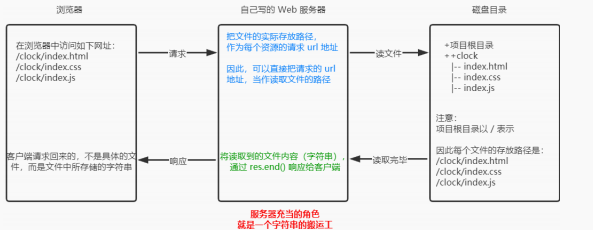
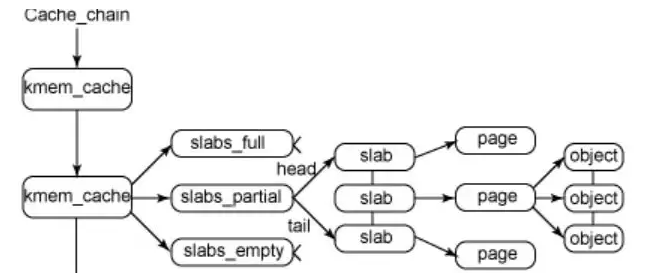
一、功能和参数
1.1、通过图像直观地理解 OneCycleLR 的过程:

补充:
生成该图像的代码:
来自:torch.optim.lr_scheduler.OneCycleLR用法_dxz_tust的博客-CSDN博客
import cv2
import torch.nn as nn
import torch
from torchvision.models import AlexNet
import matplotlib.pyplot as plt
#定义2分类网络
steps = []
lrs = []
# ## !!!!下面这一行如果感觉太慢,可以使用:model = torch.nn.Linear(2, 1) !!!!
model = AlexNet(num_classes=2)
# ------------------------------------------
lr = 0.1
optimizer = torch.optim.SGD(model.parameters(), lr=lr, momentum=0.9)
#total_steps:总的batch数,这个参数设置后就不用设置epochs和steps_per_epoch,anneal_strategy 默认是"cos"方式,当然也可以选择"linear"
#注意,这里的max_lr和你优化器中的lr并不是同一个
#注意,无论你optim中的lr设置是啥,最后起作用的还是max_lr
scheduler =torch.optim.lr_scheduler.OneCycleLR(optimizer,max_lr=0.9,total_steps=100, verbose=True)
# ------------------------------------------
for epoch in range(10):
for batch in range(10):
scheduler.step()
lrs.append(scheduler.get_lr()[0])
steps.append(epoch*10+batch)
plt.figure()
plt.legend()
plt.plot(steps, lrs, label='OneCycle')
plt.savefig("dd.png")
1.2、参数介绍
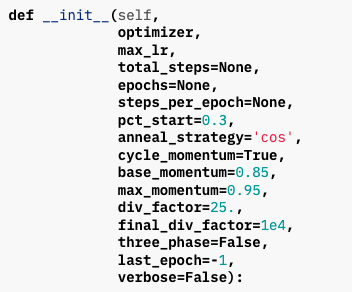
上图中的值,就是参数的默认值。
详细介绍:(英文挺容易理解,就不再翻译了。)
optimizer (Optimizer): Wrapped optimizer.
max_lr (float or list): Upper learning rate boundaries in the cycle
for each parameter group.
total_steps (int): The total number of steps in the cycle. Note that
if a value is not provided here, then it must be inferred by providing
a value for epochs and steps_per_epoch.
Default: None
epochs (int): The number of epochs to train for. This is used along
with steps_per_epoch in order to infer the total number of steps in the cycle
if a value for total_steps is not provided.
Default: None
steps_per_epoch (int): The number of steps per epoch to train for. This is
used along with epochs in order to infer the total number of steps in the
cycle if a value for total_steps is not provided.
Default: None
pct_start (float): The percentage of the cycle (in number of steps) spent
increasing the learning rate.
Default: 0.3
anneal_strategy (str): {'cos', 'linear'}
Specifies the annealing strategy: "cos" for cosine annealing(退火), "linear" for
linear annealing(退火).
Default: 'cos'
cycle_momentum (bool): If ``True``, momentum is cycled inversely(相反地)
to learning rate between 'base_momentum' and 'max_momentum'.
Default: True
base_momentum (float or list): Lower momentum boundaries in the cycle
for each parameter group. Note that momentum is cycled inversely
to learning rate; at the peak of a cycle, momentum is
'base_momentum' and learning rate is 'max_lr'.
Default: 0.85
max_momentum (float or list): Upper momentum boundaries in the cycle
for each parameter group. Functionally,
it defines the cycle amplitude(振幅) (max_momentum - base_momentum).
Note that momentum is cycled inversely
to learning rate; at the start of a cycle, momentum is 'max_momentum'
and learning rate is 'base_lr'
Default: 0.95
div_factor (float): Determines the initial learning rate via
initial_lr = max_lr/div_factor
Default: 25
final_div_factor (float): Determines the minimum learning rate via
min_lr = initial_lr/final_div_factor (可以看出,最终的lr是非常非常小的)
Default: 1e4
three_phase (bool): If ``True``, use a third phase of the schedule to annihilate(消灭) the
learning rate according to 'final_div_factor' instead of modifying the second
phase (the first two phases will be symmetrical about the step indicated by
'pct_start').Default: False
last_epoch (int): The index of the last batch. This parameter is used when
resuming a training job. Since `step()` should be invoked after each
batch instead of after each epoch, this number represents the total
number of *batches* computed, not the total number of epochs computed.(这句话的意思是:last_epoch表示已经训练了多少个batches,而不是训练了多少个epochs)
When last_epoch=-1, the schedule is started from the beginning.
Default: -1
verbose (bool): If ``True``, prints a message to stdout for
each update. Default: ``False``.
关于参数我的一些理解:
- optimizer 学习率是要在优化器中使用的。这个参数就是用于指定这个学习率用于哪个优化器。根据我的观察,其实就是给optimizer加了一个调整学习率的HOOK
- max_lr 就是【1.1、】图的上界;
- total_steps 或者 (epochs + steps_per_epoch)二者必须设置其中一个(官方文档:You must either provide a value for total_steps or provide a value for both epochs and steps_per_epoch.),原因是计算每一步的学习率需要用到 total_steps 。通过(epochs + steps_per_epoch)可以计算出total_steps(total_steps = epochs * steps_per_epoch);
- pct_start 表示【1.1、】图的上升阶段占 total_steps 的比例;
- anneal_strategy 表示【1.1、】途中下降阶段的策略:cos、linear;
- cycle_momentum 这个不怎么理解,直接使用默认值就可以了
- max_momentum 这个也不怎么理解,使用默认值就可以了;关于单词“inversely”的含义可以参考其中标红的部分
- div_factor 确定初始学习率,即【1.1、】图最左侧的起点,使用默认值就可以
- final_div_factor 确定最终的学习率,即【1.1、】图最右侧的终点,使用默认值就可以
- three_phase 这个后面单独细讲
- last_epoch 看英语解释就可以,比较容易理解
- verbose 看英语解释就可以,比较容易理解
1.2.1、关于参数 three_phase 的介绍
【1.1、】中图只有上升和下降两个阶段。将【1.1、】图的代码增加 three_phase=True 参数后,
scheduler =torch.optim.lr_scheduler.OneCycleLR(optimizer,total_steps=100,max_lr=0.9,three_phase=True)其图像会变成下面这样:
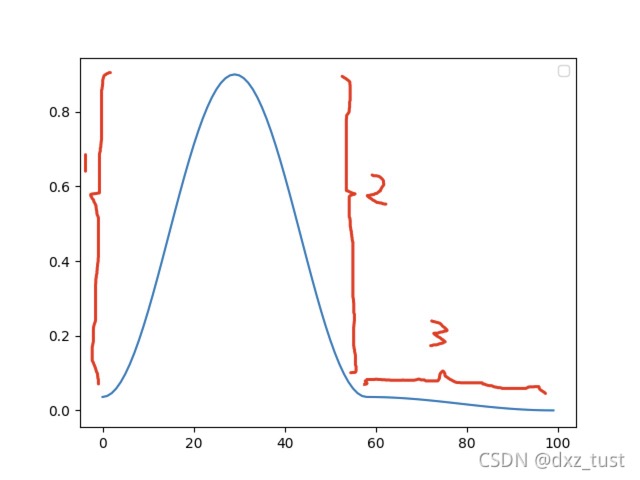
整个图将分为3个部分:①上升阶段,②第一个下降阶段,③第二个下降阶段
并且:① 和 ② 是对称的。
①和②在total_steps中的占比都是pct_start。所以pct_start如果大于等于0.5,那么即使设置了tree_phase参数,也不会出现③这个阶段。
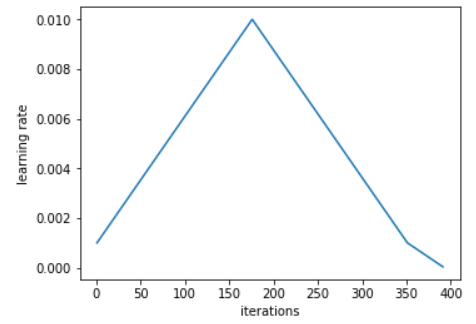
补充:如果上升和下降都采用线性(linear)的方法,图像会类似于下图:
(来自:侵权立删)
1.2.2、three_phase 对训练效果影响的注意点
官方有这么一句话:The default behaviour of this scheduler follows the fastai implementation of 1cycle, which claims that "unpublished work has shown even better results by using only two phases". To mimic the behaviour of the original paper instead, set ``three_phase=True``.
即,论文中的 OneCycleLR() 是三阶段的,但是有人验证过了,三阶段的训练效果没有二阶段的训练效果好。所以直接使用默认值 False 更好一些。
1.3、官方的使用例子
data_loader = torch.utils.data.DataLoader(...)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
scheduler = torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr=0.01, steps_per_epoch=len(data_loader), epochs=10)
for epoch in range(10):
for batch in data_loader:
train_batch(...)
scheduler.step()二、一个可以直接使用的OneCycleLR配置
scheduler = torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr=0.01, total_steps=100)three_phase 使用默认值(False)效果更好。