(int arr[],int sz)
{
int i = 0;
int j = 0;
int z = 0;
for (i = 1; i <= sz-1; i++)
{
for (j = 0; j <= sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
z = arr[j];
arr[j] = arr[j+1];
arr[j + 1] = z;
}
}
}
}
int main()
{
int arr[] = { 9,8,7,6,5,4,3,2,1,0 };
int i = 0;
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr,sz);
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
10、重点:回调函数经典使用—qsort库函数介绍及使用
qsort()函数是C语言库函数中的一种排序算法,其用到的排序思想是快速排序(quicksort)。它的独特之处在于可以排序任意类型的数组元素(整形、浮点型、字符串和结构体类型)。
qsort()—>这个函数可以排序任意类型的数据
先来解释以下这个库函数:
void qsort (void* base, //待排序的数据的起始位置
size_t num, //待排序的数据元素个数
size_t size, //待排序的数据元素的大小(单位是字节)
int (*compar)(const void* e1,const void* e2)); //函数指针--->比较函数
//e1和e2是我们要比较的两个元素地址。
在使用qsort()库函数时,最关键的是compar,需要传这个函数指针,那也就意味着我们需要自己写一个比较函数,程序员A想要排序字符,那它就需要自己写一个比较字符的函数,然后把函数传qsort()里面。如果程序员B想要排序整型,那它就需要自己写一个比较整型的函数,然后把函数传qsort()里面等等。
所以说这个比较函数,我们需要自己写。
下面我们使用qsort()来实现排序:
#include <stdio.h>
#include <stdlib.h>
//程序员自己创建的比较函数,比较两个整型元素
int cmp_int(const void* e1, const void* e2)
{
return (*(int*)e1 - *(int*)e2);
}
int main()
{
int arr[10] = { 9,8,7,6,5,4,3,2,1,0 };
int sz = sizeof(arr) / sizeof(arr[0]);
qsort(arr, sz, sizeof(arr[0]), cmp_int);
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
这里说一下,比较函数的返回值:
函数的返回值类型为 int 类型,总共有三种情况:< 0:elem1小于elem2;0:elem1等于elem2;> 0:elem1大于elem2。
那如果数组为:int arr[10] = { 0,1,2,3,4,5,6,7,8,9 };
然后想见降序排序呢?
只需要修改一行代码即可:让e2-e1即可。
return (*(int*)e2 - *(int*)e1);
那我们来看一下我们自己写的cmp_int()函数,我们只需要写出这个函数,并且我们也不调用它,我们只需要把这个cmp_int()函数传递给qsort()即可,qsort()在合适的时机下,自己内部就会调用cmp_int()函数,这就是回调函数。
10.1、使用qsort()进行其它的排序
使用qsort()对结构体中的字符串进行排序。
//对姓名进行排序
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
struct Stu
{
char name[20];
int age;
};
//比较函数
int cmp_stu_by_name(const void* e1, const void* e2)
{
return strcmp(((struct Stu*)e1)->name, ((struct Stu*)e2)->name);
}
void test2()
{
struct Stu s[] = { {"zhangsan",19},{"lisi",20}, {"wangwu",21} };
int sz = sizeof(s) / sizeof(s[0]);
qsort(s, sz, sizeof(s[0]), cmp_stu_by_name);
}
int main()
{
test2();
return 0;
}
//对年龄进行排序
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
struct Stu
{
char name[20];
int age;
};
//比较函数
int cmp_stu_by_age(const void* e1, const void* e2)
{
return ((struct Stu*)e1)->age - ((struct Stu*)e2)->age;
}
void test2()
{
struct Stu s[] = { {"zhangsan",19},{"lisi",20}, {"wangwu",21} };
int sz = sizeof(s) / sizeof(s[0]);
qsort(s, sz, sizeof(s[0]), cmp_stu_by_age);
}
int main()
{
test2();
return 0;
}
10.2、分析qsort()并模拟设计qsort()实现整型冒泡排序

1、首先第一个参数(传参要排序的数据的起始位置):为什么要传参void* 的数据呢?我们来想一下这个问题:qsort()在设计的时候,作者能不能知道。程序员在使用qsort()时需要排序什么数据?答案:不能!!!原因很简单,这个因素是不群顶的,比如:A想要整型数据,B想排序结构体数据,C想排序字符串数据等等。那既然不能,所以只能把这个起始位置传递给void*来接收。因为void*型的指针可以接收任意型的地址。
2、第二个参数:既然需要对数据进行排序,那肯定需要提供数据元素的个数。
3、第三个参数(理解这个参数非常重要是核心):为什么需要这个宽度呢?因为由第一个参数只能得到起始位置,由第二个参数只能得到要排序元素个数,那如何改变相比较的两个元素怎么办呢?这个时候就需要知道一个元素到底占用多少个字节,知道一个元素占多少字节后,我们加上这个width就能来回的改变量比较的两个元素了。这个是核心。qsort()完全不知道,所以需要给个一个元素的宽度。
有了以上三个参数,就能依次找到每个元素了。
4、第四个参数:通过上面三个参数找到元素,然后进行比较。
知道了qsort()的设计原理后,下面我们来自己设计qsort()实现冒泡排序。
//原版冒泡排序
#include <stdio.h>
void bubble_sort(int arr[],int sz)
{
int i = 0;
int j = 0;
int z = 0;
for (i = 1; i <= sz-1; i++)
{
for (j = 0; j <= sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1]) //核心改变的地方就在这,如何交换?
{
z = arr[j];
arr[j] = arr[j+1];
arr[j + 1] = z;
}
}
}
}
int main()
{
int arr[] = { 9,8,7,6,5,4,3,2,1,0 };
int i = 0;
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr,sz);
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
//模拟qsort(),实现整型冒泡排序,一定要仔细对比,发现精髓
#include <stdio.h>
void Swap(char* buf1, char* buf2,int width)
{
//这里因为buf1和buf2都是char*类型的,所以+-1,只能访问一个字节的内容
//因为是一个字节一个字节去访问的,那到底需要访问并交换多少次呢?这个时候width就起作用了,
//只需要访问并交换width次即可。
int i = 0;
for (i = 0; i < width; i++)
{
char tmp = *buf1;
*buf1 = *buf2;
*buf2 = tmp;
buf1++;
buf2++;
}
}
int cmp_int(const void* e1, const void* e2)
{
return (*(int*)e1 - *(int*)e2);
}
void test_qsort(void* base, int sz,int width,int (*cmp)(const void* e1,const void* e2))
{
int i = 0;
int j = 0;
for (i = 0; i < sz - 1; i++)
{
for (j = 0; j < sz - 1 - i; j++)
{
//重点来了:因为base是void*类型的指针,不能解引用,不能+-,所以需要强制类型转换
//但是至于转成那个类型呢?比如这个:肯定是转为int*类型的,但是我们总不能直接写:(int*)base吧?
//直接这样写是因为我们知道,ao,原来我们传递的是个整型数组,所以需要int*类型的去接收,但是如果
//传的是float类型的数组呢?那也是四个字节。那还能写int*吗?显然不能,所以直接还是不够灵活
//这里是有一个灵活的逻辑代码,来解决这个问题的。
//可以这样写:
//给e1传参:(char*)base+j*width 第一个待比较元素地址
//给e2传参:(char*)base+(j+1)*width 第二个带比较元素地址
//这里需要好好体会一下,qsort()为什么要传width的精髓就在这里。
if (cmp((char*)base + j * width,(char*)base+(1+j)*width) > 0) //这里调用cmp函数,就不写成(*cmp)的形式了,这个*可有可无。
{
//那下面就是交换的逻辑代码了,这里交换单独用一个函数实现
//这里的交换,交换的是两个元素,所以需要传参以上两个元素的指针,而且还需要传递width,需要知道每个元素有多宽。
Swap((char*)base + j * width, (char*)base + (1 + j) * width,width);
}
}
}
}
test3()
{
int arr[] = { 9,8,7,6,5,4,3,2,1,0 };
int i = 0;
int sz = sizeof(arr) / sizeof(arr[0]);
test_qsort(arr, sz, sizeof(arr[0]), cmp_int);
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
}
int main()
{
test3();
return 0;
}
10.3、模拟实现qsort()实现结构体排序
改动地方并不大,其中交换,比较部分完全不用改动,唯一要做的是需要我们自己写比较函数即可。
//结构体字符串进行排序
#include <stdio.h>
#include <string.h>
struct Stu
{
char name[20];
int age;
};
void Swap(char* buf1, char* buf2,int width)
{
//这里因为buf1和buf2都是char*类型的,所以+-1,只能访问一个字节的内容
//因为是一个字节一个字节去访问的,那到底需要访问并交换多少次呢?这个时候width就起作用了,
//只需要访问并交换width次即可。
int i = 0;
for (i = 0; i < width; i++)
{
char tmp = *buf1;
*buf1 = *buf2;
*buf2 = tmp;
buf1++;
buf2++;
}
}
//其它地方不用改变,只需要自己创建这个比较函数即可
int cmp_struct_name(const void* e1,const void* e2)
{
return strcmp(((struct Stu*)e1)->name, ((struct Stu*)e2)->name);
}
void test_qsort(void* base, int sz,int width,int (*cmp)(const void* e1,const void* e2))
{
int i = 0;
int j = 0;
for (i = 0; i < sz - 1; i++)
{
for (j = 0; j < sz - 1 - i; j++)
{
//重点来了:因为base是void*类型的指针,不能解引用,不能+-,所以需要强制类型转换
//但是至于转成那个类型呢?比如这个:肯定是转为int*类型的,但是我们总不能直接写:(int*)base吧?
//直接这样写是因为我们知道,ao,原来我们传递的是个整型数组,所以需要int*类型的去接收,但是如果
//传的是float类型的数组呢?那也是四个字节。那还能写int*吗?显然不能,所以直接还是不够灵活
//这里是有一个灵活的逻辑代码,来解决这个问题的。
//可以这样写:
//给e1传参:(char*)base+j*width
//给e2传参:(char*)base+(j+1)*width
//这里需要好好体会一下,qsort()为什么要传width的精髓就在这里。
if (cmp((char*)base + j * width,(char*)base+(1+j)*width) > 0) //这里调用cmp函数,就不写成(*cmp)的形式了,这个*可有可无。
{
//那下面就是交换的逻辑代码了,这里交换单独用一个函数实现
//这里的交换,交换的是两个元素,所以需要传参以上两个元素的指针,而且还需要传递width,需要知道每个元素有多宽。
Swap((char*)base + j * width, (char*)base + (1 + j) * width,width);
}
}
}
}
void test4()
{
struct Stu s[3] = {{"aaa",17},{"bbb",12},{"ccc",15}};
int sz = sizeof(s) / sizeof(s[0]);
test_qsort(s, sz, sizeof(s[0]), cmp_struct_name);
}
int main()
{
test4();
return 0;
}
//结构体年龄进行排序
#include <stdio.h>
#include <string.h>
struct Stu
{
char name[20];
int age;
};
void Swap(char* buf1, char* buf2,int width)
{
//这里因为buf1和buf2都是char*类型的,所以+-1,只能访问一个字节的内容
//因为是一个字节一个字节去访问的,那到底需要访问并交换多少次呢?这个时候width就起作用了,
//只需要访问并交换width次即可。
int i = 0;
for (i = 0; i < width; i++)
{
char tmp = *buf1;
*buf1 = *buf2;
*buf2 = tmp;
buf1++;
buf2++;
}
}
//其它地方不用改变,只需要自己创建这个比较函数即可
int cmp_struct_age(const void* e1,const void* e2)
{
return ((struct Stu*)e1)->age - ((struct Stu*)e2)->age;
}
void test_qsort(void* base, int sz,int width,int (*cmp)(const void* e1,const void* e2))
{
int i = 0;
int j = 0;
for (i = 0; i < sz - 1; i++)
{
for (j = 0; j < sz - 1 - i; j++)
{
//重点来了:因为base是void*类型的指针,不能解引用,不能+-,所以需要强制类型转换
//但是至于转成那个类型呢?比如这个:肯定是转为int*类型的,但是我们总不能直接写:(int*)base吧?
//直接这样写是因为我们知道,ao,原来我们传递的是个整型数组,所以需要int*类型的去接收,但是如果
//传的是float类型的数组呢?那也是四个字节。那还能写int*吗?显然不能,所以直接还是不够灵活
//这里是有一个灵活的逻辑代码,来解决这个问题的。
//可以这样写:
//给e1传参:(char*)base+j*width
//给e2传参:(char*)base+(j+1)*width
//这里需要好好体会一下,qsort()为什么要传width的精髓就在这里。
if (cmp((char*)base + j * width,(char*)base+(1+j)*width) > 0) //这里调用cmp函数,就不写成(*cmp)的形式了,这个*可有可无。
{
//那下面就是交换的逻辑代码了,这里交换单独用一个函数实现
//这里的交换,交换的是两个元素,所以需要传参以上两个元素的指针,而且还需要传递width,需要知道每个元素有多宽。
Swap((char*)base + j * width, (char*)base + (1 + j) * width,width);
}
}
}
}
void test4()
{
struct Stu s[] = {{"bbb",17},{"aaa",12},{"ccc",15}};
int sz = sizeof(s) / sizeof(s[0]);
test_qsort(s, sz, sizeof(s[0]), cmp_struct_age);
}
int main()
{
test4();
return 0;
}
【补充:】我们模拟实现的qsort()和库函数qsort(),还是有差别的。差别在算法思想上。
我们模拟实现的qsort()的算法是冒泡排序,而库函数qsort()的算法是快速排序算法。
11、学会一维数组和二维数组之间的代码转换
arr[i]-------->*(arr+i)
*cpp[-2]------------->*(*(cpp+(-2)))------->*(*(cpp-2))
cpp[-1][-1]----------->*(*(cpp-1)-1)
12、指针和数组面试题
12.1、一维数组练习
重点掌握:数组名的理解,指针的运算和指针类型的意义
#include <stdio.h>
int main()
{
int a[] = { 1,2,3,4 };
//答案:16
//分析:a是数组名,sizeof(a)计算的是整个数组的大小。
printf("%d\n", sizeof(a));
//答案:4/8 ,
//分析:这个形式不符合这个两个特殊情况:1、sizeof(数组名),2、&数组名
//既然不符合以上两个特殊情况,那么这里的a就代表数组首元素地址,那a+0=a,a之后还是数组首元素地址
//所以答案为:4/8。
printf("%d\n", sizeof(a+0));
//答案:4
//分析:a没有单独放在sizeof()中,并且没有&a,所以*a不符合两个特殊情况,
//所以a是首元素地址,然后*a是对a进行解引用,就得到了数组首元素
//因为该数组元素是int类型的,所以有4和字节。
printf("%d\n", sizeof(*a));
//答案:4/8
//分析:a没有单独放在sizeof()中,并且没有&a,所以不符合两个特殊情况,
//所以a是首元素地址,a+1就表示数组第二个元素的地址
//既然是地址,答案就为4/8。
printf("%d\n", sizeof(a+1));
//答案:4
//分析:a[1]表示数组第二个元素,是4个字节。
printf("%d\n", sizeof(a[1]));
//答案:4/8
//分析:&a取出整个数组地址,但是归根结底数组地址也是个地址,
//所以在不同的平台上答案是4/8
printf("%d\n", sizeof(&a));
//答案:16
//分析:方法一:&a拿到的是数组地址,类型是int (*)[4],是一种数组指针。
//*&a,对数组指针解引用,得到的是数组,那sizeof(a),就是16
//分析:方法二:*和&是相互抵消的,只剩下了a,所以是16。
printf("%d\n", sizeof(*&a));
//答案:4/8
//分析:&a取出整个数组地址,&a+1,是从数组a的地址向后跳过整个数组的大小,
//从而到达了数组a后面相邻的某个地址
//但是说白了,也是个地址,既然是地址,答案就是4/8。
printf("%d\n", sizeof(&a+1));
//答案:4/8
//分析:&a[0]表示数组第一个元素的地址,计算的是地址的大小,所以答案:4/8。
printf("%d\n", sizeof(&a[0]));
//答案:4/8
//&a[0]表示数组第一个元素的地址,&a[0]+1就是跳过一个整型,到了数组第二个元素的地址
//计算的是地址,所以答案:4/8。
//&a[0]+1 ---> &a[1]
printf("%d\n", sizeof(&a[0]+1));
return 0;
}
12.2、字符数组练习
第一组练习:
#include <stdio.h>
#include <string.h>
int main()
{
char arr[] = { 'a','b','c','d','e','f' };
//答案:6
//分析:arr是数组名,直接放在sizeof()里面,是统计的整个数组大小,因为一个元素是1字节
//所以一共是6个字节,答案是6。
printf("%d\n", sizeof(arr));
//答案:4/8
//分析:arr+0,arr并没有单独放在sizeof()里面,所以arr是数组首元素地址,
//arr+0还是数组首元素地址,计算一个地址的大小,所以答案是4/8
printf("%d\n", sizeof(arr+0));
//答案:1
//分析:arr是数组首元素地址,*arr表示解引用首元素地址,所以最终表示数组中的第一个元素
//一个元素是1个字节,所以答案:1。
//*arr--->*(arr+0)--->arr[0]
printf("%d\n", sizeof(*arr));
//答案:1
//分析:arr[1]表示数组第二个元素,大小为1个字节。
printf("%d\n", sizeof(arr[1]));
//答案:4/8
//分析:&arr,取整个数组的地址,但说白了,归根结底,还是地址,
//那sizeof()计算地址的大小,是4/8。
printf("%d\n", sizeof(&arr));
//答案:4/8
//分析:&arr取整个数组的地址,&arr+1表示跳过整个数组,跳到了和这个数组后面相邻的地址
//归根结底还是地址,那么sizeof()计算地址大小,结果还是4/8。
printf("%d\n", sizeof(&arr+1));
//答案:4/8
//分析:&arr[0]取出数组第一个元素的地址,&arr[0]+1表示跳过一个字符,跳到了数组第二个元素的地址
//归根结底还是地址,那么sizeof()计算地址大小,结果还是4/8。
printf("%d\n", sizeof(&arr[0]+1));
return 0;
}
第二组练习:
#include <stdio.h>
#include <string.h>
int main()
{
//没有'\0'
char arr[] = { 'a','b','c','d','e','f' };
//答案:随机值,因为没有'\0',不知道从哪地方结束。
printf("%d\n", strlen(arr));
//答案:随机值,arr+0还是数组首元素地址,因为不知道'\0',不知道从哪地方结束。
printf("%d\n", strlen(arr+0));
//答案:这个题是错的,有问题。因为传给strlen()的参数需要是地址,而*arr表示数组中第一个元素
//并不是一个地址,所以此题目错误。
printf("%d\n", strlen(*arr));
//答案:题目错误,原因同上。
printf("%d\n", strlen(arr[1]));
//答案:随机值,和上面的第一题、第二题的随机一样。
printf("%d\n", strlen(&arr));
//答案:随机值,是上面一题的随机值-6。
printf("%d\n", strlen(&arr + 1));
//答案:随机值,是上上面一题的随机值-1。
printf("%d\n", strlen(&arr[0] + 1));
return 0;
}
第三组练习:
#include <stdio.h>
#include <string.h>
int main()
{
//有'\0'。
char arr[] = "abcdef";
//答案:7
//分析:数组末尾里面有'\0',因为是用sizeof()计算,需要包含数组末尾的'\0'。
//所以一共是7个元素。
printf("%d\n", sizeof(arr));
//答案:4/8
//分析:arr+0,不属于两种特殊情况,所以这个里的arr是数组首元素地址,
//那使用sizeof()计算地址大小,答案为:4/8。
printf("%d\n", sizeof(arr + 0));
//答案:1
//分析:*arr表示数组第一个元素,用sizeof()计算大小,是1个字节
printf("%d\n", sizeof(*arr));
//答案:1
//分析:arr[1]表示数组第二个元素,用sizeof()计算大小,是1个字节。
printf("%d\n", sizeof(arr[1]));
//答案:4/8
//分析:&arr取出整个数组地址,从一个元素开始,归根结底,还是个地址,
//用sizeof()计算地址大小,结果是4/8。
printf("%d\n", sizeof(&arr));
//答案:4/8
//分析:&arr+1,跳过整个数组,跳到这个数组后面相邻的地址处,但是归根结底还是地址
//用sizeof()计算地址大小,结果为4/8。
printf("%d\n", sizeof(&arr + 1));
//答案:4/8
//分析:&arr[0]表示数组第一个元素的地址,&arr[0]+1是数组第二个元素的地址
//用sizeof()计算地址大小,结果为4/8。
printf("%d\n", sizeof(&arr[0] + 1));
return 0;
}
第四组练习:
#include <stdio.h>
#include <string.h>
int main()
{
//有'\0'。
char arr[] = "abcdef";
//答案:6
//分析:数组末尾里面有'\0',因为是用strlen()计算,只需要计算到'\0之前的元素个数'。
printf("%d\n", strlen(arr));
//答案:6
//分析:同上
printf("%d\n", strlen(arr + 0));
//分析:题目错误,因为传给strlen()的参数需要是地址,而*arr表示数组中第一个元素
//传参并不是一个地址,所以此题目错误。
printf("%d\n", strlen(*arr));
//分析:题目错误,因为传给strlen()的参数需要是地址,而arr[1]表示数组中第一个元素
///传参并不是一个地址,所以此题目错误。
printf("%d\n", strlen(arr[1]));
//答案:6
//分析:
printf("%d\n", strlen(&arr));
//答案:随机值
//分析:跳过整个数组,跳到这个数组后面相邻的地址处,但是到底什么时候遇见'\0',是不知道的
//所以是随机值。
printf("%d\n", strlen(&arr + 1));
//答案:5
//分析:&arr[0]表示数组第一个元素的地址,&arr[0]+1是数组第二个元素的地址
//用sizeof()计算地址大小,结果为4/8。
printf("%d\n", strlen(&arr[0] + 1));
return 0;
}
第五组练习:
#include <stdio.h>
#include <string.h>
int main()
{
//把首字符'a'的地址放在p里面了。
char* p = "abcdef";
//答案:4/8
//分析:p现在是指针变量,用sizeof()计算地址大小,是4/8
printf("%d\n", sizeof(p));
//答案:4/8
//分析:p+1,也是个地址,用sizeof()计算地址大小,是4/8
printf("%d\n", sizeof(p+1));
//答案:1
//分析:p本身是个指针,代表首字符'a'的地址,现在*p,就是解引用,就变为'a'了,字符'a'是一个字节。
printf("%d\n", sizeof(*p));
//答案:1
//分析:p[0]--->*(p+0)--->*p,所以原理同上。
printf("%d\n", sizeof(p[0]));
//答案:4/8
//分析:p本身是指针,&p就是二级指针,二级指针也是指针,所以用sizeof()计算地址大小,就是4/8。
printf("%d\n", sizeof(&p));
//答案:4/8
//分析:&p+1也是二级指针,原理同上。
//【补充:】&p+1是跳过整个字符串了。
printf("%d\n", sizeof(&p+1));
//答案:4/8
//分析:&p[0]+1--->&[p+0]+1--->&p+1,就变成字符串中'b'的地址。所以用sizeof()计算地址大小,就是4/8。
printf("%d\n", sizeof(&p[0]+1));
//---------------------------------------------
//答案:6
//分析:p是个指针,代表首字符'a'的地址,传给strlen(),遇见'\0'之后,一共有6和字符。
printf("%d\n", strlen(p));
//答案:5
//分析:p+1代表从字符串中'b'的位置出发,一直遇见'\0',一共有5个字符。
printf("%d\n", strlen(p + 1));
//分析:题目错误,strlen()需要传的参数是地址
printf("%d\n", strlen(*p));
//分析:p[0]--->*(p+0)--->*p---‘a’,strlen()需要的是指针参数,而p[0]是个字符'a'
//所以题目错误。
printf("%d\n", strlen(p[0]));
//答案:随机值
//分析:&p是个二级指针,不知道什么时候遇见'\0',所以是随机值。
printf("%d\n", strlen(&p));
//答案:随机值
//分析:&p+1是个二级指针,不知道什么时候遇见'\0',所以是随机值。
printf("%d\n", strlen(&p + 1));
//答案:5
//分析:&p[0]+1--->&[p+0]+1--->&p+1,就变成字符串中'b'的地址。然后用strlen()取统计字符串个数,
//遇见'\0'一共有5个字符串,所以答案是5。
printf("%d\n", strlen(&p[0] + 1));
return 0;
}
12.3、二维数组练习
#include <stdio.h>
int main()
{
int a[3][4] = { 0 };
//答案:48
//数组名a单独放在sizeof()里面,所以统计的是整个二维数组的大小,所以是3*4*4=48。
printf("%d\n", sizeof(a));
//答案:4
//分析:a[0][0]是二维数组中第一列第一行的元素,一个元素大小为4字节,所以答案是4。
printf("%d\n", sizeof(a[0][0]));
//答案:16
//分析:a[0]是二维数组第一行数组名,数组名单独放在一起,是计算整个第一行元素的大小的。
//第一行有4个元素,4*4=16。
printf("%d\n", sizeof(a[0]));
//答案:4/8
//分析:a[0]+1这里a[0]并不是单独放在sizeof()里面了,那这里的a[0]就不能代表整个第一行元素了
//这里的a[0]代表的就是第一行第一个元素的地址,然后在+1,就是第一行第二个元素的地址。
//然后sizeof()计算地址大小,答案是:4/8。
printf("%d\n", sizeof(a[0]+1));
//答案:4
//分析:由上面的知:a[0]+1是就是第一行第二个元素的地址,然后*(a[0]+1)),
//相当于是对第一行第二个元素的地址解引用,得到字符'b',大小是4字节。所以答案是:4。
printf("%d\n", sizeof(*(a[0]+1)));
//答案:4/8
//分析:a虽然是二维数组的地址,但是a并没有单独放在sizeof()里面,也没有取地址a。
//那a现在就表示的是二维数组首元素地址,二维数组的首元素是第一行,a表示的就是第一行的地址
//那a+1表示的就是二维数组中第二行的地址。
//既然是地址,那么使用sizeof()计算地址大小,答案就是:4/8。
printf("%d\n", sizeof(a+1));
//答案:16
//分析:由上面知:a+1是二维数组中第二行的地址,*(a+1)就是对第二行地址进行解引用,所以就拿到了整个第二行
//然后用sizeof()计算其大小,那就是:4*4=16。
printf("%d\n", sizeof(*(a+1)));
//答案:4/8
//分析:&a[0]是对第一行的数组名取地址,拿出的是第一行的地址
//&a[0]+1,跳过第一行,拿到的是第二行的地址。
//既然是地址,用sizeof()计算地址大小,就是4/8。
printf("%d\n", sizeof(&a[0]+1));
//答案:16
//分析:由上可知:&a[0]+1是第二行的地址,那*(&a[0]+1)就是,对第二行地址进行解引用,
//得到整个第二行,第二行有4个元素,4*4=16字节。
printf("%d\n", sizeof(*(&a[0]+1)));
//答案:16
//分析:a是二维数组数组名,但是a并没有单独放在sizeof()里面,所以a表示的是首元素地址,
//二维数组首元素地址,又是第一行的地址,然后在*a,相当于对第一行地址解引用,得到整个第一行
//第一行共有4个元素,所以就是4*4=16字节。
printf("%d\n", sizeof(*a));
//答案:16
//分析:a[3]?好像没有a[3],一共就3行,最多也就是a[0],a[1],a[2]。那来的a[3]呢?
//其实这里的a[3]的像是和a[0]一样,访问的是这个形式,所以是16。
//比如:int a = 10;
//sizeof(a); = sizeof(int);。
//上面的就是这个效果。
printf("%d\n", sizeof(a[3]));
return 0;
}
12.4、以上练习总结
总结:
数组名的意义:
1、sizeof(数组名),这里的数组名表示整个数组,计算的是整个数组的大小。
2、&数组名,这里的数组名表示整个数组,取出的是整个数组的地址。
3、除此之外所有的数组名都表示首元素地址。
13、指针笔试题
笔试题1:
#include <stdio.h>
struct Test
{
int num;
char* pcName;
short sDate;
char cha[2];
short sBa[4];
}* p = (struct Test*)0x100000;
//假设p的值为0x100000.如下表达式的值分别为多少?
//已知,结构体Test类型的变量大小是20字节。
//这个结果只针对X86平台。
int main()
{
//p现在是结构体指针,p+0x1,相当于p+1(因为16进制的0x1也就是10进制的1),因为现在p、还是结构体指针,且每个结构体指针是20字节
//所以p每+1,相当于跳过20个字节,这20是十进制数,转为16进制是14
//所以p+1--->0x100000+20(十进制)--->0x100000+0x100014=0x100014。
printf("%p\n", p + 0x1);
//现在将p强制类型转换为无符号长整型了,意思就是p现在由结构体指针转为整型了,那
//p+0x1,就是直接加1即可。所以:p+0x1--->p+1(因为16进制的0x1也就是10进制的1)--->0x100000+1=0x100001
printf("%p\n", (unsigned long)p + 0x1);
//现在将p强制类型转为无符号int*类型的了,那现在p+0x01--->p+1,因为现在p是int*类型的,
//所以每加1,相当于跳过4个字节,所以:p+0x01--->0x100000+0x000004=0x100004
printf("%p\n", (unsigned int*)p + 0x1);
return 0;
}
输出:

笔试题2:(在我电脑上运行没结果)
#include <stdio.h>
int main()
{
int a[4] = { 1,2,3,4 };
int* ptr1 = (int*)(&a + 1);
int* ptr2 = (int*)((int)a + 1);
printf("%x,%x", ptr1[-1], *ptr2);
return 0;
}
输出:

分析:要注意以下几个重要的点:
-
大小端存储模式。
-
int*+1和int+1的区别。
-
ptr1[-1]代表什么意思?其实就是:*(ptr+(-1))—>*(ptr-1)。
首先在VS编译器下,是采用小端存储模式,所以数组a在内存中的存储,分布图如下:
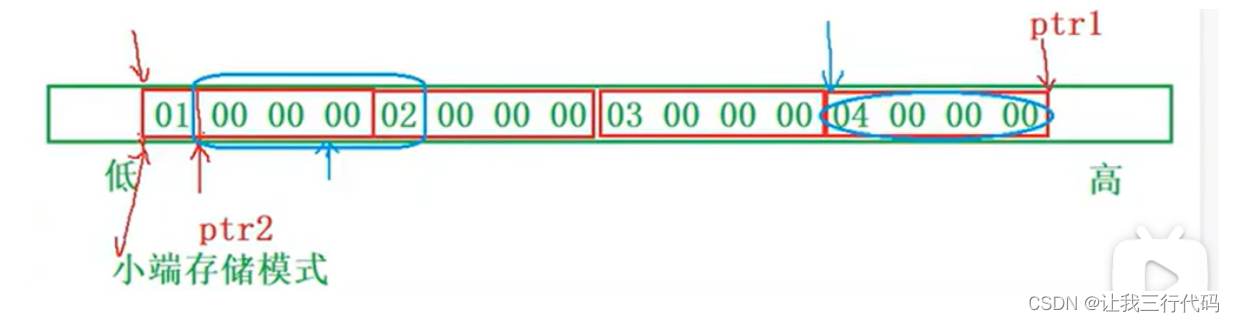
- 先分析ptr1,&a代表取整个a数组的地址,然后&a+1跳过整个a数组地址,所以ptr1指向的位置如上图。并且&a+1是int(*)[4]类型的,所以需要强制类型转换位int(*)。这个很容易理解。
- 在分析ptr2,a是数组名,是数组首元素地址,现在的a还是int*类型的,但是现在给强制类型转换了—>(int)a,如果a还是int*类型的,那a+1,就是一次性跳过4个字节。但是现在a是int类型的了,那么a+1,就只是简单的+1了。然后(int*)((int)a + 1)又将int类型的值变为in\t*类型的,所以现在ptr2指向第一个整型里面的第二个字节的位置。
下面计算结果:
- ptr1[-1]—>*(ptr1+(-1))—>*(ptr1-1),那么ptr1就指向了,如下位置:
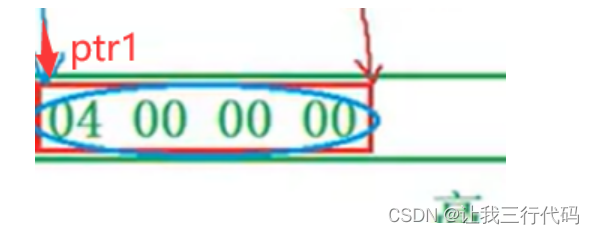
然后又因为是小端存储,所以在拿取是也应该反着拿取,所以拿取结果就是:0000004,由于前面0省略,结果为:4。
- *ptr2的结果,需要在指向的位置,向后读取4个字节,因为ptr2是int*类型的,如上图(左边蓝色圈部分)就是ptr2要读取的结果,然后又因为是小端存储,所以在拿取是也应该反着拿取,所以拿取结果就是:02000000,由于前面0省略,结果为:2000000。
笔试题3:
#include <stdio.h>
int main()
{
int a[3][2] = { (0,1),(2,3),(4,5) };
int* p;
p = a[0];
printf("%d", p[0]);
return 0;
}
输出:

分析:首先这里是有个坑的,二维数组{}里面是小括号,是括号表达式,括号表达式的最终结果是以最左则的表达式结果为准,所以说最终二维数组中只有三个元素:{1,3,5},其余的用0填充,所以说最终的二维数组的结果为:
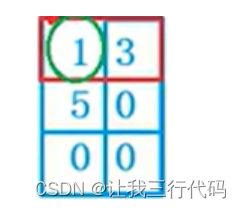
a[0]是二维数组第一行元素的数组名,此数组名即没有单独在sizeof()里面,又没有&数组名。所以a[0]表示首元素地址,即a[0][0]的地址,因为p = a[0],所以p被赋值给a[0][0]的地址。
那p[0]—>*(p+0)—>*p,因为p是a[0][0]的地址,所以在解引用就是元素1。
笔试题4:
#include <stdio.h>
int main()
{
int a[5][5];
int(*p)[4];
p = a;
printf("%p\n%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
return 0;
}
输出:

分析:首先我们先要画处a数组的图,这个图最好是画成在内存中存储的形式:
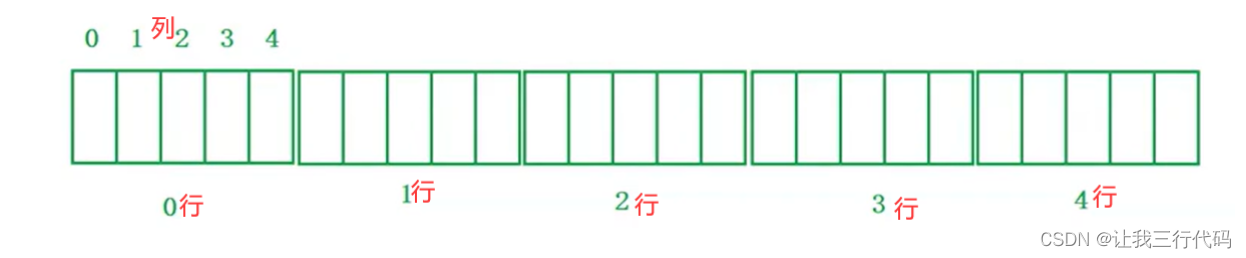
我们来分析以下a和p
- a是数组名,即没有单独放在sizeof()里面,有没有&数组名、所以a是首元素地址,代表二维数组第一行的地址。那么a就是数组指针类型,且类型为:int(*)[5]。
- p题目中给的数组指针类型是int(*)[4]
- 可以发现:a和p的数组指针类型不相同。那p = a能直接赋值吗?答案:是可以直接赋值的,无非就是有警告,但这个p的地址在经过a的赋值后肯定会指向数组首元素地址的。如下:
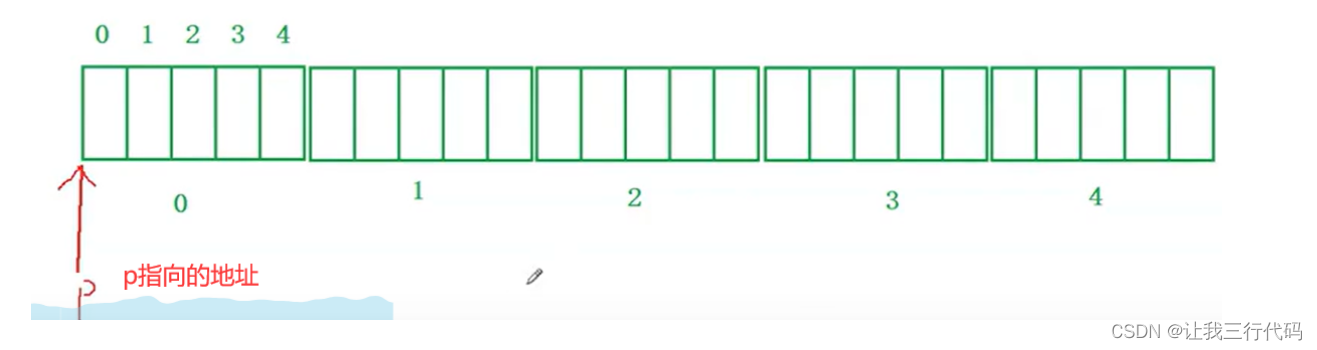
但是p的数组指针类型是int(*)[4],所以p一回只能访问或跳过4个整型的数据。
那好基本问题理顺了,现在看printf(),我们只需要找到p[4][2]的地址 和a[4][2]的地址,就可以了。
- 首先,a[4][2]地址很好找,按照二维数组的规则来就能找到,如下图:
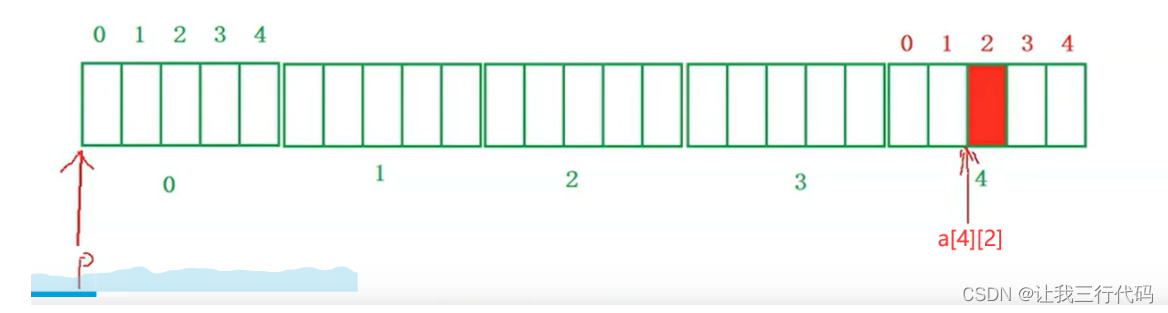
- 接着来找p[4][2]的位置,我们先来转换以下:p[4][2]—>*(*(p+4)+2),上面说过了p+/-1跳过4个整型元素,那p+4就是跳过16个整型元素,那p的位置就是如下图的地方:
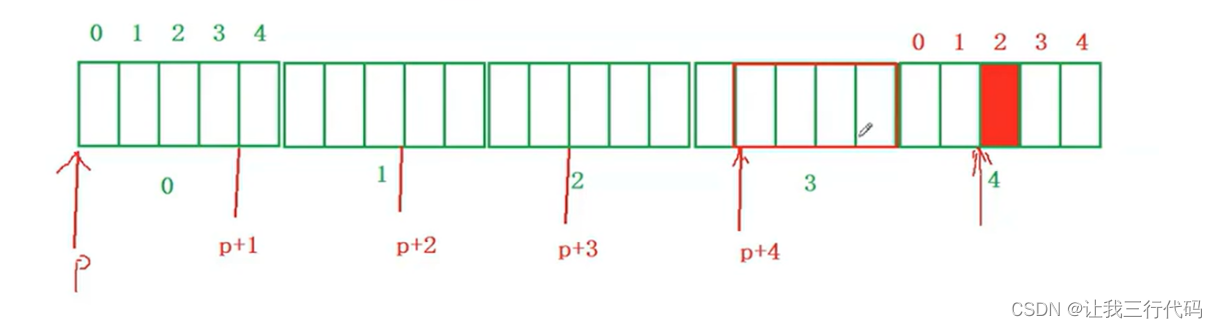
- 但是现在还没结束,我们要找到*(*(p+4)+2)的地址,就是在*(p+4)的基础上在+2个整型元素,如下图:
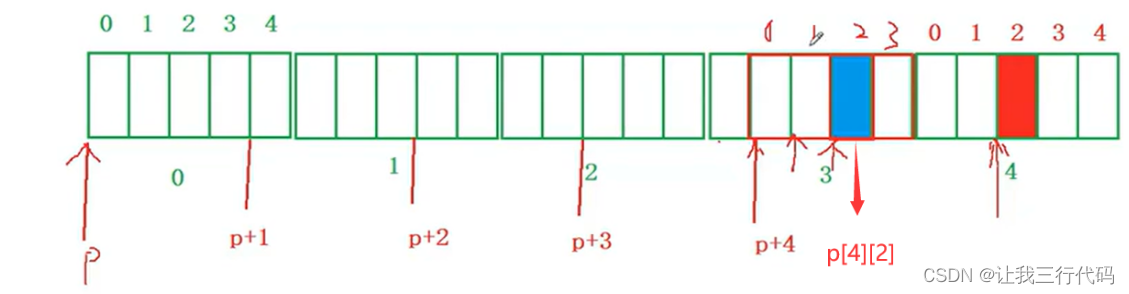
那这样p[4][2]的地址位置就找到了。
最后计算结果:
以前说过,两个指针相减,得到的是指针和指针之间的元素个数。那p[4][2]和a[4][2]之间相差个个数就为4,如下图:
但是这里还需要注意知识点:在内存中是由低地址和高地址的,由于p[4][2]在低地址,a[4][2]在该地址,那&p[4][2] - &a[4][2]就是低地址-高地址,那结果应该是-4才对。
但是当我们打印的时候,还有些地方不一样。
-
%d打印很正常,-4就打印-4,所以说第二个输出结果就为-4。 -
但是
%p打印的时候就不能直接打印-4,这个时候就牵涉到存储在内存中存储的知识点了,这个时候需要写出-4的原码,反码,补码。- -4的原码:10000000000000000000000000000100
- -4的反码:11111111111111111111111111111011
- -4的补码:11111111111111111111111111111100
现在需要以
%p的形式来打印,换句话说是以地址的形式来打印,地址是没有原码,反码,补码概念的。所以可以直接通过内存中的补码打印出来:11111111111111111111111111111100转为16进制为:FFFFFFFC。
所以最终结果打印为:
FFFFFFFC
-4
笔试题5:
#include <stdio.h>
int main()
{
char* a[] = { "work","at","alibaba" };
char** pa = a;
pa++;
printf("%s\n", *pa);
return 0;
}
输出:

分析:如下画图:
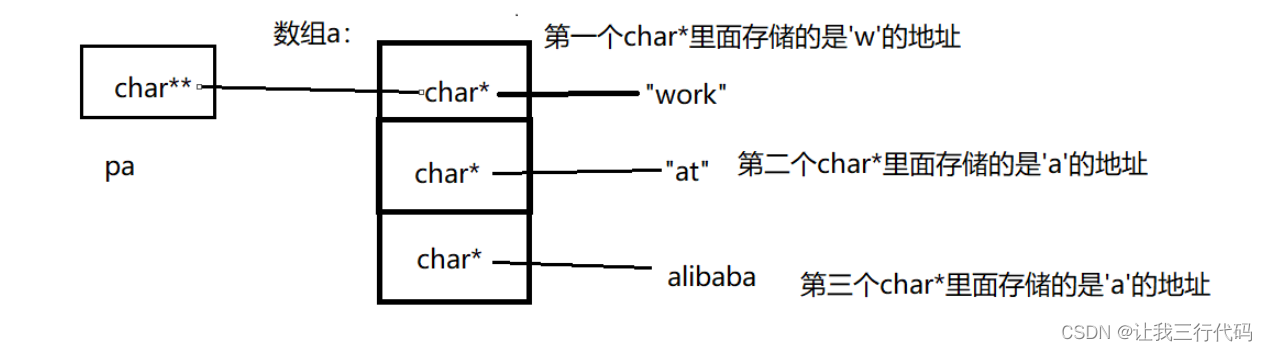
现在pa++,那pa指向的位置就从第一个char*指向了第二个char*,然后*pa,解引用之后,得到了第二个char*的值,而第二个char*的值,里面存放的是’a’的地址,所以以%s进行打印,就会输出:“at”。
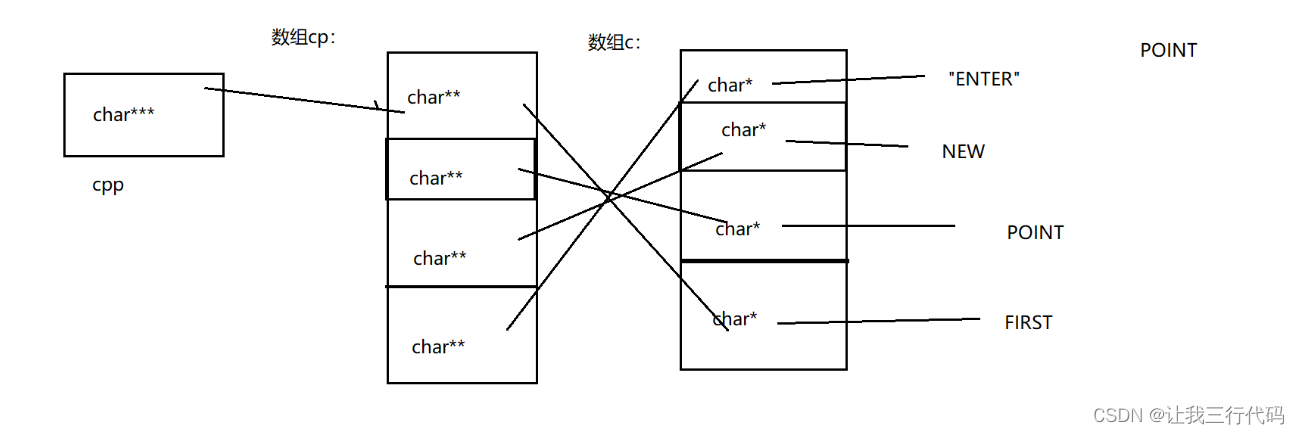
笔试题6:(太复杂,目前能力有限,这里只听过程,不做笔记,以后回来重听)
#include <stdio.h>
int main()
{
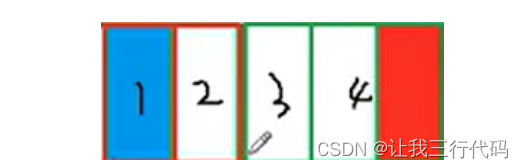
char* c[] = { "ENTER","NEW","POINT","FIRST" };
char** cp[] = { c + 3,c + 2,c + 1,c };
char*** cpp = cp;
printf("%s\n", **++cpp);
printf("%s\n", *-- * ++cpp + 3);
printf("%s\n", *cpp[-2] + 3);
printf("%s\n", cpp[-1][-1] + 1);
return 0;
}
输出:

画出示意图: