C++线程库(2)
- 线程同步
- 互斥锁
- 条件变量与互斥锁的搭配使用
- 举例1
- 举例2
- 举例3
线程同步
在C++线程库(1)的博客中说了互斥量只能解决多个线程访问共享资源的问题,但是很明显没有次序感,而线程安全就是不同线程访问资源但是得到的结果是固定的就这就线程安全,所以为了保证线程安全,互斥锁一般与条件变量搭配使用。
我们知道进程是资源分配的基本单位,线程是CPU调度的基本单位。实际上我们创建线程就是在堆区申请了空间,而原本一个进程分配的4G空间中的堆区数据,代码区,数据区这些区域存放的数据都是资源,这些资源都可以被创建的线程进行访问。这就是线程进程的区别,线程可以共享资源,而多进程是拥有不同的资源。
void fun(int a,int b) {
int c=a+b;
}
int main() {
int x=10;
int y=20;
int z=0;
z=fun(x,y);
}
如果我们编写程序这么一段程序,那么操作系统层面是怎么操作的呢?
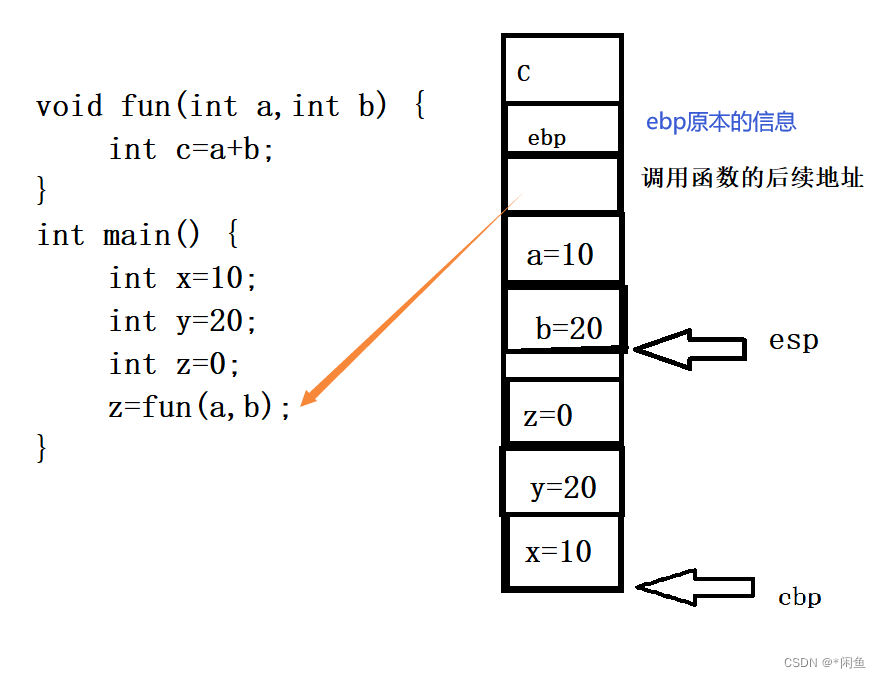
首先在操作系统中存在很多寄存器,其中就有ebp和esp用于栈资源保护,比如上面代码中,主函数开始运行,在栈区从高地址向低地址进行分配内存,ebp首先在栈底,然后向上进行赋值,x=10,y=20,z=0,而调用x,y,z的时候呢就是通过ebp的偏移量进行调用,偏移4字节就是x,偏移8字节就是y,然后再栈顶重新分配内存,来传递参数,将x和y的值赋值给a和b,然后再向上有一块地址空间存放调用fun函数的后续地址,姐这上面会有一块地址空间存放主函数ebp现在的位置,然后ebp移动到该位置,开始调用该函数,如果访问c变量就向上偏移4字节,调用结束之后,会获取ebp的原本位置,进行复原,esp和ebp回到原本位置,执行其他代码。
互斥锁
void func(char ch) {
for (int i = 0; i < 10; ++i) {
for (int j = 0; j < 10; ++j) {
printf("%c ", ch);
}
printf("\n");
}
printf("\n");
}
int main() {
std::thread tha(func,'A');
std::thread thb(func, 'B');
std::thread thc(func, 'C');
std::thread thd(func, 'D');
std::thread the(func, 'E');
tha.join();
thb.join();
thc.join();
thd.join();
the.join();
return 0;
}
我们试运行上面代码,会发现其中打印出来是乱码,这是为什么呢?
因为我们的打印的输出都是再屏幕上,如果不同线程打印在不同的终端上就会出现不同的结果。
例如:
void func(char ch) {
char filename[20] = {};
sprintf(filename, "test%c.txt", ch);
FILE* fp = fopen(filename, "w");
for (int i = 0; i < 10; ++i) {
for (int j = 0; j < 10; ++j) {
fprintf(fp,"%c ", ch);
}
fprintf(fp,"\n");
}
fprintf(fp,"\n");
fclose(fp);
fp = nullptr;
}
这样我们就会创建不同的五个文件进行打印,我们运行之后也会发现创建了五个文件,其中的的数据也很整齐。
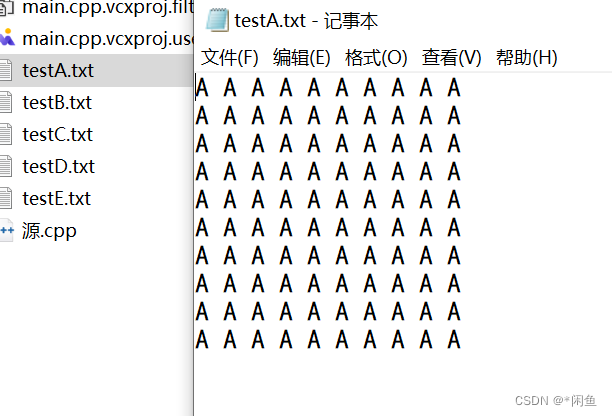
条件变量与互斥锁的搭配使用
举例1
std::mutex m_cv;
std::condition_variable cv;
std::string mydata;
bool ready=false;
bool processed = false;
void worker_thread() {
std::unique_lock<std::mutex> lock(m_cv);
while (!ready) {
cv.wait(lock);
}
mydata += "数据处理完成";
processed = true;
lock.unlock();
cv.notify_one();
}
int main() {
std::thread tha(worker_thread);
mydata += "data";
{
std::unique_lock < std::mutex >lock(m_cv);
ready = true;
cout << "main() signal data ready for processing" << endl;
}
cv.notify_one();
{
std::unique_lock<std::mutex> lock(m_cv);
while (!processed) {
cv.wait(lock);
}
}
cout << "back int main(), data" << mydata << endl;
tha.join();
return 0;
}
我们先通过讲解上面代码进行理解:
首先程序编译链接,将程序编译为二进制文件(可执行文件),其实程序执行的第一个程序不是主函数,其实会有一个函数运行在主函数之前,用来初始化堆区,栈区,代码区等。
首先创建线程tha,然后主线程和tha线程两者竞争获得锁(用户态切换到内核态,获取锁,如果获得锁了就又切换到用户态,如果没有获得锁就会终端线程,就会将这个线程放入锁得等待队列中),我们举例tha线程获取到锁,他获取到锁之后呢ready为false,进入循环,进入cv等待函数。该函数有四个步骤,第一步:弃锁,第二步:终止线程,将线程放入条件变量得等待队列中,第三步:等待被唤醒,被唤醒之后线程会被放入互斥锁得等待队列中,第四步:获取锁。
而很明显这四个步骤中被卡在了第三步,此时呢因为其释放了锁,所以主线程可以获得锁了,获得锁之后将ready置为true,然后主线程执行了cv的唤醒函数,这样tha线程被唤醒,唤醒之后进入锁的等待队列,此时很明显两个线程又都在获取锁,我们举例这个时候主线程获取到锁,获取到锁之后,processed为false,所以进入循环,然后主线程也进入cv条件变量的等待队列,这里的流程和tha线程等待是一样的,也释放了锁资源,这个时候tha线程获得锁(从锁的等待队列出来),ready为true,继续执行,将processed置为true,然后唤醒主线程,主线程从条件变量的等待队列中出来,进入互斥锁的等待队列,因为在tha线程中工作函数结束之后资源会释放,所以函数结束,锁页会自动进行解锁,解锁之后主线程的会从互斥锁的等待队列中出来,最后因为processed为true,所以不会再次进入循环,执行下面语句,等待tha线程结束。而这个线程的瑕疵就在于在函数结束之后才会自动解锁,我们需要优化,在唤醒主线程前进行解锁。
举例2
同样先看代码:
const int n = 10;
int tag = 1;
std::mutex mtx;
std::condition_variable cv;
void funa() {
std::unique_lock<std::mutex> lock(mtx);
for (int i = 0; i < n; ++i) {
while (tag!=1)
{
cv.wait(lock);
}
cout << "funa: A "<<endl;
tag = 2;
cv.notify_all();
}
}
void funb() {
std::unique_lock<std::mutex> lock(mtx);
for (int i = 0; i < n; ++i) {
while (tag != 2)
{
cv.wait(lock);
}
cout << "funb: B " << endl;
tag = 3;
cv.notify_all();
}
}
void func() {
std::unique_lock<std::mutex> lock(mtx);
for (int i = 0; i < n; ++i) {
while (tag != 3)
{
cv.wait(lock);
}
cout << "func: C " << endl;
tag = 1;
cv.notify_all();
}
}
int main() {
std::jthread tha(funa);
std::jthread thb(funb);
std::jthread thc(func);
return 0;
}
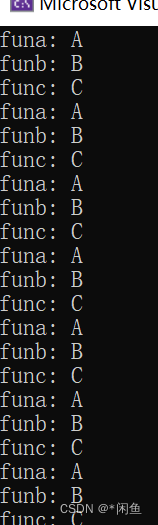
首先三个创建三个线程,三个线程在竞争锁,我们举例线程C获得锁,线程AB就在互斥锁的等待队列中,执行C线程,因为tag值为1,所以线程C进入条件变量的等待队列中,同样的四个步骤:
- 释放锁
- 进入条件变量的等待队列
- 等待被唤醒,唤醒后进入锁的等待队列中
- 获得锁
也卡在了条件变量的等待队列中,然后线程AB中的第一获得锁,我们举例B获得锁,B线程和C线程一样,进入条件变量的等待队列中,然后A线程获得锁,不会进入条件变量的等待队列中,进行输出,然后将tag值设置为2,唤醒线程。注意这里是唤醒所有的线程,唤醒了BC线程,两个线程进入到锁的等待队列中,等待获取锁,而线程A会再一次进入循环而因为tag值设置为2,而进入条件变量的等待队列中,释放锁,BC线程抢占锁,如果C抢占到就会进入条件变量的等待队队列中,如果B抢到就会输出,从而唤醒其他线程,循环进入等待队列之后其他线程才可以获取锁,依次循环下去就可以按照顺序打印到想要的结果,因为tag的值和一个线程相对应,其他线程就算抢占到锁也会进入条件变量的等待队列中。
唤醒所有线程:我们在讲解程序的时候大家也可以看到是唤醒所有线程,这个和唤醒一个有什么不一样吗?和名字一样,唤醒一个线程就会随机唤醒一个线程,而另一个就是唤醒所有的线程。这里为什么会用唤醒所有,而举例1会用唤醒一个呢?举例1只有两个线程,唤醒一个线程也肯定唤醒的是另一个线程,而这个程序创建了三个线程,如果线程A在输出之后唤醒了C线程,A线程调用完唤醒函数之后页会进入到条件变量的等待队列中,而C线程执行下去页会进入到条件变量的等待队列中,我们会发现程序锁死了,三个线程都在条件变量的等待队列中,没有程序来唤醒线程。----但是呢唤醒所有线程这里会存在一个惊群现象。惊群现象呢就是接收到数据之后唤醒了所有的线程,然而这些线程都不能处理这个数据而再一次进入条件变量等待队列,这很显然效率很低。所以编程过程中epoll一般只对应一个套接字,因为在epoll过滤接收到数据之后,只有相对应的套接字来处理。
举例3
我们试着编写一个程序,创建三个线程,调用funa,funb,func函数,依次输出1,2,3,4,5,6也就是线程a输出1,4,7等,线程b输出2,5,8,线程C输出3,6,9等输出到100
程序是这样编写的:
const int n = 100;
int tag = 1;
std::mutex mtx;
std::condition_variable cv;
void funa() {
std::unique_lock<std::mutex> lock(mtx);
while (tag <= n) {
while (tag % 3 != 1 && tag <= n) {
cv.wait(lock);
}
if (tag > n) break;
if (tag % 3 == 1)
cout << "funa:" << tag++ << endl;
cv.notify_all();
}
cv.notify_all();
}
void funb() {
std::unique_lock<std::mutex> lock(mtx);
while (tag <= n) {
while (tag % 3 != 2 && tag <= n) {
cv.wait(lock);
}
if (tag > n) break;
if(tag%3==2)
cout << "funb:" << tag++ << endl;
cv.notify_all();
}
cv.notify_all();
}
void func() {
std::unique_lock<std::mutex> lock(mtx);
while (tag <= n) {
while (tag % 3 != 0 && tag <= n) {
cv.wait(lock);
}
if (tag > n) break;
if (tag % 3 == 0)
cout << "func:" << tag++ << endl;
cv.notify_all();
}
cv.notify_all();
}
int main() {
std::jthread tha(funa);
std::jthread thb(funb);
std::jthread thc(func);
return 0;
}
可以试着理解一下这段代码为什么这样编写?
为了防止在线程结束的时候有线程在条件变量的等待队列中,所以要唤醒,当然我们编写的这个程序因为在函数中设置的条件比较多所以也可在结束以不唤醒。
当然这个题可以有多种方法做出来,但是大家要有这样的习惯。