INTERSPEECH 2023 论文预讲会是由CCF语音对话与听觉专委会、语音之家主办,旨在为学者们提供更多的交流机会,更方便、快捷地了解领域前沿。活动将邀请 INTERSPEECH 2023 录用论文的作者进行报告交流。
INTERSPEECH 2023 论文预讲会第二期邀请到华南理工大学专场分享,欢迎大家预约观看。

第二期
华南理工大学【专场】
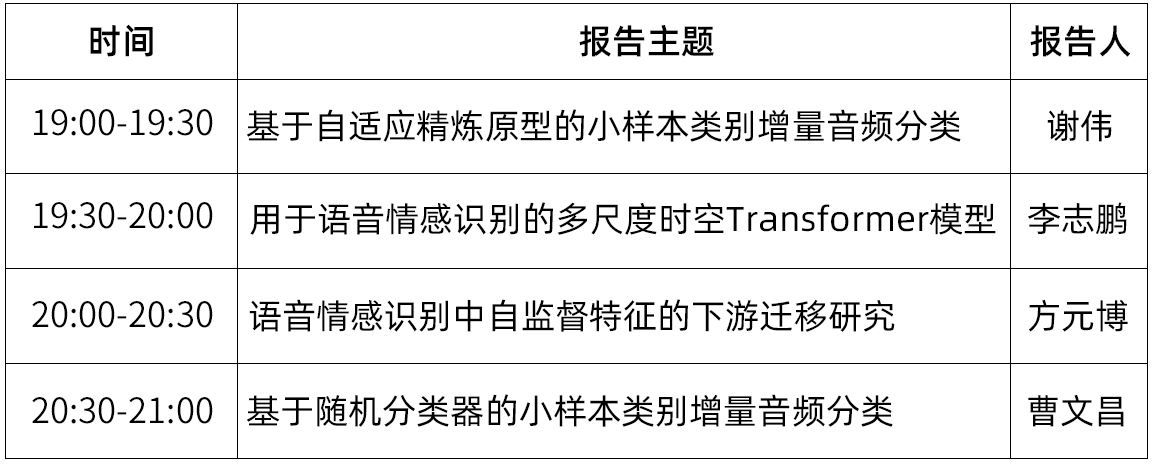
时间:6月20日(周二) 19:00-21:00
形式:线上
议程:每位嘉宾分享30分钟(含5分钟QA)
嘉宾&主题

嘉宾简介:工学博士,毕业于华南理工大学信息与通信工程专业,主要研究方向为信号分析与深度学习。
分享主题:基于自适应精炼原型的小样本类别增量音频分类
摘要:新的声音类别不断涌现于开放环境中,给声音识别模型在适应动态声学环境方面带来了巨大挑战。这一挑战促使本文研究一个新问题,即少样本类别增量音频分类。本文旨在研究如何使模型能够在仅利用少量新类别训练样本的情况下,持续识别新类别的声音,同时不遗忘旧的类别。为实现这一目标,本文提出了一种模型动态扩展的方法,通过持续生成具有强区分性的原型并应用于扩展模型的分类器,以实现模型对新旧类别声音的准确识别。该方法采用随机情景训练策略和动态关系投影模块增强原型的区分性。在Nsynth-100和FSC-89这两个数据集的实验结果中,本文所提出的方法在平均准确率和性能下降速率方面优于对比方法。

嘉宾简介:华南理工大学电子与信息学院一年级硕士生,研究方向为语音情感识别。
分享主题:用于语音情感识别的多尺度时空Transformer模型
摘要:语音情感识别(SER)在人机交互系统中起着至关重要的作用。最近,各种不同架构的Transformer模型已经成功地应用于语音领域。然而,现有的Transformer模型更加注重全局信息,庞大的计算量带来了很大的计算压力。另一方面,情感信息是以多粒度的形式存在于帧/音素/单词/话语中的,这意味着除了语音信号的全局表征,细节信息也是很重要的。为了解决上述问题,本文为语音情感识别任务提出了一个多尺度Transformer架构(MSTR),包括三个主要部分:多尺度时间特征提取器,分形自注意模块以及尺度混合器模块。这三个部分能够有效地降低Transformer架构的计算量以及提高多尺度情感表征能力。实验结果表明,所提出的MSTR模型在语音情感数据集中的表现明显优于基线模型。

嘉宾简介:华南理工大学电子与信息学院博士生,主要研究方向为语音信号处理,情感识别。
分享主题:语音情感识别中自监督特征的下游迁移研究
摘要:最近自监督表征学习在语音领域取得了巨大的进展,基于transformer的下游模型在下游语音任务上提供了良好的迁移性能。然而,其固有结构是否真的适合于下游迁移是不确定的。在本文中,我们打破了传统多头自注意力和前馈神经网络(MSA-FFN)结构,采用block结构搜索策略(BAS)来研究合适的下游迁移方式。在语音情感识别任务中,我们发现:
(1)在下游模型的早期阶段,应该避免采用MSA先行的设计。
(2)在使用自监督特征的情况下,使用一个简单的FFN就可以进行良好的下游迁移。论文所提出的方法也可以应用于其它基于自监督特征的下游语音任务。

嘉宾简介:华南理工大学电子与信息学院二年级硕士生,研究方向为语音信号处理,音频识别,说话人识别,小样本类增量学习。
分享主题:基于随机分类器的小样本类别增量音频分类
摘要:对于当前的音频分类方法来说,类别的数量往往是固定不变的,并且模型只能识别预先给定的类别。当出现新类时,模型需要使用之前类别的充足样本再次训练。如果新的类别不断出现,上述方法的工作将受到负面影响甚至无法正常工作。在这项研究中,我们提出了一种用于小样本类增量音频分类的方法,该方法能够在识别新类的同时保持旧类的识别率。我们的模型由特征提取器和随机分类器组成。特征提取器在初始阶段训练完成后被冻结,随机分类器则会在增量阶段被不断扩展和训练。以NSynth语料库和LibriSpeech语料库为基础,我们构造了NS-100数据集和LS-100数据集,实验结果表明我们的方法在平均准确率和性能下降速率方面优于对比方法。
参与方式
直播将通过CSDN进行直播,手机端、PC端可同步观看
👇👇👇
https://live.csdn.net/room/weixin_48827824/bUPkzEod
论文征集
INTERSPEECH 2023 论文预讲会面向全球线上招募,结合定向邀请与自选投稿的方式,来选择预讲会的嘉宾。
投稿邮箱:jack@speechhome.com