《Prefix-Tuning: Optimizing Continuous Prompts for Generation》阅读笔记
论文题目:Prefix-Tuning: Optimizing Continuous Prompts for Generation
论文链接:https://arxiv.org/pdf/2101.00190
论文来源:Arxiv (2021)
源码链接:https://github.com/XiangLi1999/PrefixTuning
转载请声明:爱学习NLP的皮皮虾
INTRODUCTION
微调(Fine-tunning)是使用大型预训练语言模型执行诸如摘要的下游任务的普遍方法,但它需要替换和存储LM的所有参数,因此,构建和部署依赖于大型预训练语言模型的NLP系统,需要为每个任务存储一个修改过的语言模型参数副本,由于预训练模型都有很大的参数量,这一操作可能是非常昂贵的。
解决这个问题的一种自然方法是轻量微调(lightweight fine-tunning),它冻结了大部分预训练参数,并用小的可训练模块来增强模型,比如在预先训练的语言模型层之间插入额外的特定任务层。适配器微调(Adapter-tunning)在自然语言理解和生成基准测试上具有很好的性能,通过微调,仅添加约2-4%的任务特定参数,就可以获得类似的性能。
GPT-3可以在不进行任何特定于任务的微调的情况下部署,即用户在任务输入前添加一个自然语言任务指令和一些示例,然后从LM生成输出。这种方法被称为情境学习(in-context learning)或提示(prompting)。
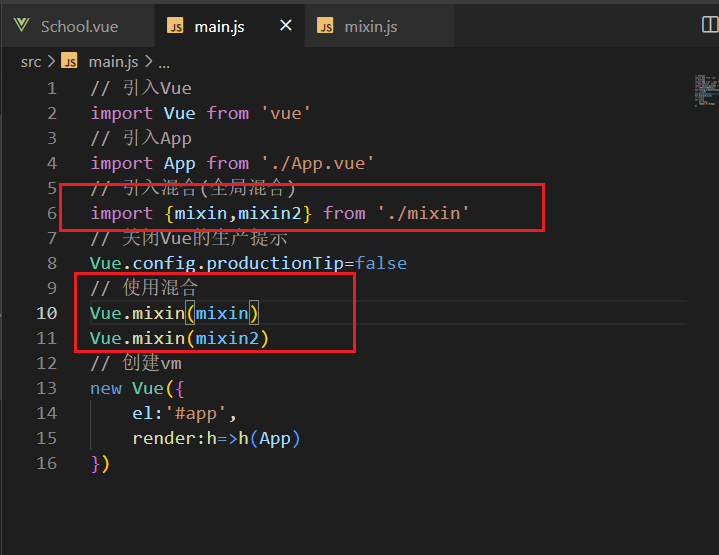
本文提出了前缀微调(prefix-tunning),用于生成任务的轻量微调。前缀微调将一个连续的特定于任务的向量序列添加到输入,称之为前缀,如下图中的红色块所示。与提示(prompt)不同的是,前缀完全由自由参数组成,与真正的token不对应。相比于传统的微调,前缀微调只优化了前缀。因此,我们只需要存储一个大型Transformer和已知任务特定前缀的副本,对每个额外任务产生非常小的开销。

METHOD
1. 问题陈述
本文考虑两个生成任务:table-to-text 和摘要任务。

其中Pidx表示第idx个位置是前缀,|Pidx|表示前缀长度
对于table-to-text任务,本文使用自回归语言模型GPT-2,输入为source( x )和target( y)的拼接,模型自回归地生成 ![]() :
:
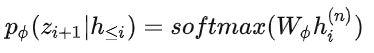
对于摘要任务,本文使用BART模型,编码器输入source文本 x ,解码器输入target黄金摘要( y ),模型预测摘要文本 ![]() 。
。
在传统微调方法中,模型使用预训练参数进行初始化,然后用对数似然函数进行参数更新。
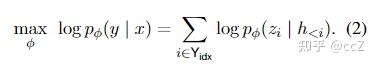
2. 前缀微调
关于前缀/提示的设计,我们可以给模型若干的字词作为提示,比如我们想让模型生成“Obama”,那我们可以在其常见的搭配前加上上下文(例如,Barack),那么LM就会把更高的可能性分配给想要的单词。但是对于很多生成任务来说,找到合适的离散的前缀进行优化是非常困难的,尽管它的效果是不错的。
因此本文将指令优化为连续的单词嵌入,而不是通过离散的token进行优化,其效果将向上传播到所有Transformer激活层,并向右传播到后续的token。严格来说,这比离散提示符更具表达性,后者需要匹配嵌入的真实单词。
对于自回归模型,加入前缀后的模型输入表示:
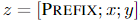
对于编解码器结构的模型,加入前缀后的模型输入表示:
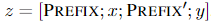
本文构造一个矩阵 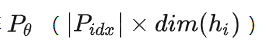 去存储前缀参数,该前缀是自由参数。
去存储前缀参数,该前缀是自由参数。
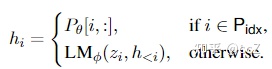
目标函数依旧是公式(2),但是语言模型的参数是固定的,只更新前缀参数。
除此之外,作者发现直接更新前缀参数会出现不稳定的情况,甚至模型表现还有轻微的下降,因此作者对前缀参数矩阵进行重参数化:
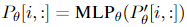
其中 ![]() 在第二维的维数要比
在第二维的维数要比![]() 小,然后经过一个扩大维数的MLP,一旦训练完成,这些重参数化的参数就可以丢弃,只保留
小,然后经过一个扩大维数的MLP,一旦训练完成,这些重参数化的参数就可以丢弃,只保留![]() 。
。
EXPERIMENTS
1. 数据集和指标
table-to-text任务:
数据集:E2E,WebNLG,DART
指标:BLEU, METEOR, TER, Mover-Score, BERTScore, BLEURT
摘要任务:
数据集:XSum
指标: ROUGE-1, ROUGE-2, ROUGE-L
2. 实验结果
table-to-text

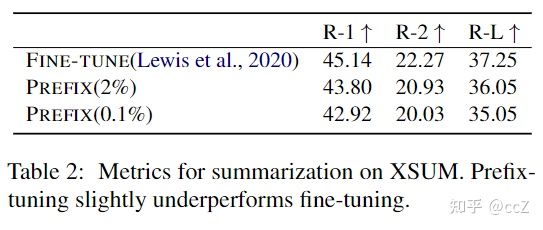
摘要:
低资源分析:

前缀长度分析:

CONCLUSION
本文提出一种更好的微调方法,通过加入前缀实现统一模型在不同任务上的微调,实现小样本学习,极大地减少了参数量。目前对于前缀的构造,大致可以分为本文的连续前缀和离散前缀(自动生成或手动设计),对于在摘要任务上加入离散前缀,有点类似于从对话中提取特征或结构,但这种方法的优势就在于它不需要大量的样本,而传统的融入结构的方法仍然需要很多样本。感觉这种方法可能是摘要任务之后的趋势之一。



![Axios和Spring MVC[前端和后端的请求和响应处理]](https://img-blog.csdnimg.cn/68598cee28404cbc83dfbfcc1879ff9d.png)