文章目录
- 背景
- LruCache简介
- LruCache在DSP系统中的应用场景
- LruCache+Redis
- 增加LruCache数据过期清除机制
- ConcurrentHashMapLruCache
- 零拷贝机制
- 源码
背景
我之前工作的一家公司是一家传媒公司,公司的主要盈利方式为在公司项目中接入广告,以及自媒体广告宣传的方式。作为一家传媒公司,DSP系统是必不可少的。
DSP系统是互联网广告需求方平台,用于承接媒体流量,投放广告。业务特点是并发度高,平均响应低(百毫秒)。
为了能够有效提高DSP系统的性能,我们将公司收到的广告信息放入到了Redis这种键值对的系统中进行缓存,在大约两年前,那个时候的性能完全符合要求,但是随着公司规模的扩大,系统QPS不断的提高,Redis也已经难以满足不断增长的并发量的需求了,所以我尝试使用本地缓存+Redis缓存的方式来优化DSP系统。
然后再网络上学习的时候发现可以使用Lru或者Lfu来解决类似的问题,将他们作为本地缓存将会很有效的提高项目性能。这里考虑到LFU的一些缺点,比如占用空间更多,计算比LRU更加缓慢一点(没差那么多),所以我权衡了一下选择了LRU。
使用LruCache + 键值存储数据库(Redis)的机制将远端数据变为本地缓存数据,不仅能够降低平均获取信息的耗时,而且通过一定的过期清除机制,也可以维持服务内存占用在安全区间。
本文将会结合实际应用场景,阐述引入LruCache的原因,并会在高QPS下的挑战与解决方案等方面做详细深入的介绍,希望能对DSP感兴趣的你有所启发。
LruCache简介
简单介绍以及实现
LruCache采用的缓存算法为LRU(Least Recently Used),即最近最少使用算法。这一算法的核心思想是当缓存数据达到预设上限后,会优先淘汰近期最少使用的缓存对象。
LruCache内部维护一个双向链表和一个映射表。链表按照使用顺序存储缓存数据,越早使用的数据越靠近链表尾部,越晚使用的数据越靠近链表头部;映射表通过Key-Value结构,提供高效的查找操作,通过键值可以判断某一数据是否缓存,如果缓存直接获取缓存数据所属的链表节点,进一步获取缓存数据。LruCache结构图如下所示,上半部分是双向链表,下半部分是映射表(不一定有序)。双向链表中value_1所处位置为链表头部,value_N所处位置为链表尾部。
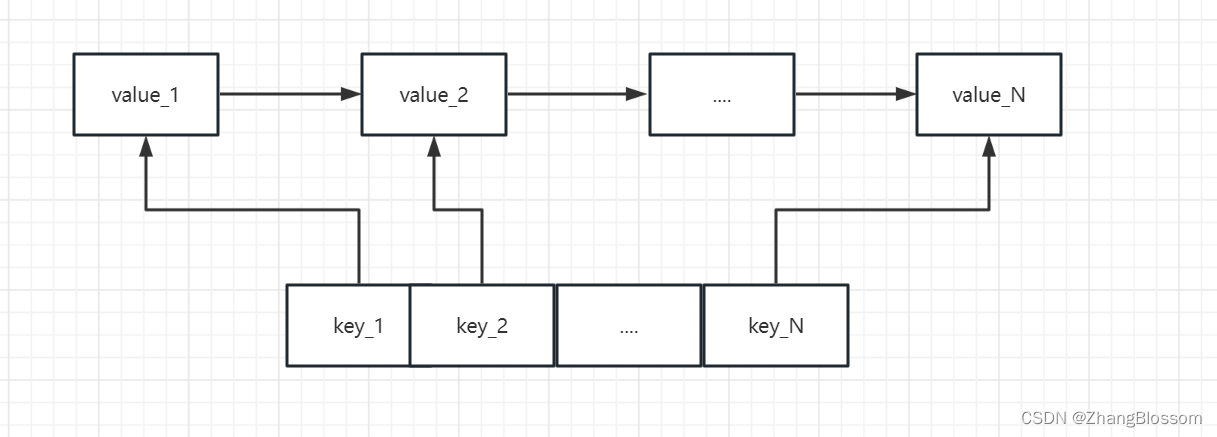
LruCache读操作,通过键值在映射表中查找缓存数据是否存在。如果数据存在,则将缓存数据所处节点从链表中当前位置取出,移动到链表头部;如果不存在,则返回查找失败,等待新数据写入。下图为通过LruCache查找key_2后LruCache结构的变化。
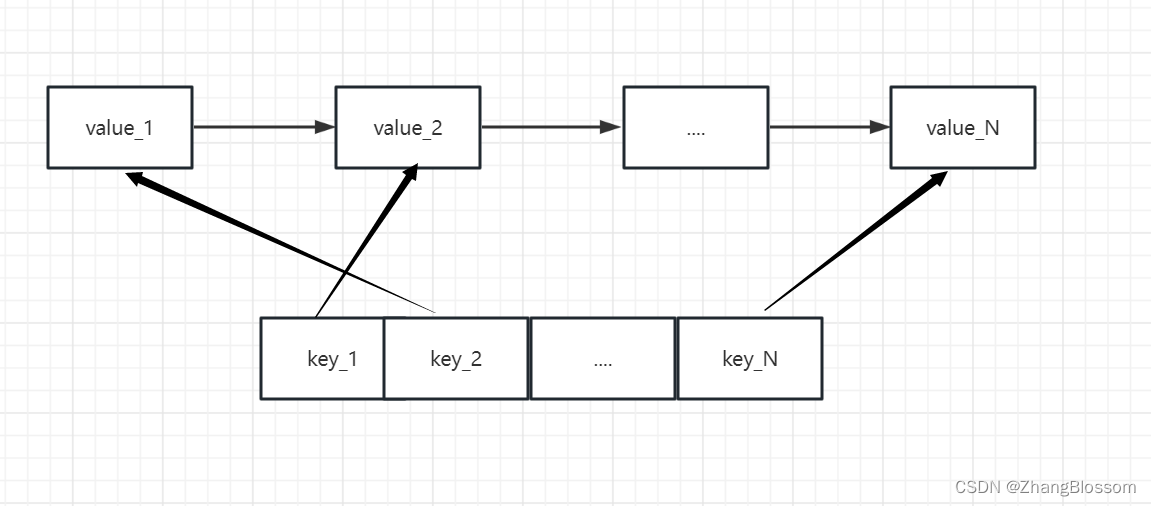
LruCache没有达到预设上限情况下的写操作,直接将缓存数据加入到链表头部,同时将缓存数据键值与缓存数据所处的双链表节点作为键值对插入到映射表中。下图是LruCache预设上限大于N时,将数据M写入后的数据结构。

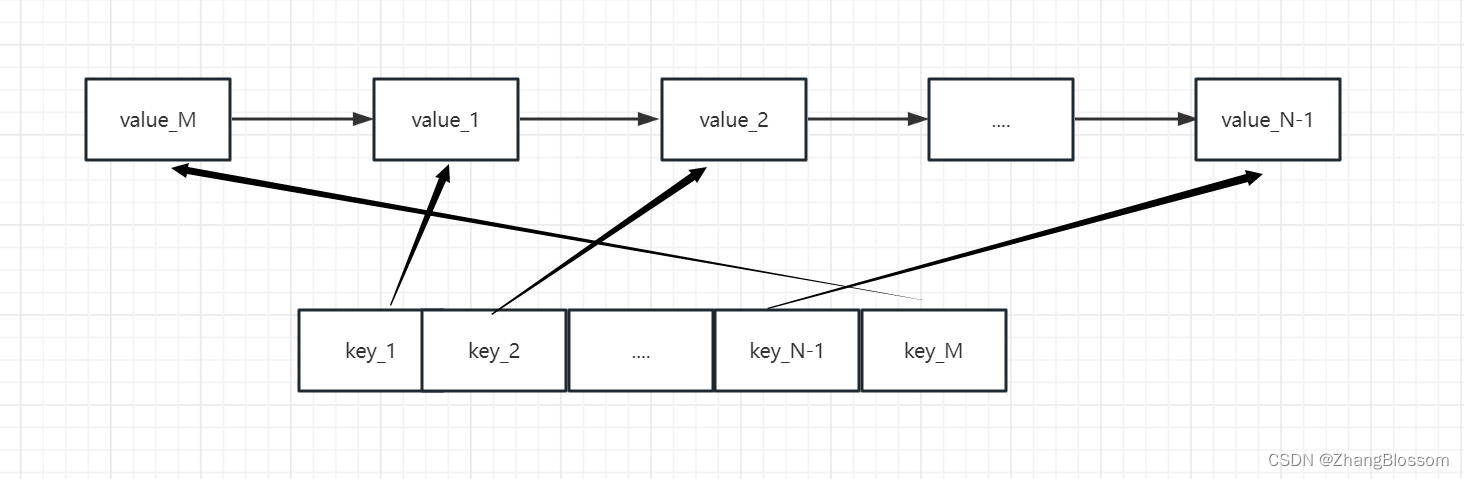
LruCache达到预设上限情况下的写操作,首先将链表尾部的缓存数据在映射表中的键值对删除,并删除链表尾部数据,再将新的数据正常写入到缓存中。下图是LruCache预设上限为N时,将数据M写入后的数据结构。
LruCache在DSP系统中的应用场景
在DSP系统中广泛应用键值存储数据库,例如使用Redis存储广告信息,服务可以通过广告ID获取广告信息。每次请求都从远端的键值存储数据库中获取广告信息,由于网络等一系列原因,请求耗时非常长(相对的)。
并且随着业务的增长,QPS的增多,将远程服务器上的缓存移动到本地作为本地缓存是解决这个问题的好办法。
另外服务本身的内存占用要稳定在一个安全的区间内。面对持续增长的广告信息,引入LruCache + 键值存储数据库的机制来达到提高系统性能,维持内存占用安全、稳定的目标。
LruCache+Redis
在较低QPS环境下,直接请求Redis获取广告信息,可以满足场景需求。但是随着单机QPS的增加,直接请求Redis获取广告信息,耗时也会增加,无法满足业务场景的需求。
引入LruCache,将远端存放于Redis的信息本地化存储。LruCache可以预设缓存上限,这个上限可以根据服务所在机器内存与服务本身内存占用来确定,确保增加LruCache后,服务本身内存占用在安全范围内;同时可以根据查询操作统计缓存数据在实际使用中的命中率。
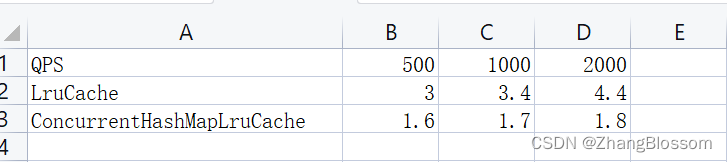
下图是增加LruCache结构前后,且增加LruCache后命中率高于90%的情况下,针对持续增长的QPS得出的数据获取平均耗时(ms)对比图:

上图可以发现,使用LruCache确实可以明显的提高QPS,但是我在使用中发现了一个比较严重的问题。
那就是,数据一致性问题。
增加LruCache数据过期清除机制
我们的广告并不是一成不变的,有些广告主会更新他们的广告,那么作为使用广告的服务方,如果Redis中的广告数据修改了,我们的服务是无法感知到数据的变化的。
当缓存的命中率较高或者部分数据在较长时间内多次命中,可能出现数据一致性的情况。即数据源发生了变化,但服务无法及时更新数据。针对这一业务场景,增加了数据过期清退机制。
过期清除机制的组成部分有三点:
1:设置缓存数据过期时间
2:缓存数据单元增加时间戳
3:查询时进行时效性判断。
缓存数据单元将数据进入LruCache的时间戳与数据一起缓存下来。缓存过期时间表示缓存单元缓存的时间上限。查询中的时效性判断表示查询时的时间戳与缓存时间戳的差值超过缓存过期时间,则强制将此数据清空,重新请求Redis获取数据做缓存。
在查询中做时效性判断可以最低程度的减少时效判断对服务的中断。当LruCache预设上限较低时,定期做全量数据清理对于服务本身影响较小。但如果LruCache的预设上限非常高,则一次全量数据清理耗时可能达到秒级甚至分钟级,将严重阻断服务本身的运行。所以将时效性判断加入到查询中,只对单一的缓存单元做时效性判断,在服务性能和数据有效性之间做了折中,满足业务需求。
ConcurrentHashMapLruCache
LruCache引入公司DSP系统后,在一段时间内较好地支持了业务的发展。随着业务的迭代,单机QPS持续上升。在更高QPS下,LruCache的查询耗时有了明显的提高,逐渐无法适应低平响的业务场景。在这种情况下,引入了ConcurrentHashMapLruCache机制以解决这个问题。
LruCache在高QPS下的耗时增加原因分析:
线程安全的LruCache中有锁的存在。每次读写操作之前都有加锁操作,完成读写操作之后还有解锁操作。在低QPS下,锁竞争的耗时基本可以忽略;但是在高QPS下,大量的时间消耗在了等待锁的操作上,导致耗时增长。
ConcurrentHashMapLruCache适应高QPS场景:
针对大量的同步等待操作导致耗时增加的情况,解决方案就是尽量减小临界区。
考虑到LruCache的底层是一个Map结构,并且考虑到细粒度锁,并且考虑到并发安全问题。
我马上想到的是用ConcurrentHashMap来完成上面的要求。
并且考虑到ConcurrentHashMap是会自动扩容的,这是不被我们允许的,所以
引入Hash机制,对全量数据做分片处理,在原有LruCache的基础上形成HashLruCache,以降低查询耗时。
ConcurrentHashMapLruCache依赖ConcurrentHashMap本身提供的hash机制以及并发安全机制,将广告信息按照其ID取模,然后分散到ConcurrentHashMap的桶上,其value信息就是广告信息,并且满足了线程安全问题。
下面是默认桶长度为16的ConcurrentHashMapLruCache耗时:
根据以上分析,进一步提高HashLruCache性能的一个方法是确定最合理的分片数量,增加足够的并行度,减少同步等待消耗。所以分片数量可以与CPU数量一致。由于超线程技术的使用,可以将分片数量进一步提高,增加并行性。
零拷贝机制
线程安全的LruCache内部维护一套数据。对外提供数据时,将对应的数据完整拷贝一份提供给调用方使用。如果存放结构简单的数据,拷贝操作的代价非常小,这一机制不会成为性能瓶颈。但是本公司DSP系统的应用场景中,LruCache中存放的数据结构非常复杂(我们的广告表大概有30+个字段),单次的拷贝操作代价很大,导致这一机制变成了性能瓶颈。
理想的情况是LruCache对外仅仅提供数据地址,即数据指针。使用方在业务需要使用的地方通过数据指针获取数据。这样可以将复杂的数据拷贝操作变为简单的地址拷贝,大量减少拷贝操作的性能消耗,即数据的零拷贝机制。直接的零拷贝机制存在安全隐患,即由于LruCache中的过期清除机制,可能会出现某一数据已经过期被删除,但是使用方仍然通过持有失效的数据指针来获取该数据。
进一步分析可以确定,以上问题的核心是存放于LruCache的数据生命周期对于使用方不透明。解决这一问题的方案是为LruCache中存放的数据添加原子变量的引用计数。使用原子变量不仅确保了引用计数的线程安全,使得各个线程读取的引用计数一致,同时保证了并发状态最小的同步性能开销。不论是LruCache中还是使用方,每次获取数据指针时,即将引用计数加1;同理,不再持有数据指针时,引用计数减1。当引用计数为0时,说明数据没有被任何使用方使用,且数据已经过期从LruCache中被删除。这时删除数据的操作是安全的。
源码
额,只能说,基于一些原因,就不开放源码了,到时候可能有机会我会写一个简易的demo。
敬请期待咯。
有兴趣可以看看我的其他项目咯,最好点个stars!
你的支持是我进步的最好动力!
动态线程池技术









![[RPC]:Feign远程调用](https://img-blog.csdnimg.cn/ace59a2cc4744a96bbda96c734b86821.png)
