文章目录
- 🐾1. 索引🐾
- 💐1.1 概念💐
- 🌸1.2 作用与缺点🌸
- 🌷1.2.1作用🌷
- 🍀1.2.2缺点🍀
- 🌹1.3 使用场景🌹
- 🌻1.4 使用🌻
- 🌺1.4.1查看索引🌺
- 🍁1.4.2创建索引🍁
- 🍃1.4.3删除索引🍃
- 🍂1.5 B树和B+树(经典面试题)🍂
- 🌿1.5.1 B树🌿
- 🍄1.5.2 B+树🍄
- 🌵1.5.3如果表中有多个索引?🌵
- 🌴1.6MySQL数据组织的方式🌴
- 🌲1.7 案例🌲
- 🌰2. 事务🌰
- 🌱2.1 为什么使用事务🌱
- 🌼2.2 事务的概念🌼
- 🌾2.3 使用🌾
- 🌋2.4事务的特性🌋
- 🌌2.5事务的问题总结🌌
- ⛅️3. 内容重点总结⛅️
大家好,我是晓星航。今天为大家带来的是 MySQL索引事务 相关的讲解!😀
🐾1. 索引🐾
💐1.1 概念💐
索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。可以对表中的一列或多列创建索引,并指定索引的类型,各类索引有各自的数据结构实现。
🌸1.2 作用与缺点🌸
🌷1.2.1作用🌷
- 数据库中的表、数据、索引之间的关系,类似于书架上的图书、书籍内容和书籍目录的关系。
- 索引所起的作用类似书籍目录,可用于快速定位、检索数据。
- 索引对于提高数据库的性能有很大的帮助。
🍀1.2.2缺点🍀
1.需要付出额外的空间代价来保存索引数据
2.索引可能会拖慢新增,删除,修改的速度
整体来说,还是认为索引是利大于弊的,实际开发中,查询场景一般要比增删查改频率高很多!!!
🌹1.3 使用场景🌹
要考虑对数据库表的某列或某几列创建索引,需要考虑以下几点:
- 数据量较大,且经常对这些列进行条件查询。
- 该数据库表的插入操作,及对这些列的修改操作频率较低。
- 索引会占用额外的磁盘空间。
满足以上条件时,考虑对表中的这些字段创建索引,以提高查询效率。
反之,如果非条件查询列,或经常做插入、修改操作,或磁盘空间不足时,不考虑创建索引。
🌻1.4 使用🌻
创建主键约束(PRIMARY KEY)、唯一约束(UNIQUE)、外键约束(FOREIGN KEY)时,会自动创建对应列的索引。
🌺1.4.1查看索引🌺
- 查看索引
show index from 表名;
案例:查看学生表已有的索引
show index from student;

把表中的内容,根据 name 又搞了一份目录出来
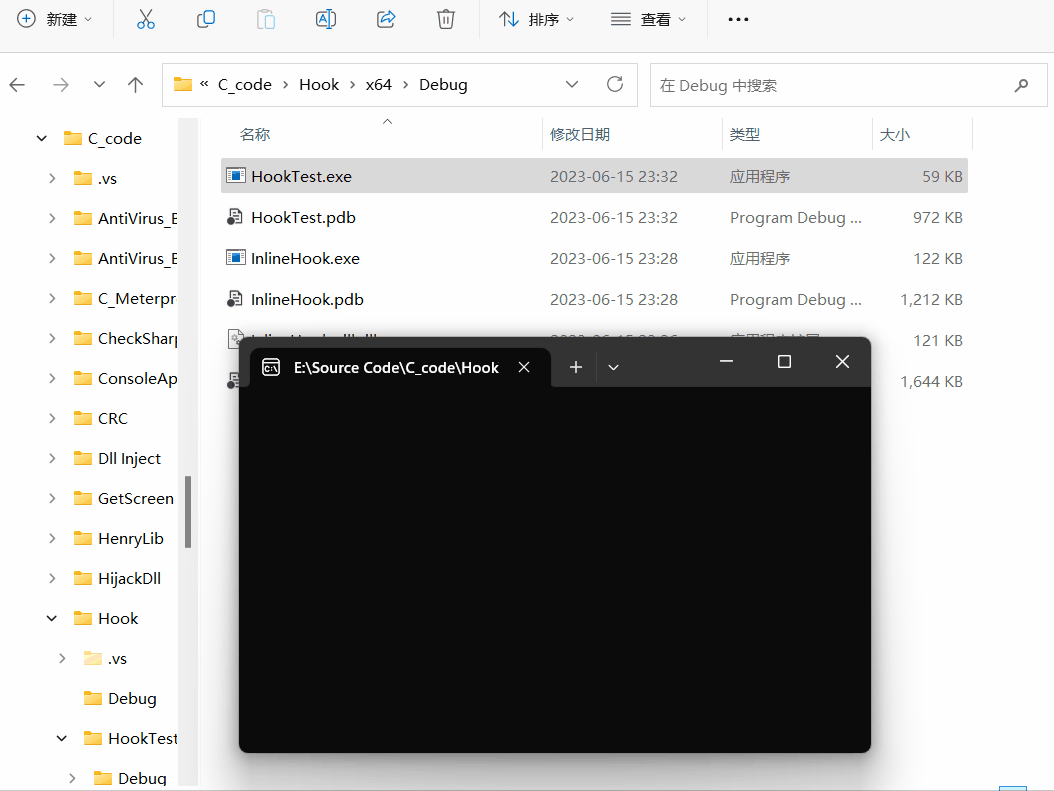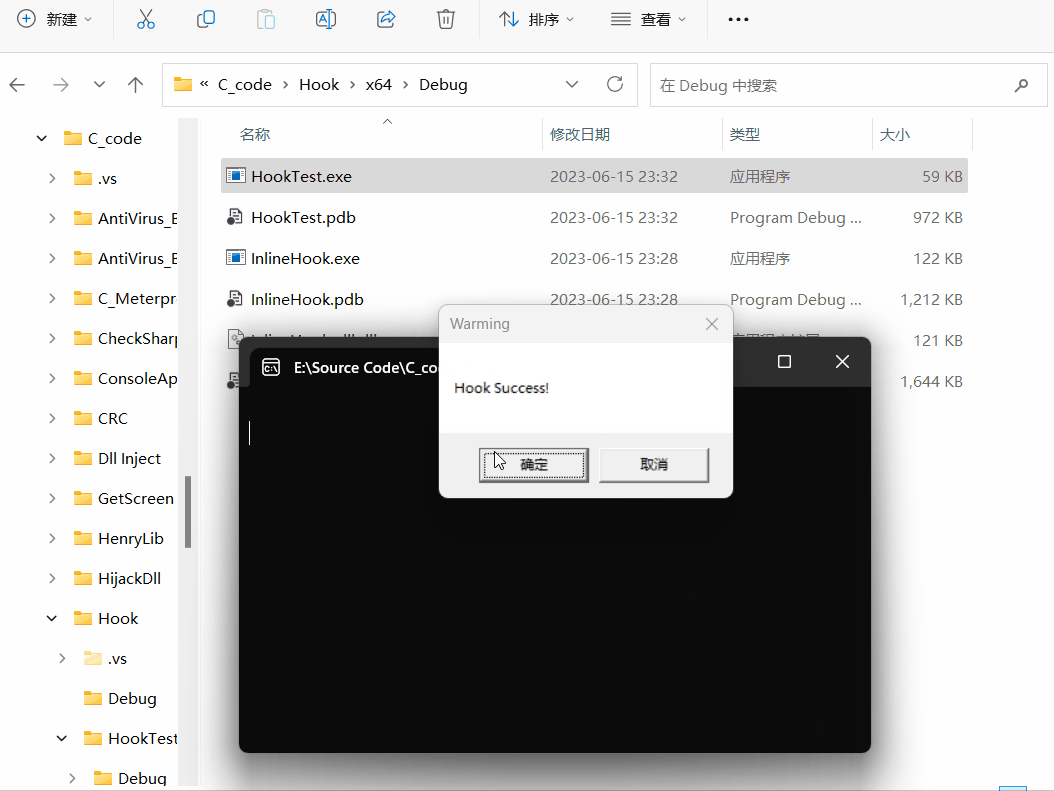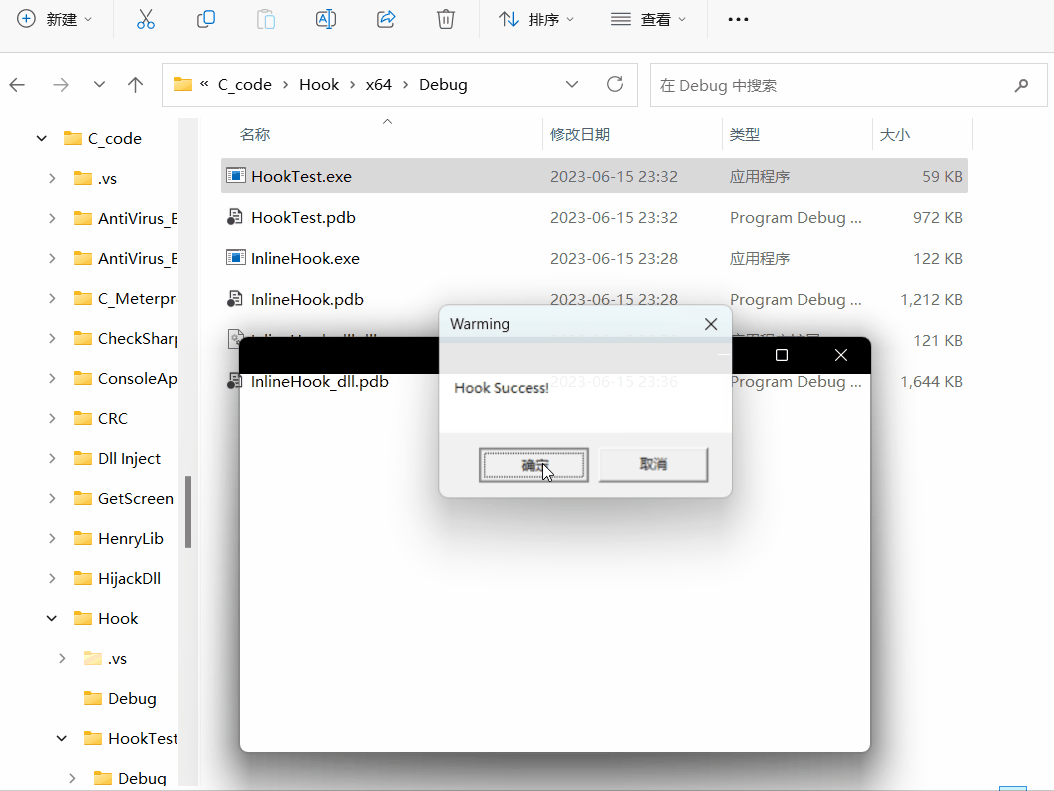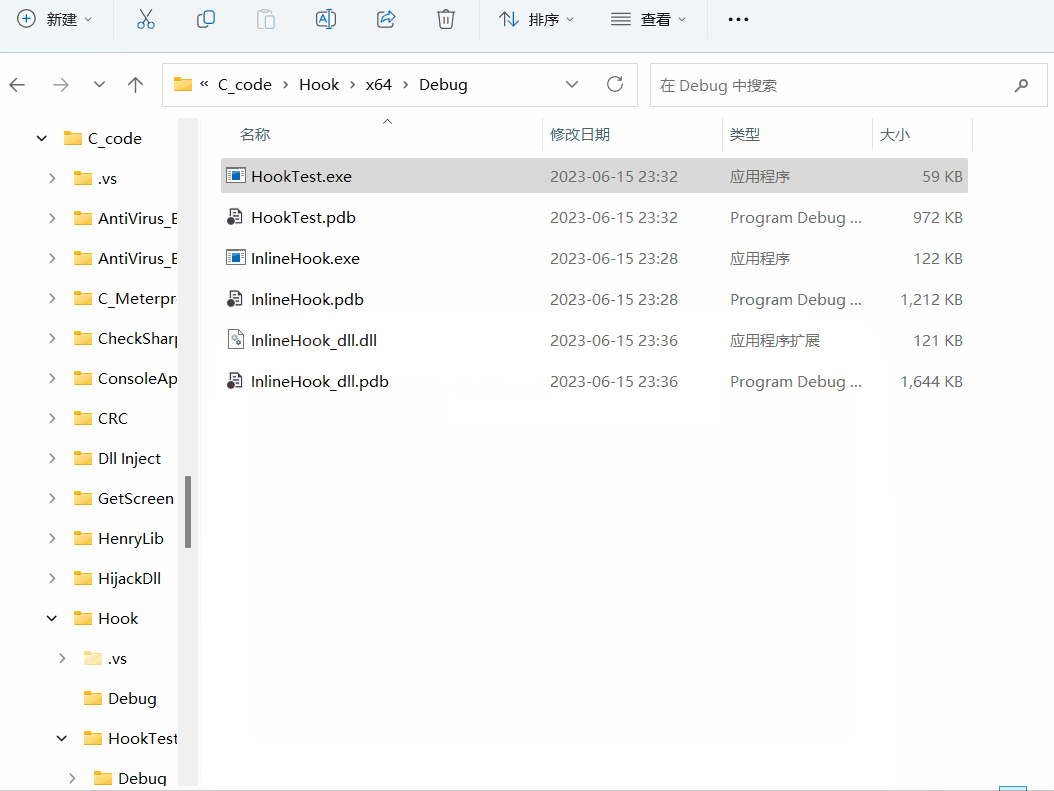
🍁1.4.2创建索引🍁
创建索引操作,可能很危险!!!
如果表里的数据很大,这个建立索引的开销也会很大!!!
有一本很厚的书,现在让你给这本书手动写一份目录出来,那么就会很慢很麻烦
那么针对以上情况我们有没有好的解决方法呢?
答案是有的,那就是在创建表之初,就把索引设定好,如果表里已经有很多数据了,索引就不要动了!!!
- 创建索引
对于非主键、非唯一约束、非外键的字段,可以创建普通索引
create index 索引名 on 表名(字段名);
案例:创建班级表中,name字段的索引
create index idx_classes_name on classes(name);

🍃1.4.3删除索引🍃
- 删除索引
drop index 索引名 on 表名;
案例:删除班级表中name字段的索引
drop index idx_classes_name on classes;

🍂1.5 B树和B+树(经典面试题)🍂
🌿1.5.1 B树🌿
B树左右数值没有特定要求,只需要在规定范围之间即可:

当节点的子树多了,节点上保存的 key 就多了。意味着在同样 key 的个数的前提下 B 树的高度就要比 二叉搜索树 低很多!!!
树的高度越高,进行查询比较的时候,访问磁盘的次数就越多!!!
🍄1.5.2 B+树🍄
B+树子树生成的左侧数据只需要大于最小值和小于最大值就行,但是最右数据必须为最大值的那个数据。

整个树的所有数据都是包含在 叶子 节点中的!!!(所有非叶子节点中的 key 最终都会出现在叶子节点中)
B+树特点:
- 一个节点,可以储存 N 个 key 划分出了 N 个区间 (而不是 N + 1 个区间)
- 每个节点中的 key 值,都会在子节点中也存在 (同时该 key 是子节点的最大值)
- B+树的叶子节点,是首尾相连的,类似于一个链表
- 由于叶子节点,是完整的数据集合,只在叶子节点这里存储数据表的每一行的数据。而 非叶子节点 ,只存 key 值本身即可
B+树的优势:
- 当前一个节点保存更多的 key ,最终树的高度是相对更矮的。查询的时候减少了 IO 访问次数。(和B树一样)
- 所有的查询最终都会落到叶子节点上。(查询任何一个数据,经过的 IO 访问次数,是一样的,次数是更稳定的)
- B+树的所有的叶子节点,构成链表,比较方便进行一个范围查询
例如找一个 学号>5 并且 <11的同学
只需要先找到 5 所在位置,再找到 11 所在位置
从 5 沿着链表遍历到 11 ,中间结果即为所求。
非常方便,非常高效

- 由于数据都在叶子节点上,非叶子节点只存储 key ,导致非叶子节点占用空间是比较小的。这些非叶子节点就可能在内存中缓存(或者是缓存一部分)。又进一步减少了 IO 的次数。
注:这里的 IO 特指硬盘的访问。 I–>input(输入) O–>output(输出)
🌵1.5.3如果表中有多个索引?🌵
针对 id 有主键索引
针对 name 又有一个索引
表的数据还是按照 id 为主键,构建出 B+ 树通过叶子节点组织所有的数据行。
其次,针对 name 这一列,会构建另外一个 B+ 树,但是这个 B+树 的叶子节点就不再储存这一行的完整数据,而是存主键 id 是啥
此时,如果你根据 name 来查询,查到叶子节点的得到的只是 主键 id,还需要再通过主键 id 去主键的 B+树 里再查一次。(查两次B+树)
[上述过程称为 “回表” ,这个过程,都是 mysql 自动完成的,用户感知不到]
🌴1.6MySQL数据组织的方式🌴
当你看到一张 “表” 的时候,实际上这个表不一定就是按照 “表格” 这样的数据结构在硬盘上组织的,也有可能是按照这种树形结构组织。(具体是哪种结构,取决于你的表里有没有索引,以及数据库使用了哪种存储引擎)
🌲1.7 案例🌲
准备测试表:
-- 创建用户表
DROP TABLE IF EXISTS test_user;
CREATE TABLE test_user (
id_number INT,
name VARCHAR(20) comment '姓名',
age INT comment '年龄',
create_time timestamp comment '创建日期'
);
准备测试数据,批量插入用户数据(操作耗时较长,约在1小时+):
-- 构建一个8000000条记录的数据
-- 构建的海量表数据需要有差异性,所以使用存储过程来创建, 拷贝下面代码就可以了,暂时不用理解
-- 产生名字
drop function if exists rand_name;
delimiter $$
create function rand_name(n INT, l INT)
returns varchar(255)
begin
declare return_str varchar(255) default '';
declare i int default 0;
while i < n do
if i=0 then
set return_str = rand_string(l);
else
set return_str =concat(return_str,concat(' ', rand_string(l)));
end if;
set i = i + 1;
end while;
return return_str;
end $$
delimiter ;
-- 产生随机字符串
drop function if exists rand_string;
delimiter $$
create function rand_string(n INT)
returns varchar(255)
begin
declare lower_str varchar(100) default
'abcdefghijklmnopqrstuvwxyz';
declare upper_str varchar(100) default
'ABCDEFJHIJKLMNOPQRSTUVWXYZ';
declare return_str varchar(255) default '';
declare i int default 0;
declare tmp int default 5+rand_num(n);
while i < tmp do
if i=0 then
set return_str
=concat(return_str,substring(upper_str,floor(1+rand()*26),1));
else
set return_str
=concat(return_str,substring(lower_str,floor(1+rand()*26),1));
end if;
set i = i + 1;
end while;
return return_str;
end $$
delimiter ;
-- 产生随机数字
drop function if exists rand_num;
delimiter $$
create function rand_num(n int)
returns int(5)
begin
declare i int default 0;
set i = floor(rand()*n);
return i;
end $$
delimiter ;
-- 向用户表批量添加数据
drop procedure if exists insert_user;
delimiter $$
create procedure insert_user(in start int(10),in max_num int(10))
begin
declare i int default 0;
set autocommit = 0;
repeat
set i = i + 1;
insert into test_user values ((start+i) ,rand_name(2,
5),rand_num(120),CURRENT_TIMESTAMP);
until i = max_num
end repeat;
commit;
end $$
delimiter ;
-- 执行存储过程,添加8000000条用户记录
call insert_user(1, 8000000);
查询 id_number 为778899的用户信息:
-- 可以看到耗时4.93秒,这还是在本机一个人来操作,在实际项目中,如果放在公网中,假如同时有1000
个人并发查询,那很可能就死机。
select * from test_user where id_number=556677;

可以使用explain来进行查看SQL的执行:
explain select * from test_user where id_number=556677;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test_user
type: ALL
possible_keys: NULL
key: NULL <== key为null表示没有用到索引
key_len: NULL
ref: NULL
rows: 6
Extra: Using where
1 row in set (0.00 sec)
为提供查询速度,创建 id_number 字段的索引:
create index idx_test_user_id_number on test_user(id_number);
换一个身份证号查询,并比较执行时间:
select * from test_user where id_number=776655;
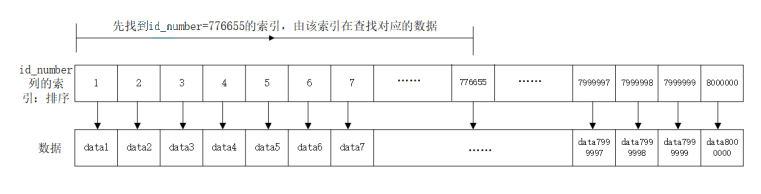
可以使用explain来进行查看SQL的执行:
explain select * from test_user where id_number=776655;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test_user
type: ref
possible_keys: idx_test_user_id_number
key: idx_test_user_id_number <= key用到了idx_test_user_id_number
key_len: NULL
ref: const
rows: 1
Extra: Using where
1 row in set (0.00 sec)
索引保存的数据结构主要为B+树,及hash的方式,实现原理会在以后数据库原理的部分讲解。

🌰2. 事务🌰
🌱2.1 为什么使用事务🌱
准备测试表:
drop table if exists accout;
create table accout(
id int primary key auto_increment,
name varchar(20) comment '账户名称',
money decimal(11,2) comment '金额'
);
insert into accout(name, money) values
('阿里巴巴', 5000),
('四十大盗', 1000);
比如说,四十大盗把从阿里巴巴的账户上偷盗了2000元
-- 阿里巴巴账户减少2000
update accout set money=money-2000 where name = '阿里巴巴';
-- 四十大盗账户增加2000
update accout set money=money+2000 where name = '四十大盗';
假如在执行以上第一句SQL时,出现网络错误,或是数据库挂掉了,阿里巴巴的账户会减少2000,但是四十大盗的账户上就没有了增加的金额。
解决方案:使用事务来控制,保证以上两句SQL要么全部执行成功,要么全部执行失败。
🌼2.2 事务的概念🌼
事务指逻辑上的一组操作,组成这组操作的各个单元,要么全部成功,要么全部失败。(将多个sql语句打包成一个整体)
其实如果一个操作失败了,并不是真的没执行,而是"看起来想没执行一样",我们的命令选择了恢复现场,把数据还原成未执行之前的状态了。(这个恢复数据的操作,称为"回滚"–roolback)
在不同的环境中,都可以有事务。对应在数据库中,就是数据库事务。
🌾2.3 使用🌾
(1)开启事务:start transaction;
(2)执行多条SQL语句
(3)回滚或提交事务:rollback/commit;
说明:rollback即是全部失败,commit即是全部成功。
start transaction;
-- 阿里巴巴账户减少2000
update accout set money=money-2000 where name = '阿里巴巴';
-- 四十大盗账户增加2000
update accout set money=money+2000 where name = '四十大盗';
commit;
🌋2.4事务的特性🌋
1.原子性 [最核心的特性] 初心
2.一致性 事务执行前后,数据得是靠谱的
3.持久性 事务修改的内容时写到硬盘上的,持久存在的,重启也不会丢失。
4.隔离性 隔离性是为了解决 “并发” 执行事务,引起的问题。
并发:一个餐馆(服务器),同一时刻要给多个顾客(客户端)提供服务,这些顾客提出的请求,是"一个接一个"来的吗?还是一股脑一起来了一波?这些都是无法预测的。此时服务器同时处理多个客户端的请求,就称为 “并发” (齐头并进的感觉)
数据库也是服务器,也可能多个客户端都给服务器提交事务,数据库也就需要并发的处理多个事务。
事务的隔离性是为了解决在数据库并发处理事务的时候,不会有问题(即使有问题,问题也不大)
🌌2.5事务的问题总结🌌
1.脏读问题:就是一个事务读到另一个事务没有提交的数据。事务A修改了一个数据,但未提交,事务B读到了事务A未提交的更新结果,事务B读到的就是脏数据。
解决方法:mysql引入 “写操作加锁” 机制,比如说我先和一个同事商量好,我写代码的过程中,你别来看。等我改完,提交到码云上,你再通过我的码云看。这个给写加锁的操作,就降低了并发程度(降低了效率),提高了隔离性(提高了数据的准确性)
[写的时候不能看,给写的操作加锁,写完了才能看]
2.不可重复读:就是一个事务读到另一个事务修改后并提交的数据(update)。在同一个事务中,对于同一组数据读取到的结果不一致。比如,事务B 在 事务A 提交前读到的结果,和在 事务A 提交后读到的结果可能不同。不可重复读出现的原因就是由于事务并发修改记录而导致的。
解决方法:约定同事读代码的时候,我不能修改,就是给读加锁。通过这个读加锁,又进一步的降低了事务的并发处理能力(处理效率也降低),提高了事务的隔离性(数据的准确性又提高了) 读完之后这个锁就解开了
3.幻读:事务 A 对一个表中的数据进行了修改,这种修改涉及到表中的全部数据行。此时,突然事务 B 插入了一条数据并提交了,当事务 A 提交了修改数据操作之后,再次读取全部数据,结果发现还有一条数据未更新,给人感觉好像产生了幻觉一样。这就是幻读!
解决方法:数据库使用 “串行化” 这样的方式来解决幻读。彻底放弃并发处理事务。一个接一个的串行的处理事务。这样做,并发程度是最低的(效率是最慢的),隔离性是最高的(准确性也是最高的)。
相当于是同事们要求,在他们读代码时,A不能摸电脑,必须强制摸鱼!!!

⛅️3. 内容重点总结⛅️
- 索引:
(1)对于插入、删除数据频率高的表,不适用索引
(2)对于某列修改频率高的,该列不适用索引
(3)通过某列或某几列的条件查询频率高的,可以对这些列创建索引
- 事务
start transaction;
...
rollback/commit;

感谢各位读者的阅读,本文章有任何错误都可以在评论区发表你们的意见,我会对文章进行改正的。如果本文章对你有帮助请动一动你们敏捷的小手点一点赞,你的每一次鼓励都是作者创作的动力哦!😘