文章目录
- 前言
- 第3章 顺序程序设计
- 第4章 选择结构程序设计c
- 第5章 循环程序设计
- 第6章 利用数组处理批量数据
- 第7章 用函数实现模块化程序设计
- 第8章 善于利用指针
- 第9章 用户建立数据类型
- 结构体
- 字节对齐
- 第10章 对文件的输入输出
前言
鉴于写CSDN博客一篇一篇查找比较麻烦,所以特此把这些按照分类别成一个目录,后面把这些问题、知识点写到相关目录的下面,根据目录查找,复习,这个C语言系列就写到这篇上面了。后面如果写得太多,一篇博客写不完就把链接放到下面查找。
第3章 顺序程序设计
- 输入输出
-
- 输入输出语句属于C语言嘛?不是,C语言本身不提供输入输出语句,而我们常见的scanf和printf是计算机属于IO接口这块,与硬件打交道的部分,这些函数由软件公司根据IO接口一系列标准编辑成一些具有功能的文件完成,C语言编辑器直接调用即可。(个人理解)
-
- C语言中,即我们编写的源程序是怎么调用这些输入输出函数的?头文件#include<stdio.h>,std:standard标准,io:io接口,h:head files头文件。
-
- 调用的两种区别:有#include<stdio.h>和#include"stdio.h"两种方式。第一种是由远到近的标准方式,第二种是有近到远的方式。这里的远指的是C编译系统的目录,就是放这些头文件的目录地方,近就是我们写源头程序的目录,即用户当前目录。
-
- 计算机是方便人设计的,而与计算机交互中,最明显的就是视觉方面,在输入时我们希望以我们理解的方式输入,输出时以我们理解的方式输出,当然不能为所欲为,想怎么输出就怎么输出,这就要结合计算机能给你呈现什么?而计算机可以给你呈现的是我可以显示这个数据的大小,和多少进制,这就是输入输出格式。比如%d,这就是我们希望计算机用十进制整数格式输出,如果我们想让数据显示的范围更大一些,就用%f,这个规定显示更大一些,而且也包含小数。比如ASCII码中包含了写英文用到的符号这些,而这些是用二进制存在计算机里面的,如果我们想把这些二进制对应的符号输出来,就可以使用%c,单字符输出,如果字符比较多考虑%s,字符串输出。
-
- 试一下%f小数的极限?一般实数的整数部分全部输出,小数部分只输出6位。所以在%m.nf中,精确度n>=6位是没有意义的。
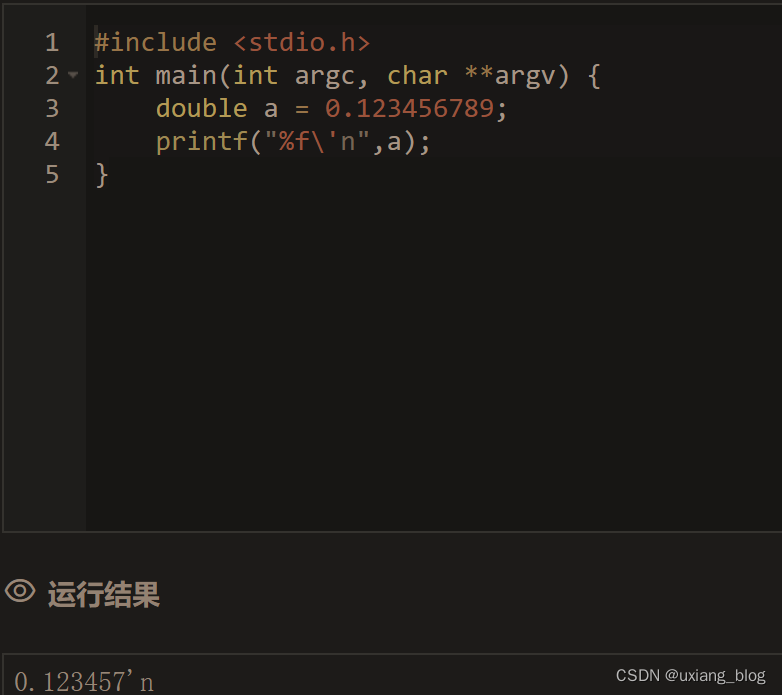
- 试一下%f小数的极限?一般实数的整数部分全部输出,小数部分只输出6位。所以在%m.nf中,精确度n>=6位是没有意义的。
-
- %f:%附加符,修饰符,起修饰补充声明的意思,f以小数形式输出。%f就是我(计算机)提前你说一下或者声明一下哈,我要用小数输出。
-
- 键入问题,在刷题目的时候,有一道题目要求用户键入的正确格式,我选择了"a b c"(a空格b空格c,enter)结果是错误的,它告诉了我正确的答案应该如下输入才对。于是我试了一番,结果。。。。
#include <stdio.h>
int main(int argc, char **argv) {
double a ,b ,c;
scanf("%lf,%lf,%lf",&a,&b,&c);
printf("%f,%f,%f",a,b,c);
}
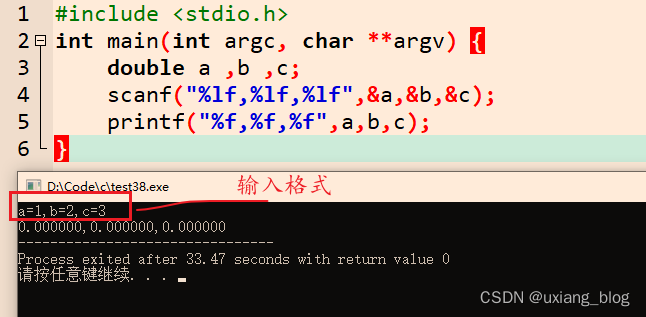
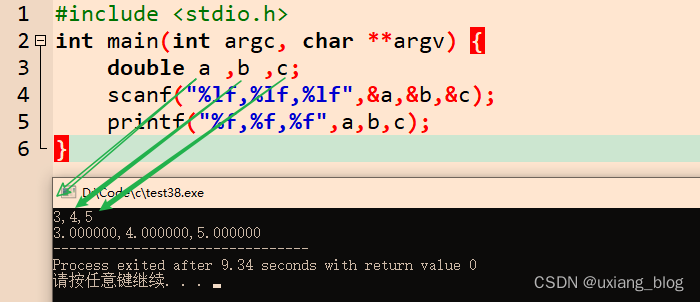
后来我发现是我理解错误了,它这句话是在告诉我第一个是a的位置,所以用“a=”表示,第二个是b的位置,所以用“b=”表示,第三个是c的位置,所以用“c=”表示。而中间用“,”逗号隔开,表示第一个数据的结束,第二个数据的开始,用来表示这三个变量的分界点,就与定义的一一对应上了,然后enter键入,代表我确定是这个三个数字。
-
- putchar( c),c可以是字符常量,整型常量,字符变量,或者整型变量。提到字符,这就得从计算机的源头说起,最常见到得就是英语文章,里面涉及英语单词,标点符号,除此之外还有其他方面用到得字符符号,把这些在各个领域常用到得符号集合在一起,存储在计算机里,方便使用计算机调用,这些符合的集合有个专门的名字,叫做ASCII码,它的范围用十进制表示是0~255(参考本书)。而putchar( c)这个字符输出函数就是专门用来显示这些字符的,而把一个整型赋值给c的时候,就是告诉计算机在ASCII码中找到这个整型数值,显示出与它对应的符号,当然,如果这个整型值不在ASCII码中,那就不知道什么了。这里值得注意的是如果我们要写一个字符,那怎么知道它是字符还是变量呢?为了区别,字符就该写成’a’,这个就是表示字母a,但是如果写成a,那就表示具有多大变量
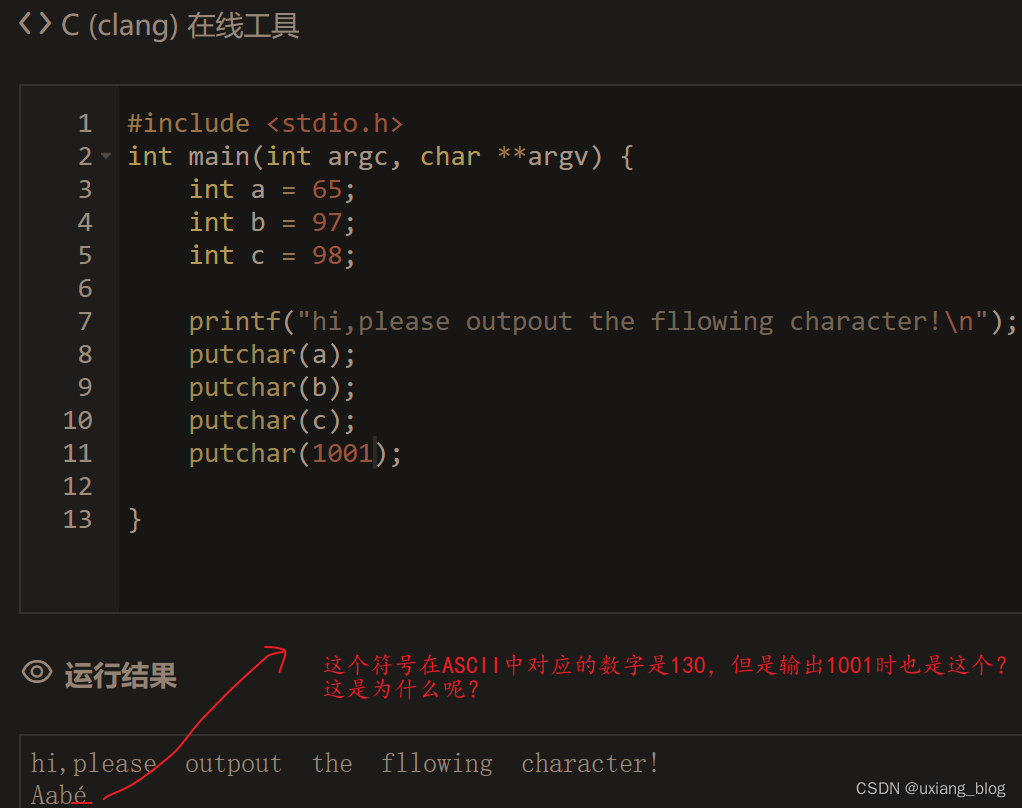
- putchar( c),c可以是字符常量,整型常量,字符变量,或者整型变量。提到字符,这就得从计算机的源头说起,最常见到得就是英语文章,里面涉及英语单词,标点符号,除此之外还有其他方面用到得字符符号,把这些在各个领域常用到得符号集合在一起,存储在计算机里,方便使用计算机调用,这些符合的集合有个专门的名字,叫做ASCII码,它的范围用十进制表示是0~255(参考本书)。而putchar( c)这个字符输出函数就是专门用来显示这些字符的,而把一个整型赋值给c的时候,就是告诉计算机在ASCII码中找到这个整型数值,显示出与它对应的符号,当然,如果这个整型值不在ASCII码中,那就不知道什么了。这里值得注意的是如果我们要写一个字符,那怎么知道它是字符还是变量呢?为了区别,字符就该写成’a’,这个就是表示字母a,但是如果写成a,那就表示具有多大变量
-
- getchar( c)是字符输入函数。
第4章 选择结构程序设计c
第5章 循环程序设计
#include <stdio.h>
int main(int argc, char **argv) {
int p[8]={11,12,13,14,15,16,17,18},i=0,j=0;
while(i++ < 7)if(p[i]%2) j+= p[i];
printf("%d",j);
}
j=?
//45,这个函数的作用是数组中的奇数之和,因为经过i++判断之后i++忽略掉了第0个元素11,直接从第2个元素13开始了。
第6章 利用数组处理批量数据
char c[3][3]={"a","bc","def"};矩阵 c 存储如下:
a b c
d e f
char c[3][3] = {"a", "bc", "def"},矩阵 c 存储如下:
a \0 \0
b c \0
d e f
第7章 用函数实现模块化程序设计
第8章 善于利用指针
第9章 用户建立数据类型
结构体
struct sk{
int a;
float b;
}data, *p = &data;
(1)(*p).data.a ?
(2) (*p).a?
(3)p->data.a ?
(4)p.data.a ?
(*p).data.a:这个表达式尝试使用 (*p) 运算符先解引用指针 p,然后再使用成员访问运算符 . 访问 data 字段,最后使用 .a 访问结构体 data 中的成员 a。然而,data 结构体本身并没有名为 data 的字段,因此这个表达式是错误的。
(*p).a:这个表达式也使用 (*p) 运算符先解引用指针 p,然后使用成员访问运算符 . 访问 a 字段。这是正确的方法之一,用于访问结构体 data 中的成员 a。
p->data.a:这个表达式使用箭头运算符 -> 直接从指针 p 中访问结构体 data 中的成员 a。箭头运算符会自动进行指针解引用和成员访问操作。因此,这也是正确的方法之一,用于访问结构体 data 中的成员 a。
p.data.a:这个表达式是错误的。因为 p 是一个指针,使用点运算符 . 来访问结构体成员需要对指针进行解引用。这里应改为 (*p).a 或 p->a 来访问结构体 data 中的成员 a。
正确的两种方法是 (*p).a 和 p->a。这两个表达式都能正确访问结构体 data 中的成员 a。
字节对齐
点击跳转详见博主棉花糖超人【C上分之路】第八篇:结构体声明定义、结构体数组以及字节对齐
1、按一个字节对齐;
2、按编译器默认进行对齐;
3、字节对齐规则:
(1)结构体内部任何K字节的基本对象相对于结构体首地址的偏移,必须是K的整数倍
(2)结构体变量的首地址能够被其最宽基本类型成员的大小所整除
(3)结构体的总大小为结构体最宽基本类型成员大小的整数倍
struct stu{
union{
char a[5];
int b[2];
}_class;
char c[8];
float d;
}lk;
若int为2字节,char 1 float 4 ,Find sizeof(lk)?
根据结构体内存对齐的规则,对于这个结构体的大小 sizeof(struct stu) 的计算如下:
char a[5] 占用 5 个字节。
int b[2] 占用 2 个 int类型大小的字节,因为 int 在题中定义为 2 个字节大小,所以 int b[2] 总共占用 4 个字节。
char c[8] 占用 8 个字节。
float d 占用 4 个字节。
所以,这个结构体的总大小为 5 + 4 + 8 + 4 = 21 个字节,即 sizeof(struct stu) 的值为 21