GPT1开山之作:Improving language understanding by generative pre-training

本文提出了gpt1,即使用无标签的数据对模型先进行训练,让模型学习能够适应各个任务的通用表示;后使用小部分 task-aware的数据对模型进行微调,可以在各个task上实现更强大的功能。
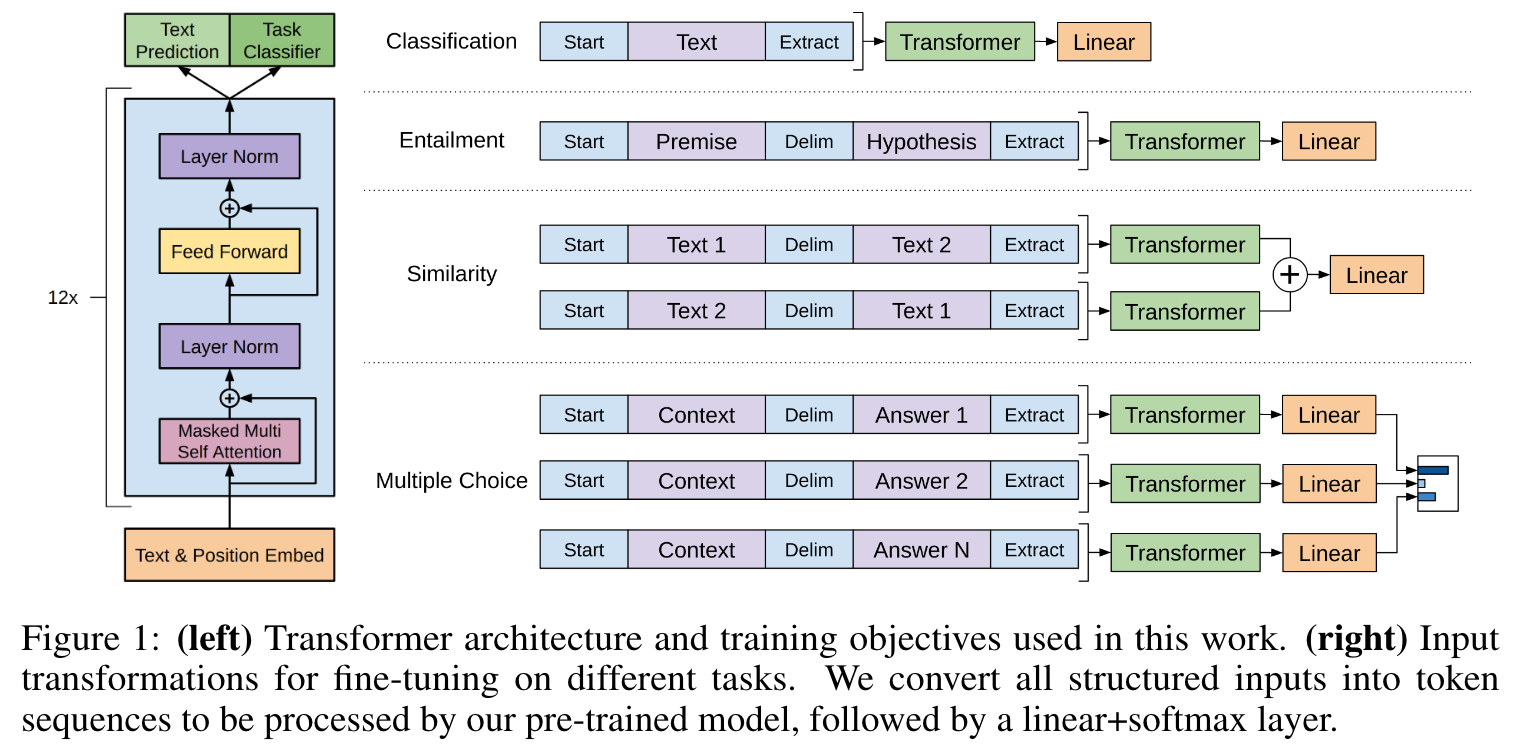
设计框架
分为两块,pre-train和fine-tune,使用transformer模型的解码器部分。
第一阶段:Unsupervised pre-training
预测连续的k个词的下一个词的概率,本质就是最大似然估计,让模型下一个输出的单词的最大概率的输出是真实样本的下一个单词的
u
i
u_i
ui。后面的元素不会看,只看前k个元素,这就和transformer的解码器极为相似。

第二阶段:Supervised fine-tuning
训练下游的task的数据集拥有以下形式的数据:假设每句话中有m个单词,输入序列
{
x
1
,
x
2
,
.
.
.
,
x
m
}
\{x^1,x^2,...,x^m\}
{x1,x2,...,xm} 和一个标签
y
y
y(忧下游任务决定)。
在这个阶段,作者定义了两个优化函数,L1保证句子的连贯性,L2保证下游任务的准确率。

其完整的内部结构如下: