参考:
参考:
https://github.com/ultralytics/ultralytics
https://github.com/TommyZihao/Train_Custom_Dataset/blob/main/%E7%9B%AE%E6%A0%87%E8%BF%BD%E8%B8%AA/%E5%85%AC%E5%BC%80%E8%AF%BE/
https://www.rstk.cn/news/42041.html?action=onClick
*** 跟踪与检测都是用的YOLOv8目标检测一样的权重
1、命令行运行
视频下载:
人流量视频:
https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20220418-mmtracking/data/mot_people_short.mp4
车流量视频:
https://zihao-openmmlab.obs.cn-east-3.myhuaweicloud.com/20230502-YOLO/videos/bridge-short.mp4
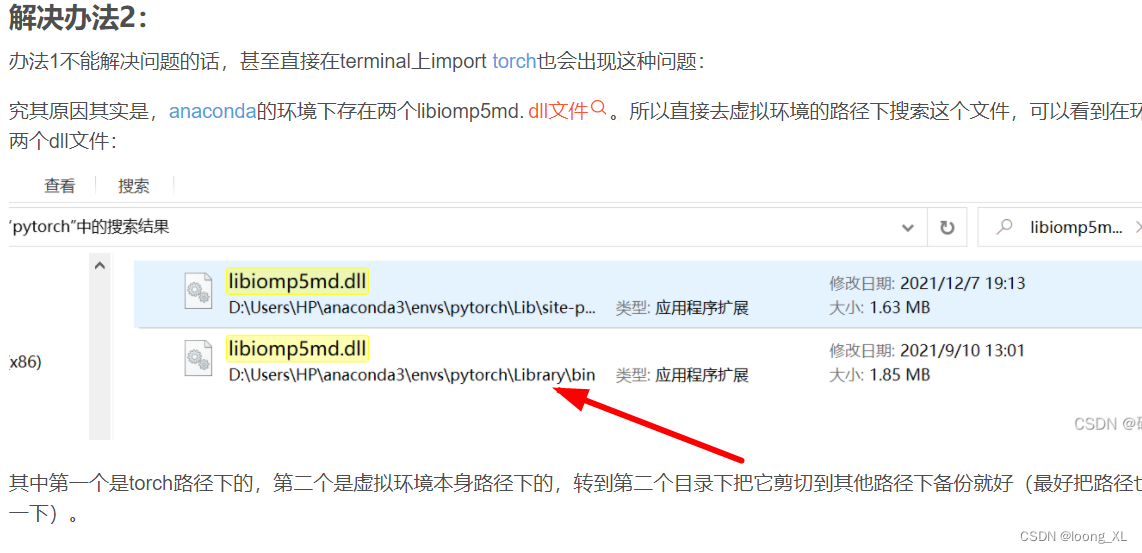
可能出现报错OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
解决方法参考:https://blog.csdn.net/qq_37164776/article/details/126832303
需要去env环境里把其中一个删除再运行
##检测
yolo detect predict model=C:\Users\lonng\Downloads\yolov8s.pt source=bus.jpg ##图片
yolo detect predict model=C:\Users\lonng\Downloads\yolov8s.pt source=C:\Users\lonng\Desktop\rdkit_learn\opencv2\videos\bridge-short.mp4 show=True save=True ##视频
##调摄像头
yolo detect predict model=C:\Users\lonng\Downloads\yolov8s.pt source=0 show=True

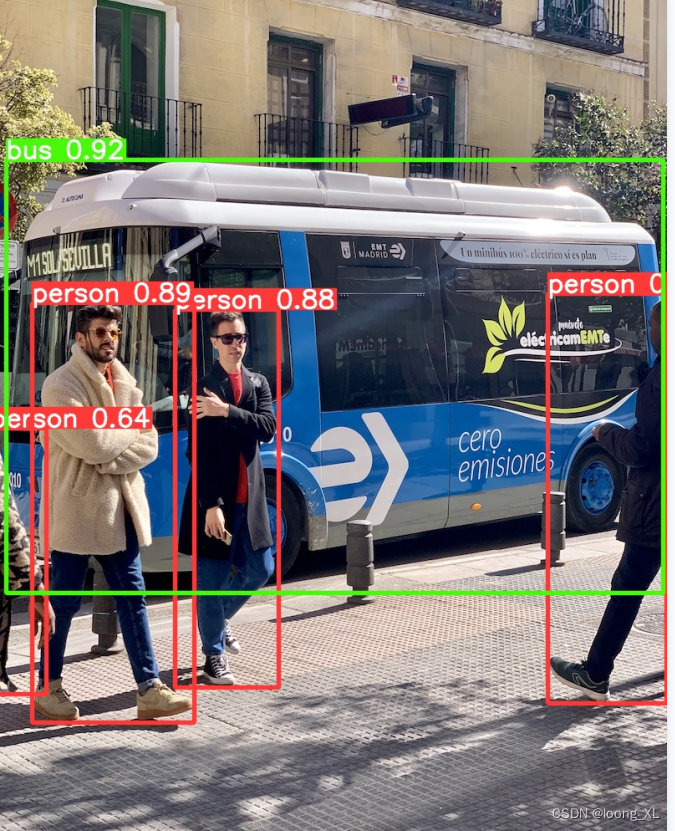
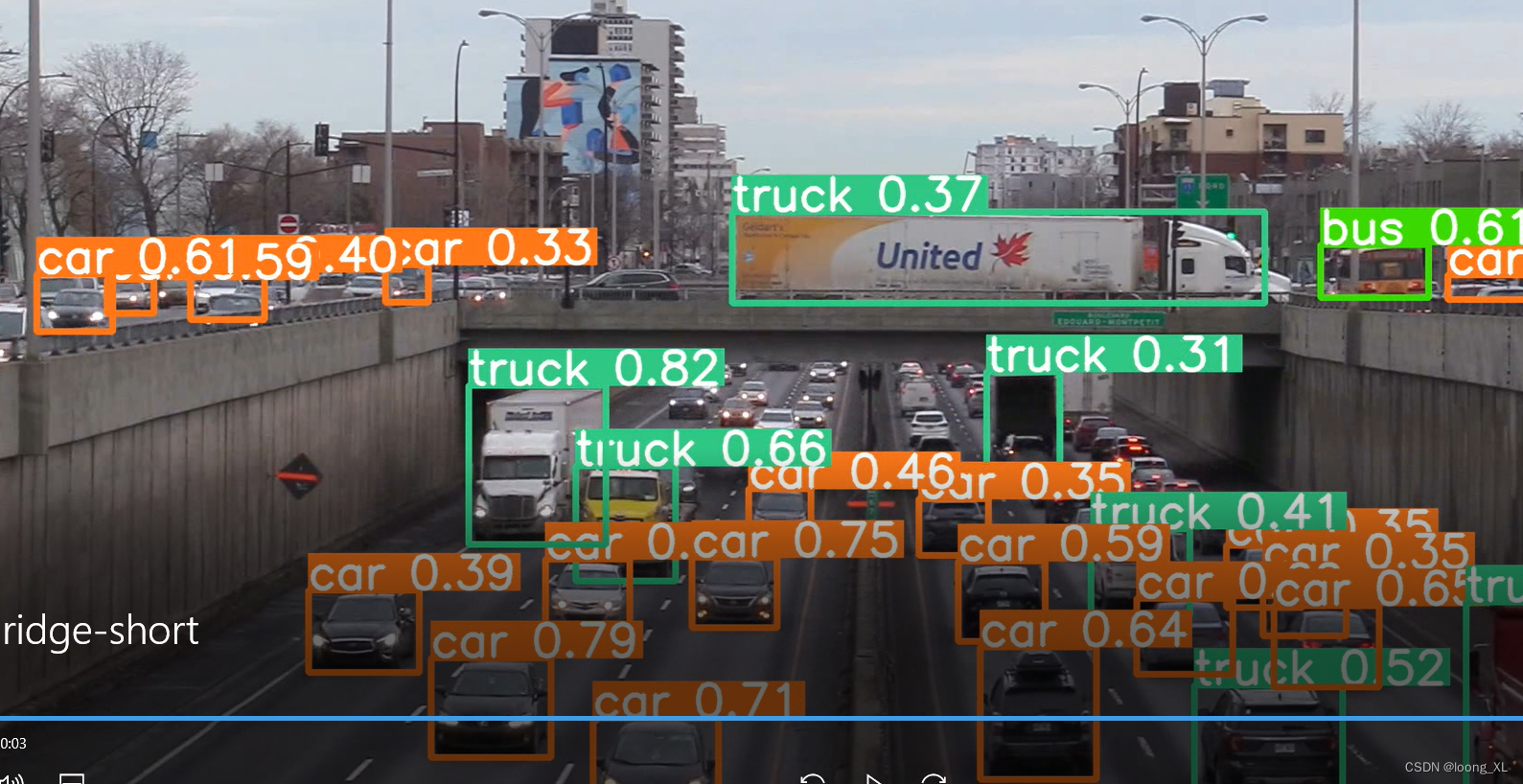
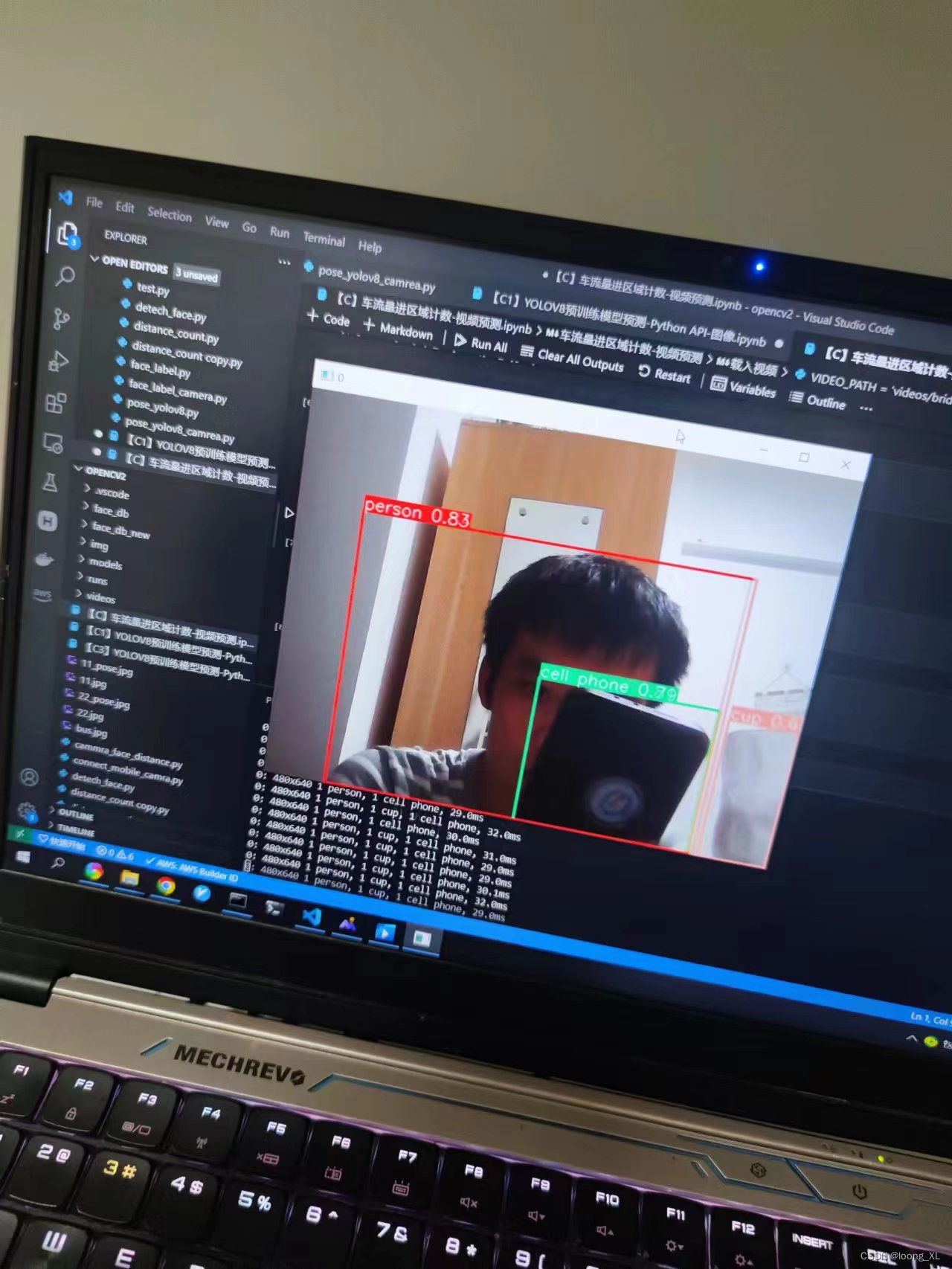
注意:跟踪命令行没有predict,只有track
##跟踪,文件路径不需要加引号
yolo track model=C:\Users\lonng\Downloads\yolov8s.pt source=C:\Users\lonng\Desktop\rdkit_learn\opencv2\videos\mot_people_short.mp4 show=True save=True
yolo track model=C:\Users\lonng\Downloads\yolov8s.pt source=0 show=True ##摄像头
运行解释会保存到runs目录下


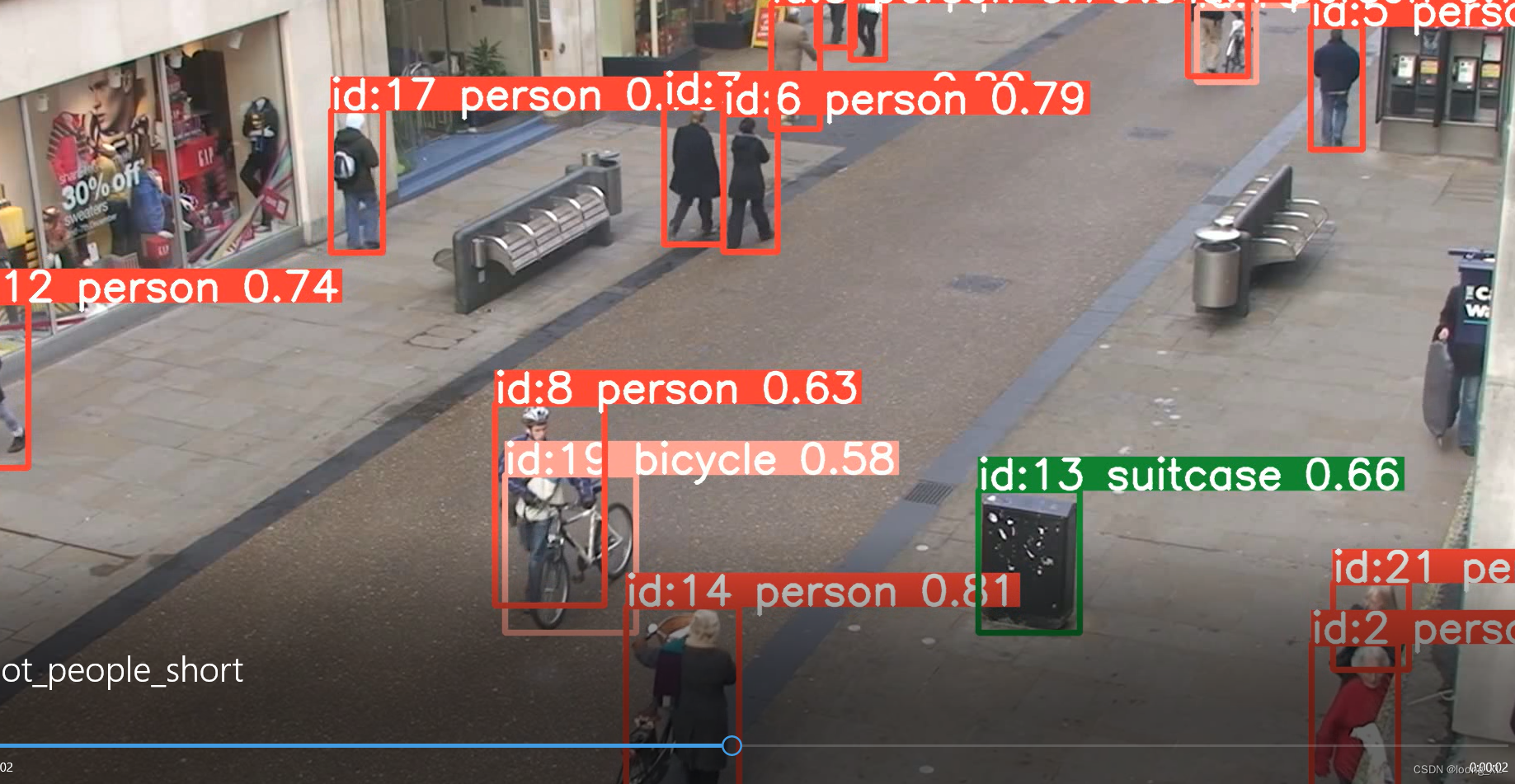

2、python代码运行
跟踪完整代码:
import time
from tqdm import tqdm
import cv2
import numpy as np
from ultralytics import YOLO
import supervision as sv
model = YOLO(r'C:\Users\lonng\Downloads\yolov8s.pt')
VIDEO_PATH = 'videos/bridge-short.mp4'
##指定统计区域
polygons = [
np.array([[600, 680], [927, 680], [851, 950], [42, 950]]),
np.array([[987, 680], [1350, 680], [1893, 950], [1015, 950]])
]
zones = [sv.PolygonZone(polygon=polygon, frame_resolution_wh=video_info.resolution_wh) for polygon in polygons]
# 配色方案
colors = sv.ColorPalette.default()
# 区域可视化,每个区域配一个 PolygonZoneAnnotator
zone_annotators = [
sv.PolygonZoneAnnotator(zone=zone, color=colors.by_idx(index), thickness=6, text_thickness=12, text_scale=4)
for index, zone in enumerate(zones)
]
# 目标检测可视化,每个区域配一个 BoxAnnotator
box_annotators = [
sv.BoxAnnotator(color=colors.by_idx(index), thickness=2, text_thickness=4, text_scale=2)
for index in range(len(polygons))
]
##每帧处理
def process_frame(frame: np.ndarray, i) -> np.ndarray:
'''
输入 bgr 的 numpy array
输出 bgr 的 numpy array
'''
# YOLOV8 推理预测
results = model(frame, imgsz=1280, verbose=False, show=False, device='cuda:0')[0]
# 用 supervision 解析预测结果
detections = sv.Detections.from_yolov8(results)
# 遍历每个区域对应的所有 Annotator
for zone, zone_annotator, box_annotator in zip(zones, zone_annotators, box_annotators):
# 判断目标是否在区域内
mask = zone.trigger(detections=detections)
# 筛选出在区域内的目标
detections_filtered = detections[mask]
# 画框
frame = box_annotator.annotate(scene=frame, detections=detections_filtered, skip_label=True)
# 画区域,并写区域内目标个数
frame = zone_annotator.annotate(scene=frame)
# 更新进度条
pbar.update(1)
return frame
## 视频每帧预测
filehead = VIDEO_PATH.split('/')[-1]
OUT_PATH = "out-" + filehead
with tqdm(total=video_info.total_frames-1) as pbar:
sv.process_video(source_path=VIDEO_PATH, target_path=OUT_PATH, callback=process_frame)
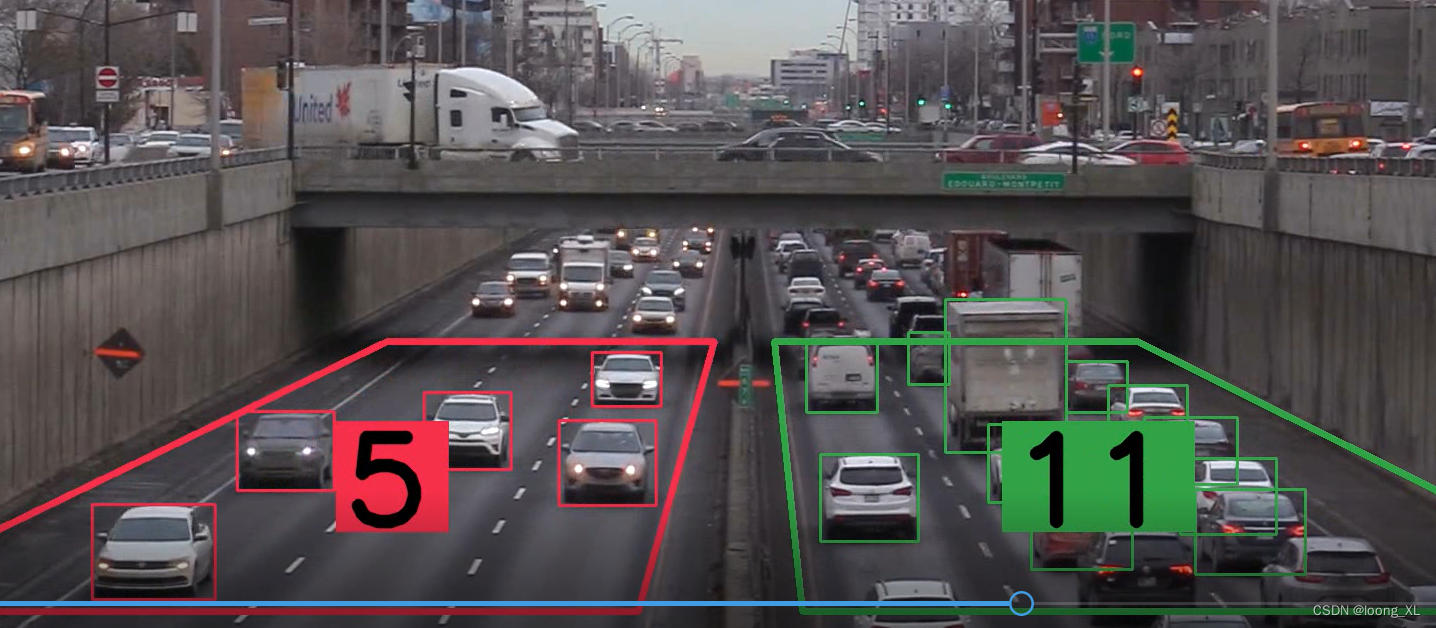
out-bridge-short