本文题目来自微信群讨论。

在 Elasticsearch 中,评分(或打分)通常在查询过程中进行,以判断文档的相关性。
默认的打分机制使用的是 BM25,但你也可以通过自定义的打分查询(function_score)来自定义评分机制。然而,如果你想要将评分范围限定在0到1之间,你可能需要在查询中使用脚本来实现。
Elasticsearch 的评分主要关注的是相关性排序,而不是确切的评分值,因此如果你想要让 Elasticsearch 的评分等比例地映射到0和1之间,你需要使用一些形式的归一化或缩放方法。但这并不是 Elasticsearch 内置的功能,你需要自己来实现。
1、归一化解读
当我们谈论"归一化"时,我们指的是将数据集转换为一个共享的,标准化的比例或范围。这在数据分析和机器学习中非常常见,因为它能够帮助我们对不同的数据集进行公平的比较。

例如,假设你有两个数据集,一个是人们的身高(以厘米为单位),另一个是人们的体重(以千克为单位)。这两个数据集的范围和单位都不同。如果我们直接比较它们,就很难得出有意义的结论。然而,如果我们将两者都归一化到0和1之间,我们就可以更容易地比较和理解这两个数据集。
常见的归一化方法是使用最小值最大值归一化法(Min-Max Normalization)。我们会使用到以下公式:
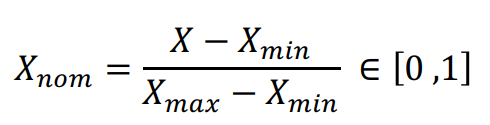
其中Xmax代表最大值、Xmin代表最小值。需要注意的是,当有新数据进来时,可能会改变最大值或最小值,这时候我们就需要重新定义式子中的Xmax和Xmin,以免导致错误。
参考:https://www.cupoy.com/collection/0000018008CD5D70000000046375706F795F72656C656173654355/00000181709BCC8F000000056375706F795F72656C656173654349
2、Elasticsearch 归一化
在这个 Elasticsearch 的案例中,我们正在讨论的是如何将评分(_score)归一化到0和1之间。
默认情况下,Elasticsearch 的评分可以在很大的范围内变化,这取决于很多因素,比如查询的复杂性,文档的数量,等等。如果我们想要更方便地比较和理解这些评分,我们可以将它们归一化,这样所有的评分都会在0和1之间。
简而言之,归一化就是将数据转换到一个统一的范围,这样我们就可以更容易地进行比较和理解。
归一化的方法取决于你知道评分范围的上下限,或者愿意接受一些近似值。一种可能的方法是,首先执行一个查询来获取最高和最低的评分,然后使用这些值来归一化其他查询的评分。
然而,需要注意的是,这种方法可能会产生不一致的结果,因为 Elasticsearch 的评分机制会考虑各种因素(如 tf-idf,字段长度等),并且对于不同的查询,最高和最低的评分可能会有所不同。
因此,归一化评分在 Elasticsearch 中是一个复杂的任务,可能需要在查询级别和/或应用级别进行处理。如果你正在设计一个系统,需要在0和1之间等比例地映射评分,那么可能需要重新考虑是否 Elasticsearch 的评分机制是最适合的方式,或者可能需要查找其他方法来补充或替代 Elasticsearch 的评分。
3、Elasticsearch 8.X 评分归一化
如果你想将 Elasticsearch 的评分等比例地映射到0和1之间,你首先需要知道可能的评分范围。这可能需要你先执行一个查询来找出可能的最高和最低分。以下是一个简单的示例。首先,我们做一个查询来找到评分范围:
GET /your_index/_search
{
"query": { "match_all": {} },
"size": 1,
"sort": [ { "_score": "desc" } ]
}这个查询会返回评分最高的文档。你可以从返回的结果中找到 _score 字段,这就是最高的评分。你也可以通过将排序方向改为 "asc" 来找到最低的评分。然后,你可以用这些值来进行归一化。
假设你已经找到了最高评分 max_score 和最低评分 min_score,你可以在查询中使用一个脚本来进行归一化:
{
"query": {
"function_score": {
"query": { "match_all": {} },
"script_score": {
"script": {
"source": "(_score - params.min) / (params.max - params.min)",
"params": {
"max": max_score,
"min": min_score
}
}
}
}
}
}在这个查询中,我们使用了一个脚本,这个脚本会将原始评分 (_score) 归一化到0和1之间。注意,你需要将 max_score 和 min_score 替换为你在前面的查询中找到的值。
请注意,这只是一个简单的示例,并且这种方法有一些限制。例如,最高和最低的评分可能会随着索引的更新而改变。你可能需要定期更新这些值,或者在每次查询时都计算这些值,这可能会影响查询的性能。
此外,这个脚本假设评分总是在 min_score 和 max_score 之间。如果有新的文档或查询导致评分超出了这个范围,那么这个脚本可能会返回小于0或大于1的值。
在使用这个方法时,你需要考虑这些限制,并根据你的实际情况进行调整。
4、Elasticsearch 8.X 归一化实操
接下来我们通过一个实际的操作示例来演示这个过程。
4.1 获取最大评分
POST kibana_sample_data_ecommerce/_search
{
"_source": [""],
"query": {
"match": {
"customer_full_name": "Underwood"
}
},
"size": 10,
"sort": [
{
"_score": "desc"
}
]
}得到结果:4.4682097。
4.2 获取最小评分
POST kibana_sample_data_ecommerce/_search
{
"_source": [""],
"query": {
"match": {
"customer_full_name": "Underwood"
}
},
"size": 10,
"sort": [
{
"_score": "asc"
}
]
}得到结果:3.731265。
4.3 计算到0-1之间的评分
POST kibana_sample_data_ecommerce/_search
{
"from": 0,
"size": 10,
"_source": [
""
],
"sort": [
{
"_score": {
"order": "asc"
}
}
],
"query": {
"script_score": {
"query": {
"match": {
"customer_full_name": "Underwood"
}
},
"script": {
"source": "(_score - params.min) / (params.max - params.min)",
"params": {
"max": 4.4682097,
"min": 3.731265
}
}
}
}
}通过这些步骤,我们就可以实现在 Elasticsearch 中将评分等比例地映射到0和1之间。
但是,这种方法有其局限性和挑战,需要根据实际情况进行调整和优化。
5、小结
本文详细讨论了在Elasticsearch中实现评分归一化的方法。
这涉及到获取最高和最低评分,然后通过查询中的脚本进行归一化处理。虽然此方法在将评分等比例映射到0和1之间上有所作用,但存在诸如评分范围随索引更新而变化,新的文档或查询可能引发评分超出预设范围等限制。
因此,虽然本文给出了具体的操作示例,但在实际应用中,用户需要根据具体情况灵活调整和优化。
推荐阅读
全网首发!从 0 到 1 Elasticsearch 8.X 通关视频
重磅 | 死磕 Elasticsearch 8.X 方法论认知清单
如何系统的学习 Elasticsearch ?
2023,做点事
实战 | Elasticsearch自定义评分的N种方法

更短时间更快习得更多干货!
和全球 近2000+ Elastic 爱好者一起精进!

大模型时代,抢先一步学习进阶干货!