系列文章
收录于【Linux】文件系统 专栏
关于文件描述符与文件重定向的相关内容可以移步 文件描述符与重定向操作。
可以到 浅谈文件原理与操作 了解文件操作的系统接口。
目录
系列文章
揭秘C库文件结构体
文件缓冲区
为什么需要文件缓冲区
刷新机制
内核文件缓冲区
模拟实现
结构声明
函数实现
fopen
fclose
fllush
fwrite
揭秘C库文件结构体
🍡之前我们说过,C 库中的 IO 函数是对系统调用的封装,而系统调用函数需要使用到文件描述符 fd,由此我们便可以推断出一个结论:FILE中必定封装了fd。
🍡其实,stdout、stdin、stderr 也是 FLIE* 类型的,我们不妨访问该结构体看看,一众成员变量中的 _fileno 就是封装起来的fd。
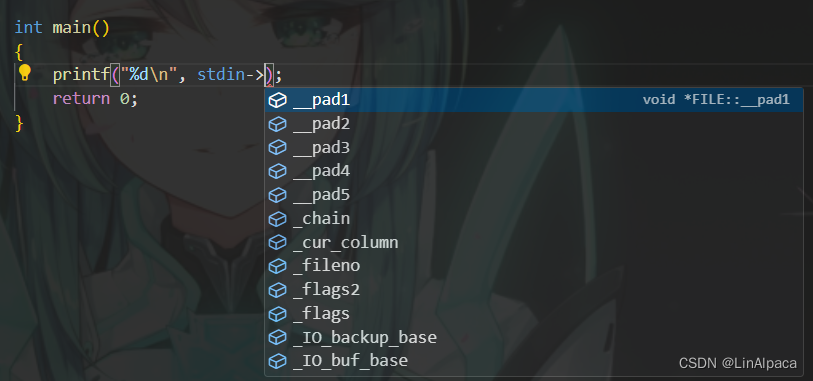
🍡将三个文件和新打开文件的 _fileno 都打印出来,最后的结果正是 fd 所对应的数字。
int main()
{
printf("%d\n", stdin->_fileno);
printf("%d\n", stdout->_fileno);
printf("%d\n", stderr->_fileno);
FILE* f = fopen("log.txt","w");
printf("%d\n",f->_fileno);
return 0;
}
🍡现在,我们来看看这段代码,用两种函数对显示器写入,直接运行的话就是正常输出两个语句。
int main()
{
fprintf(stdout, "%s", "hello fprintf\n");
const char *str = "hello write\n";
write(1, str, strlen(str));
fork();
return 0;
}
🍡若是将其重定向到文件之中就大有不同了。

🍡可以看出 write 先写入文件,之后 fprintf 再写入,而且还写了两次。其实,在 FILE 结构体中还有一部分空间会作为文件缓冲区,并依照特定的刷新机制刷新内部的数据。
文件缓冲区
为什么需要文件缓冲区
🍡之前在冯诺依曼体系中我们说过,访问的外设速度是极慢的,若每次写入字符都直接写入文件,就会极大的拉低程序的运行速度。
🍡我们这里使用两种方式进行计数,第一种数字每次改变时都打印到显示器上,第二种则是计数完成再进行打印,最后输出消耗的时间。
int main()
{
int count = 0;
int begin1 = clock();
for(int i = 0;i<10000;i++)
{
count++;
printf("%d\n",count);
}
int end1 = clock();
count = 0;
int begin2 = clock();
for(int i = 0;i<10000;i++)
{
count++;
}
printf("%d\n",count);
int end2 = clock();
printf("first is : %d\n",end1-begin1);
printf("second is : %d\n",end2-begin2);
return 0;
}![]()
🍡最后的结果便是第一种明显慢于第二种,便有力地展现了外设的访问速率与 CPU 的访问速率的差别。
🍡使用文件缓冲区后,结合特定的刷新机制,便可以有效地节约调用者的时间。
刷新机制
🍡刷新机制可以被分作不同的三种:
- 无缓冲
- 行缓冲
- 全缓冲
🍡行缓冲就是遇到 \n 时刷新之前的缓冲区,经典代表如显示器。而一般的普通文件使用的都是全缓冲,只有缓冲区满的时候才会刷新缓冲区。
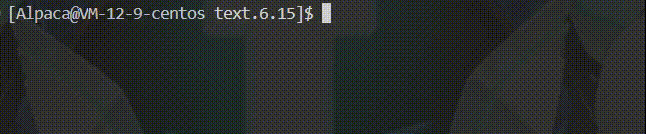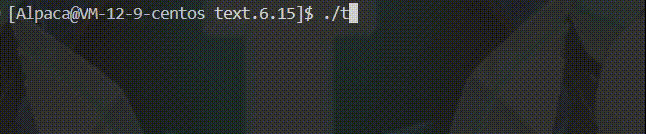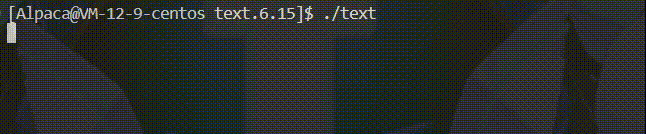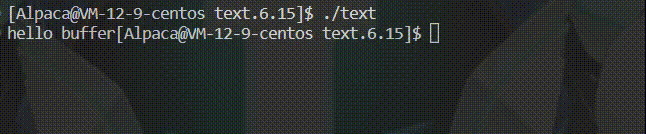
int main()
{
printf("hello buffer");
sleep(1);
return 0;
}🍡若是这样试着输出的话,由于没有识别到 \n 便不刷新缓冲区,休眠一秒后程序结束才将缓冲区内的内容刷新出来。
🍡想要避免这种情况,那我们便可以在语句末加上 \n 。
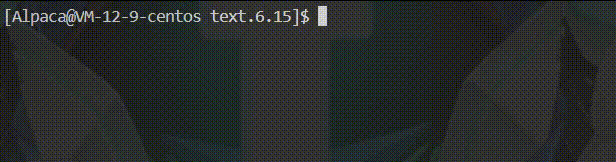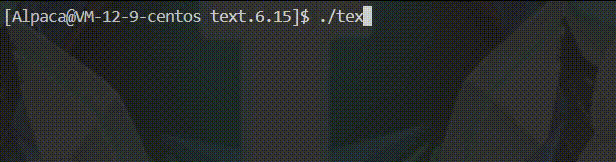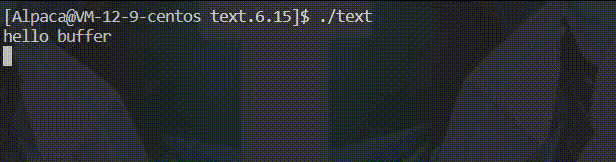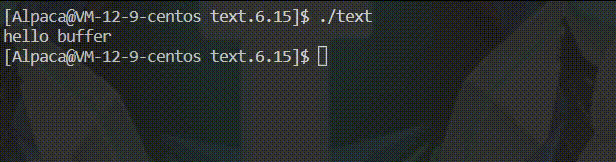
int main()
{
printf("hello buffer\n");
sleep(1);
return 0;
}
🍡由于识别到了 \n 因此直接刷新缓冲区中的内容,之后再休眠 1 秒,最后程序结束。
🍡现在我们便可以解释上面那个打印问题了。
🍡在显示器上打印时为行缓冲,因此第一次 fprintf 时就直接刷新缓冲区了,之后再调用 write 由于 write 没有缓冲区便直接写入。
🍡第二次重定向到普通文件中,fprintf 的刷新策略就改变了,即便有 \n 也无法刷新缓冲区。便进入休眠,之后调用 fork 创建了一个子进程,由于子进程会继承父进程的相关代码数据便继承了缓冲区中的内容,程序结束才刷新缓冲区,于是 fprintf 就打印了两次。
内核文件缓冲区
🍡在上一篇文章中,我们讲过在内存中打开的文件都有对应一个缓冲区,那这个缓冲区跟 C 库中的文件缓冲区有什么区别吗?
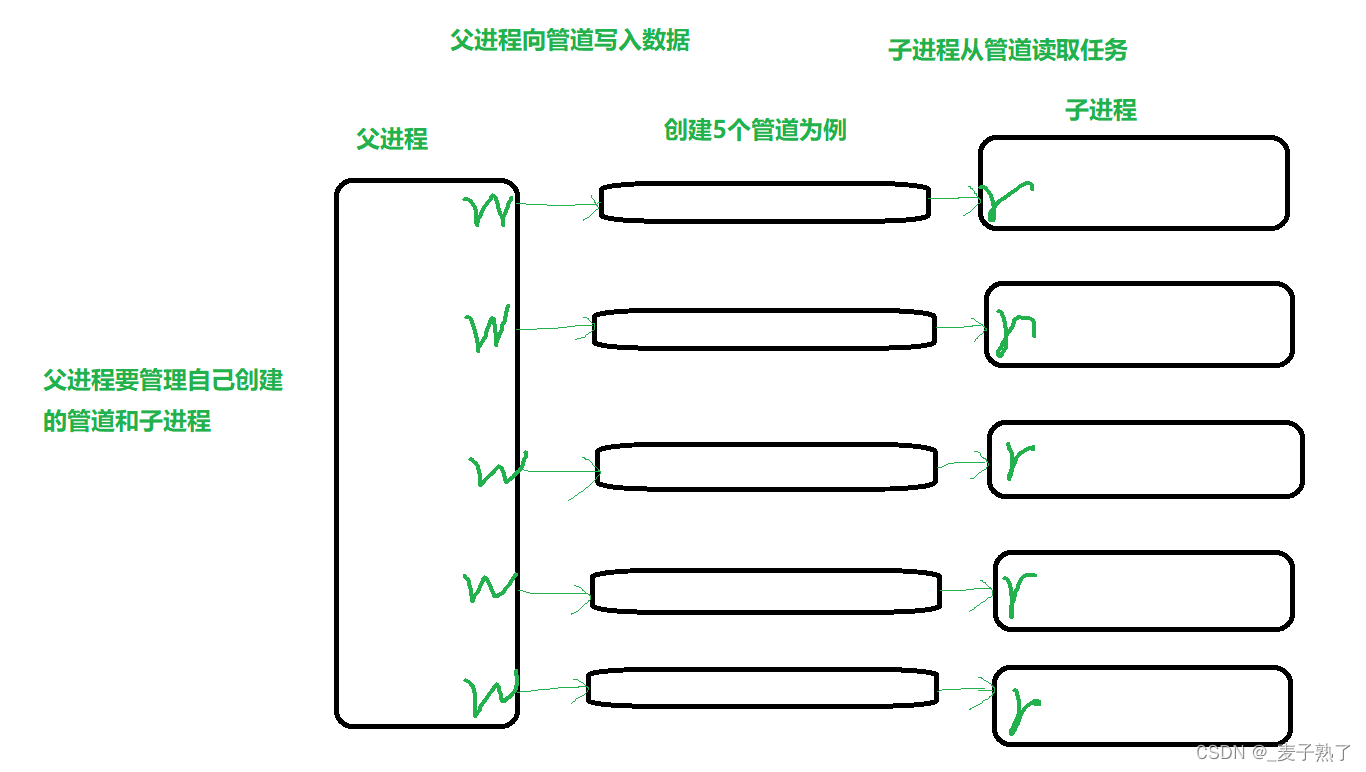
🍡再来看这张图,从用户层出发若调用 C 库的文件操作,数据就会先被拷贝到库的文件缓冲区中,符合刷新策略时再进行系统调用,将数据拷贝到内核级缓冲区中。若直接调用系统调用则直接将数据拷贝到内存级缓冲区中。
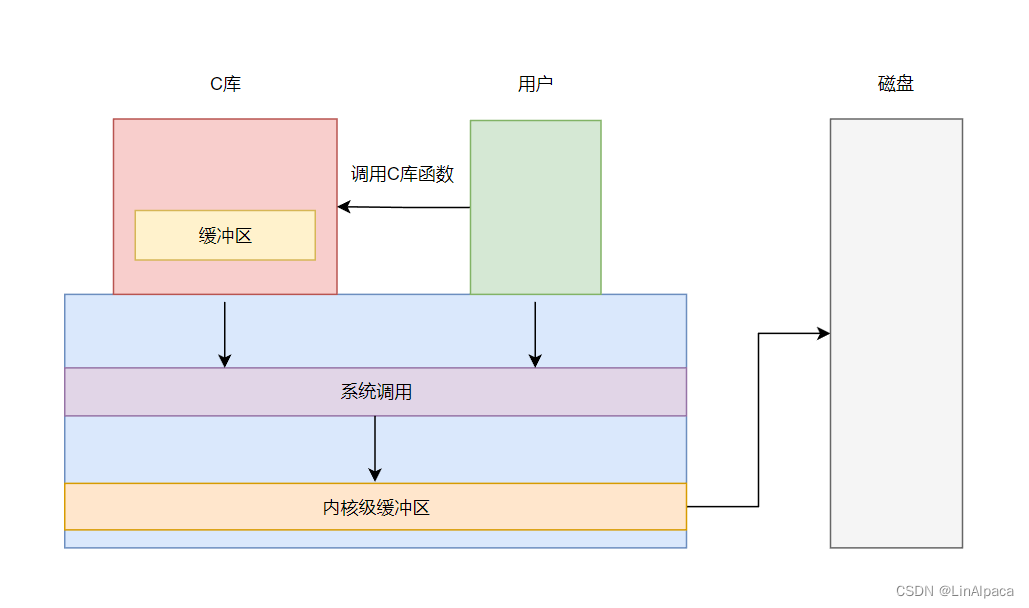
🍡之后操作系统会根据其自身的刷新策略对内核级缓冲区进行刷新,由于 OS 内部需要考虑的内容更多更复杂,因此其刷新策略要比库中的缓冲区要复杂得多。根据写入的先后顺序就是最终文件内部数据的顺序。
🍡但是缓冲区的本质还是为了减少 IO 次数从而增加一次 IO 的数据量,提高 IO 效率。
模拟实现
🍡接下来,我们将对C库中的FILE结构进行模拟实现,简单地实现文件的打开、关闭与写入操作。
结构声明
🍡根据对 FILE 的理解,定义一个 MY_FILE 结构体,内部封装了文件描述符、刷新策略 、缓冲区、写入字符的数量,同时声明相关函数。
#define NUM 1024
#define BUFF_NONE 0x1 //用位图的方式表示不同的模式
#define BUFF_LINE 0x2
#define BUFF_ALL 0x4
typedef struct MY_FILE
{
int fd; //文件描述符
int mode; //刷新策略
char buffer[NUM]; //缓冲区
int cur; //写入字符的数量
}MY_FILE;
MY_FILE* my_fopen(const char *path, const char *mode);
size_t my_fwrite(char* str,int size,int nmemb,MY_FILE* fp);
void my_fclose(MY_FILE* fp);函数实现
fopen
🍡实现 fopen 我们可以将这个函数内容分作几个部分。
- 设置文件打开模式
- 根据路径打开文件
- 初始化结构体
- 返回指针
🍡首先根据传入的参数判断文件将要以什么方式打开,之后我们便可以根据打开方式打开文件,一切无误后便可以开辟空间、向结构体中填入数据,最后返回结构体指针即可。
MY_FILE *my_fopen(const char *path, const char *mode)
{
// 设置文件打开模式
if (strcmp(mode, "r") == 0)
flag |= O_RDONLY;
else if (strcmp(mode, "w") == 0)
flag |= (O_WRONLY | O_CREAT | O_TRUNC);
else if (strcmp(mode, "a") == 0)
flag |= (O_WRONLY | O_CREAT | O_APPEND);
if(strstr(mode,"+")) flag |= O_RDWR;
else
{
// wb ...
}
// 根据路径打开文件
umask(0);
mode_t m = 0666;
int fd = 0;
if (flag & O_CREAT) // 读或追加的形式打开文件
{
fd = open(path, flag, m);
}
else
fd = open(path, flag);
if (fd < 0)
return NULL; // 确保文件打开
// 建立MY_FILE结构体
MY_FILE *pf = (MY_FILE *)malloc(sizeof(MY_FILE)); // 开辟内存
if (pf == NULL)
{
close(fd); // 关闭文件
return NULL; // 开辟失败返回
}
// 初始化结构体
pf->fd = fd;
pf->cur = 0;
pf->mode = BUFF_LINE; // 默认为行刷新
memset(pf->buffer, '\0', sizeof(pf->buffer));
// 返回指针
return pf;
}fclose
🍡在关闭文件时,首先要确定的就是此时文件缓冲区中是否还有数据,若还有就需要先刷新到文件之中,之后再释放结构体空间。
void my_fclose(MY_FILE *fp)
{
// 确保传入的不是空指针
assert(fp);
// 冲刷缓冲区
if (fp->cur > 0)
my_fllush(fp);
// 关闭文件
close(fp->fd);
// 释放空间
free(fp);
// 指针置空
fp = NULL;
}fllush
🍡冲刷缓冲区的本质就是进行 IO,之后将缓冲区内的内容清空即可。
void my_fllush(MY_FILE *fp)
{
//确保指针非空
assert(fp);
//进行文件IO
write(fp->fd,fp->buffer,fp->cur);
//清空缓冲区
fp->cur = 0;
fsync(fp->fd);
}
fwrite
🍡虽然叫做 fwrite 但是实际上进行的操作则是将数据拷贝到缓冲区中,这时候我们要关心写入的字节数与当前的剩余空间,若缓冲区已满就刷新一遍,若还未满则判断其与当前缓冲区剩余字节的大小关系,再根据相应的字节将数据写入缓冲区,最后根据刷新策略判断一下当前是否需要刷新即可。
size_t my_fwrite(char *ptr, int size, int nmemb, MY_FILE *fp)
{
// 确保传入的文件指针非空
assert(fp);
// 判断缓冲区的剩余空间
size_t user_size = size * nmemb;
size_t my_size = NUM - fp->cur;
size_t writen = 0;
// 空间已满,冲刷缓冲区
if (my_size == NUM)
my_fllush(fp);
// 1.空间未满,直接写入
if (my_size >= user_size)
{
memcpy(fp->buffer + fp->cur, ptr, user_size);
fp->cur += user_size;
writen = user_size;
}
// 2.空间未满,但无法写入全部内容,写入部分内容
else
{
memcpy(fp->buffer + fp->cur, ptr, my_size);
fp->cur += my_size;
writen = my_size;
}
// 计划刷新
if (fp->mode & BUFF_ALL) // 全缓冲
{
if (fp->cur == NUM)
my_fllush(fp);
}
else if (fp->mode & BUFF_LINE) // 行缓冲
{
if (fp->buffer[fp->cur - 1] == '\n')
my_fllush(fp);
}
else // 无缓冲
{
}
// 结算写入的大小
return writen / nmemb;
}🍡好了,今天 文件缓冲区 的相关内容到这里就结束了,如果这篇文章对你有用的话还请留下你的三连加关注。