今天再来回顾一下DINO中匈牙利匹配与损失函数部分,该部分大致与DETR相似,却又略有不同。
为了查看数据方便,博主将num_query改为20,max_select值也为20。
匈牙利匹配过程
首先是数据送入匈牙利匹配中进行标签匹配过程了。
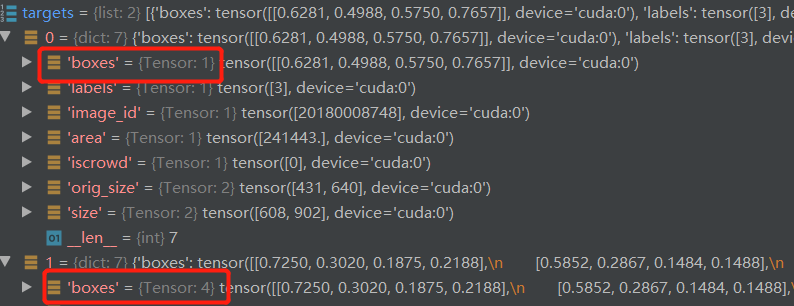
获取预测的类别,box信息
bs, num_queries = outputs["pred_logits"].shape[:2]
#获取预测值信息
out_prob = outputs["pred_logits"].flatten(0, 1).sigmoid()
#[batch_size * num_queries, num_classes] torch.Size([40, 4]) 4为类别数目
out_bbox = outputs["pred_boxes"].flatten(0, 1)
# [batch_size * num_queries, 4] torch.Size([40, 4]) 4为xywh数据
获取真实框的类别与box信息
tgt_ids = torch.cat([v["labels"] for v in targets])
tgt_bbox = torch.cat([v["boxes"] for v in targets])
计算Focal_loss:pos_cost_class与neg_cost_class皆为:torch.Size([40, 4]),得到cost_class为:torch.Size([40, 5]),cost_class为每个query与target的损失。
alpha = self.focal_alpha #0.25
gamma = 2.0
neg_cost_class = (1 - alpha) * (out_prob ** gamma) * (-(1 - out_prob + 1e-8).log())
pos_cost_class = alpha * ((1 - out_prob) ** gamma) * (-(out_prob + 1e-8).log())
cost_class = pos_cost_class[:, tgt_ids] - neg_cost_class[:, tgt_ids]
计算L1距离得到cost_bbox为:torch.Size([40, 5])
cost_bbox = torch.cdist(out_bbox, tgt_bbox, p=1)
计算giou,得到cost-giou为:torch.Size([40, 5])
cost_giou = -generalized_box_iou(box_cxcywh_to_xyxy(out_bbox), box_cxcywh_to_xyxy(tgt_bbox))
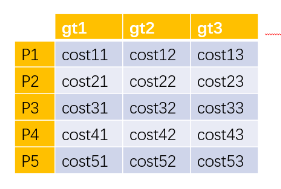
构成cost矩阵
C = self.cost_bbox * cost_bbox + self.cost_class * cost_class + self.cost_giou * cost_giou
C = C.view(bs, num_queries, -1).cpu()
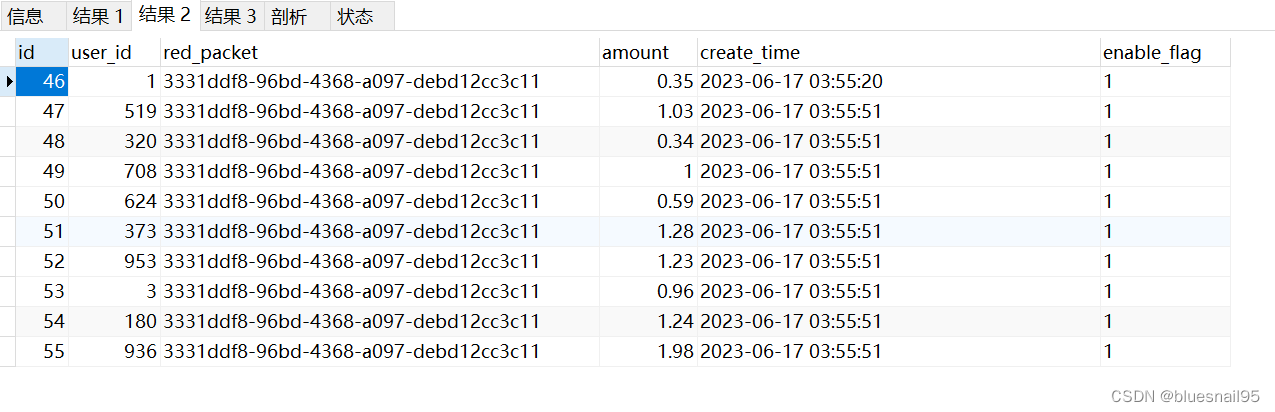
中间步骤C:
最终形成的C:torch.Size([2, 20, 5])
获取每个batch中对应的标签个数
sizes = [len(v["boxes"]) for v in targets]
使用匈牙利匹配算法进行计算,得出匹配的标签与预测框。
indices = [linear_sum_assignment(c[i]) for i, c in enumerate(C.split(sizes, -1))]
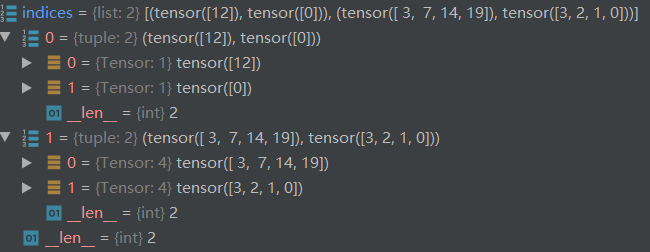
得出的indices是list形式,内部每个元素为tuple,其内为array对应标签id与预测框id。

将indices转换为tensor向量形式。
return [(torch.as_tensor(i, dtype=torch.int64), torch.as_tensor(j, dtype=torch.int64)) for i, j in indices]
返回的indices如下:
CDN构造过程
CDN是DINO的创新点之一,其是如何构造的呢?举个例子:
设置batch_size=2,第一张图片有一个标注框,第二张图片有4个标注框
开始设置参数dn_number=100,即添加噪声的query有100个,同时要设置对照组,也是100
则dn_number=200,注意这里是设置dn_query的个数
随后判断设置多少个对照组,根据每个batch中最大的tgt数目设置dn_group。
known = [(torch.ones_like(t['labels'])).cuda() for t in targets]
#[tensor([1], device='cuda:0'), tensor([1, 1, 1, 1], device='cuda:0')]
batch_size = len(known)#2
known_num = [sum(k) for k in known]
#[tensor(1, device='cuda:0'), tensor(4, device='cuda:0')]
if int(max(known_num)) == 0:
dn_number = 1
else:
if dn_number >= 100:
dn_number = dn_number // (int(max(known_num) * 2))
#确定dn_number=25
什么意思呢,就是说总共我每个batch中设置25组即可。
然后总共正样本数为(1+4)x25=125,同理负样本数也是如此,两者加起来总共有250个
随后对标签进行加噪。
分别得到编码后的标签类别与box:(input_label_embed等都需经过embed编码)
input_label_embed:torch.Size([250, 256])
input_bbox_embed:torch.Size([250, 4])
由于我们设置了dn_query数目固定为200,生成dn_query:
初始时全为0,
padding_label = torch.zeros(pad_size, hidden_dim).cuda()#torch.Size([200, 256])
padding_bbox = torch.zeros(pad_size, 4).cuda()#torch.Size([200, 4])
随后复制batch维度:
input_query_label = padding_label.repeat(batch_size, 1, 1)#torch.Size([2, 200, 256])
input_query_bbox = padding_bbox.repeat(batch_size, 1, 1)#torch.Size([2, 200, 4])
可以看到,此时其全部为0,那么如何将我们加噪后的query放进去呢?
if len(known_num):
map_known_indice = torch.cat([torch.tensor(range(num)) for num in known_num]) # [1,2, 1,2,3]
map_known_indice = torch.cat([map_known_indice + single_pad * i for i in range(2 * dn_number)]).long()
if len(known_bid):
input_query_label[(known_bid.long(), map_known_indice)] = input_label_embed
input_query_bbox[(known_bid.long(), map_known_indice)] = input_bbox_embed
第一个判断获取了标识index,第二个判断结合batch_id与indice来进行填充:
举个例子:
input_query_box[0,0]填充input_bbox_embed[0]
input_query_box[1,0]填充input_bbox_embed[1]
input_query_box[1,1]填充input_bbox_embed[2]
input_query_box[1,2]填充input_bbox_embed[3]
input_query_box[1,3]填充input_bbox_embed[4]
input_query_box[0,4]填充input_bbox_embed[5]
input_query_box[1,4]填充input_bbox_embed[6],以此类推
至此便构造出dn_query了,值得一提的是只有最大tgt数目的图像中的query是全部有非零值的,在本次例子中,第一个batch中2x100个query中只有2x25个非零值,而在第二个batch中,全部都是被填充的。
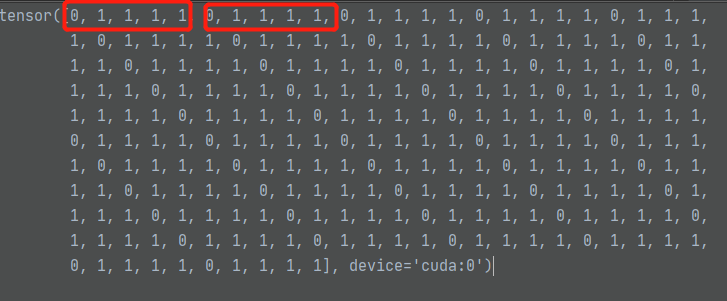
known_bid值如下所示:五个一组
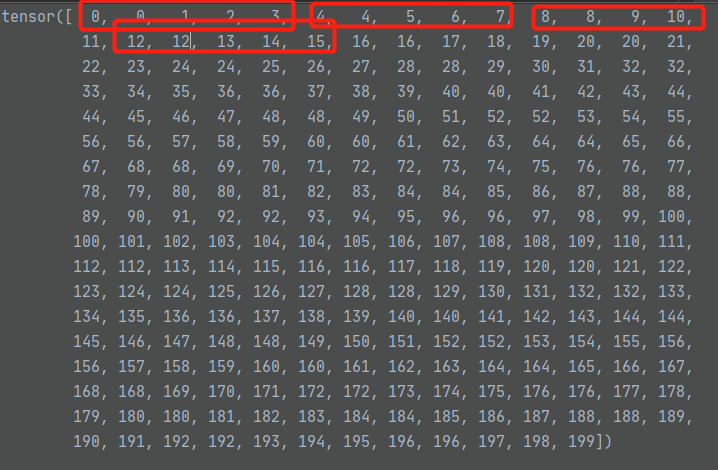
indices值如下所示,五个一组,配合batch_id可以将加噪后的值填入到query中,共有250个,但其值最大到199,刚好与200对应。
计算Label Loss
首先看传入的label_loss的参数:
def loss_labels(self, outputs, targets, indices, num_boxes, log=True):
outputs为预测结果:labels:torch.Size([2, 200, 4]) box:torch.Size([2, 200, 4])
targets为真实值
indices为匈牙利匹配结果:
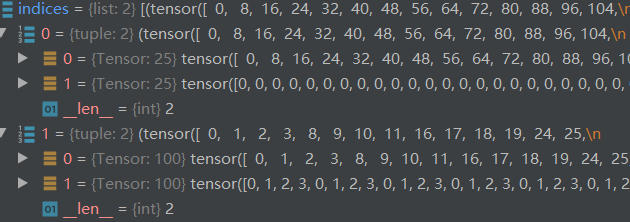
num_boxes为box的个数,此时为125,需要注意的是在第一次跳入loss_labels时,实际上计算的是DN的损失。
使用dn_query计算loss不易查看(有200个),我们使用匈牙利匹配的结果来查看:
target共有5个,其中第一个batch有一个,第二个batch有4个。