一、简介
2021-4-25 11:04:16
数据仓库分层是数据仓库设计中非常重要的一个环节,一个好的分层设计可以极大地简化数据仓库的操作,提升使用体验。然需要注意的是,分层理论并不绝对,只是提供一种普适的指导思想和原则,最重要的还是要看业务的具体需要。
为什么要做数据分层?
作为数据分析人员,我们自然希望自己的数据体系分层清晰、有序,容易调用和维护,对设计者和使用者来说,都赏心悦目,比如说下图这种:
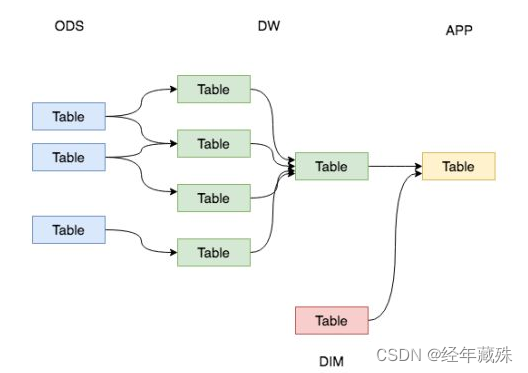
层次清晰,且表之间的依赖关系明确,使用者极易接受。
但实际上,大多数情况下,我们所使用的数据体系可能是层级混乱,且依赖关系复杂,循环依赖,跨层依赖多,冗余严重的情况,如下图:
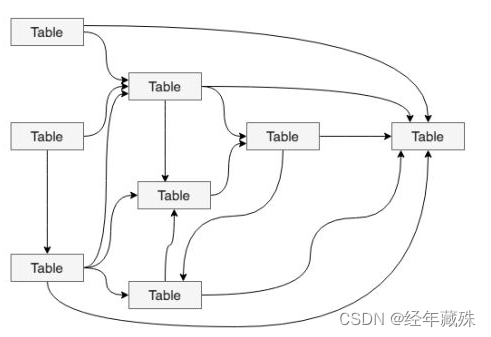
所以我们需要一种有效的数据组织与管理的体系,来使得我们的数据更为有效,调用更加高效,这一体系,或者说这套规范,就是数据分层。
当然,数据分层并不能解决所有的数据问题,但是它的存在可以给你带来很多好处,比如说:
- 清晰展示数据结构:每个数据层都有它的作用域和职责,在使用表的时候可以据此更加方便的定位、理解表的职能;
- 减少重复的开发:规范数据分层,开发一些通用的中间层数据,能够减少大量的重复计算;
- 统一数据口径:通过分层,提供统一的数据出口,从而统一对外输出的数据口径;
- 复杂问题简单化:将一个复杂的任务分解成多个步骤来完成,每一层解决特定的问题。
二、初级分层
目前,比较通用的数据分层体系,是把数据分为3层:
- ODS层,即数据运营层,存放的是接入数据仓库的贴源数据;
- DW层,即数据仓库层,这里存放的是我们需要重点设计的数据仓库中间层数据;
- APP层(ADS),即数据应用层,这里存放的是面向业务制定的应用数据。(
如报表数据)
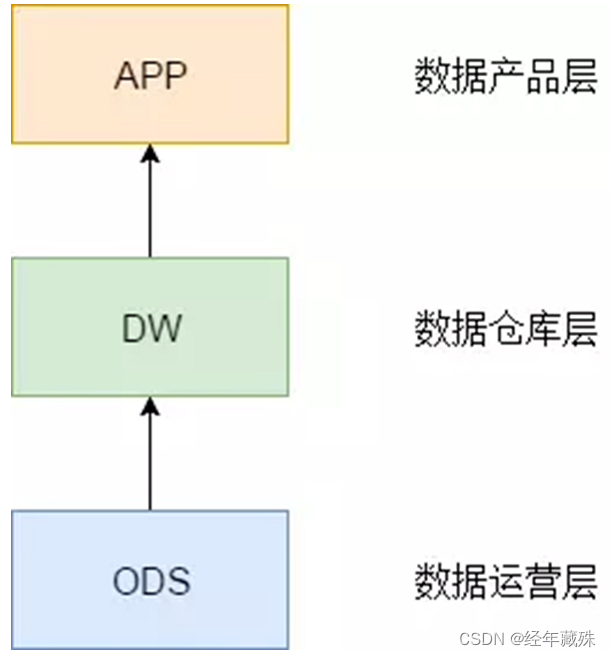
下面详细介绍一下这三大层。
2.1 ODS层
ODS层,全称是Operational Data Store,直译做“可操作数据存储”。是面向主题的,最接近数据源的层,也称贴源层。
数据源中的数据,经过抽取、转换后装载进ODS层,就是ETL三板斧操作。
ODS层的数据,总体上是按照业务系统的分类原封不动的转移进来的。
一般来讲,考虑到后续的数据回溯问题,不会在ODS层做过多的数据清洗工作,该层的本质是“原封不动传入”,至于异常值处理、降噪、去重等数据清洗工作,是后面的DW层来做的。
事实上,也不能简单的将ODS层看成是业务系统数据源的一个简单备份,二者还是有些区别的,比如说ods层一般是放在大数据分布式系统中,而业务系统DB基本是放在关系型数据库中。
ODS层在数据同步时一般是通过数据库直连抽取或者数据库日志抽取。
关于ODS物理表的表命名规范,尽量跟业务系统保持一致,可以添加额外的标识来区分增量表和全量表,比如说加入"_delta"来标识该表为增量表。
增量表:以天为分区,每个分区存放当日的新增数据;
全量表:以天为分区,每个分区存放截止到当日的全量快照数据。
2.2 DW层
DW层,全称是Data Warehouse,直译就是数据仓库。
这是我们做数据仓库的核心一层,精华所在。在这里,会将ODS层的数据按照各种主题进行聚合,从而建立不同的数据分析模型。
DW层根据功能又可以细化成3层:
- DWD层:即Data Warehouse Detail,直译“数据仓库明细层”;
- DWM层:即Data Warehouse Middle,直译“数据仓库中间层”;
- DWS层:即Data Warehouse Service,直译“数据仓库服务层”
2.2.1 DWD层
个人感觉是DW中相对最重要的一层,
DWD层一般保持着跟ODS层一样的数据粒度,是在ODS层的基础上做了更多的质量优化和精度保证等,个人感觉可以认为是DW的基础。
另外,该层会采用一些维度退化的方法,将维表退化到事实表中,减少事实表和维表的关联。即可以将事实表中的某些重要属性字段做适当冗余,做适当的宽表化处理。
除此之外,DWD层也会做一部分的数据聚合工作,将相同主题的数据汇集到一张表中,提高数据的可用性。
个人感觉,层的主要职能较为清晰,但是细节上功能划分其实并没有那么严格,可定制性相对比较强,比如说DWD层也可以做聚合,并非是DWM层独有
DWD层存放的一般是明细事实表,明细事实表的设计有五个步骤:选择业务过程 -> 确定粒度 -> 选择维度 -> 确定事实(度量) -> 冗余维度。
2.2.2 DWM层
该层主要是在DWD层的基础上,对数据做轻度的聚合操作,生成一系列的中间表,提升公共指标的复用性,减少重复加工。
直观地讲,就是对通用的核心维度进行聚合操作,算出相应的统计指标。
在有的地方,该层也被称为是DWB(Data Warehouse Basis),即数据仓库基础层,做轻度汇总。
2.2.3 DWS层
也称为数据集市、宽表。
按照业务划分,如订单、用户等,生成字段比较多的宽表,用于提供后续的业务查询等。
一般来讲,该层的数据表会相对比较少,但是一张表会涵盖很多的业务内容,由于字段数比较多,所以会被称为“宽表”。
在实际计算中,如果直接从DWD或者ODS来计算宽表的统计指标,会存在计算量太大或者维度太少的问题,所以一般的做法是,在DWM层计算出多个窄的中间表,然后拼接成一张DWS的宽表。但是宽和窄的界限不宜界定,也可以去掉DWM层,只保留DWS层,把所有数据放在DWS层即可。
DWS层的功能,使用规范化语言来描述:
以分析的主题作为建模驱动,基于上层应用和产品的指标需求,构建公共粒度的汇总指标表。以宽表化作为手段,来构建各种统计指标,如形成日、周、月粒度的汇总明细。
如果存在7天和30天的事实,可以选择用两列来存放7天和30天的事实,但是需要在列名和字段上说明清楚。
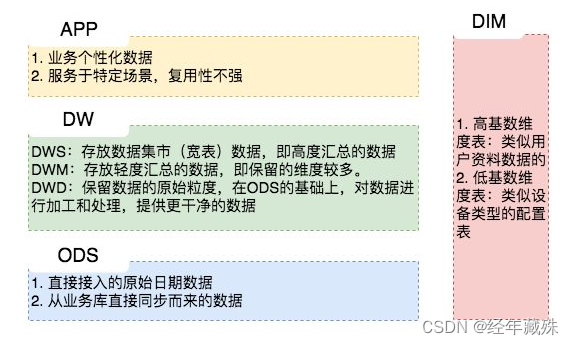
2.3 APP层
一般是提供给数据产品和数据分析使用的数据。比如我们常说的报表数据,一般放在这里。
有的参考文献里也称这一层是ADS层,全称是“ApplicationData Service”
2.4 维表层(DIM层)
建立一致性数据分析维表,方便进行交叉探查。
据参考文献2:
维表层分两种:
- 高基数维度数据:一般是用户资料表、商品资料表等类似资料表,数据量可能是千万级或者上亿级别;
- 低基数维度数据:配置表,如中文含义表、日期码表,数据量在个位数或几千几万不等。
三、简单分层示例
以下摘自参考文献2.
比如说用户访问日志这一数据的管理。

DWD层:整合数据来源,并做加工清洗;
DWM层:选取核心维度来做聚合,产生多个中间表;
DWS层:把每个主题的全部数据放在一张表中,产出各个业务主题的宽表。
APP层:从DWS层的一张或几张宽表中取出数据,拼接成一张应用表即可。
四、 各层的存储与计算
并不绝对,目前大数据发展日新月异,各种技术层出不穷,另外具体业务的需要,也不可能让这种东西固定下来。
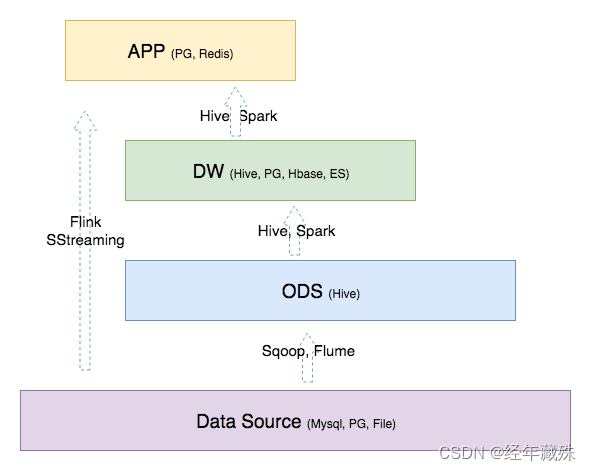
Data Source:一般是各种业务库和埋点库等,存储的话一般是用MySQL、PostgreSql之类的;
ODS层:ODS层的数据一般非常大,所以大多数时候会存在HDFS上,如HIVE和Hbase,HIVE居多;
DW层:这个的存储跟ODS一致,但为了降低处理难度,也会放在PG或者ES数据库中;
APP层:支持数据应用,如报表等,一般都要求尽量快的响应速度,所以会选择放在MySQL、PG、Redius等可实时的数据库中。
计算引擎的话,可以简单看看下面这种,仅为简单参考,毕竟要具体情况具体分析。
五、对数据分层的总结
从能力范围上来讲,我们希望80%的需求都由20%的表来支持。直接点讲,就是80%的需求,都可以用DWS层的表来支持就可以,剩下DWS支持不了的,就用DWM和DWD层的表来支持,这些再支持不了的话,就从ODS去捞原始日志。
从数据聚合程度来讲,我们希望,越往上的数据聚合程度越高,DWD是保持了原始粒度,基本不做聚合(维度退化不算),DWM做轻度聚合,DWS做更高的聚合。实际上这里对聚合的程度我还是摸不准,从这个角度来讲,我们可以理解成我们是以数据的聚合程度来划分数据层次的。
从对应用的支持上来看,越往上,对应用越友好,比如说APP层,实际上就是针对应用来设计的。
提几点需要注意的:
- 应用层不能直接调ODS;
- DWS应该优先调用DWD和DIM;
- 应该避免APP层过渡引用DWD层。
六、附录
宽表
顾名思义,宽表指字段特别多的数据表。一般是将业务主体相关的维度、指标等关联在一起得来。
特点:
- 大量内容放在同一张表,宽表本身已不符合第三范式的设计规范。
- 会造成大量数据冗余;
- 但是可以提高数据查询的性能。
DWD层,对ODS层做一些数据清洗和 规范化等操作,
DWS层,对ODS层或者DWD层做一些轻度的汇总
七、参考文献
- 数据仓库-通用的数据仓库分层方法
- 【漫谈数据仓库】 如何优雅地设计数据分层 ODS DW DM层级
- 数据仓库分层中的ODS、DWD、DWS
- 数据仓库分层设计
- 关于构建数据仓库的几个问题
![[Spring Cloud]:Study Notes·壹](https://img-blog.csdnimg.cn/522591a137d5424188ad8f9c6707fcb7.png)