接上篇《23、urllib使用post请求百度翻译》
上一篇我们讲解了如何使用urllib实现百度翻译的效果。本篇我们来讲解如何使用urllib抓取某某电影排行榜信息。
一、某某电影介绍
1、某某电影网站
某某电影成立于2005年,最初只是一个小型的电影社区,但随着时间的推移逐渐发展成为了一个拥有海量用户和内容的大型电影网站。目前,某某电影已成为全球最大的中文电影数据库之一,其数据库包含了来自各个国家和地区的电影信息。它提供了最新的电影资讯、电影评论、评分和推荐等服务,同时也提供了一个交流、分享和发现电影的平台: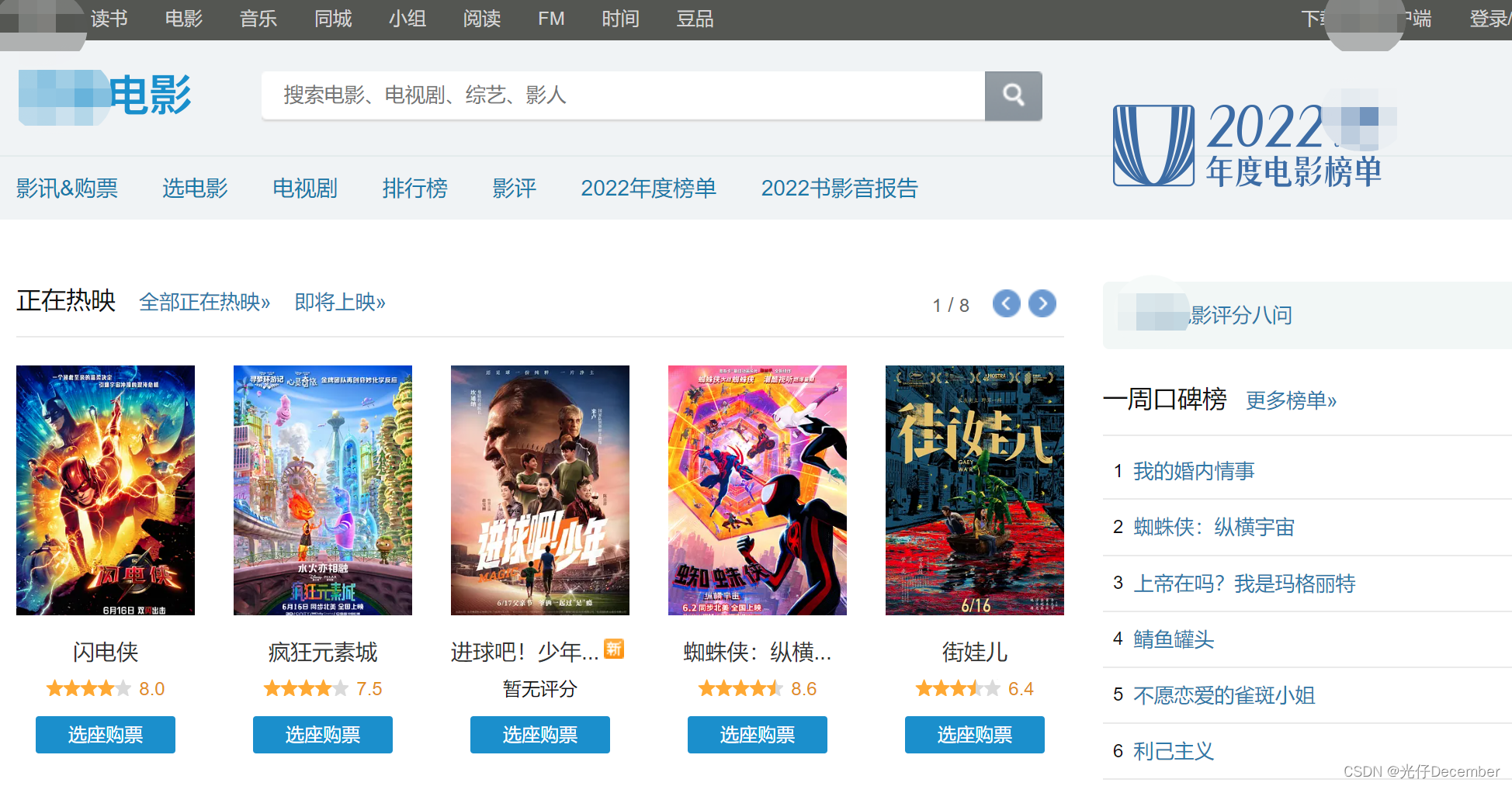
2、电影排行榜介绍
点击网站首页的“排行榜”,或这直接浏览器输入“https://movie.douban.com/chart”地址,都可以看到某某电影的排行榜信息,是以从上到下的列表形式展示: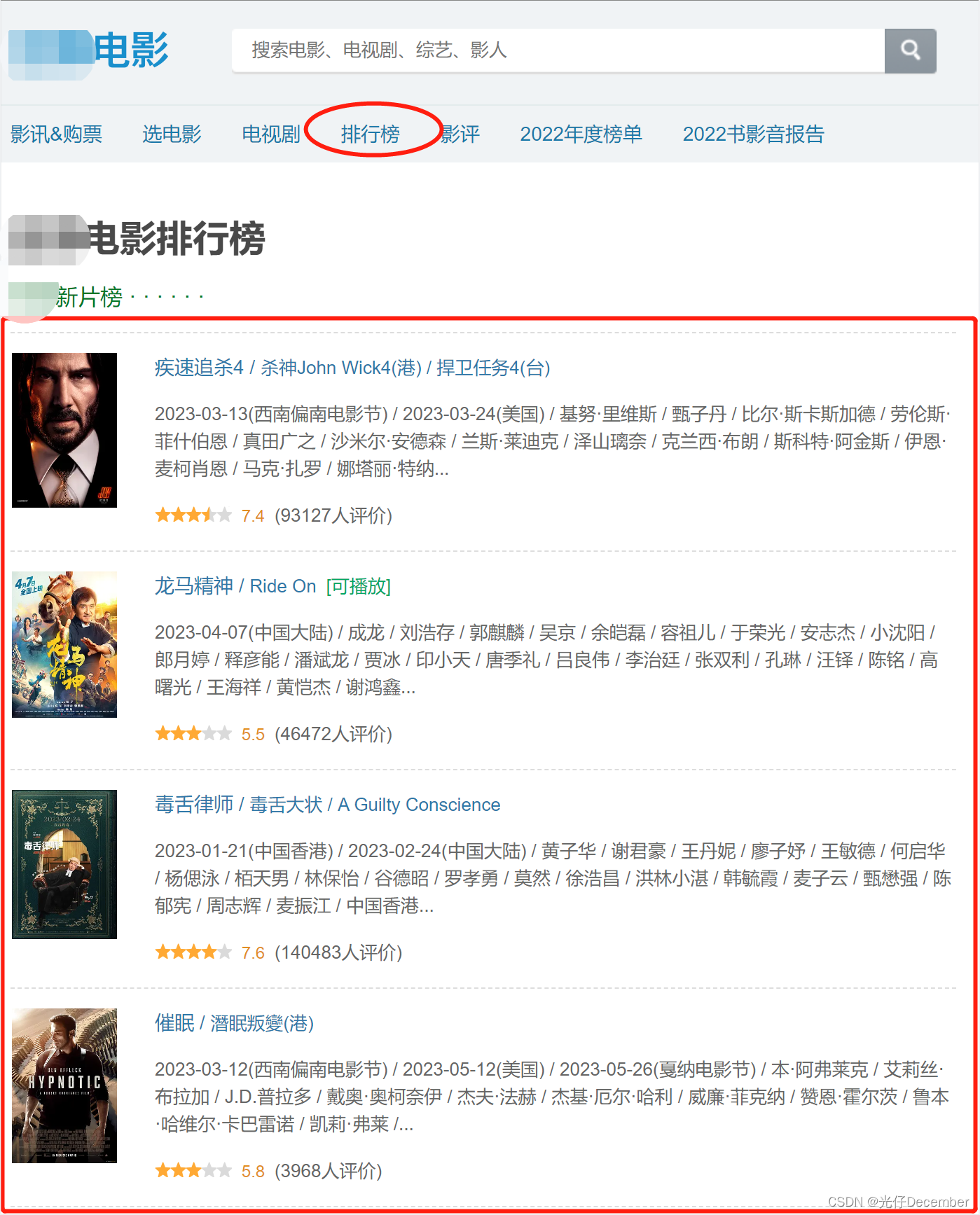
如果我们选择“动作”类电影,地址会变为“https://movie.douban.com/typerank?type_name=动作&type=5&interval_id=100:90&action=”,内容是一行2个,从上到下布局的列表: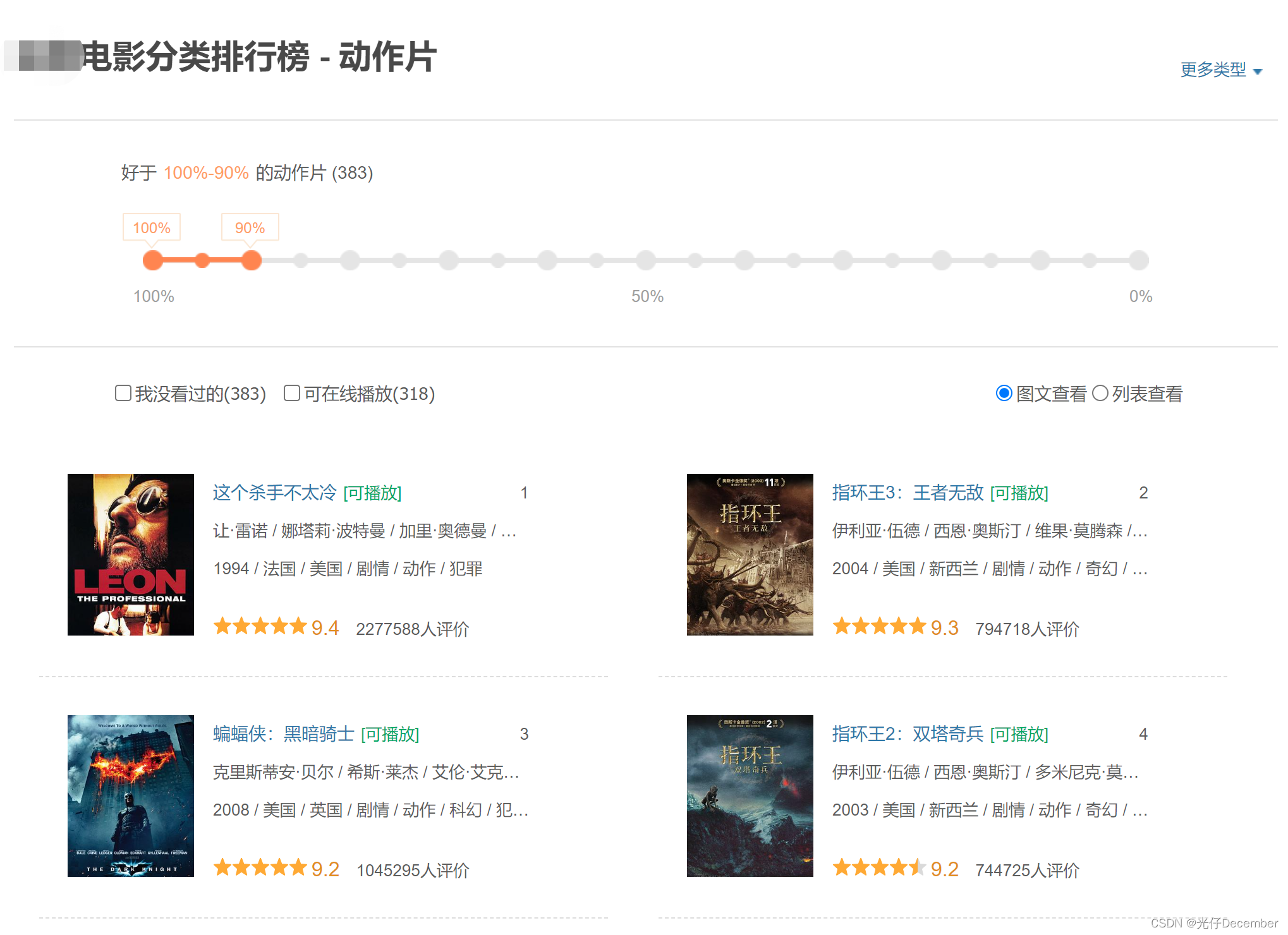
其中地址栏的type_name就是电影的类型,type是电影类型ID,interval_id是“好于xx%-xx%的xx片”,是一个区间值,用“:”分割。
二、抓取动作类电影首页
1、分析页面数据请求
我们按照上面网页的分析,准备抓取动作类电影第一页的所有电影信息。
我们F12打开动作类电影首页的源码信息,刷新页面后,就可以看到很多请求信息:
通过分析判断,我们找到一个“”的http请求,这里的结果看起来就是电影列表的请求结果: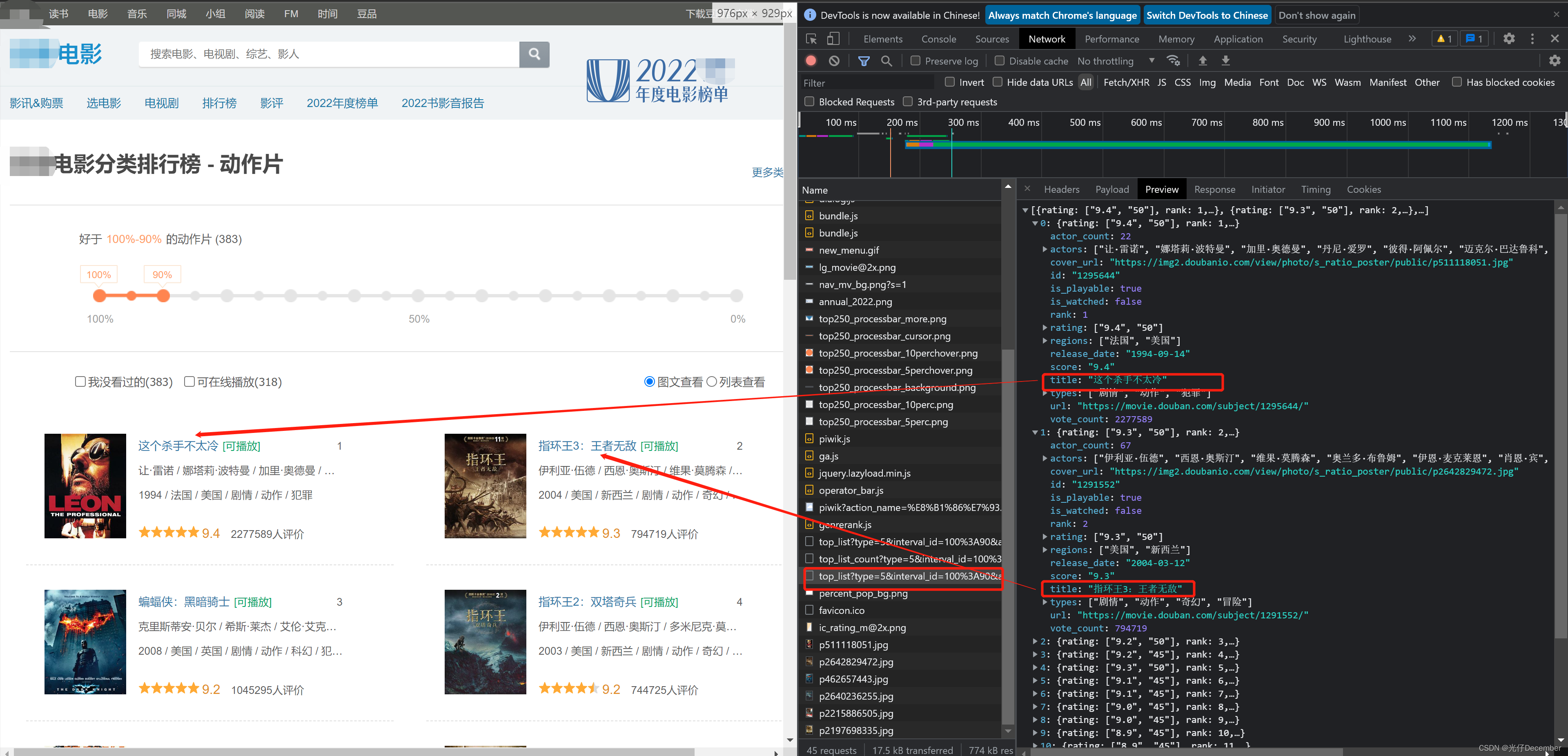
地址是“https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20”,是一个get请求: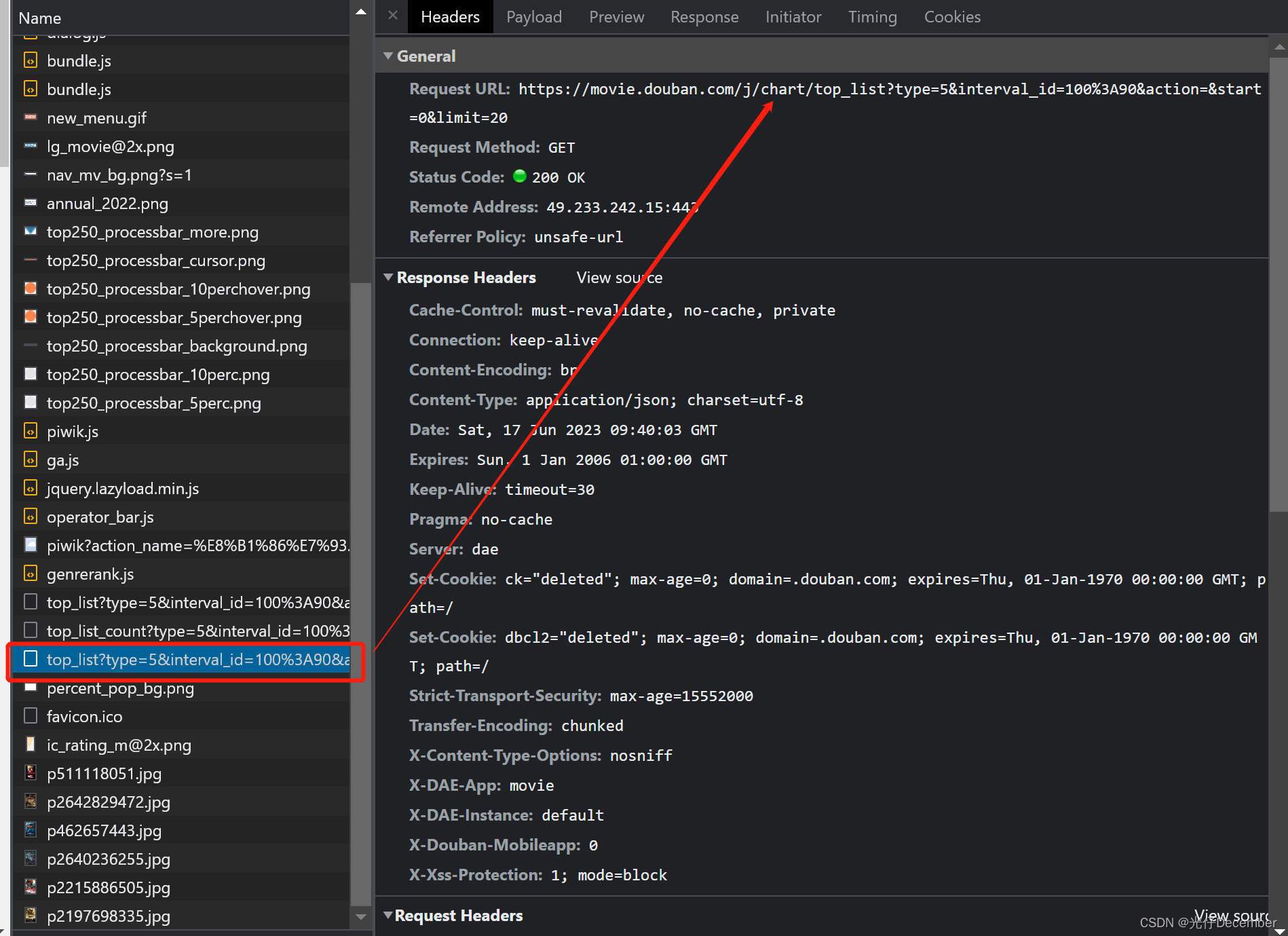
请求参数有“type”、“interval_id”、“action”、“start”和“limit”: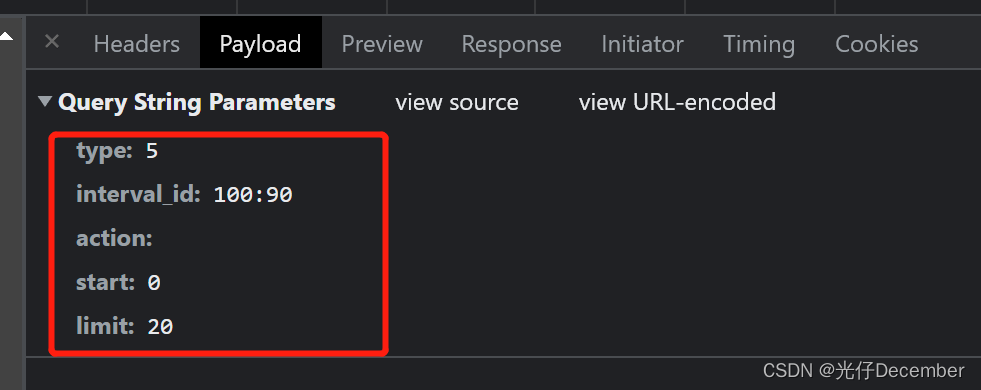
这里和之前一样,type是电影类型ID,interval_id是“好于xx%-xx%的xx片”,是一个区间值,用“:”分割,start是当前获取的总数据量(目前的0是还没有获取任何数据),limit是本次新请求的数据量。
2、使用urllib抓取首页数据
我们已经确定了抓取的url地址为“https://movie.douban.com/j/chart/top_lis”,请求的参数也确定了,head参数按照之前百度翻译的规则,只需要定义好Cookie即可(这里顺带捎上User-Agent参数):
# _*_ coding : utf-8 _*_
# @Time : 2023-06-17 17:45
# @Author : 光仔December
# @File : 抓取某某电影数据
# @Project : Python_Projects
import urllib.request
# 某某电影排行服务的API地址,get请求的参数直接拼接在地址上
url = "https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.66 Safari/537.36',
'Cookie': 'll="118237"; bid=XC5KAjdVhr0; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1686994243%2C%22https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DdYERHe3ZepjqV24sOD9vz5FTFdU_VNfjjjJcv-wT7iKaTIkpeg3VXDZM4g-87dJO%26wd%3D%26eqid%3Dcdc028140007592b00000003648d7d48%22%5D; _pk_id.100001.4cf6=003d6c4f8c5a5918.1686994243.; _pk_ses.100001.4cf6=1; ap_v=0,6.0; __utma=30149280.1819017266.1686994243.1686994243.1686994243.1; __utmb=30149280.0.10.1686994243; __utmc=30149280; __utmz=30149280.1686994243.1.1.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utma=223695111.1834148081.1686994243.1686994243.1686994243.1; __utmb=223695111.0.10.1686994243; __utmc=223695111; __utmz=223695111.1686994243.1.1.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __yadk_uid=CNd55Pec33U7Y2fvSlRoIIPfHFHp2r6z; _vwo_uuid_v2=DD581C8DF7B5095A18828A5BEB7A2E02B|d387f0c02fd08058553b6ad87363290f; __gads=ID=abc089f235d209f0-22edbe9eaab400ed:T=1686994466:RT=1686994466:S=ALNI_Maj4OLb9xqctrwIkc4iumOK0U6MRw; __gpi=UID=00000c50aa502f07:T=1686994466:RT=1686994466:S=ALNI_MbWaQIC_DBfN6WNUac3i9Z6tLzQmA'
}
# 创建request请求对象
request = urllib.request.Request(url=url,headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的数据
content = response.read().decode('utf-8')
# 将结果写入json文件,因为里面有中文,所以要指定encoding编码格式
fp = open('douban.json','w',encoding='utf-8')
fp.write(content)结果,生成了一个json文件,里面就是电影信息: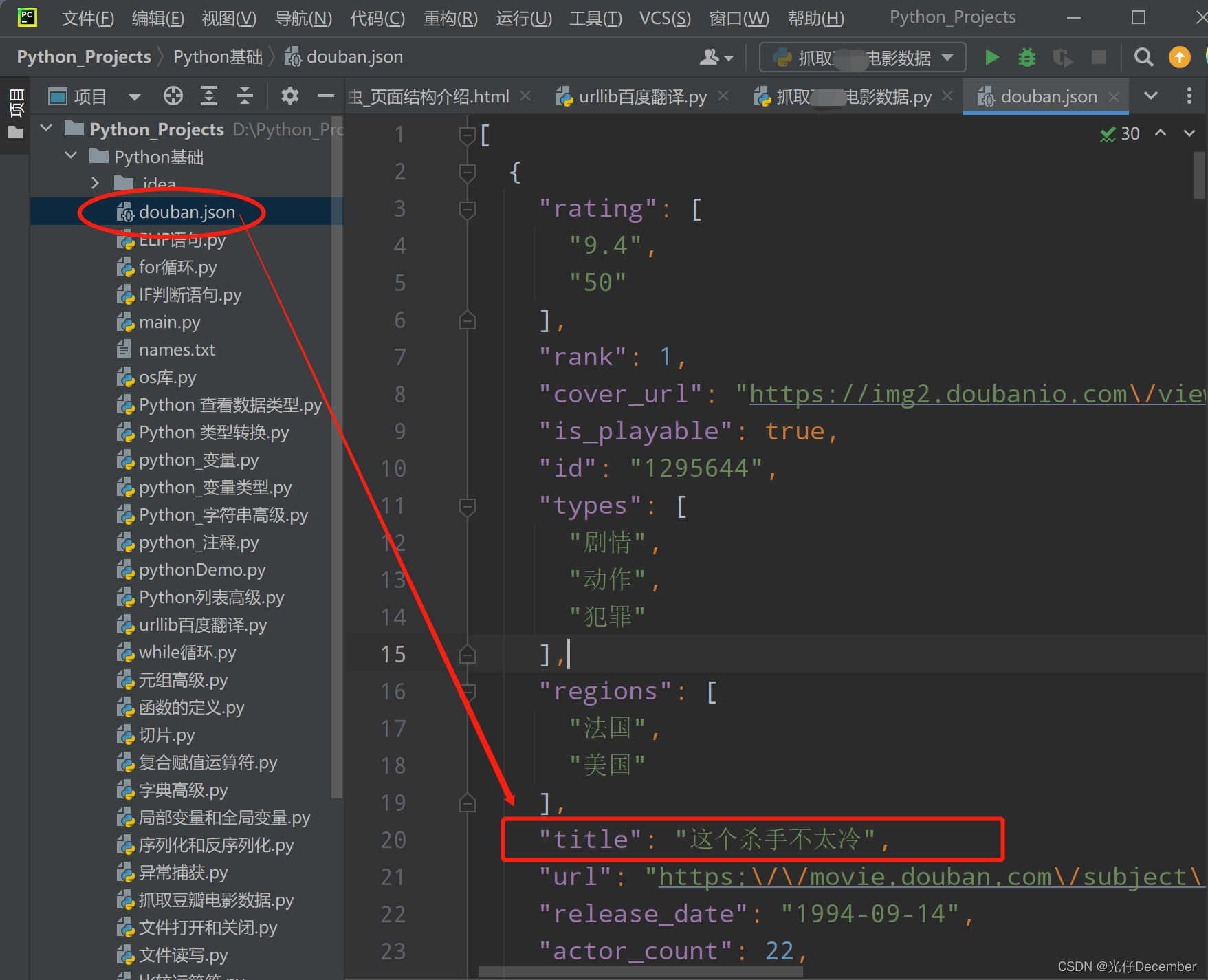
看的时候一般是一行,不好看,可以使用PyCharm的格式化,这样就会以json换行的格式显示,比较容易解读:
三、电影列表分页数据获取
我们一开始获取排行榜第一页的时候,只是看到20条数据,但是我们鼠标往下滑的时候,电影自动会继续加载,可以不停的往下刷: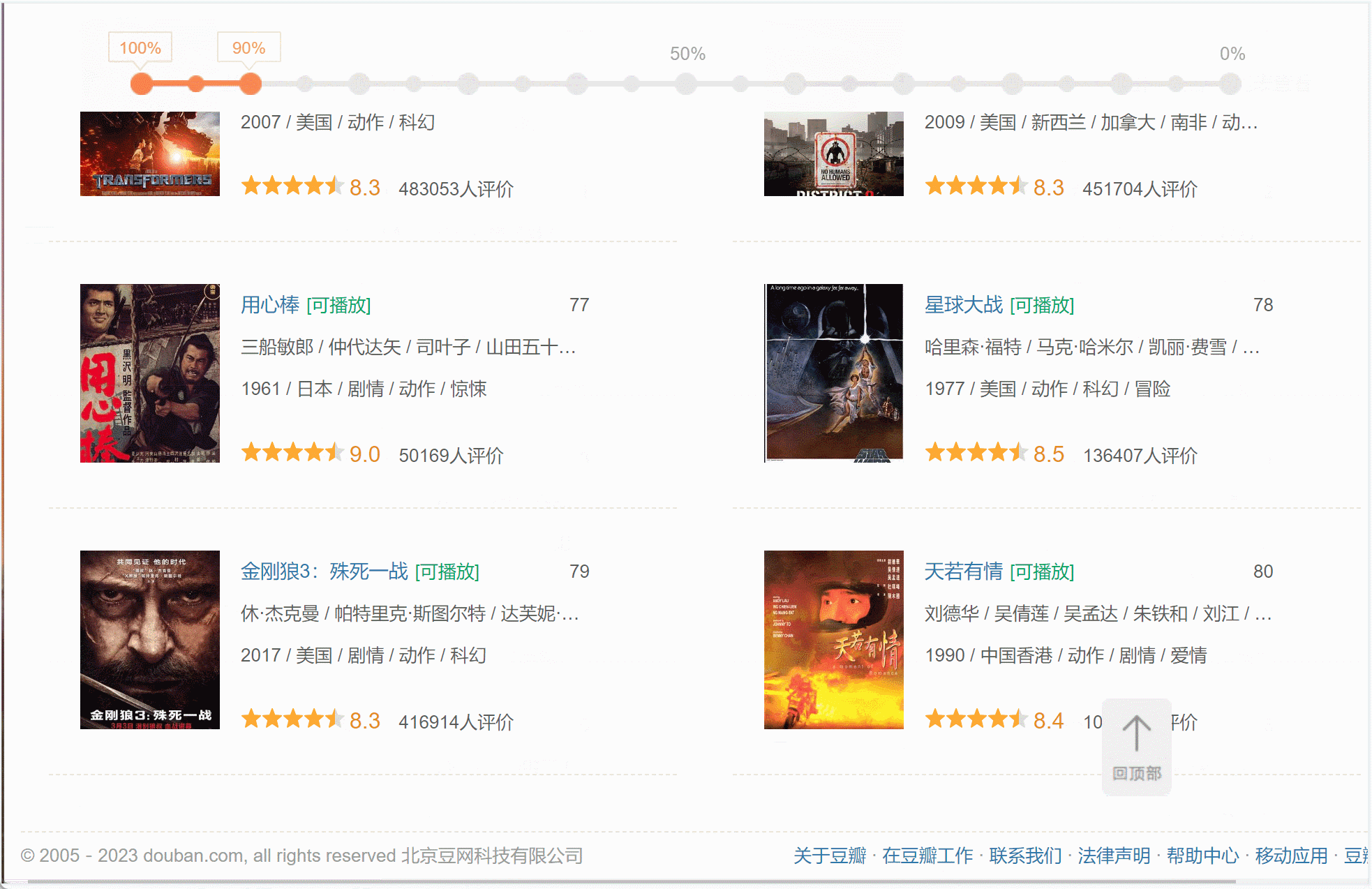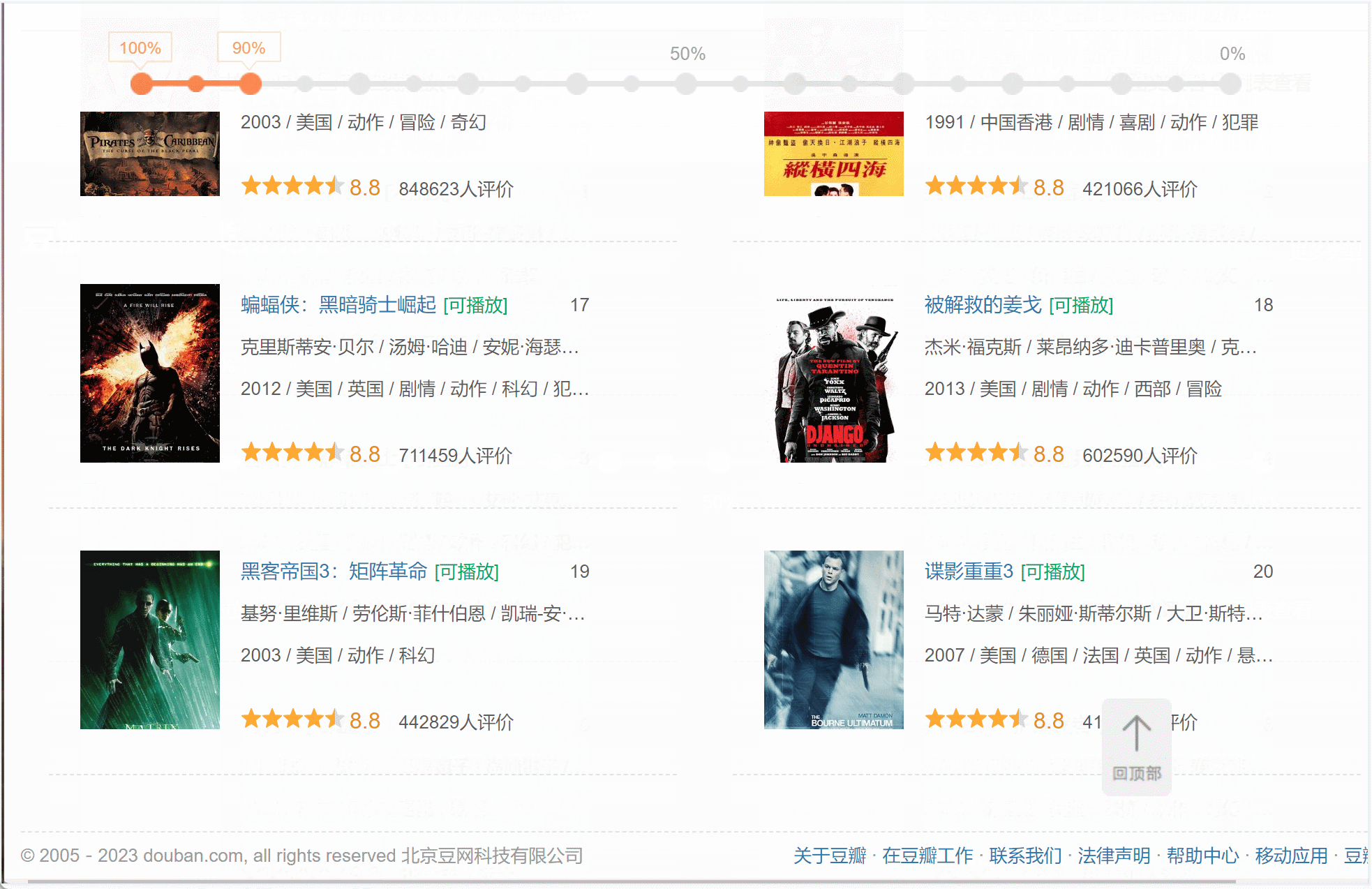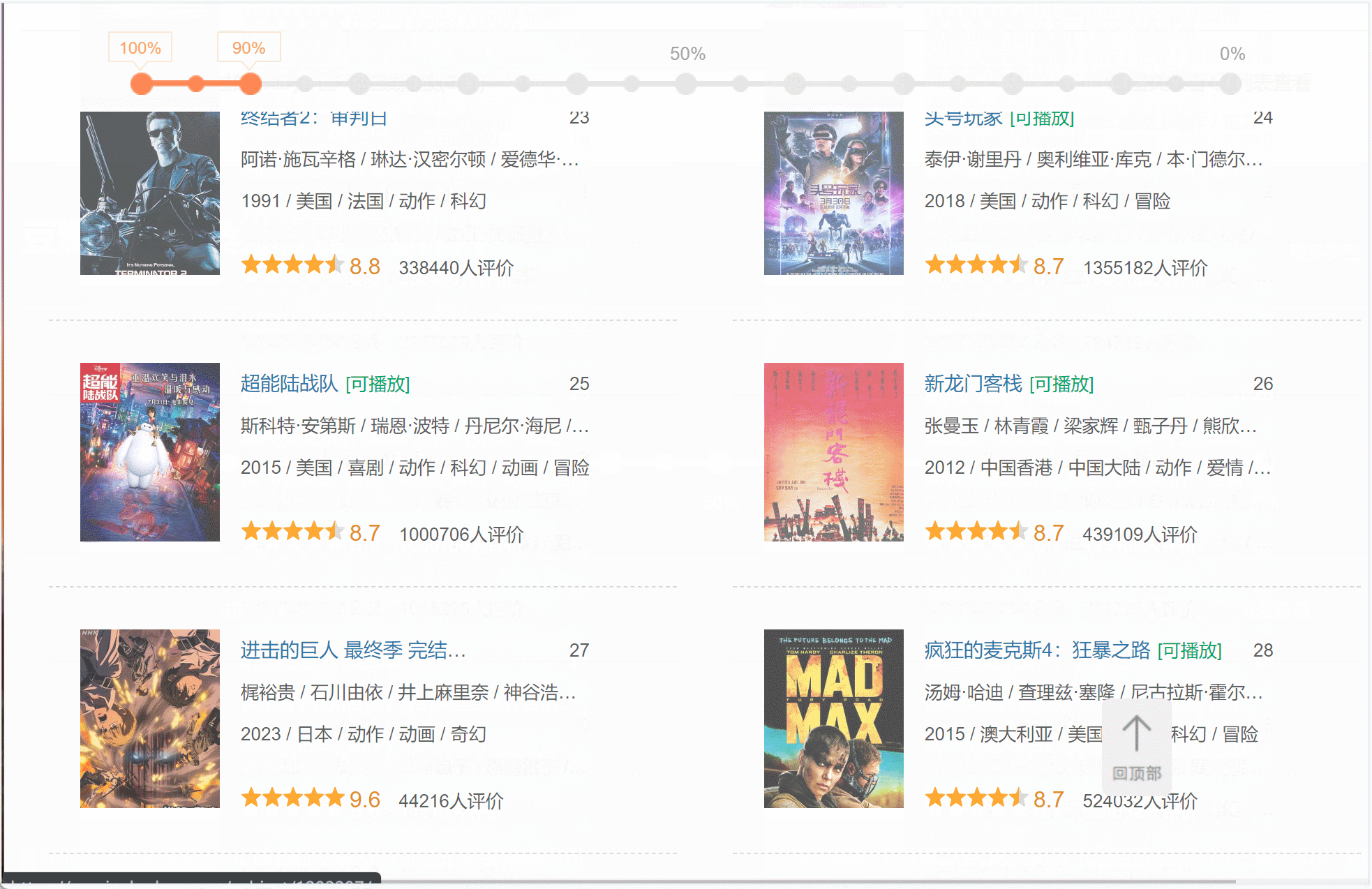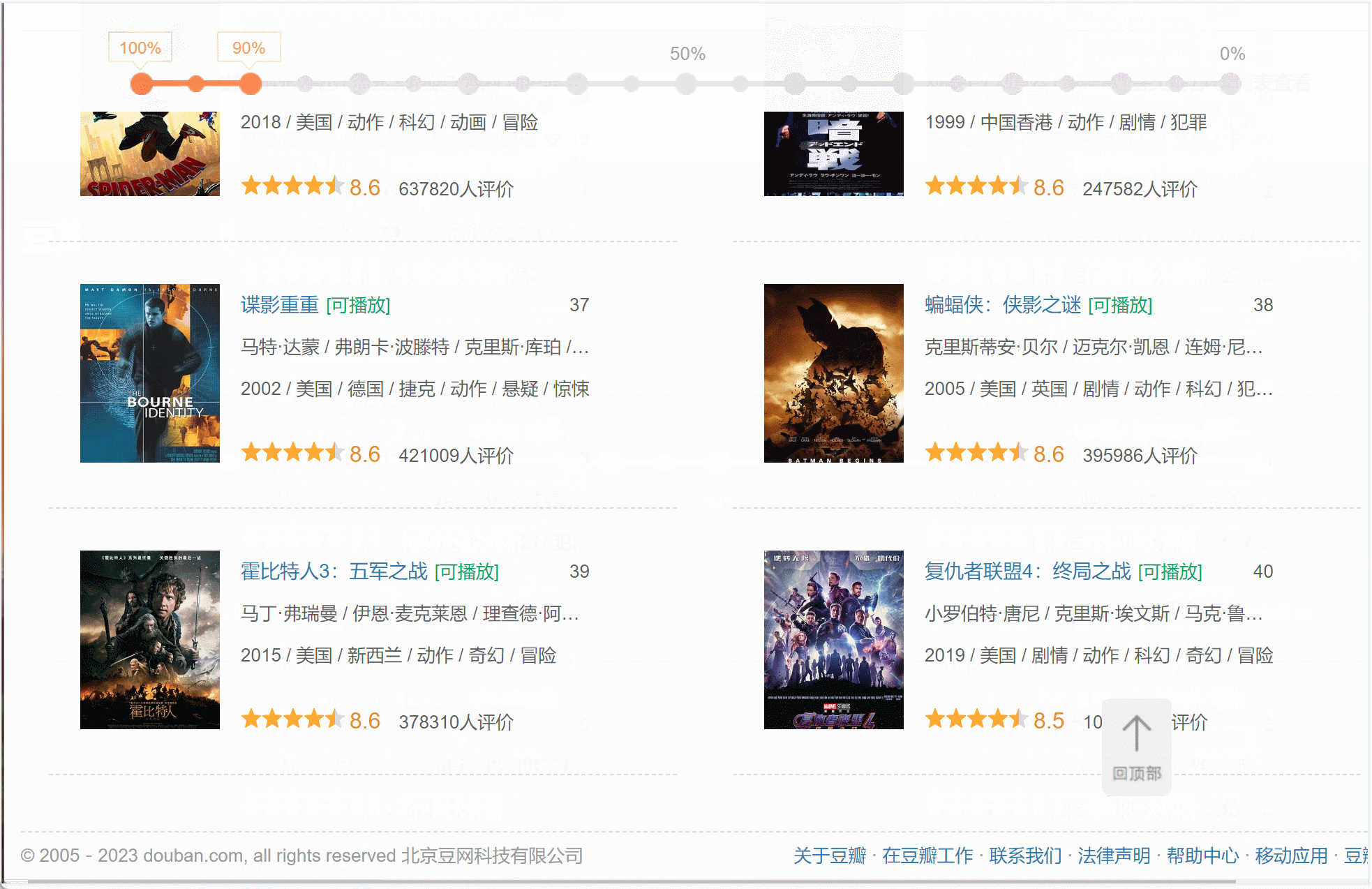
可以看到刷到20的时候顿一下,然后加载到40条,然后再顿一下,加载了60条。这种效果就是html页面的异步加载,是通过JavaScript的ajax技术实现的,相当于在页面不整体刷新的情况下,布局更新页面的内容,每一次滑到底部,就异步请求获取下一页的20个电影拼接到列表中去。
其实我们获取也比较简单,我们F12查看每次滑动的请求地址: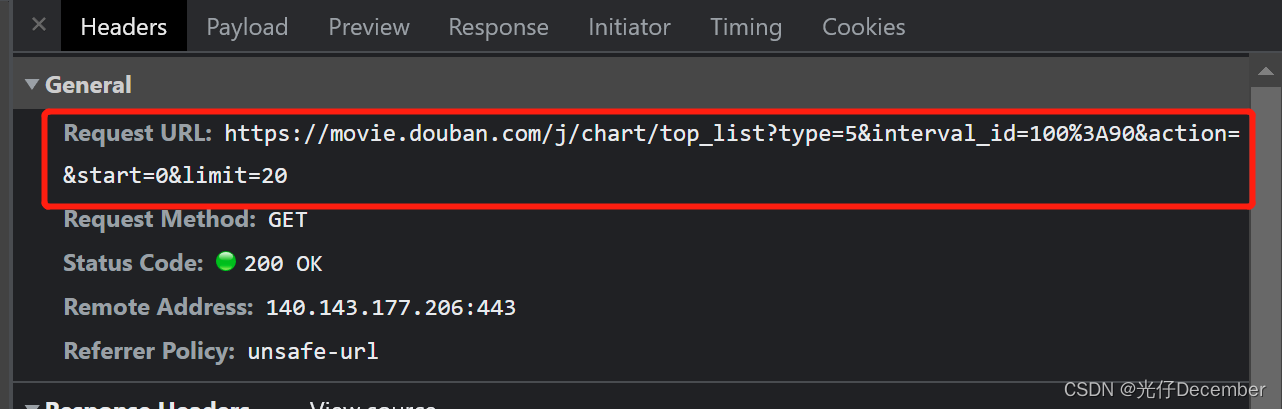
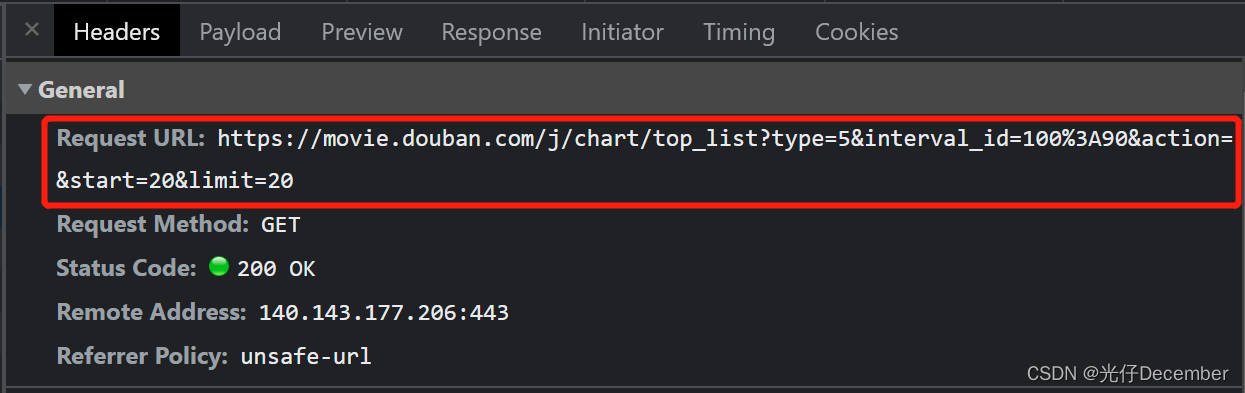
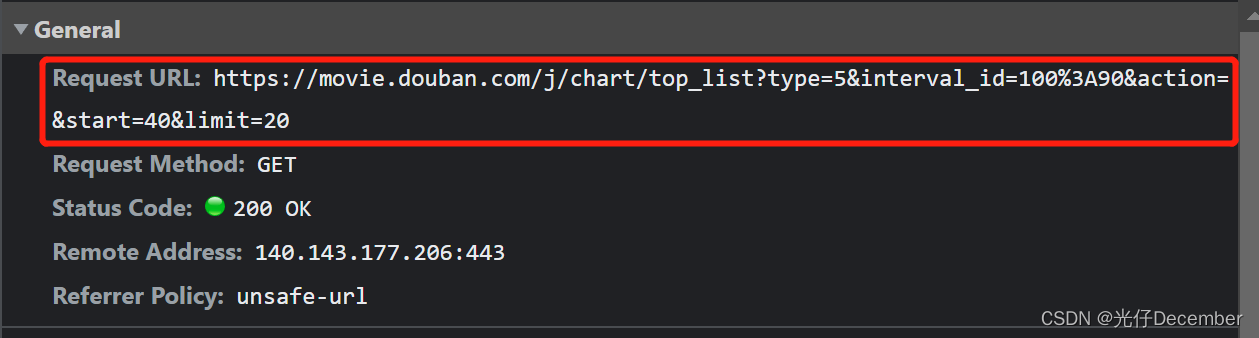
可以看到其他都没有变化,只是“start”和“limit”参数有变化,即是我们请求的页数是几页,该页加载几条(这里就是分别加载了第1页,第2页,第3页,每页获取20条电影数据),这就是比较主流的“分页”逻辑效果。
清楚了这个分页逻辑,我们就知道如何实现某某电影前N页的数据,例如前10页数据,那就每次改变start的值就可以,从0加载到40即可(每页20条不变)。假设我们要获取前三页数据,我们可以使用for循环重置请求的start参数,然后将每次获取的数据拼接到上次获取的数据上即可,完整代码:
# _*_ coding : utf-8 _*_
# @Time : 2023-06-17 18:14
# @Author : 光仔December
# @File : 抓取某某电影数据-分页实现
# @Project : Python_Projects
import urllib.request
import json
# 定义一个获取每页数据的方法
def get_movies_by_start(s_url, start, limit):
s_url = str(s_url) + '&start=' + str(start) + '&limit=' + str(limit)
print("s_url", s_url)
# 创建request请求对象
request = urllib.request.Request(url=s_url, headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的数据
result = response.read().decode('utf-8')
return result
# 某某电影排行服务的API地址,get请求的参数直接拼接在地址上
url = "https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action="
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.66 Safari/537.36',
'Cookie': 'll="118237"; bid=XC5KAjdVhr0; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1686994243%2C%22https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DdYERHe3ZepjqV24sOD9vz5FTFdU_VNfjjjJcv-wT7iKaTIkpeg3VXDZM4g-87dJO%26wd%3D%26eqid%3Dcdc028140007592b00000003648d7d48%22%5D; _pk_id.100001.4cf6=003d6c4f8c5a5918.1686994243.; _pk_ses.100001.4cf6=1; ap_v=0,6.0; __utma=30149280.1819017266.1686994243.1686994243.1686994243.1; __utmb=30149280.0.10.1686994243; __utmc=30149280; __utmz=30149280.1686994243.1.1.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utma=223695111.1834148081.1686994243.1686994243.1686994243.1; __utmb=223695111.0.10.1686994243; __utmc=223695111; __utmz=223695111.1686994243.1.1.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __yadk_uid=CNd55Pec33U7Y2fvSlRoIIPfHFHp2r6z; _vwo_uuid_v2=DD581C8DF7B5095A18828A5BEB7A2E02B|d387f0c02fd08058553b6ad87363290f; __gads=ID=abc089f235d209f0-22edbe9eaab400ed:T=1686994466:RT=1686994466:S=ALNI_Maj4OLb9xqctrwIkc4iumOK0U6MRw; __gpi=UID=00000c50aa502f07:T=1686994466:RT=1686994466:S=ALNI_MbWaQIC_DBfN6WNUac3i9Z6tLzQmA'
}
start = 0
limit = 20
content = [] # 获取的数据内容,拼接结果
max_page = 3 # 获取的最大页数
# 循环3页数据,并将结果拼接
for start in range(0, 3):
result = get_movies_by_start(url, start * limit, limit)
obj = json.loads(result)
# 合并json数组
content.extend(obj)
# 将结果写入json文件,因为里面有中文,所以要指定encoding编码格式
fp = open('douban2.json', 'w', encoding='utf-8')
content = json.dumps(content, ensure_ascii=False) # 将json对象转换为字符串,因为有中文,不用ascii编码
fp.write(content)这里我们首先定义了一个get_movies_by_start函数,可以加载任意页的某某电影排行榜数据,参数是url地址以及需要加载的页数和数据量。
拼接的话,就是每次请求时,将获取到的新json数组,加入到已经获取的json数组中去即可。
这里我们每次调用请求get_movies_by_start函数的时候,都会打印一次请求url,可以看到如同我们在页面请求的时候效果一样,每一次请求start会有变化:
数据效果: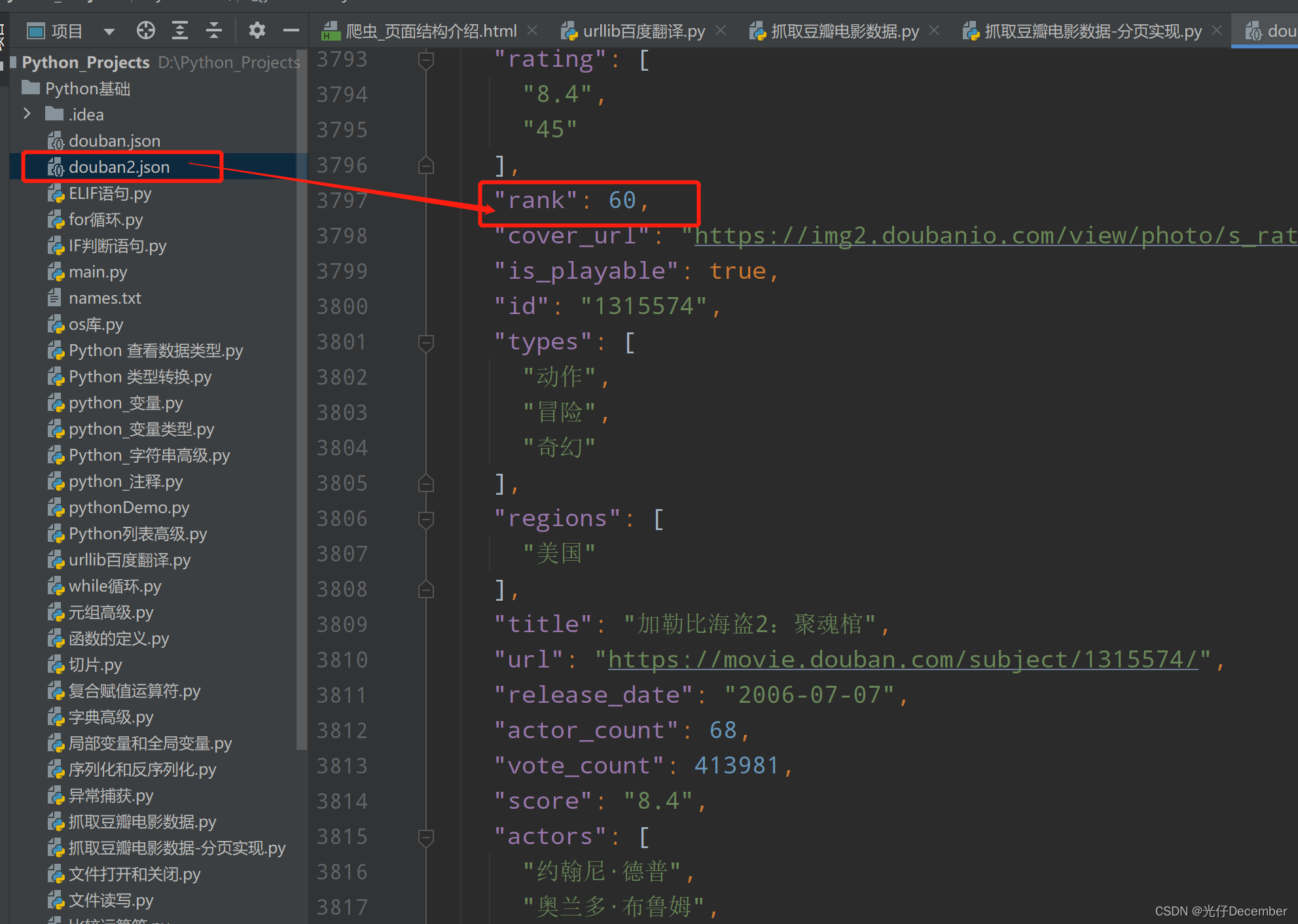
通过"rank"字段我们可以看到获取了排行前60条的数据,证明我们的数据获取是成功的。
至此,我们通过urllib成功获取到了某某电影网站的列表。
本次我们获取数据的形式是get类型请求,下一篇博文我们将学习通过post请求来获取肯德基官网的数据。
参考:尚硅谷Python爬虫教程小白零基础速通教学视频
转载请注明出处:https://blog.csdn.net/acmman/article/details/131263587