目录
1、神经网络表示
2、计算神经网络的输出
3、多个样本的向量化
4、激活函数
5、激活函数的导数
6、神经网络的梯度下降法
1、神经网络表示
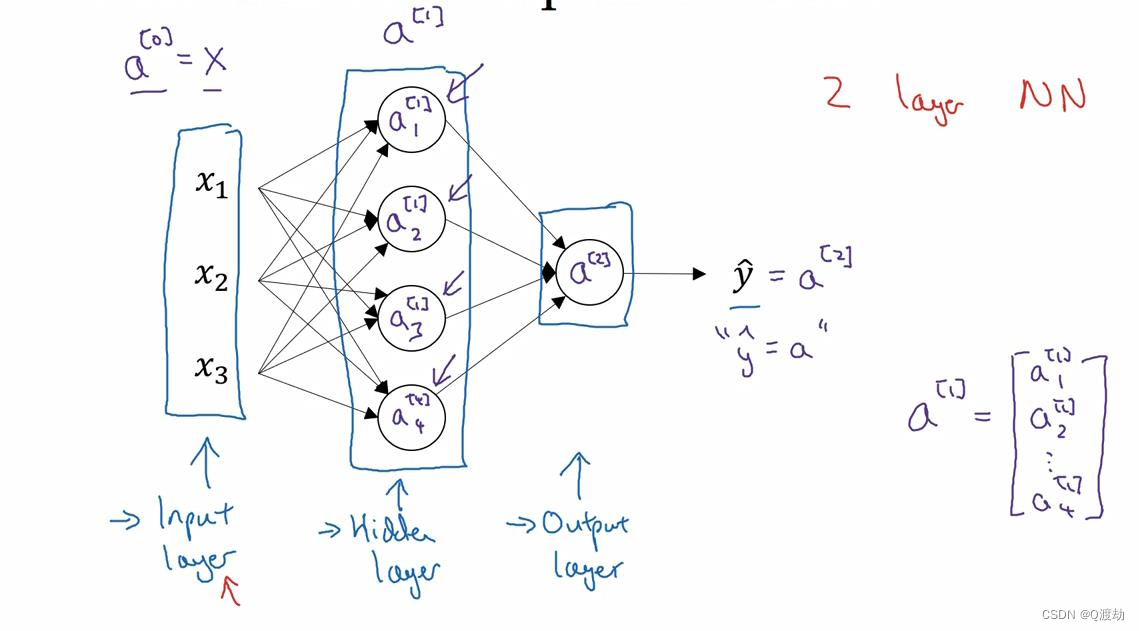
- 输入层:有输入特征𝑥1、𝑥2、𝑥3
- 隐藏层:四个结点,表示你无法在训练集中看到他们,使用了sigmoid 激活函数
-
输出层:它负责产生预测值,使用了sigmoid 激活函数
- 符号惯例:其中,𝑥表示输入特征,𝑎表示每个神经元的输出,𝑊表示特征的权重,上标表示神经网络的层数(隐藏层为 1),下标表示该层的第几个神经元
- 注意 :计算网络的层数时,输入层是不算入总层数内,所以隐藏层是第一层,输出层是第二层。第二个惯例是我们将输入层称为第零层,所以在技术上,这仍然是一个三层的神经网络,因为这里有输入层、隐藏层,还有输出层。但是在传统的符号使用中,阅读研究论文中,人们将这个神经网络称为一个两层的神经网络,不将输入层看作一个标准的
2、计算神经网络的输出

- 小圆圈代表了计算的两个步骤。
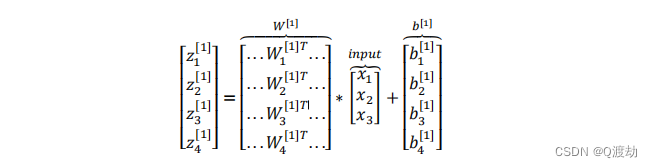
- 第一步,计算𝑧1 [1] , 𝑧1 [1] = 𝑤1 [1]𝑇 𝑥 + 𝑏1 [1]。
- 第二步,通过激活函数计算𝑎1 [1] , 𝑎1 [1] = 𝜎(𝑧1 [1] )。
- 隐藏层的第二个以及后面两个神经元的计算过程一样,只是注意符号表示不同,最终分别得到𝑎2[1]、𝑎3[1]、𝑎4 [1]
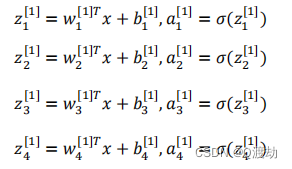
- 向量化计算:如果你执行神经网络的程序,用 for 循环来做这些看起来真的很低效
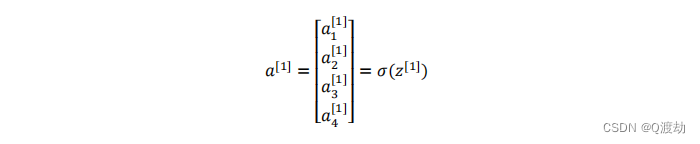
-
对于神经网络的第一层,给予一个输入 𝑥 ,得到 𝑎 [1] , 𝑥 可以表示为 𝑎 [0] 。通过相似的衍生你会发现,后一层的表示同样可以写成类似的形式,得到 𝑎 [2],𝑦^ = 𝑎 [2](隐藏层和输出层都使用了sigmoid 激活函数)。具体过程见公式
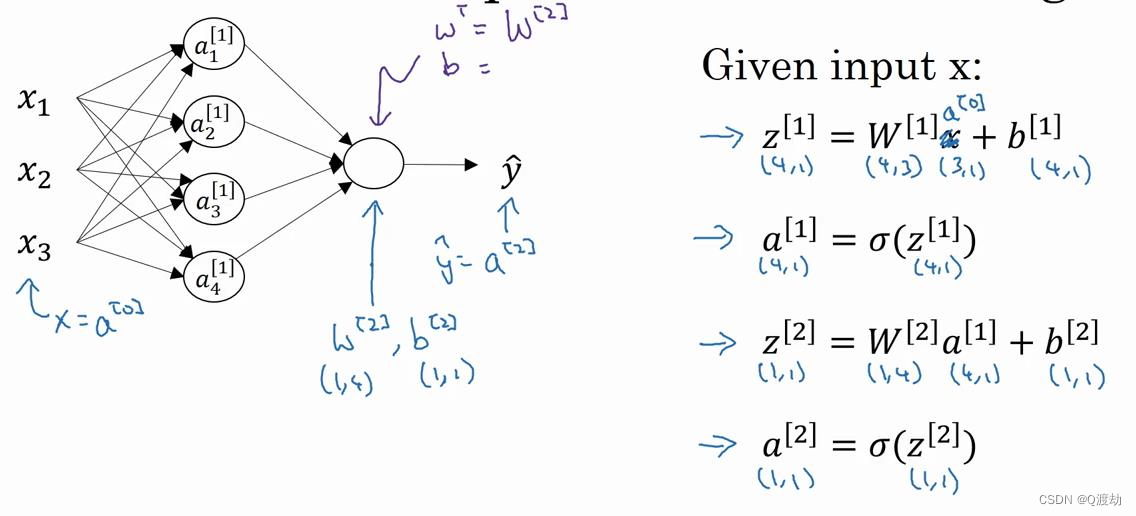
- 如上图左半部分所示为神经网络,把网络左边部分盖住先忽略,那么最后的输出单元就
相当于一个逻辑回归的计算单元。当你有一个包含一层隐藏层的神经网络,你需要去实现以计算得到输出的是右边的四个等式,并且可以看成是一个向量化的计算过程,计算出隐藏层的四个逻辑回归单元和整个隐藏层的输出结果,如果编程实现需要的也只是这四行代码。
3、多个样本的向量化
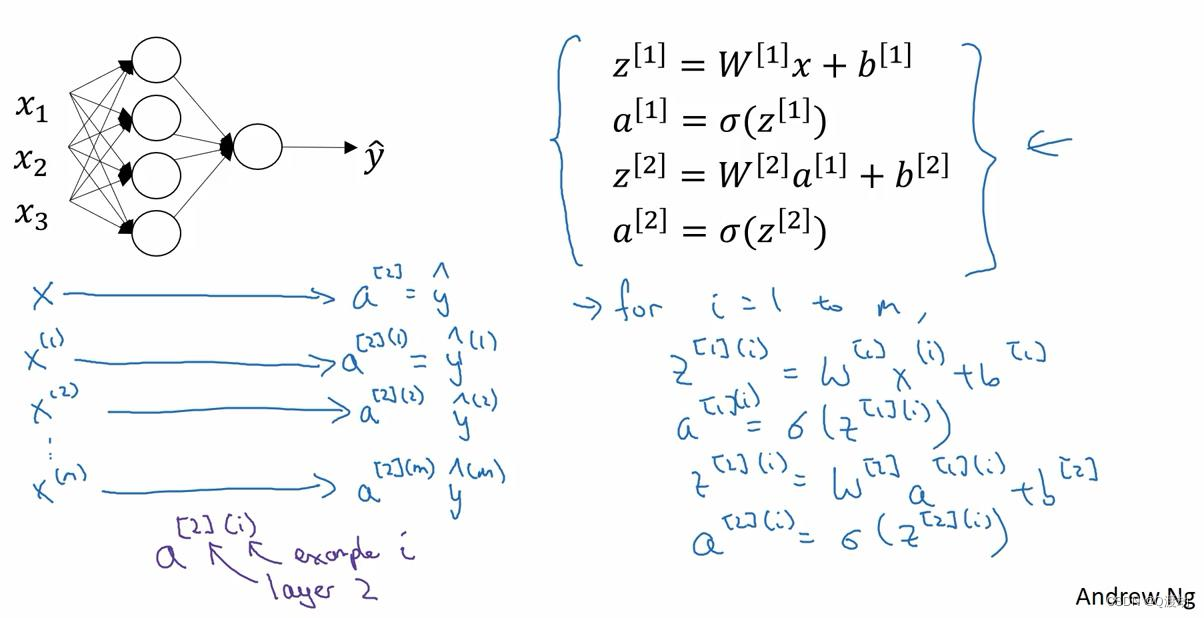
- 𝑎 [2](𝑖),(𝑖)是指第𝑖个训练样本而[2]是指第二层
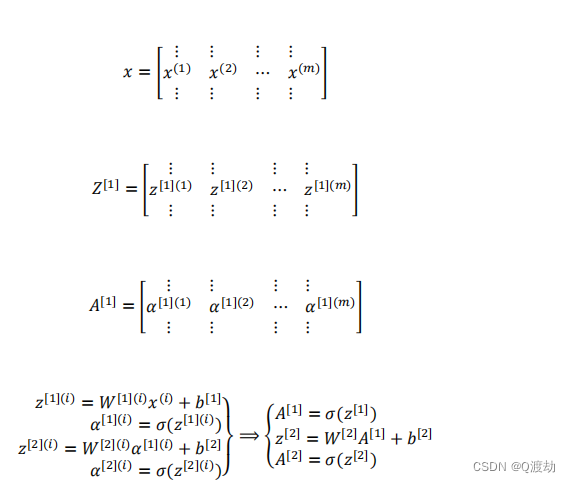
- 证明:𝑊[1] 是一个矩阵,𝑥(1) , 𝑥 (2) , 𝑥 (3)都是列向量,矩阵乘以列向量得到列向量,下面
将它们用图形直观的表示出来
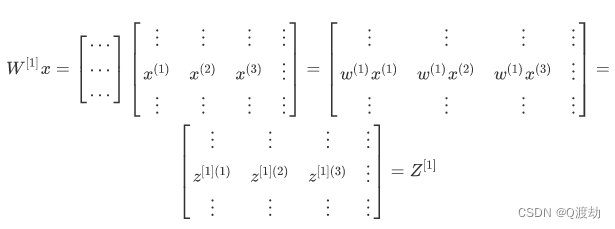
- 所以从图中可以看出,当加入更多样本时,只需向矩阵𝑋中加入更多列
4、激活函数
- 在前面的神经网路的前向传播中,𝑎 [1] = 𝜎(𝑧 [1] )和𝑎 [2] = 𝜎(𝑧 [2] )这两步会使用到 sigmoid 函数。 sigmoid 函数在这里被称为激活函数,但是,有时其他的激活函数效果会更好
![]()
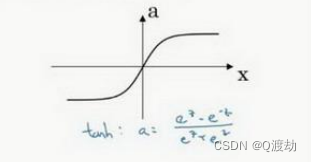
- 𝑔(𝑧 [1] ) = 𝑡𝑎𝑛ℎ(𝑧 [1] ) 效果总是优于 sigmoid 函数。因为函数值域在-1 和+1 的激活函数,其均值是更接近零均值的。在训练一个算法模型时,如果使用 tanh 函数代替 sigmoid 函数中心化数据,使得数据的平均值更接近 0 而不是 0.5
- 但有一个例外:在二分类的问题中,对于输出层,因为𝑦的值是 0 或 1,所以想让𝑦^的数值介于 0 和 1 之间,而不是在-1 和+1 之间。所以需要使用 sigmoid 激活函数
-
对隐藏层使用 tanh 激活函数,输出层使用 sigmoid 函数
- sigmoid 函数和 tanh 函数两者共同的缺点是,在𝑧特别大或者特别小的情况下,导数的梯度或者函数的斜率会变得特别小,最后就会接近于 0,导致降低梯度下降的速度
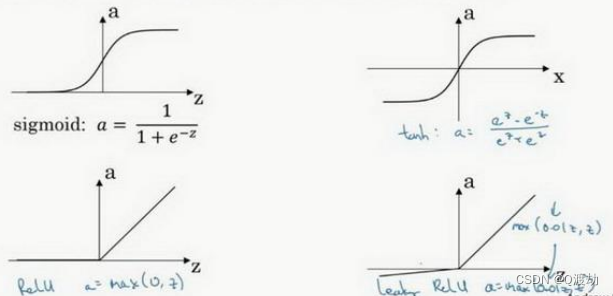
- 选择激活函数的经验法则:
如果输出是 0 、 1 值(二分类问题),则输出层选择 sigmoid 函数,然后其它的所有单元都选择 Relu 函数。这是很多激活函数的默认选择,如果在隐藏层上不确定使用哪个激活函数,那么通常会使用 Relu 激活函数。有时,也会使用 tanh 激活函数,但 Relu 的一个优点是:当 𝑧 是负值的时候,导数等于 0 。这里也有另一个版本的 Relu 被称为 Leaky Relu 。当 𝑧 是负值时,这个函数的值不是等于 0 ,而是轻微的倾斜。尽管在实际中 Leaky ReLu 使用的并不多,但是这个函数通常比 Relu 激活函数效果要好
-
sigmoid 激活函数:除了输出层是一个二分类问题基本不会用它。tanh 激活函数: tanh 是非常优秀的,几乎适合所有场合。ReLu 激活函数:最常用的默认函数,,如果不确定用哪个激活函数,就使用 ReLu 或者Leaky ReLu
-
why:在神经网络中使用非线性激活函数的主要原因是,如果不使用非线性激活函数,多层神经网络就相当于单层线性模型,而无法捕捉复杂的非线性关系。因此,通过使用非线性激活函数,神经网络可以学习更加复杂和抽象的模式,从而提高其预测和分类能力。
-
此外,非线性激活函数还可以解决梯度消失的问题。在深层神经网络中,当使用线性激活函数时,每一层的输出都是前一层输出的线性组合,这种线性组合对梯度的贡献非常小,导致梯度在反向传播时逐渐消失。而非线性激活函数可以引入非线性变换,增加梯度的大小,从而避免梯度消失问题。 因此,使用非线性激活函数是神经网络能够充分发挥其优势的重要因素之一
- 因此,不能在隐藏层用线性激活函数,可以用 ReLU 或者 tanh 或者 leaky ReLU 或者其他的非线性激活函数,唯一可以用线性激活函数的通常就是输出层
5、激活函数的导数
-
在神经网络中使用反向传播的时候,你真的需要计算激活函数的斜率或者导数。针对以下四种激活,求其导数如下:
1
)
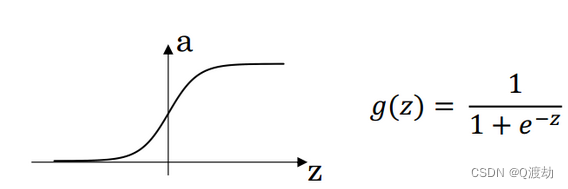
sigmoid activation function
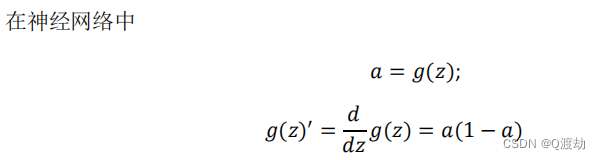
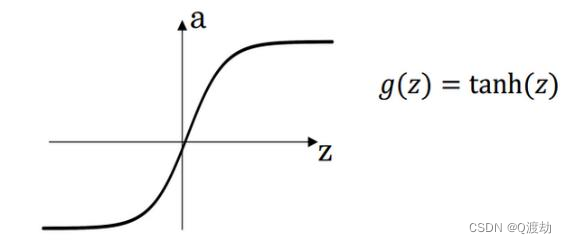
2) Tanh activation function

3)Rectified Linear Unit (ReLU)
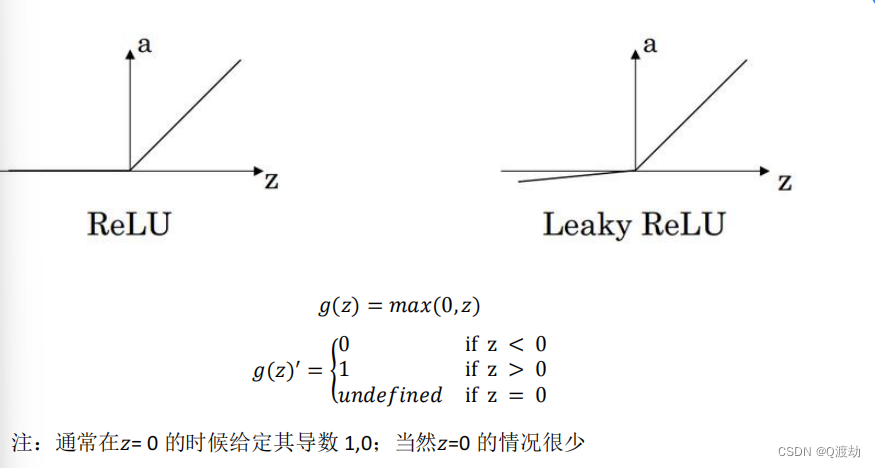
4)Leaky linear unit (Leaky ReLU)

6、神经网络的梯度下降法
-
单隐层神经网络会有𝑊[1], 𝑏 [1] , 𝑊 [2] , 𝑏 [2] 这些参数,还有个𝑛𝑥 表示输入特征的个数, 𝑛 [1] 表示隐藏单元个数, 𝑛 [2]表示输出单元个数。
-
矩阵 𝑊 [1] 的维度就是 (𝑛 [1] , 𝑛 [0]),𝑏 [1]就是𝑛 [1] 维向量,可以写成(𝑛 [1] , 1) ,就是一个的列向量。 矩阵 𝑊 [2] 的维度就是(𝑛 [2] , 𝑛 [1] ),𝑏 [2]的维度就是(𝑛 [2] , 1) 维度
- Cost function
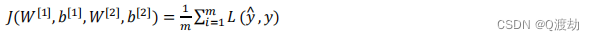
- 训练参数需要做梯度下降,在训练神经网络的时候,随机初始化参数很重要,而不是初
始化成全零。当你参数初始化成某些值后,每次梯度下降都会循环计算以下预测值:
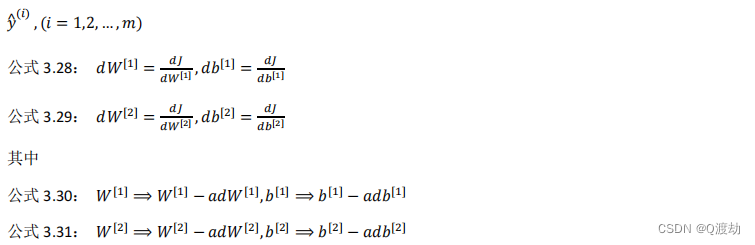
- 正向传播方程如下:

- 反向传播方程如下: 这些都是针对所有样本进行过向量化,𝑌是1 × 𝑚的矩阵;这里 np.sum 是 python 的 numpy 命令,axis=1 表示水平相加求和,keepdims 是防止python 输出那些古怪的秩数(𝑛, ),加上这个确保阵矩阵𝑑𝑏 [2]这个向量输出的维度为(𝑛, 1)这样标准的形式。

- 开始计算反向传播时,需要计算隐藏层函数的导数,输出在使用 sigmoid 函数进行二元分类。这里是进行逐个元素乘积,因为𝑊[2]𝑇𝑑𝑧 [2]和(𝑧 [1] )这两个都为(𝑛 [1] , 𝑚)矩阵