JVM
- 回收哪个区域?
- 关联面试题:fullgc会回收方法区(元空间)吗?
- 怎么判断对象可以被回收了
- 关联面试题:哪些对象可以作为 GC Root (两栈两方法)
- JVM GC什么时候执行?
- 分代回收机制
- 思考:假如eden区80m,老年代200m,一个对象90m?
- 各区域触发垃圾回收的类型与解释
- 新生代
- 新生代GC收集(类比倒水)
- 老年代(为什么老年代的回收耗时,比新生代更长呢)
- 跨代引用的问题
- 方法区
- 回收算法讲解
- 标记 - 清除算法
- 标记 - 复制算法
- 标记 - 整理算法
- 常用的垃圾回收器
- Serial/Serial Old
- ParNew( 负责收集新生代区域)
- Parallel Scavenge
- Parallel Old
- CMS
- CMS 负责收集老年代区域,它采用**标记-清除**算法。
- G1
- 运行步骤
- 三色标记(解决或降低用户线程的停顿)
- 原理流程
- 最终标记和重新标记解决了什么?
- 漏标
- 多标
- 读屏障、写屏障
- CMS通过写屏障卡表解决
- G1写屏障rset解决
回收哪个区域?
JVM GC只回收堆区和方法区内的基本类型数据和对象。
栈区的数据(仅指基本类型数据),在超出作用域后会自动出栈释放掉,所以其不在JVM GC的管理范围内。
关联面试题:fullgc会回收方法区(元空间)吗?
1.常量对象不再任何地方被引用的时候,这个常量可以被回收
2.无用类(堆中不存在该类的任何实例对象,加载该类的类加载器已经被回收,Class对象不在任何地方被引用)
怎么判断对象可以被回收了
对象不可达
GC Roots 作为起始节点,从这些节点开始,根据引用关系向下搜索,搜索过程的就是一条引用链,没有在这个链条上面的对象,也就是根节点通过引用链不可达到这个对象时,就认为这个对象是可以被回收的。
关联面试题:哪些对象可以作为 GC Root (两栈两方法)
- 虚拟机栈中引用的对象
- 本地方法栈中 JNI引用的对象
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
public class StaticObj {
public static Object obj = new Object();
//...
}
public class ConstObj {
public static final String STR = "hello";
//...
}
JVM GC什么时候执行?
- 老年代空间不足
- 方法区空间不足
- Eden区和s区不足
- 手动触发gc
分代回收机制
弱分代假说:绝大多数对象都是朝生夕死的。
强分代假说:熬过越多次的垃圾回收的对象,就越难消亡
思考:假如eden区80m,老年代200m,一个对象90m?
老年代的担保机制,如果一个对象大于设定的值那么直接丢到老年代中。
除此之外,当存活的对象超过Survivor空间大小时,这些存活的对象会忽略年龄,直接进入老年代里。
各区域触发垃圾回收的类型与解释
- Minor GC:只回收新生代区域。
- Major GC:只回收老年代区域。只有CMS实现了MajorGC,所以在老年代里,触发GC,除了CMS和G1之外的其他收集器,大多数触发的其实是 Full GC
- Full GC:回收整个堆区和方法区
- Mixed GC:回收整个新生代和部分老年代。G1收集器实现了这个类型。
新生代
默认情况下,新生代(Young generation)、老年代(Old generation)所占空间比例为 1 : 2 。
包含1个伊甸园空间(Eden), 2个幸存者空间(Fron Survivor、To Survivor)
Eden : Fron : To = 8 : 1 : 1
适合使用标记-复制算法
新生代GC收集(类比倒水)
新创建的对象,是保存在伊甸园空间的(Eden)。那些经历多次GC依然存活的对象会经由幸存者空间(Survivor)转存到老年代空间(Old generation)
老年代(为什么老年代的回收耗时,比新生代更长呢)
1、老年代内存占比更大,所以理论上回收的时间也更长
2、老年代使用的是标记-整理算法,清理完成内存后,还得把存活的对象重新排序整理成连续的空间,成本更高
跨代引用的问题
卡表(Card Table)
每一个卡页,可能会包含N个存在跨区域引用的对象,只要存在跨区域引用的对象,这个卡页就会被标识为1。当GC发生的时候,就不需要扫描整个区域了,只需要把这些被标识为1的卡页加入对应区域的 GC Roots 里一起扫描即可。
方法区
之前引用的面试题已经说明过,这边再重新说明一次
1.常量对象不再任何地方被引用的时候,这个常量可以被回收
2.无用类(堆中不存在该类的任何实例对象,加载该类的类加载器已经被回收,Class对象不在任何地方被引用)
回收算法讲解
标记 - 清除算法
标记出所有存活的对象,再扫描整个空间中未被标记的对象直接回收。
标记 - 复制算法
把内存分成两块大小相同的空间(1 : 1),每次只使用其中一块,当使用中的这块内存用完了,就把存活的对象移动到另一块内存中,再把使用过的这块内存空间一次性清理掉。(依照eden区、survivor区思考)
缺点:这个做法虽然效率极高,但也浪费了一半的内存空间。
标记 - 整理算法
和标记-清除算法一样,先标记,但清除之前,会先进行整理,把所有存活的对象往内存空间的左边移动,然后清理掉存活对象边界以外的内存,即完成了清除的操作。
常用的垃圾回收器
Serial/Serial Old
一个单线程工作的收集器。在进行垃圾回收的时候,需要暂停所有的用户线程,直到回收结束。
ParNew( 负责收集新生代区域)
ParNew 就是 在Serial 收集器的基础之上,实现了它的多线程版本。
Parallel Scavenge
和 ParNew 很相似,都是新生代的收集器,支持多线程并行回收,也同样是使用标记-复制来作为回收算法。
区别:实现一个可控制吞吐量的垃圾收集器。
Parallel Old
Parallel Old 是 Parallel Scavenge 的老年代版本
CMS
CMS 负责收集老年代区域,它采用标记-清除算法。
- 初始标记
STW,GC Root直接关联的对象 - 并发标记
并发标记从GC Roots直接关联的对象开始,遍历整个引用链,这个阶段耗时较长,但用户线程可以和GC线程一起并发执行。 - 重新标记
STW,重新标记就是修正用户线程继续运行,导致的变动的那一部分对象 - 并发清理
缺陷:
1.内存碎片。由于使用了 标记-清理 算法,回收结束后会产生大量不连续的内存空间,也就是内存碎片。
2.GC进行时会降低吞吐量。
3.浮动垃圾。CMS有两个阶段是可以用户线程和GC线程并发执行的,用户线程的继续执行自然会伴随垃圾的不断产生,这些就是浮动垃圾。这些垃圾只能等下次触发GC的时候才能清除了
G1
G1 收集器的设计理念是:实现一个停顿时间可控的低延迟垃圾收集器。
G1 依然遵循分代回收的设计理论,但它对堆(Java Heap)内存进行了重新布局,不再是简单的按照新生代、老年代分成两个固定大小的区域了,而是把堆区划分成很多个大小相同的区域(Region),新、老年代也不再固定在某个区域了,每一个Region都可以根据运行情况的需要,扮演Eden、Survivor、老年代区域、或者Humongous区域。
运行步骤
1.初始标记
只标记 GC Roots 能直接关联的对象
2.并发标记
从根节点(GC Root)开始,顺着引用链遍历整个堆,找出存活的对象。这个步骤耗时较长,但用户线程可以和GC线程并发执行。
3.最终标记
处理并发标记阶段,用户线程继续运行产生的引用变动,这个阶段需要暂停用户线程,支持并行处理。
4.筛选回收
计算出各个Region的回收价值和成本,再根据用户期望的停顿时间来决定要回收多少个Region。
回收使用的是复制算法,把需要回收的这些Region里存活的对象,复制到空闲的Region中,然后清理掉旧Region全部空间。
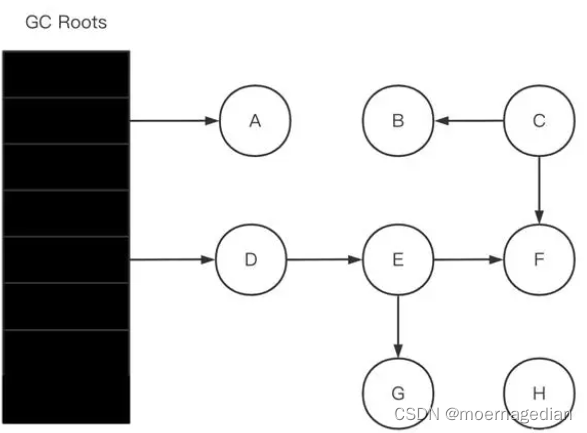
三色标记(解决或降低用户线程的停顿)
原理流程
初始标记
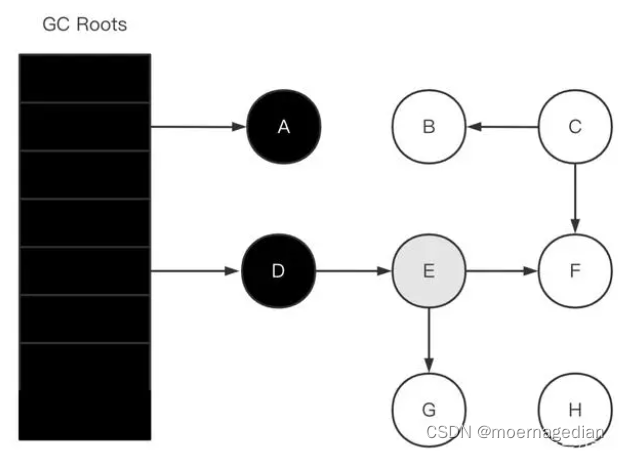
并发标记
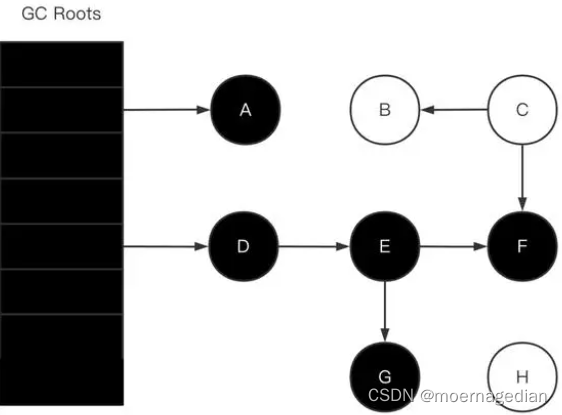
此时黑色对象就是存活的对象,白色对象就是已消亡可回收的对象。
最终标记和重新标记解决了什么?
漏标
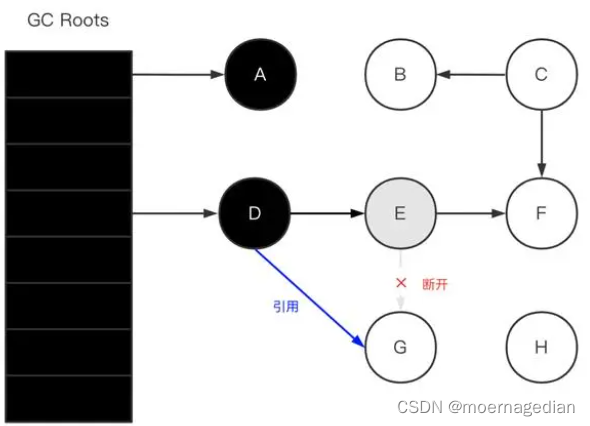
D此时所有引用已经扫描过,但是此时D->G,但是对于GC线程来说,是不知道这个引用的,就会产生漏标。
多标
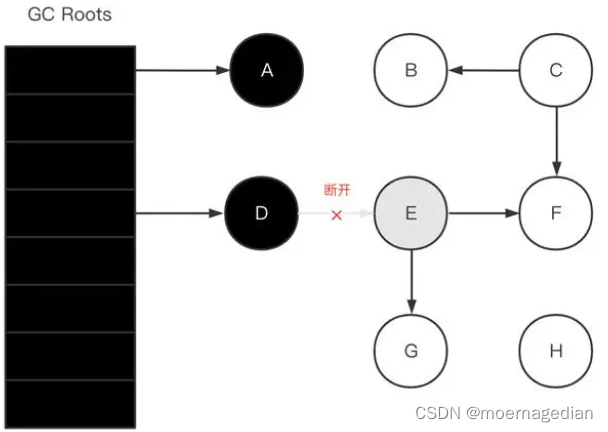
D->E 引用断开,E、F、G不可达。
读屏障、写屏障
在读写前后,将变动节点记录下来(对象 G) 给记录下来。(可以想象成AOP)
CMS通过写屏障卡表解决
卡表是一个与Java堆大小相同的数组,每个元素记录着相应内存区域是否被修改。当用户线程修改了某个被标记的对象的指针时,就会由卡表中相应的条目被设置为“dirty”。垃圾收集器会检查卡表中所有“dirty”条目所对应的内存区域。
G1写屏障rset解决
Remembered Set(RSet),它是一种专门针对并发标记整理算法的优化,它能够更方便和高效地记录所有引用了老年代对象的新生代对象,避免了传统卡表方式在处理跨代引用时需要全局扫描卡表的缺点。
当某个Region的对象被修改时,处理这个Region的线程需要扫描该Region的RSet,找到其他Region中指向该Region的对象,