目录
前言:
1 进程和线程
2 线程库接口
2.1 线程库基础理解
2.2 创建线程
2.2 线程资源回收
2.3 线程分离
前言:
本篇主要是对Linux原装线程库的函数接口进行学习,还有一部分的线程概念补充。
1 进程和线程
博主在上一篇文章当中有讲过,进程是承担资源分配的载体,而线程是CPU调度的基本单位,并且所有的线程能够共享进程的数据。这没有什么问题,但是这难道不会有一点奇怪吗?
那就是如果所有的线程都能够共享地址空间的数据,那么这是不是就意味着多个线程同时进入一个函数,它们所看到的东西都是一样的?如果是一样的,这样有问题吗?如果不是一样的,OS又是如何识别是哪一个线程正在执行这个函数呢?
这个时候就需要引入一个线程私有属性的概念了:
线程 ID一组寄存器独立栈errno信号屏蔽字调度优先级
上面的这几个属性当中,最重要的就是独立栈还有寄存器了,另外需要了解的就是线程ID,其余的几个知道就行了。
为什么我说独立栈和寄存器是最重要的呢?因为明白线程有的这两个属性,才能真正明白线程切换还有线程运行时的行为特征,对于这部分博主会在讲解接口的时候为大家展开讲解的。
线程之间的共享属性:
文件描述符表每种信号的处理方式 (SIG_ IGN 、 SIG_ DFL 或者自定义的信号处理函数 )当前工作目录用户 id 和组 id
其实上面的共享属性博主虽然说是线程之间的,但是本质上其实是进程级别的属性,只是线程本身没有额外的添加,从而直接把进程当中的拿过来了。为什么不添加呢?原因很简单,这些属性有且只能有一份存在,多了会导致程序执行紊乱。我用信号处理方式为例,如果线程1对于野指针问题导致的段错误的处理方式是忽略操作,而线程2对于野指针异常信号是直接让程序退出,那么真正来了一个段错误信号之后,进程应该采用哪一种方式呢?所以这部分属性是必须保持一致的。
2 线程库接口
2.1 线程库基础理解
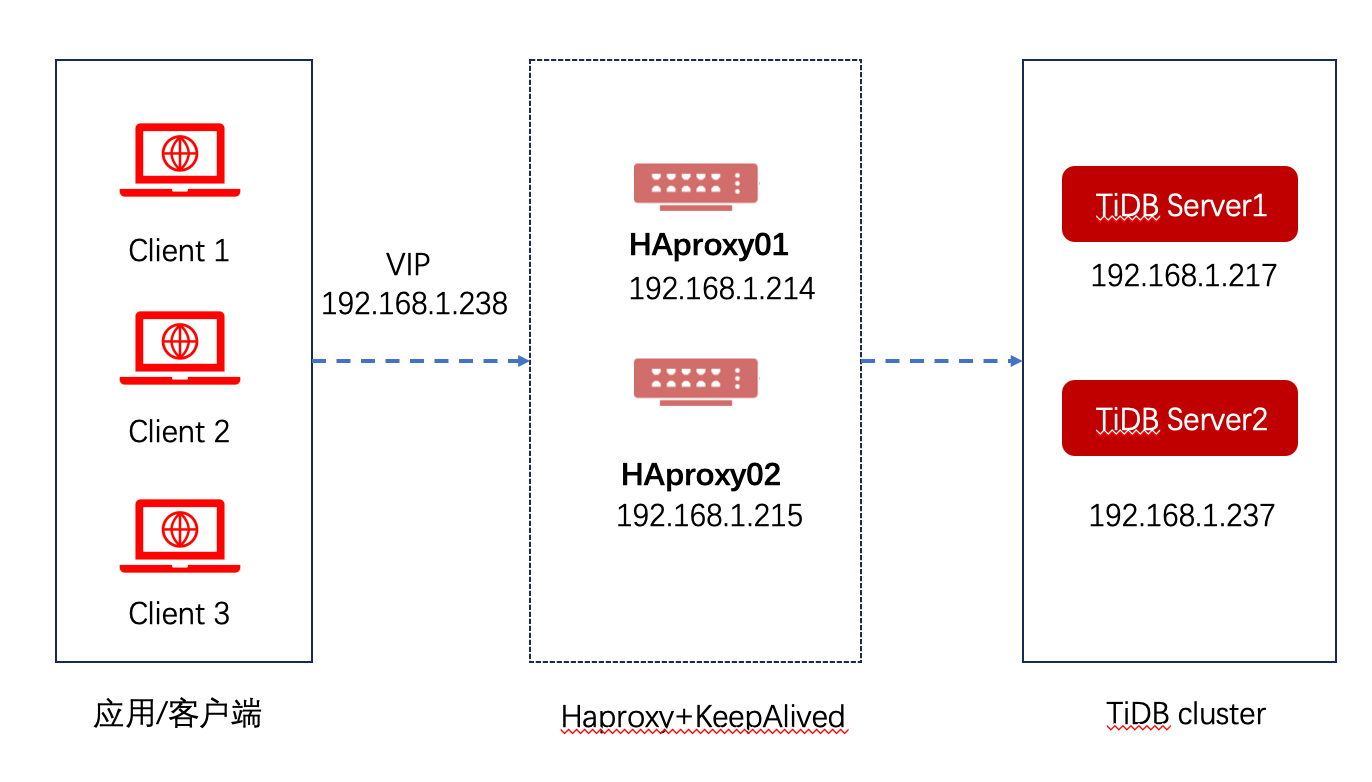
首先,博主在上一篇文章当中讲过,在Linux当中是没有真正的线程的,只有轻量级进程的概念,所以在Linux当中只有轻量级进程的接口,但是对于我们用户来说,我们是不认识什么轻量级进程的,我们只认线程,只要线程接口,但是Linux当中又没有,怎么办?只能是额外设计一个线程库用来封装轻量级进程的接口。因为有了这样一个库的存在,用户还是使用的线程的方法,而OS本质上还是使用的自己的那一套轻量级进程的管理方案。
如下图就是Linux为我们添加的动态线程库:
![]()
看到这个动态库,大家有没有想到一个东西呢?那就是在使用编译指令的时候需要在后面添加上一个-lpthread这样的一个后缀,否则OS就像是眼睛瞎了一样找不到,这一部分博主在动静态库连接的过程当中有讲过,博主也就不再赘述了。如下:
mythread:mythread.cc
g++ -o $@ $^ -std=c++11 -lpthread
.PHONY:clean
clean:
rm -f mythread
2.2 创建线程

创建线程的函数接口如上图,这个函数的第一个参数是输出型参数,用于创建线程之后为我们返回一个线程ID这个东西,第二个表示线程的私有属性结构,一般来说我们不用对它做修改,所以传参时,直接传入一个nullptr就行,第三个参数表示我们要给线程执行的任务,因为它本身就是一个函数指针,之后传入一个返回类型为void*,参数也为void*的函数指针即可。第四个参数是一个输入型参数,这个参数的类型为void*,这表示了之后执行传入的函数的参数就是它。如下为使用方式。
代码:
#include <iostream>
#include <pthread.h>
#include <unistd.h>
#include <string>
using namespace std;
void toHex(int tid)
{
printf("%x\n",tid);
}
void *running1(void *args)
{
// 对无类型的数据做类型转换
string data = static_cast<const char *>(args);
while (true)
{
// 输出“hello world”表示正确
cout << data << "线程ID ";
toHex(pthread_self());
sleep(1);
}
return nullptr;
}
int main()
{
pthread_t tid1;
const char *data = "hello world";
// 创建线程
int n = pthread_create(&tid1, nullptr, running1, (void *)data);
// 创建线程返回值不为0表示错误
if (n != 0)
{
cout << "create thread fail" << endl;
}
while (1)
{
cout << "I am main thread" << " ";
toHex(pthread_self());
sleep(1);
}
return 0;
}输出:

如上代码可以看到,我们生成了线程,因为分别执行了两个死循环,所以证明了我们的线程已经生成了成功,并且,通过我们的线程执行函数里面,收到了主线程传递的参数,也可以证明我们的参数传递也是正确的。
当然我这里只是简单的传入了一个字符串,其实最重要的是,这个参数使用无类型接收的参数,所以它可以传入任意的一个值都是没有问题的,什么意思呢?也就是说,我们的这个参数可以传递任意的类,结构体,这才是真正有意义的。
线程ID和LWP:
大家看到了上面的输出结果,为什么会有线程ID和LWP两种不同的东西来表示我们的线程啊?这样做感觉好奇怪,有什么实际的意义吗?
其实这样做确实是有它自己的意义的,首先,LWP所对应的值是什么?轻量级进程,这个是用来给操作系统看的,但是线程ID呢?这一点我们就不能简单的理解它了,我问一个问题,我们的线程被创建出来之后,他需要管理吗?需要被组织吗?当然需要,但是这是由谁来做的呢?难道是操作系统吗?
事实上操作系统确实是做了一部分的管理和组织的功能,但是还有一部分内容是OS所不方便代为执行的,我们的线程栈还有线程局部存储,原因如下:
方便快捷:线程 ID 是一个整数类型的变量,易于在程序中进行传递和管理。
动态性:线程 ID 在创建线程时动态分配,并且可以重复使用,因此能够很好地适应不同场景下的线程管理需求。
安全性:使用线程 ID 能够保证每个线程的资源可以被独立地管理,从而避免多个线程之间产生冲突和竞争等问题。
为什么这么说呢?还记得我们的线程库是怎么来的吗?通过封装LWP接口来的,所以按照实现的角度来说,是可以通过LWP来实现的,但是我们不这么做就是为了保证线程栈的独立性。
看到我们输出图的线程ID转为16进制之后的值了吗?它是什么?它是一个地址,表示线程栈的首地址,因为这个地址是不相同的,所以每一次CPU执行有相同函数的线程的时候是不会出现紊乱的操作的,这样讲大伙估计有一些疑问,那么请看下图:
#include <iostream>
#include <pthread.h>
#include <unistd.h>
#include <string>
using namespace std;
void toHex(int tid)
{
printf("%x\n",tid);
}
void *running1(void *args)
{
// 对无类型的数据做类型转换
//string data = static_cast<const char *>(args);
int num = 100;
while (true)
{
// 输出“hello world”表示正确
//cout << data << "线程ID ";
//oHex(pthread_self());
cout << num << " " << &num << endl;
sleep(1);
}
return nullptr;
}
int main()
{
pthread_t tid1,tid2;
//const char *data = "hello world";
// 创建线程
int n = pthread_create(&tid1, nullptr, running1, nullptr);
int y = pthread_create(&tid2, nullptr, running1, nullptr);
// 创建线程返回值不为0表示错误
if (n != 0 || y != 0)
{
cout << "create thread fail" << endl;
}
while (1)
{
// cout << "I am main thread" << " ";
// toHex(pthread_self());
sleep(1);
}
return 0;
}
我们看到上面的代码,如果说不同的线程进入了相同的函数之后,看到的是同一份资源,那么这个资源的地址按照道理来说应该是相同的,但是事实是这样吗?并不是,也不应该是一样的,否则我们的程序不就直接乱套了嘛。
其实我们可以想象到操作系统是如何做的,我们的地址计算方式其实很简单,线程不是带有寄存器的数据嘛,那么一定有对应的寄存器是用来表示我们的线程独立栈的起始位置,和结束位置,然后通过起始地址偏移,就能找到所有变量在不同线程当中地址位置了。
2.2 线程资源回收
大家有没有注意到,前面博主故意在回避线程执行完毕的返回值?并且我们的主线程创建完成线程之后还需要加一个死循环防止线程退出,这样的方式确实是有一点点挫了,所以这个时候就有了另外一个线程接口了:

这个函数接口表示在主线程只有等待线程执行完毕之后才能继续相同运行,第一个参数就是我们的线程ID,用来识别是哪一个线程退出了,第二个参数就涉及到了我们的线程执行完毕之后的返回值了,因为线程的返回值是一个void*类型,如果我们直接传递void*类型去接收,那么必然会出现形参接收值得情况,这是我们不希望看到的,所以只能通过二级指针的方式接收。
#include <iostream>
#include <pthread.h>
#include <unistd.h>
#include <string>
using namespace std;
void toHex(int tid)
{
printf("%x\n",tid);
}
typedef struct point
{
int x;
int y;
}point;
void *running1(void *args)
{
int n = 10;
while (n--)
{
cout << n << endl;
sleep(1);
}
point* ret = new point;
ret->x = 2;
ret->y = 1;
return (void*)ret;
}
int main()
{
pthread_t tid1;
// 创建线程
int n = pthread_create(&tid1, nullptr, running1, nullptr);
// 创建线程返回值不为0表示错误
if (n != 0)
{
cout << "create thread fail" << endl;
}
point* ret = nullptr;
pthread_join(tid1, (void**)&ret);
cout << ret->x << ' ' << ret->y << endl;
return 0;
}
如上图可以看出,返回值可以是一个结构体,返回之后可以在主线程当中被使用,有意思波。并且大家有没有想过不使用return返回,而是通过exit退出会怎么样呢?很简单,整个进程直接退出了,这个是进程退出的函数啊伙伴们,虽然我们不能使用exit但是我们可以使用另外一个函数:

这个函数的使用方式和return相同,博主也不想多讲,相信大家也是能明白的。
2.3 线程分离
基于上面的线程退出资源等待,我们有一个问题,那就是我的主线程并不关心你的退出资源,我主线程也有自己的事情要做,但是你却强制要我等你,这不是很烦的一件事情嘛,所以基于这个需求,线程还有一个接口用来分离线程:

使用了这个函数之后,线程会与主线程分离,并且在此之后,主线程甚至不能去等待它了,等待就会出错,就像是我们分手了之后还是别去找对方比较好,省的还被骂一顿。
pthread_detach(tid1);
pthread_join(tid1, (void**)&ret);
如上代码,我在join之前最线程进行分离,运行会出现什么问题?

看吧,会出现问题的,等待函数直接不起作用了,所以记住线程分离之后是不能在等待的。
直接退出的原因是由于等待函数不起作用了,并且主线程并没有需要执行的内容,进程直接退出,资源被释放了。
以上就是博主对这一部分知识的群不理解了,希望能够帮助到大家。 这里博主抛出一个问题,那就是多线程同时对一个全局变量进行修改是否会出现什么问题呢?



![[Spring Cloud]:Study Notes·壹](https://img-blog.csdnimg.cn/522591a137d5424188ad8f9c6707fcb7.png)