文章目录
- 1. 题目描述
- 2. 项目细节分析
- 定时爬取任务思路
- 避免多次爬取数据重复问题
- 网站结构
- 根据爬取信息确认招标地区
- 3. 项目代码
- 4. 运行截图
1. 题目描述
中北大学信息安全技术爬虫课程设计
题目 5:招投标信息分析系统 (20050441 2005031113)
要求:文档内容至少包含系统结构、功能模块图、功能流程图、数据流图。实现语言不限。自动访问http://www.ccgp.gov.cn/获取信息
子题目 1:网络爬虫获取招标信息 要求:获取数据数量大于 2 万条,自定义多媒体格式(包括图片、声音、pdf 文件)保存在数据库中。关键字用例可自定义。统计下载数据,过滤数据。能显示、查找数据信息。每 24 小时采集一次。
子题目 2:网络爬虫获取中标信息 要求:获取数据数量大于 2 万条,自定义多媒体格式(包括图片、声音、pdf 文件)保存在数据库中。关键字用例可自定义。统计下载数据,过滤数据。能显示、查找数据信息。每 24 小时采集一次。
子题目 3:针对某一地区发出的招标信息进行分析,对该地区可实现画像,自动分析出该地区的招标特点及经济发展水平
子题目 4:对获取到的 pdf 文件进行解码,数据保存入数据库中,在数据库中增删改查。可多条件查询。
这份源代码实现的是子题目 1 和子题目 3
2. 项目细节分析
此项目中的路径均是绝对路径,需要根据实际项目位置修改。 修改完路径后点击 autoSpider 即可运行
定时爬取任务思路
24小时爬取功能实现
使用Windows系统自带的任务计划程序来实现定时执行Python程序的功能。具体操作步骤如下:
打开“任务计划程序”,可以在Windows搜索栏中输入“任务计划程序”来打开。
在左侧面板中找到“任务计划程序库”,右键点击并选择“创建任务”。
在弹出的对话框中,输入任务名称并勾选“使用最高权限运行”。
切换到“触发器”选项卡,点击“新建”,设置触发器的具体时间和频率,如每天、每周、每月等。
切换到“操作”选项卡,点击“新建”,在“程序或脚本”一栏中输入bat文件路径
点击“确定”保存设置,任务计划程序会自动执行Python程序,可以在“历史记录”中查看执行情况。
避免多次爬取数据重复问题
为了避免爬取到重复信息,这里再项目中创建了log.txt文件用来记录爬虫爬取的最新状态,如果今日的爬虫爬取到日志信息状态时,说明已经把最新的信息爬取完毕,直接退出爬虫并且更新信息即可
所以可以分析出,这个项目如果这样设计的话是不支持多线程的

网站结构
公开招标网站信息比较简单,可以直接通过GET方法获取。
我使用BS4进行解析,因为不同地方的招标信息细节结构可能不一样,但是都是存在同一个div标签下
根据爬取信息确认招标地区
这里选择优先级不同的方式统计,扫描爬取到的信息,按照优先级统计地区出现的次数,最后根据次数最多的城市的省份划分区域
这个项目使用了一个比较大的字典保存信息
3. 项目代码
由于代码比较多,这里只展示部分,完整项目Github上
from lxml import etree
from Spider.Seleium.msg_xpath import dialog
from Spider.Seleium.tool import unit_tool
from Spider.Seleium.tool import save
import openpyxl as op
# 多线程爬虫
from queue import Queue
def setup():
# 打开保存文件
wb = op.load_workbook('C:\\Users\\30309\\Desktop\\GovSpider\\Spider\\Seleium\\data.xlsx')
# print(wb.get_named_ranges()) # 输出工作页索引范围
# print(wb.get_sheet_names()) # 输出所有工作页的名称
# 取第一张表
# ws = wb.get_sheet_names()
# table = wb.get_sheet_by_name(ws[0])
table = wb.active
# print(table.title) # 输出表名
nrows = table.max_row # 获得行数
ncol = table.max_column # 获得行数
print(nrows, ncol)
# 读取配置文件
head, endLine = save.readLog()
# 从配置文件中获取是否添加头部信息
have_head = False
if head.find('True') != -1:
have_head = True
dialog_flag = False
prevLine = []
end = False
# 爬取第1到第25页数据
for page in range(1, 25):
root = f'http://www.ccgp.gov.cn/cggg/zygg/gkzb/index_{page}.htm'
html = etree.HTML(unit_tool.get_html(root))
paths = html.xpath(dialog.href)
for path in paths:
print(dialog.page_root + path)
page_msg = unit_tool.get_html(dialog.page_root + path)
list_bs4 = unit_tool.bs4Msg(page_msg)
if len(list_bs4) == 0:
continue
bs4 = list_bs4[0]
msg = unit_tool.bs4ToStr(bs4.select('td'))
have_file = unit_tool.haveFile(msg)
head, val = unit_tool.splitList(msg)
unit_tool.findCity(val)
if have_file:
file_id = unit_tool.getFile(bs4)
unit_tool.insertFile(file_id, val)
# print(file_id)
for sub_url in file_id:
file_url = dialog.download_root + sub_url
# print(file_url)
if not have_head:
# 所有文件写入头,头只写一次
save.InsertExcel(table, head, nrows)
nrows += 1
have_head = True
# 写入数据
if endLine.find(str(val)) != -1:
end = True
break
if not dialog_flag:
prevLine = val
dialog_flag = True
save.InsertExcel(table, val, nrows)
nrows += 1
if end:
prevLine = ':'.join(endLine.split(':')[1:])
print("Dialog: 今日数据爬取完毕")
break
# print("DEBUG获取完成")
# 写入配置文件
save.writeLog(have_head, prevLine)
wb.save('data.xlsx')
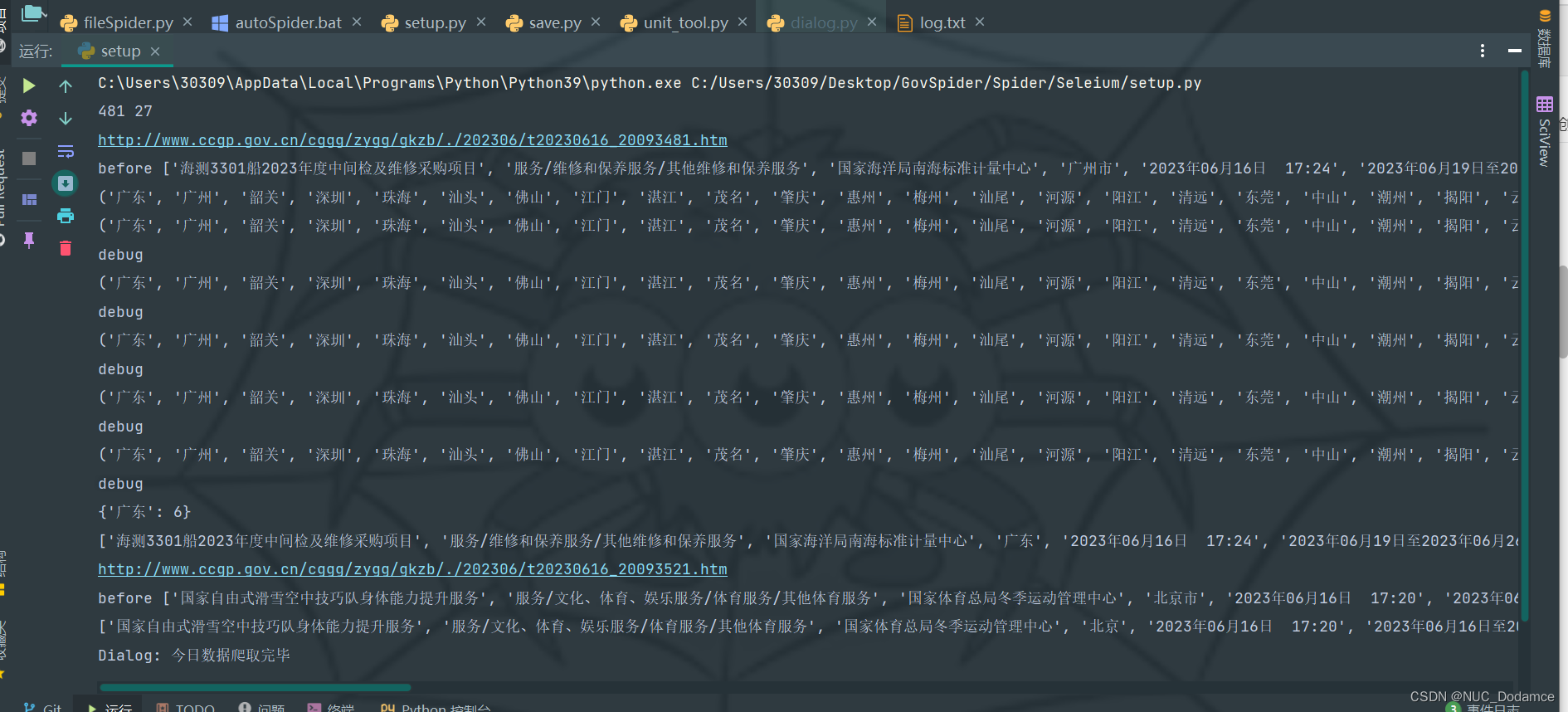
4. 运行截图



![[Spring Cloud]:Study Notes·壹](https://img-blog.csdnimg.cn/522591a137d5424188ad8f9c6707fcb7.png)