HBase是一个分布式的、面向列的NoSQL数据库,可以存储大量的非结构化或半结构化的数据。tif是一种常见的影像文件格式,可以存储多波段的栅格数据。本文将介绍如何使用Python的happybase模块和gdal模块,从tif格式的影像文件中读取数据,并将其存储到HBase数据库中。
主要内容包括:
- 准备工作:安装Python环境,安装happybase模块和gdal模块,安装HBase数据库,并准备tif影像文件。
- 读取tif影像数据:使用readTif函数读取tif影像数据集,并获取其宽度、高度、波段数、数据数组、仿射变换参数和投影信息。遍历tif影像文件所在的文件夹,获取tif影像文件的日期和分块信息。
- 写入HBase数据库:创建一个happybase连接对象,并获取或创建一个happybase表对象。遍历每个分块,使用readTif函数读取每个分块的每个日期的每个波段的数据,并将其存储到一个三维的numpy数组中。遍历每个像素,将其对应的每个波段的每个日期的数据组合成一个字典,作为HBase表中的列值。使用分块编号、行号和列号拼接成一个字符串,作为HBase表中的行键。使用put方法将行键和列值写入HBase表中。关闭happybase连接对象。
一、准备工作
- 安装Python环境,本文使用的是Anaconda3。
- 安装happybase模块,可以使用pip或conda命令。例如:
pip install happybase
- 安装gdal模块,可以使用pip或conda命令。例如:
conda install gdal
- 启动分布式集群,hadoop以及hbase;启动thrift服务,可以使用hbase-daemon.sh脚本。例如:
hbase-daemon.sh start thrift
就可以使用happybase模块连接到thrift服务,并操作HBase数据库了
- 准备tif格式的影像文件,并放在一个文件夹中。本文使用的是Sentinel-2卫星的10个波段的影像数据,分为多个日期和多个分块。
二、读取tif影像数据
- 导入需要的模块,包括time、happybase、gdal、numpy、pandas、os和tqdm。例如:
import time
import happybase
from osgeo import gdal
import numpy as np
import pandas as pd
import os
from tqdm import tqdm
- 定义一个函数readTif,用于读取tif格式的影像数据集,并返回其宽度、高度、波段数、数据数组、仿射变换参数和投影信息。例如:
# 读取tif数据集
def readTif(fileName, xoff=0, yoff=0, data_width=0, data_height=0):
dataset = gdal.Open(fileName)
num_bands = dataset.RasterCount
# print(num_bands)
if dataset == None:
print(fileName + "文件无法打开")
# 栅格矩阵的列数
width = dataset.RasterXSize
# 栅格矩阵的行数
height = dataset.RasterYSize
# 波段数
bands = dataset.RasterCount
# 获取数据
if (data_width == 0 and data_height == 0):
data_width = width
data_height = height
data = dataset.ReadAsArray(xoff, yoff, data_width, data_height)
# 获取仿射矩阵信息
geotrans = dataset.GetGeoTransform()
# 获取投影信息
proj = dataset.GetProjection()
return width, height, bands, data, geotrans, proj
- 获取tif影像文件所在的文件夹路径,并遍历该文件夹下所有以.tif为后缀名的文件。例如:
# 分块影像所在文件夹,不能有中文
tifDir = r"E:\pyimg\tif2csv\S2SR10mallband3tile"
tifs = [i for i in os.listdir(tifDir) if i.endswith(".tif")]
print("有 %s 个tif文件" % len(tifs))

- 获取tif影像文件的日期和分块信息,并去重排序。例如:
# 获取目标文件数量,前缀相同的
bandlist=['B2','B3','B4','B5','B6','B7','B8','B8A','B11','B12']
datelist1 = []
fenkuailist1 = []
for i in tifs:
datelist1.append(i[:-26])
fenkuailist1.append(i[-25:-4])
datelist = list(set(datelist1))
datelist.sort(key=datelist1.index)
fenkuailist = list(set(fenkuailist1))
fenkuailist.sort(key=fenkuailist1.index)
print("有 %s 个日期" % len(datelist))
print("datelist" , datelist)
print("每个日期 %s 个块" % len(fenkuailist))
print("fenkuailist" , fenkuailist)
三、写入HBase数据库
- 创建一个happybase连接对象,并指定HBase数据库的IP地址。例如:
connection = happybase.Connection('192.168.1.100')
# # before first use:
connection.open()
- 获取或创建一个happybase表对象,并指定表名和列族名。例如:
table = connection.table('rawdata')
- 遍历每个分块,使用readTif函数读取每个分块的每个日期的每个波段的数据,并将其存储到一个三维的numpy数组中。例如:
#len(fenkuailist)
for kuai in range(1):
print("(%d/%d)块编号:"%(kuai+1,len(fenkuailist)),fenkuailist[kuai])
# 初始化立方体
img_file = tifDir + "\\" + datelist[0] + "-" + fenkuailist[kuai] + ".tif"
im_width, im_height, im_bands, im_data, kuai_im_geotrans, kuai_im_proj = readTif(img_file)
tmpttt = np.empty((im_bands, im_width * im_height, len(datelist)))
# print("波段 %s 个" % im_bands)
# print("行列数", im_width, im_height)
#len(datelist)
for shijian in range(len(datelist)):
# 图像
img_file = tifDir + "\\" + datelist[shijian] + "-" + fenkuailist[kuai] + ".tif"
# print(img_file)
im_width, im_height, im_bands, im_data, im_geotrans, im_proj = readTif(img_file)
kuai_im_geotrans = im_geotrans
kuai_im_proj=im_proj
for j in range(im_bands):
# print("jjjjjjjjjjjjjjjjjjjjj",im_data[j].flatten(order = 'C'))
tmpttt[j, :, shijian] = im_data[j].flatten(order='C')
- 遍历每个像素,将其对应的每个波段的每个日期的数据组合成一个字典,作为HBase表中的列值。使用分块编号、行号和列号拼接成一个字符串,作为HBase表中的行键。使用put方法将行键和列值写入HBase表中。例如:
print("写入中...")
print(tmpttt[1, 1, :])
#im_width * im_height
for index in tqdm(range(im_width * im_height)):
dt={}
for ban in range(im_bands):
d1=zip(map(lambda x:"f1:"+x+bandlist[ban],datelist),tmpttt[ban, index, :].astype(str))
# Converting zip object to dict using dict() contructor.
dt.update(d1)
# print (dict(dt))
key=str(kuai%3)+fenkuailist[kuai][6:10]+fenkuailist[kuai][-4:]+str(index)
# print(key)
table.put(key, dt) # 提交数据,0001代表行键,写入的数据要使用字典形式表示
- 关闭happybase连接对象。例如:
connection.close() # 关闭传输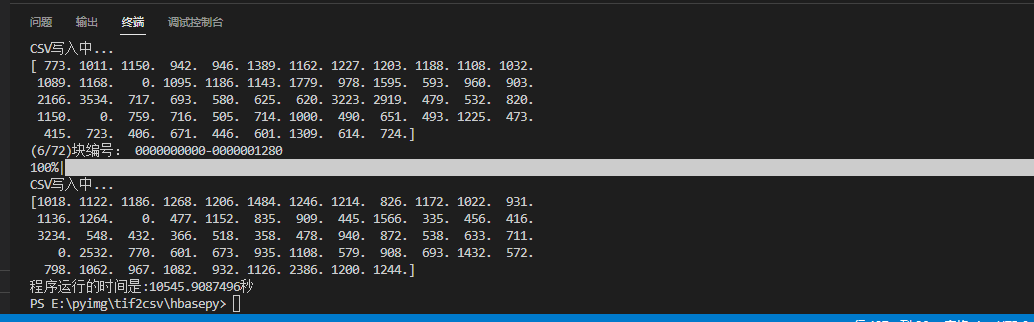
四、数据验证
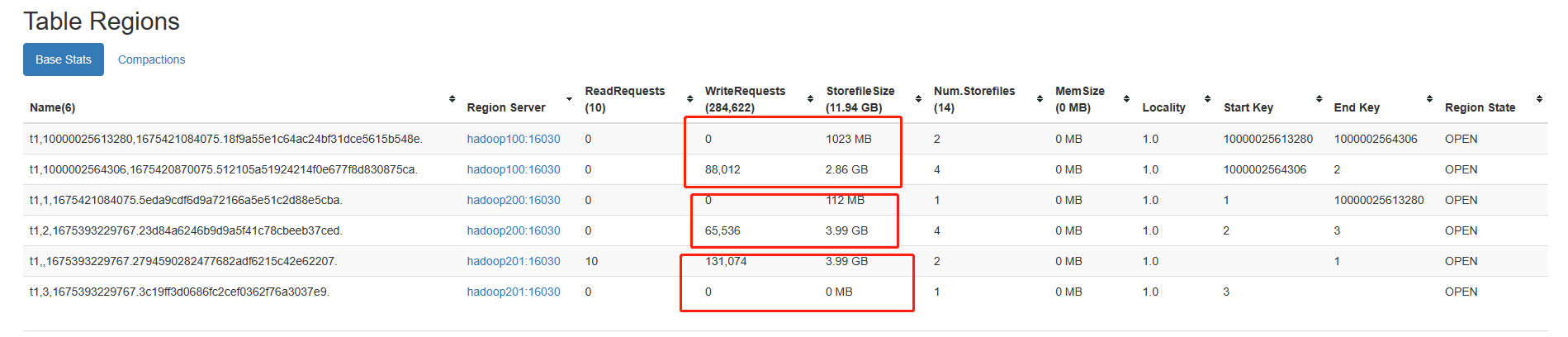
写入的表rawdata经过预分区,所以写入后数据较为均衡的分布在各个节点
- count命令
hbase shell中
count "rawdata"
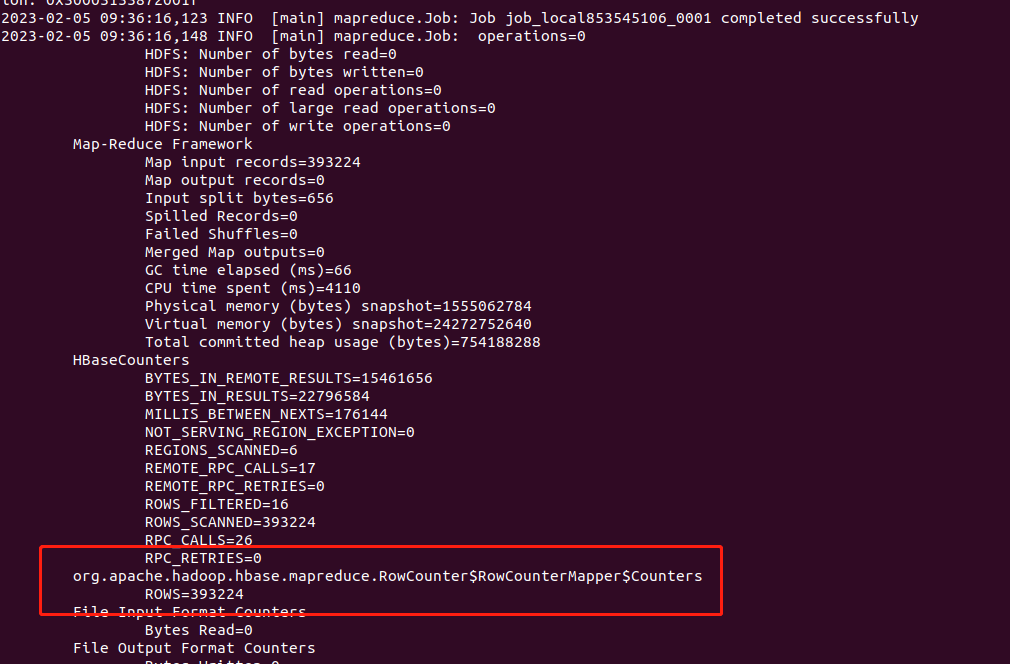
- 调用Mapreduce
具体内容根据环境配置调整
c914@hadoop100:/usr/local/hbase/bin$ ./hbase org.apache.hadoop.hbase.mapreduce.RowCounter 'rawdata'