指导书
Project #1 - Buffer Pool | CMU 15-445/645 :: Intro to Database Systems (Fall 2022) — 项目 #1 - 缓冲池 | CMU 15-445/645 :: 数据库系统简介(2022 年秋季)
Task #1:Extendible Hash Table
首先应当了解 可扩展哈希表 的概念,可以参考下面这篇文章:
Extendible Hashing (Dynamic approach to DBMS) - GeeksforGeeks — 可扩展哈希(DBMS 的动态方法) - GeeksforGeeks
下面这篇博客同样不错:
做个数据库:2022 CMU15-445 Project1 Buffer Pool Manager - 知乎 (zhihu.com)
该篇文章中以整数为例,详细描述了一个可扩展哈希表的展开过程。
特点用下面这张图就可以展现出来:
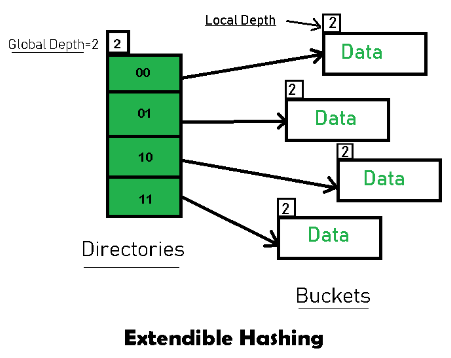
可以看出,可扩展哈希表的哈希性表现在:由 Directories 索引指向存放真正数据的 Buckets。Directories 中每个条目都有唯一的 id,哈希函数返回 id(当扩展发生时,id可能会发生变化),将数据映射到对应的Bucket中。
Directories 中的条目数量 = 2 ^ Global Depth,Global Depth也可以理解为目录中每个条目的位数。而Local Depth关联的则是 Buckets中可存放键值对的数目。
在BusTub提供的代码中,Bucket的数据结构为 list,其中存放的数据类型为pair,首先可以尝试完成Bucket类中的三个函数:Find、Insert、Remove,仅在 list 结构上操作即可。
需要完成的几个函数如下图所示:
-
可扩展哈希表的构造函数:
该类中所有的成员变量如下图所示:
// TODO(student): You may add additional private members and helper functions and remove the ones // you don't need. int global_depth_; // The global depth of the directory size_t bucket_size_; // The size of a bucket int num_buckets_; // The number of buckets in the hash table mutable std::mutex latch_; std::vector<std::shared_ptr<Bucket>> dir_; // The directory of the hash table根据默认参数可知,该哈希表的初始 global_depth = 0,num_buckets = 1,所以可以想到的是在该构造函数中初始化一个Bucket,容量等于bucket_size, 初始的 local_depth = global_depth = 0.
-
可扩展哈希表的查找函数:
/** * * TODO(P1): Add implementation * * @brief Find the value associated with the given key in the bucket. * @param key The key to be searched. * @param[out] value The value associated with the key. * @return True if the key is found, false otherwise. */ auto Find(const K &key, V &value) -> bool;根据 key 计算出 index 后,直接调用对应 Bucket 的查找函数即可
-
可扩展哈希表的移除函数:
/** * * TODO(P1): Add implementation * * @brief Given the key, remove the corresponding key-value pair in the bucket. * @param key The key to be deleted. * @return True if the key exists, false otherwise. */ auto Remove(const K &key) -> bool;根据 key 计算出 index 后,直接调用对应 Bucket 的移除函数即可
-
可扩展哈希表的插入函数:
/** * * TODO(P1): Add implementation * * @brief Insert the given key-value pair into the bucket. * 1. If a key already exists, the value should be updated. * 2. If the bucket is full, do nothing and return false. * @param key The key to be inserted. * @param value The value to be inserted. * @return True if the key-value pair is inserted, false otherwise. */ auto Insert(const K &key, const V &value) -> bool;这应该是最复杂的函数了。按照说明,需要考虑:
-
Bucket未满:
- key已存在,更新value的值
- key不存在,直接插入
-
Bucket已满,则需要执行以下步骤:
-
Bucket 的 local_depth = global_depth,增加 global_depth,且目录扩容为原来的两倍(此处指的是整个大小的扩容,是capacity);
如果 local_depth < global_depth,就继续下面两步;
-
增加对应 Bucket 的 local_depth;
-
Bucket 拆分,重新分配目录指向的Bucket,以及 key-value 对儿
-
而且要明白,insert本质是个递归的过程,因为如果要拆分,就需要将键值对插入到新的Bucket中,直到插入为止。
因为可扩展哈希表需要根据 key 值计算出目录索引,下面的代码为计算索引的代码:
template <typename K, typename V> auto ExtendibleHashTable<K, V>::IndexOf(const K &key) -> size_t { int mask = (1 << global_depth_) - 1; return std::hash<K>()(key) & mask; }可以看出,mask 计算的方式是令低位全部为1,对应global_depth的位为0。举例,一开始的global_depth = 0,则计算出的
mask = 0(b),当发生第一次因Bucket满时而发生分裂的时候,global_depth = 1, 计算可得mask = 01(b).& mask:这行代码使用位与操作符(&)将计算得到的哈希值与掩码进行按位与操作,将哈希值限制在掩码范围内。由于掩码的低global_depth_位全为 1,按位与操作将保留哈希值的低global_depth_位,忽略高位,得到最终的索引位置。如果 K = int,那么哈希函数的返回结果是整数值本身(其他类型请自行搜索)。假设 key = 3 = 011(b),那么index = 11 & 01 = 1,如果 key = 2 = 10(b),index = 10 & 01 = 0,和之前那篇文章举例使用的结论是一致的,即使用低global_depth位来区分不同的key。
另外就是如何扩展 dir,要考虑的一件事是扩展dir之后,相同的key要放在原本的Bucket中,举个课程中的例子:

-
-
可扩展哈希表的重分配Bucket函数:
根据文档说明,这个函数是可以不适用的,取决于具体的实现方式。
/** * @brief Redistribute the kv pairs in a full bucket. * @param bucket The bucket to be redistributed. */ auto RedistributeBucket(std::shared_ptr<Bucket> bucket) -> void;有两种处理方法,一个是保留原始的bucket,创建一个新的bucket,此处需要注意如果重新分配原bucket中的元素时,如果求出来的bucket不在原bucket中时,需要删除原bucket中的对应值;
而另外一种处理方法就是创建两个新的bucket,这样就不必顾虑key-value重复的问题了。
第一版分裂函数:
// 拆分,分裂之前dir已经扩容完毕了, // 且由于bucket是shared_ptr,目前dir中是存在两组完全相同的bucket的(但只需要其中两个相同的就可以完成分裂) // 把原来的bucket分为两个,并把原本bucket中的[key, value]安置好 template <typename K, typename V> auto ExtendibleHashTable<K, V>::RedistributeBucket(std::shared_ptr<Bucket> bucket) -> void { auto new_bucket = std::make_shared<Bucket>(bucket_size_, bucket->GetDepth()); int mask = (1 << bucket->GetDepth()) - 1; // 在dir中给这个新的bucket找到合适的位置 size_t old_bucket_index; bool find = false; for (size_t i = 0; i < dir_.size(); ++i) { if (!find && dir_[i] == bucket) { find = true; old_bucket_index = i; } else if (find && dir_[i] == bucket) { if ((old_bucket_index & mask) != (i & mask)) { // 这一步不可缺少,因为多次扩容之后,有可能mask低位是有可能重复出现几次的 dir_[i] = new_bucket; } } } // 重新分配old_bucket中的内容 // 此处也是一个坑,我采用的方法是不修改原有的bucket, // 如果采取的是创建两个新的bucket,就可以通过hash与mask相与来完成重新分配 std::list<std::pair<K, V>> list = bucket->GetItems(); for (const auto &it : list) { if (dir_[IndexOf(it.first)] == bucket) { continue; } std::pair<K, V> temp = it; bucket->Remove(it.first); InsertHelper(temp.first, temp.second); } num_buckets_++; }第二版分裂函数:
template <typename K, typename V> auto ExtendibleHashTable<K, V>::RedistributeBucket(std::shared_ptr<Bucket> bucket) -> void { auto bucket_0 = std::make_shared<Bucket>(bucket_size_, bucket->GetDepth()); auto bucket_1 = std::make_shared<Bucket>(bucket_size_, bucket->GetDepth()); int mask = 1 << (bucket->GetDepth() - 1); // 重新分配原bucket中的元素 for (const auto &item : bucket->GetItems()) { size_t hash_key = std::hash<K>()(item.first); if ((hash_key & mask) == 0) { bucket_0->Insert(item.first, item.second); } else { bucket_1->Insert(item.first, item.second); } } for (size_t i = 0; i < dir_.size(); ++i) { if (dir_[i] == bucket) { if ((i & mask) == 0) { dir_[i] = bucket_0; } else { dir_[i] = bucket_1; } } } num_buckets_++; }
TODO
关于加锁,本文中使用到的是 C++17中提出的scoped_lock,简单来说,相比较于C++ 11中的lock_guard,虽然其同样采用了RAII机制,但是可以接受0个或多个互斥锁。两者在灵活性上都要略逊于支持延迟加锁和超时解锁的unique_lock。
但是,课程中给出的默认函数,需要加锁处采用了scoped_lock,同样只传入了一个锁。此处仍有些不太理解为什么要这么做。
std::scoped_lock - cppreference.com — std::scoped_lock - cppreference.com
https://chat.openai.com/share/bd8dcbf6-5c8b-4e58-920f-646cde8b6b3b
如果采用对整张表加锁的方式,相当于同一时刻只能有一个线程操作整个哈希表,性能相对来说肯定是比较差的。
理论来说
1、应该对一张表加读写锁,可以同时读,但是如果有线程在尝试修改表,则阻塞其他线程;
2、对一个Bucket操作时,多个线程可以同时读,即Find,但是如果有一个线程尝试修改Bucket中的内容,则阻塞其他想要操作同一个Bucket的线程
此处还有许多细节可以探讨,整体思想有点儿类似意向锁机制。
Task #2:LRU-K Replacement Policy
首先可以尝试完成LeetCode上的第146题146. LRU 缓存 - 力扣(LeetCode),浅显地理解一下LRU的机制。
本Task需要完成地是 LRU-K算法,K的意思是访问次数,LRU本身是剔除最近最久没有被使用的元素,而LRU-K算法则是优先剔除没有达到K次访问的元素,否则就对达到了K次访问的元素按照LRU算法剔除。
实验说明中有说明,backword k-distance指的是当前时间戳与第k次前向访问的时间戳之间的时间差,少于k次历史访问数量的帧则被赋予+inf即正无穷为其backward k-distance,当可替换帧的backward k-distance都为 +inf时,则剔除具有最早时间戳的帧。原论文《The LRU-K page replacement algorithm for database disk buffering》中也有提到这一点。

需要注意的一点是,LRUKReplacer的最大大小和缓冲池大小一致,即所有帧都可以考虑被剔除;但是实际上LRUKReplacer的大小是由可以被剔除的帧的大小表示的,仅有当帧被标记为可驱逐时,replacer的大小才会增加。
单就实现LRU-K而言,对于帧元素,一个重要的区分点就在于访问次数k,按照这个思想,可以把所有帧分为两部分:
- 历史队列:用于存放可以剔除的帧,即访问次数未达到 k
- 缓存队列:用于存放不可以被剔除的帧,即访问次数已达到k
参考LRU算法,这两个队列都可以考虑用哈希 + 链表的数据结构,区别在于需要在两个链表间移动元素。
另外需要两个哈希表,一个记录当前frame被访问的次数,另一个记录当前frame是否可以被剔除。
对于历史队列和缓存队列,根据指导中的说法,缓存队列中元素的移除要使用LRU算法;而对于历史队列,应当移除"相对于当前时间戳访问时间最久远的元素",原则上应当记录每一帧出现的时间戳,采用一种类似与先进先出的算法。此处的重点在于最久远,假设k = 3,有两个元素 A 和 B,访问时间戳分别为{2,3}和{1,4},按照LRU算法,应当剔除元素 A,但是若是考虑访问时间最久远,则应当剔除元素 B。
由于我依旧采用了哈希 + 链表这种近似于LRU的算法,对于访问次数小于k次的元素,就无须采取任何操作,剔除时直接从队尾剔除即可。
待实现的函数有如下几个:
-
用于剔除某一数据帧:
/** * @brief Find the frame with largest backward k-distance and evict that frame. Only frames that are marked as 'evictable' are candidates for eviction. * * A frame with less than k historical references is given +inf as its backward k-distance. * If multiple frames have inf backward k-distance, then evict the frame with the earliest * timestamp overall. * * Successful eviction of a frame should decrement the size of replacer and remove the frame's * access history. * * @param[out] frame_id id of frame that is evicted. * @return true if a frame is evicted successfully, false if no frames can be evicted. */ auto Evict(frame_id_t *frame_id) -> bool;剔除要满足的首要条件是
可以被剔除,history_list中剔除采用 FIFO 算法,cache_list中剔除采用 LRU 算法,此处需要与帧的访问记录相匹配 -
帧的访问记录
/** * @brief Record the event that the given frame id is accessed at current timestamp. * Create a new entry for access history if frame id has not been seen before. * * If frame id is invalid (ie. larger than replacer_size_), throw an exception. You can * also use BUSTUB_ASSERT to abort the process if frame id is invalid. * * @param frame_id id of frame that received a new access. */ void RecordAccess(frame_id_t frame_id);这里有四种情况:
- 首次访问:在
history_list中记录该frame,根据先入先出的思想,记录到队首位置; - 访问次数没有达到 k:根据 FIFO 的思想,无需有任何操作;
- 访问次数刚刚达到 k:将
history_list中的元素,移动到cache_list中; - 访问次数超过 k:根据 LRU 的思想,记录到
cache_list的队首位置;
- 首次访问:在
-
用于设置某一帧可否被剔除
/** * @brief Toggle whether a frame is evictable or non-evictable. This function also * controls replacer's size. Note that size is equal to number of evictable entries. * * If a frame was previously evictable and is to be set to non-evictable, then size should * decrement. If a frame was previously non-evictable and is to be set to evictable, * then size should increment. * * If frame id is invalid, throw an exception or abort the process. * * For other scenarios, this function should terminate without modifying anything. * * @param frame_id id of frame whose 'evictable' status will be modified * @param set_evictable whether the given frame is evictable or not */ void SetEvictable(frame_id_t frame_id, bool set_evictable);根据某一frame是否可剔除的记录,以及
set_evictable的值来设置某一页是否为可被剔除或是不可被剔除。 -
移除某一帧的所有访问记录
/** * @brief Remove an evictable frame from replacer, along with its access history. * This function should also decrement replacer's size if removal is successful. * * Note that this is different from evicting a frame, which always remove the frame * with largest backward k-distance. This function removes specified frame id, * no matter what its backward k-distance is. * * If Remove is called on a non-evictable frame, throw an exception or abort the * process. * * If specified frame is not found, directly return from this function. * * @param frame_id id of frame to be removed */ void Remove(frame_id_t frame_id);只要满足可移除条件,即 frame_id < 容量,且可被移除,根据访问次数,从
history_list或者是从cache_list中移除即可,勿忘记清除访问记录,以及初始化是否可剔除变量。此处遇到了一个小坑,推荐方式是通过
thorw std::exception()抛出异常,但是为了便于得知在执行过程中更详细的信息,于是我采用了throw std::invalid_argument()的方式,同时判断这两个条件frame_id < 容量,且可被移除,但是根据设计思想,这两者的错误级别并不相同,前者会导致程序崩溃,后者则不必导致程序崩溃。 -
记录当前
Replacer的大小,即可以剔除的数据帧数/** * @brief Return replacer's size, which tracks the number of evictable frames. * * @return size_t */ auto Size() -> size_t;这一项没什么好说的,顶多需要注意一下并发的问题。
而有关加锁,我采用了简单粗暴的std::scoped_lock<std::mutex> lock(latch_),即使用一把大锁。
Task #3:Buffer Pool Manager Instance
学过数据库的大概都知道,Buffer Pool的存在,如果不了解的话,可以阅读下面这篇文章:
揭开 Buffer Pool 的面纱 | 小林coding (xiaolincoding.com)
简而言之,BufferPoolManagerInstance 负责从 DiskManager 获取数据库页面并将它们存储在内存中,当内存不足或者是明确指示需要清除缓冲区内容时,可以将其中的脏页写回到磁盘。
根据指导书中的说明,DiskManager的功能无需我们实现,专注于Buffer Pool的设计即可。
在Buffer Pool Manager Instance中,需要使用到此前完成的ExtendibleHashTable和LRUKReplacer,哈希表用于完成page_id到frame_id的映射,而LRUK替换器的工作则是跟踪每一个page.
类中的变量如下:
/** Number of pages in the buffer pool. */
const size_t pool_size_;
/** The next page id to be allocated */
std::atomic<page_id_t> next_page_id_ = 0;
/** Bucket size for the extendible hash table */
const size_t bucket_size_ = 4;
/** Array of buffer pool pages. */
Page *pages_;
/** Pointer to the disk manager. */
DiskManager *disk_manager_ __attribute__((__unused__));
/** Pointer to the log manager. Please ignore this for P1. */
LogManager *log_manager_ __attribute__((__unused__));
/** Page table for keeping track of buffer pool pages. */
ExtendibleHashTable<page_id_t, frame_id_t> *page_table_;
/** Replacer to find unpinned pages for replacement. */
LRUKReplacer *replacer_;
/** List of free frames that don't have any pages on them. */
std::list<frame_id_t> free_list_;
/** This latch protects shared data structures. We recommend updating this comment to describe what it protects. */
std::mutex latch_;
需要明确的一点是,对于pages_数组,由于成员变量为*pages_,即指向该数组的首地址,也是可以通过类似pages_[id]的方式查询其中的某个元素的,而在实现的过程中,会使用frame_id来表示第几个Page;
而对于可扩展哈希表*page_table_,K是page_id_t,V是frame_id_t,具体的Page对象依旧依赖*pages_数组来管理。
在初始化BufferPoolManagerInstance对象的时候,其实现如下:
BufferPoolManagerInstance::BufferPoolManagerInstance(size_t pool_size, DiskManager *disk_manager, size_t replacer_k,
LogManager *log_manager)
: pool_size_(pool_size), disk_manager_(disk_manager), log_manager_(log_manager) {
// we allocate a consecutive memory space for the buffer pool
pages_ = new Page[pool_size_];
page_table_ = new ExtendibleHashTable<page_id_t, frame_id_t>(bucket_size_);
replacer_ = new LRUKReplacer(pool_size, replacer_k);
// Initially, every page is in the free list.
for (size_t i = 0; i < pool_size_; ++i) {
free_list_.emplace_back(static_cast<int>(i));
}
}
可以看到,pages_的大小,和replacer_的大小,都是pool_size,我在预习相关内容的时候,在知乎上看到了如下这张图,将整个系统做了一个很好的抽象,可以看到 frame中包含着page。
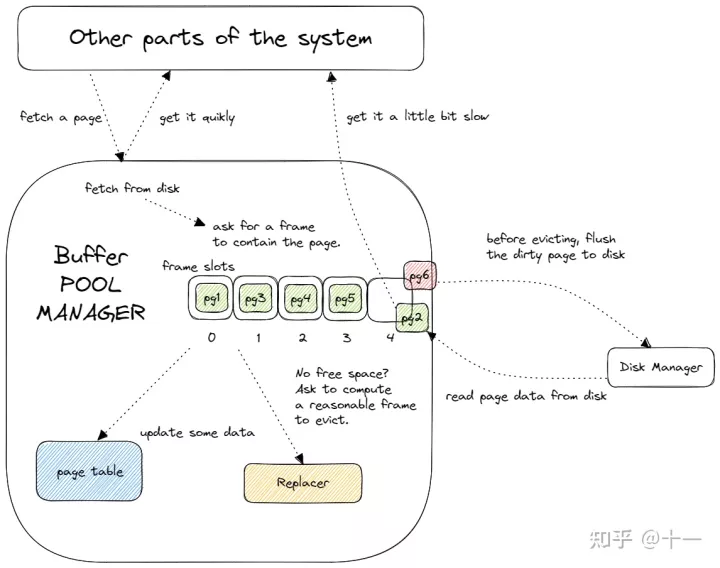
free_list中的索引是frame_id,表示哪个frame是空闲,而pages_的索引也是frame_id,表示pages中对应位置的page是否为dirty。而Buffer Pool Manager中replacer_管理的对象也是frame,通过frame_id来表示每个帧的访问次数等相关信息。
而page_table_维护的则是page_id到frame_id的映射,因为对于Buffer Pool Manager之外的对象而言,例如disk_manager_,frame_id是不可见的,仅通过page_id来操作具体的页。所以要知道某个page是否在Buffer Pool中,也是通过page_table_.
需要实现的函数有如下几个:
-
根据指定的 Page_id 取Page
/** * @brief Fetch the requested page from the buffer pool. Return nullptr if page_id needs to be fetched from the disk but all frames are currently in use and not evictable (in another word, pinned). * * First search for page_id in the buffer pool. If not found, pick a replacement frame from either the free list or the replacer (always find from the free list first), read the page from disk by calling disk_manager_->ReadPage(), and replace the old page in the frame. Similar to NewPgImp(), if the old page is dirty, you need to write it back to disk and update the metadata of the new page * * In addition, remember to disable eviction and record the access history of the frame like you did for NewPgImp(). * * @param page_id id of page to be fetched * @return nullptr if page_id cannot be fetched, otherwise pointer to the requested page */ auto FetchPgImp(page_id_t page_id) -> Page * override;先从
buffer pool中找page_id,找到做好记录就直接返回。如果没有找到,就需要将磁盘中的 page 载入内存,并从当前
buffer pool中空闲链表中或者是replacer中取一帧(优先空链表),与NewPgImp()一样,如果这一页是脏页,就需要刷回磁盘。然后,把page加载到内存中,这一步千万别忘了,我第一次测试的时候就是因为忘记这一步导致没通过。如果空闲链表中没有位置,而且所有page 都是不可剔除的,就返回 nullptr.
-
unpin 操作
/** * @brief Unpin the target page from the buffer pool. If page_id is not in the buffer pool or its pin count is already 0, return false. * * Decrement the pin count of a page. If the pin count reaches 0, the frame should be evictable by the replacer. Also, set the dirty flag on the page to indicate if the page was modified. * * @param page_id id of page to be unpinned * @param is_dirty true if the page should be marked as dirty, false otherwise * @return false if the page is not in the page table or its pin count is <= 0 before this call, true otherwise */ auto UnpinPgImp(page_id_t page_id, bool is_dirty) -> bool override; -
刷新页
/** * @brief Flush the target page to disk. * * Use the DiskManager::WritePage() method to flush a page to disk, REGARDLESS of the dirty flag. * Unset the dirty flag of the page after flushing. * * @param page_id id of page to be flushed, cannot be INVALID_PAGE_ID * @return false if the page could not be found in the page table, true otherwise */ auto FlushPgImp(page_id_t page_id) -> bool override;不再内存中就不用刷新,在内存中就调用
disk_manager_->WritePage()写入磁盘即可,因为指导中说明了,无须顾及该页是否为脏页。
-
创建一个新的Page
/** * @brief Create a new page in the buffer pool. Set page_id to the new page's id, or nullptr if all frames are currently in use and not evictable (in another word, pinned). * * You should pick the replacement frame from either the free list or the replacer (always find from the free list first), and then call the AllocatePage() method to get a new page id. If the replacement frame has a dirty page, you should write it back to the disk first. You also need to reset the memory and metadata for the new page. * * Remember to "Pin" the frame by calling replacer.SetEvictable(frame_id, false) * so that the replacer wouldn't evict the frame before the buffer pool manager "Unpin"s it. * Also, remember to record the access history of the frame in the replacer for the lru-k algorithm to work. * * @param[out] page_id id of created page * @return nullptr if no new pages could be created, otherwise pointer to new page */ auto NewPgImp(page_id_t *page_id) -> Page * override;如果当前
buffer pool已满并且所有page都是 不可被剔除的,直接返回nullptr。如果
free_list中还有空闲的帧, 就可以在该frame上创建一个page;如果
free_list中没有空闲的帧,但是replacer_中,有标记为evitable的 page(需要经过哈希表的转换),就可以根据 LRU-K 算法剔除掉一个 page ,把新的 page 置入。但是,剔除时需要判断该 page 是否为
dirty,如果是的话,就要调用disk_manager_中的相应方法将 page 写入disk;如果不是的话,就可以直接剔除(注意相关变量即可)。 -
删除Page
/** * @brief Delete a page from the buffer pool. If page_id is not in the buffer pool, do nothing and return true. If the page is pinned and cannot be deleted, return false immediately. * * After deleting the page from the page table, stop tracking the frame in the replacer and add the frame back to the free list. Also, reset the page's memory and metadata. Finally, you should call DeallocatePage() to imitate freeing the page on the disk. * * @param page_id id of page to be deleted * @return false if the page exists but could not be deleted, true if the page didn't exist or deletion succeeded */ auto DeletePgImp(page_id_t page_id) -> bool override;假设在内存中,就先从
page_table_中找,没找到就不用删了;如果在,就要看是不是该页的pin,大于0的时候表示有其他线程在用,是不可以删除的;其他情况,从*replacer_、pages_、page_table_、free_list_*中移除该页的相关信息即可。 -
刷新全部页进disk
/** * TODO(P1): Add implementation * * @brief Flush all the pages in the buffer pool to disk. */ void FlushAllPgsImp() override;遍历
pages,然后调用FlushPgImp即可。
本Project submit测试一轮的时间可是不短,大概得有五六分钟,所以最好仔细检查后再次提交。
TODO & NOTE
截止到2023年6月17日我提交后为止,共计有543人提交成功通过测试,最长用时竟然需要20s(此处使用“竟然”是因为最短的时间仅为1s不到,排名第一的0.6s的是什么神仙……)
我首先在我的ubuntu虚拟机上提交,排名为340,用时3.8s+,之后再次在我的windows本地环境下提交,排名却达到了357,用时3.9s+,二次提交后排名依旧为340,所以波动幅度大概在0.1s.
粗浅的分析一下,可以提高用时的点有两个:
- 使用更细粒度的锁
- 更改遍历方式(但我觉得这个仅在大数据下会有较为明显的时间提升)
我对并发场景下的理解,并不深刻,等学成归来再次优化吧,目标是1s内。