【论文精读ACL_2021】Prefix-Tuning: Optimizing Continuous Prompts for Generation
- 0、前言
- Abstract
- 1 Introduction
- 2 Related Work
- 2.1 Fine-tuning for natural language generation.
- 2.2 Lightweight fine-tuning
- 2.3 Prompting.
- 2.4 Controllable generation.
- 3 Problem Statement
- 3.1 Autoregressive LM
- 3.2 Encoder-Decoder Architecture
- 3.3 Method: Fine-tuning
- 4 Prefix-Tuning
- 4.1 Intuition
- 4.2 Method
- 4.3 Parametrization of Pθ
- 5 Experimental Setup
- 5.1 Datasets and Metrics
- 5.2 Methods
- 5.3 Architectures and Hyperparameters
- 6 Main Results
- 6.1 Table-to-text Generation
- 6.2 Summarization
- 6.3 Low-data Setting
- 6.4 Extrapolation
- 7 Intrinsic Evaluation
- 7.1 Prefix Length
- 7.2 Full vs Embedding-only
- 7.3 Prefixing vs Infixing
- 7.4 Initialization
- 8 Discussion
- 8.1 Personalization
- 8.2 Batching Across Users
- 8.3 Inductive Bias of Prefix-tuning
- 9 Conclusion
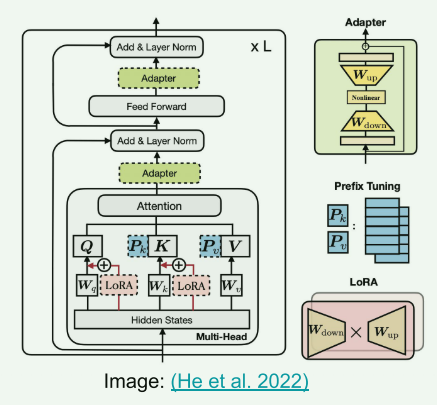
0、前言
Adapter
Prefix-Tuning
LoRA
Abstract
微调实际上是利用大型预训练的语言模型来执行下游任务的方法。
但是,它会修改所有的语言模型参数,因此需要为每个任务存储完整的副本。
在本文中,我们提出了前缀调优,这是对自然语言生成任务进行微调的一种轻量级替代方案,它保持语言模型参数不变,但优化了一个小型的连续任务特定向量(称为前缀)。
前缀调优从提示中获得灵感,允许后续令牌处理这个前缀,就像它是“虚拟令牌”一样。
我们将前缀调优应用于GPT-2以生成表到文本,并应用于BART以进行摘要。
我们发现,通过只学习0.1%的参数,前缀调优在全数据设置中获得了类似的性能,在低数据设置中表现优于微调,并且可以更好地推断出训练中没有看到的主题。
1 Introduction
微调是使用大型预训练语言模型(LMs)的普遍范式(Radford等人,2019;Devlin等人,2019)执行下游任务(例如,摘要),但它需要更新和存储LM的所有参数。
因此,要构建和部署依赖于大型预训练LM的NLP系统,目前需要为每个任务存储经过修改的LM参数的副本。
考虑到当前LMs的大尺寸,这可能非常昂贵;例如,GPT-2有774M参数(Radford等人,2019),而GPT-3有175B参数(Brown等人,2020)。
解决这个问题的一种自然方法是轻量级微调,它会冻结大多数预先训练的参数,并使用小型可训练模块来扩充模型。
例如,适配器调优(Rebuffi等人,2017;Houlsby等人,2019)在预训练语言模型的层之间插入额外的特定于任务的层。
适配器调优在自然语言理解和生成基准测试方面有很好的性能,通过微调获得类似的性能,同时只添加大约2-4%的任务特定参数(Houlsby等人,2019;Lin等人,2020)。
在极端的情况下,GPT-3 (Brown et al., 2020)可以在没有任何特定任务调优的情况下部署。
相反,用户在任务输入前添加一个自然语言任务指令(例如,TL;DR用于摘要)和一些示例;然后从LM生成输出。
这种方法被称为上下文学习或提示。
在本文中,我们受到提示的启发,提出了前缀调优,这是自然语言生成(NLG)任务的微调的轻量级替代方案。
考虑生成数据表的文本描述的任务,如图1所示,其中任务输入是一个线性化的表(例如,“name: Starbucks | type: coffee shop”),输出是一个文本描述(例如,“Starbucks services coffee.”)。
前缀调优将一系列连续的特定于任务的向量添加到输入,我们称其为前缀,如图1(下)中的红色块所示。
对于后续的令牌,Transformer可以处理前缀,就像它是一个“虚拟令牌”序列一样,但与提示不同的是,前缀完全由自由参数组成,这些参数不对应于真正的令牌。
图1(上)中的微调更新了所有Transformer参数,因此需要为每个任务存储调优后的模型副本,与此相反,前缀调优只优化前缀。
因此,我们只需要存储大型Transformer的一个副本和一个已学习的特定于任务的前缀,从而为每个额外的任务产生非常小的开销(例如,表到文本的250K参数)。
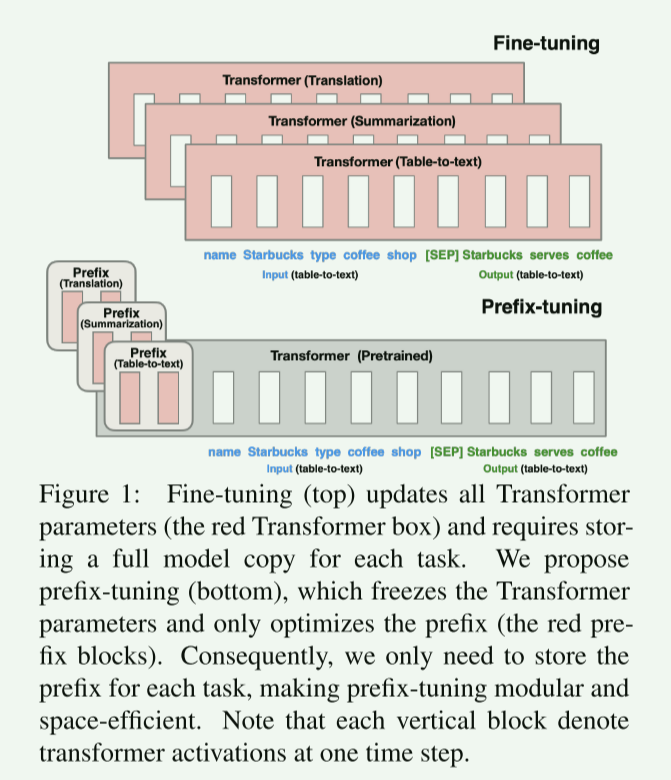
图1:微调(顶部)更新所有Transformer参数(红色Transformer框),并需要为每个任务存储完整的模型副本。
我们建议使用前缀调优(下图),它冻结Transformer参数并只优化前缀(红色前缀块)。
因此,我们只需要为每个任务存储前缀,使前缀调优模块化和节省空间。
注意,每个垂直块表示Transformer在一个时间步长的激活。
与微调相比,前缀微调是模块化的:我们训练一个上游前缀,它控制一个下游LM,而下游LM仍然没有被修改。
因此,一个LM可以同时支持许多任务。
在个性化的背景下,任务对应不同的用户(Shokri和Shmatikov, 2015;McMahan et al., 2016),我们可以为每个只对该用户的数据进行训练的用户有一个单独的前缀,从而避免数据交叉污染。
此外,基于前缀的体系结构使我们能够在一个批处理中处理来自多个用户/任务的示例,这是其他轻量级微调方法不可能做到的。
我们评估了使用GPT-2生成表到文本的前缀调优,以及使用BART生成抽象摘要的前缀调优。
在存储方面,前缀调优比微调少存储1000倍的参数。
在全数据集上训练时,在性能方面,前缀调优和微调对于表到文本来说是相当的(§6.1),而前缀调优对于摘要来说略有下降(§6.2)。
在低数据设置中,前缀调优在两个任务上的平均性能优于微调(§6.3)。
前缀调优还可以更好地推断出未见主题的表(表到文本)和文章(摘要)(§6.4)。
2 Related Work
2.1 Fine-tuning for natural language generation.
目前最先进的自然语言生成系统是基于经过微调的预先训练的LMs。
对于表到文本的生成,Kale(2020)微调了序列到序列的模型(T5;rafael et al., 2020)。
对于抽取性和抽象性的摘要,研究人员微调了掩蔽语言模型(如BERT;Devlin等人,2019)和编码解码模型(如BART;Lewis et al., 2020) 分别的(Zhong et al., 2020;刘和拉帕塔,2019;rafael et al., 2020)。
对于其他有条件的NLG任务,如机器翻译和对话生成,微调也是普遍的范式(Zhang et al., 2020c;Stickland等人,2020年;Zhu et al., 2020;刘等,2020)。
在本文中,我们主要关注使用GPT-2的表格到文本和使用BART的摘要,但是前缀调优可以应用于其他生成任务和预先训练的模型。
2.2 Lightweight fine-tuning
轻量级微调冻结大部分预训练参数,并使用小型可训练模块修改预训练模型。
关键的挑战是识别模块的高性能架构和要调优的预训练参数子集。
一类研究考虑去除参数:通过对模型参数进行二值掩码训练,去除一些模型权重(赵等人,2020;Radiya-Dixit和Wang, 2020)。
另一类研究考虑插入参数。
例如,Zhang et al. (2020a)训练一个“边”网络,通过求和将其与预训练的模型融合;适配器调优在预训练LM的每一层之间插入特定于任务的层(适配器)(Houlsby等人,2019;Lin等人,2020年;Rebuffi等人,2017;Pfeiffer等人,2020)。
与这条调优了3.6% LM参数的工作相比,我们的方法进一步降低了30倍特定于任务的参数,在保持相当性能的情况下只调优了0.1%。
2.3 Prompting.
提示意味着在任务输入前添加指令和一些示例,并从LM生成输出。
GPT-3 (Brown et al., 2020)使用手动设计的提示来适应不同的任务,这个框架被称为上下文学习。
然而,由于transformer只能在有限制长度的上下文(例如,GPT3的2048个令牌)上设置条件,因此上下文学习无法充分利用超过上下文窗口的训练集。
Sun and Lai(2020)也提示通过关键词来控制生成的句子的情绪或话题。
在自然语言理解任务中,prompt 工程在之前的工作中已经对BERT和RoBERTa等模型进行了探索(Liu等人,2019;Jiang et al., 2020;舒克和舒克,2020年)。
例如,AutoPrompt (Shin等人,2020)搜索一系列离散触发词,并将其与每个输入连接起来,从masked LM中引出情感或事实知识。
与AutoPrompt相比,我们的方法优化了连续前缀,它更具表现力(§7.2);此外,我们专注于语言生成任务。
连续向量被用来控制语言模型;例如,Subramani等人(2020)表明,经过训练的LSTM语言模型可以通过为每个句子优化一个连续向量来重构任意句子,使向量input-specific输入具有特异性。
相反,前缀调优优化了应用于该任务的所有实例的特定于任务的前缀。
因此,前缀调优可以应用到NLG任务中,而不像以前的工作只局限于句子重构。
2.4 Controllable generation.
可控生成的目的是引导预先训练的语言模型匹配句子级属性(如积极情绪或体育话题)。
这种控制可以在训练时发生:Keskar等人(2019)根据关键字或URLs等元数据对语言模型(CTRL)进行预训练。
此外,控制可以在解码时发生,通过加权解码(GeDi, Krause等人,2020)或迭代更新过去的激活(PPLM, Dathathri等人,2020)。
然而,并没有直接的方法来应用这些可控的生成技术来对生成的内容实施细粒度的控制,如表到文本和摘要等任务所要求的那样。
3 Problem Statement
考虑一个条件生成任务,其中输入是上下文
x
x
x,输出
y
y
y 是标记序列。
我们专注于两个任务,如 图2(右)所示:在表到文本中,
x
x
x 对应于线性化数据表,
y
y
y 是文本描述;在摘要中,
x
x
x 是一篇文章,
y
y
y 是一个简短的摘要。
3.1 Autoregressive LM
假设我们有一个基于 Transformer (Vaswani et al.,2017) 架构 (例如 GPT-2; Radford et al.,2019)并由
ϕ
\phi
ϕ 参数化的自回归语言模型
p
ϕ
(
y
∣
x
)
p_\phi(y \mid x)
pϕ(y∣x) .
如 图2(顶部)所示,设
z
=
[
x
;
y
]
z = [x;y]
z=[x;y] 是
x
x
x 和
y
y
y 的串联;设
X
i
d
x
\mathrm{X_{idx}}
Xidx 表示对应于
x
x
x 的索引序列,
Y
i
d
x
\mathrm{Y_{idx}}
Yidx 表示对应于
y
y
y 的索引序列。

使用自回归 LM(顶部)和编码器-解码器模型(底部)进行前缀微调的注释示例。
前缀激活 ∀ i ∈ P i d x , h i \forall i \in \mathrm{P_{idx}}, h_i ∀i∈Pidx,hi 是从可训练矩阵 P θ P_\theta Pθ 中提取的。
剩余的激活由 Transformer 计算。
在时间步 i i i 的激活是 h i ∈ R d h_i \in \mathbb R^d hi∈Rd,其中 h i = [ h i ( 1 ) ; ⋯ ; h i ( n ) ] h_i = [h_i^{(1)}; \cdots; h_i^{(n)}] hi=[hi(1);⋯;hi(n)]是这个时间步所有激活层的串联, h i ( j ) h_i^{(j)} hi(j)是第 j j j个Transformer层在时间步 i i i的激活。 1
自回归 Transformer 模型将
h
i
h_i
hi 计算为
z
i
z_i
zi 及其左侧上下文中过去激活的函数,如下所示:
h
i
=
L
M
ϕ
(
z
i
,
h
<
i
)
,
\begin{align} h_i = \mathrm{LM}_\phi(z_i, h_{<i}) \text{,} \end{align}
hi=LMϕ(zi,h<i),
h
i
h_i
hi 的最后一层用于计算下一个标记的分布:
p
ϕ
(
z
i
+
1
∣
h
≤
i
)
=
s
o
f
t
m
a
x
(
W
ϕ
h
i
(
n
)
)
p_{\phi}(z_{i+1} \mid h_{\leq i}) = softmax(W_\phi ~h_ {i}^{(n)})
pϕ(zi+1∣h≤i)=softmax(Wϕ hi(n))
W
ϕ
W_\phi
Wϕ 是一个预训练矩阵,它将
h
i
(
n
)
h_{i}^{(n)}
hi(n) 映射到词汇表上的对数logits。
3.2 Encoder-Decoder Architecture
我们还可以使用编码器-解码器架构 [例如,BART;][]{lewis-etal-2020-bart} 来建模
p
ϕ
(
y
∣
x
)
p_\phi(y\mid x)
pϕ(y∣x),其中
x
x
x 由双向编码器,解码器自回归预测
y
y
y(以编码的
x
x
x 及其左上下文为条件)。
我们使用相同的索引和激活符号,如 图2(底部)所示。
所有
i
∈
X
i
d
x
i \in \mathrm{X_{idx}}
i∈Xidx 的
h
i
h_i
hi 由双向 Transformer 编码器计算;
所有
i
∈
Y
i
d
x
i \in \mathrm{Y_{idx}}
i∈Yidx 的
h
i
h_i
hi 由自回归解码器使用相同的 公式(1) 计算。
3.3 Method: Fine-tuning
在微调框架中,我们使用预训练参数
ϕ
\phi
ϕ 进行初始化。
这里
p
ϕ
p_{\phi}
pϕ 是一个可训练的语言模型分布,我们对以下对数似然目标执行梯度更新:
max
ϕ
log
p
ϕ
(
y
∣
x
)
=
∑
i
∈
Y
i
d
x
log
p
ϕ
(
z
i
∣
h
<
i
)
.
\begin{align} \max_{\phi} ~\log p_\phi(y \mid x) = \sum_{i\in \mathrm{Y_{idx}}} \log p_\phi(z_i \mid h_{<i}) \text{.} \end{align}
ϕmax logpϕ(y∣x)=i∈Yidx∑logpϕ(zi∣h<i).
4 Prefix-Tuning
我们建议将前缀调优作为有条件生成任务的微调的替代方案。在§4.2正式定义我们的方法之前,我们首先在§4.1中提供了直觉。
4.1 Intuition
根据提示的直觉,我们相信拥有适当的上下文可以在不改变其参数的情况下控制LM。
例如,如果我们希望LM生成一个单词(例如Obama),我们可以将它的常见搭配作为上下文(例如Barack)加在前面,LM将为所需单词分配更高的概率。
将这种直觉扩展到生成单个单词或句子之外,我们希望找到一个上下文来引导LM解决一个NLG任务。
直观地说,上下文可以通过指导从x中提取什么来影响x的编码;并且可以通过控制下一个令牌分发来影响y的生成。
然而,这样的上下文是否存在并不明显。
自然语言任务指令(例如,“用一句话总结下表”)可能会指导专家注释者解决任务,但对于大多数经过训练的LMs2来说都失败了。
基于离散指令的数据驱动优化可能会有所帮助,但离散优化在计算上具有挑战性。
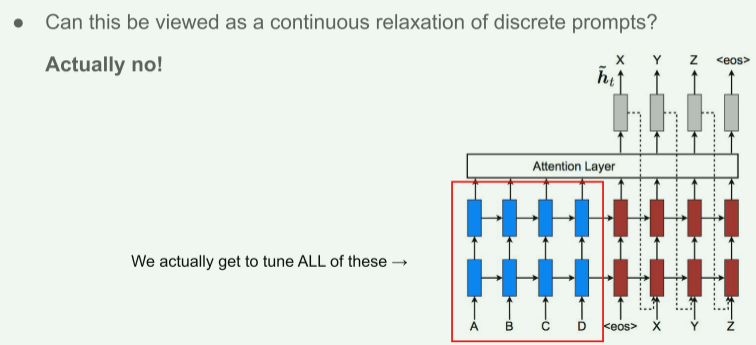
我们可以将指令优化为连续的单词嵌入,而不是对离散令牌进行优化,其效果将向上传播到所有Transformer激活层,并向右传播到后续令牌。
严格来说,这比离散提示符更具表现力,离散提示符需要匹配嵌入的真实单词。
同时,这比干预激活的所有层(§7.2)表现力更低,这避免了长期依赖,并包括更多的可调参数。
因此,前缀调优可以优化前缀的所有层。
4.2 Method
前缀微调为自回归 LM 添加前缀以获得
z
=
[
P
R
E
F
I
X
;
X
;
y
]
z = [\mathrm{PREFIX}; X; y]
z=[PREFIX;X;y],或者为encoder和encoder都加上前缀得到
z
=
[
P
R
E
F
I
X
;
X
;
P
R
E
F
I
X
′
;
y
]
z = [\mathrm{PREFIX}; X; \mathrm{PREFIX}'; y]
z=[PREFIX;X;PREFIX′;y],如 图2 所示。
这里,
P
i
d
s
\mathrm{P_{ids}}
Pids表示前缀索引序列,我们使用
∣
P
i
d
s
∣
|\mathrm{P_{ids}}|
∣Pids∣表示前缀的长度。
我们遵循公式(1)中的递归关系,除了前缀是 free 参数。
前缀微调初始化维度为
∣
P
i
d
s
∣
×
dim
(
h
i
)
|\mathrm{P_{ids}}| \times \dim(h_i)
∣Pids∣×dim(hi)的可训练矩阵
P
θ
P_\theta
Pθ(由
θ
\theta
θ 参数化) 来存储前缀参数。
h
i
=
{
P
θ
[
i
,
:
]
,
if
i
∈
P
i
d
s
,
L
M
ϕ
(
z
i
,
h
<
i
)
,
otherwise.
\begin{align} h_{i} = \begin{cases} P_{\theta}[i,:], & \text{if } i \in \mathrm{P_{ids}} \text{,}\\ \mathrm{LM}_\phi(z_i, h_{<i}), & \text{otherwise.} \end{cases} \end{align}
hi={Pθ[i,:],LMϕ(zi,h<i),if i∈Pids,otherwise.
训练目标与 公式(2) 相同,但可训练参数集发生变化:语言模型参数
ϕ
\phi
ϕ 是固定的,前缀参数
θ
\theta
θ 是唯一可训练的参数。
这里,
h
i
h_i
hi(对于所有
i
i
i)是可训练的
P
θ
P_\theta
Pθ 的函数。
当
i
∈
P
i
d
s
i \in \mathrm{P_{ids}}
i∈Pids 时,这很清楚,因为
h
i
h_i
hi 直接从
P
θ
P_{\theta}
Pθ 复制。
当
i
∉
P
i
d
s
i \not \in \mathrm{P_{ids}}
i∈Pids 时,
h
i
h_i
hi 仍然依赖于
P
θ
P_{\theta}
Pθ,因为前缀激活总是在左侧上下文中,因此会影响其右侧的任何激活.
4.3 Parametrization of Pθ
根据经验,直接更新 P θ P_\theta Pθ 参数会导致优化不稳定,性能略有下降3。
所以我们重新参数化矩阵
P
θ
[
i
,
:
]
=
M
L
P
θ
(
P
θ
′
[
i
,
:
]
)
P_\theta [i,:]= \mathrm{MLP}_\theta (P'_\theta[i,:])
Pθ[i,:]=MLPθ(Pθ′[i,:]) 通过一个较小的矩阵 (
P
θ
′
P'_\theta
Pθ′) 组成大型前馈神经网络(
M
L
P
θ
\mathrm{MLP}_\theta
MLPθ)。
请注意
P
θ
P_\theta
Pθ 和
P
θ
′
P'_\theta
Pθ′ 具有相同的行维度(即前缀长度),但不同的列维度。4
一旦训练完成,这些重新参数化的参数就可以被丢弃,只需要保存前缀( P θ P_\theta Pθ)。
5 Experimental Setup
5.1 Datasets and Metrics
我们评估了三个用于表到文本任务的标准神经生成数据集:E2E(Novikova et al.,2017)、WebNLG(Gardent et al.,2017)和DART(Radev et al.,2020)。 数据集按复杂性和大小的增加排序。 E2E只有1个域名(即餐厅评论); WebNLG有14个域,DART是开放域,使用Wikipedia中的开放域表。
E2E数据集包含大约50k个具有8个不同字段的示例; 它包含一个源表的多个测试引用,平均输出长度为22.9。 我们使用官方评估脚本,报告BLEU(Papineni et al.,2002)、NIST(Belz and Reiter,2006)、METEOR(Lavie and Agarwal,2007)、ROUGE-L(Lin,2004)和CIDEr(Vedantam et al.,2015)。
WebNLG(Gardent et al.,2017)数据集由22k个示例组成,输入x是(主题、属性、对象)三元组的序列。 平均输出长度为22.5。 在训练和验证部分,输入描述了来自9个不同DBpedia类别(例如,Monument)的实体。 测试分裂由两部分组成:前半部分包含训练数据中看到的DB类别,后半部分包含5个未看到的类别。 这些看不见的类别被用来评估外推extrapolation.。 我们使用官方评估脚本,它报告BLEU、METEOR和TER(Snover et al.,2006)。
DART(Radev et al.,2020)是一个开放域表到文本数据集,具有与WebNLG相似的输入格式(实体-关系-实体三元组)。 平均输出长度为21.6。 它由来自WikiSQL、WikitableQuestions、E2E和WebNLG的82K示例组成,并应用了一些手动或自动转换。 我们使用官方评估脚本和报告BLEU、METEOR、TER、MoverScore(Zhao et al.,2019)、BERTScore(Zhang et al.,2020b)和BLEURT(Sellam et al.,2020)。
对于摘要任务,我们使用XSUM(Narayan et al.,2018)数据集,这是一个关于新闻文章的抽象摘要数据集。 有225K个例子。 文章的平均长度为431字,摘要的平均长度为23.3字。 我们报告了ROUGE-1、ROUGE-2和ROUGE-L。
5.2 Methods
对于表到文本的生成,我们将前缀微调与其他三种方法进行了比较:微调 (FINE-TUNE)、仅微调前 2 层 (FT-TOP2)和适配器微调 (ADAPTER)。5
我们还报告了这些数据集上当前最先进的结果:在 E2E 上,Shen et al. (2019)使用了一个无需预训练的务实模型。
在 WebNLG 上,Kale (2020) 微调 T5-large。
在 DART 上,没有发布在此数据集版本上训练的官方模型。6
对于摘要,我们与微调 BART 进行比较 (Lewis et al., 2020)。
5.3 Architectures and Hyperparameters
对于表到文本,我们使用 GPT-2 M E D I U M _{\mathrm{MEDIUM}} MEDIUM 和 GPT-2 L A R G E _{\mathrm{LARGE}} LARGE;源表是线性化的。7对于总结,我们使用 BART L A R G E _{\mathrm{LARGE}} LARGE,8和源文章被截断为 512 512 512 BPE 令牌。
我们的实施基于 Hugging Face Transformer 模型 (Wolf et al., 2020)。
在训练时,我们使用 AdamW 优化器 (Loshchilov and Hutter, 2019)和线性学习率调度器,正如 Hugging Face 默认设置所建议的那样。
我们微调的超参数包括轮数、批量大小、学习率和前缀长度。
超参数详细信息在附录中。
默认设置训练
10
10
10 个时期,使用
5
5
5 的批量大小,
5
⋅
1
0
−
5
5 \cdot 10^{-5}
5⋅10−5 的学习率和
10
10
10 的前缀长度。
表格到文本模型在 TITAN Xp 或 GeForce GTX TITAN X 机器上训练。
前缀微调每个时期需要 0.2 美元小时来训练 22K 个示例,而微调大约需要 0.3 美元小时。
摘要模型在 Tesla V100 机器上进行训练,在 XSUM 数据集上每个时期花费
1.25
1.25
1.25h。
在解码时,对于三个表到文本的数据集,我们使用波束大小为
5
5
5 的波束搜索。
对于摘要,我们使用
6
6
6 的光束大小和
0.8
0.8
0.8 的长度归一化。
对于表到文本,每个句子(没有批处理)解码需要 1.2 美元秒,对于摘要,每批解码需要 2.6 美元秒(使用 10 的批大小)。
6 Main Results
6.1 Table-to-text Generation
我们发现仅添加 0.1% 任务特定参数,9前缀微调在表到文本生成中很有效,优于其他轻量级基线( ( A D A P T E R \mathrm{(ADAPTER} (ADAPTER 和 F T − T O P 2 ) FT-TOP2) FT−TOP2)),并通过微调实现了可比的性能。这种趋势在所有三个数据集上都是正确的:E2E、WebNLG,10和 DART。
为了进行公平的比较,我们将前缀调优和适配器调优的参数匹配为0.1%。
表1显示,前缀调优明显优于适配器(0.1%),平均每个数据集获得4.1个BLEU改进。
即使与微调(100%)和适配器调优(3.0%)相比,其更新的参数明显多于前缀调优,前缀调优仍然取得与这两个系统相当或更好的结果。
这表明前缀调优比适配器调优更有效,在提高生成质量的同时显著减少了参数。
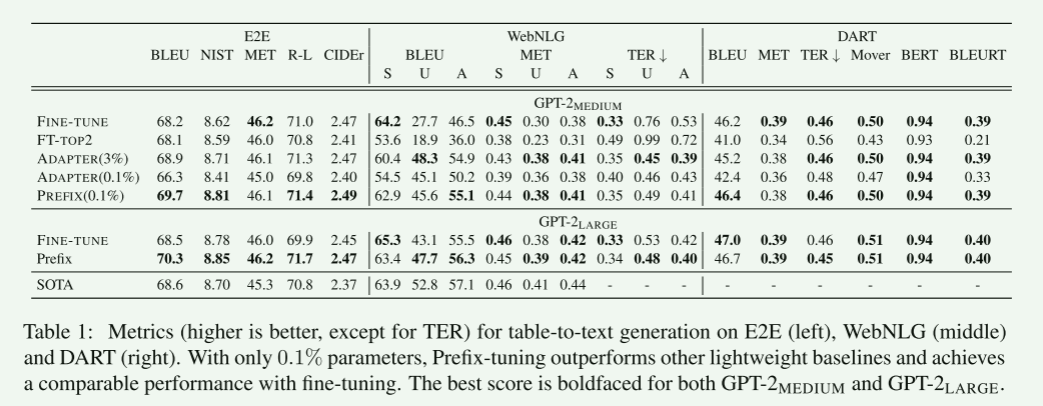
此外,在DART上获得良好的性能表明,前缀调优可以推广到具有不同域和大量关系库的表。
我们将在§6.4中更深入地研究外推性能(即推广到未见的类别或主题)。
总体而言,前缀微调是使 GPT-2 适应表到文本生成的有效且节省空间的方法。
学习到的前缀具有足够的表现力来引导 GPT-2 以正确地从不自然的格式中提取内容并生成文本描述。
前缀微调也可以很好地从 GPT-2
M
E
D
I
U
M
_{\mathrm{MEDIUM}}
MEDIUM 扩展到 GPT-2
L
A
R
G
E
_{\mathrm{LARGE}}
LARGE,这表明它有可能扩展到具有类似架构的更大模型,比如 GPT-3。
6.2 Summarization
如 表2 所示,使用 2% 参数,前缀微调获得的性能略低于微调(36.05 vs. 37.25 在ROUGE-L中)。
只有 0.1% 的参数,前缀微调的性能低于完全微调(35.05 对 37.25)。
XSUM 与三个表到文本数据集之间存在一些差异,这可以解释为什么前缀微调在表到文本中具有比较优势:
(1) XSUM 包含的示例比三个表到文本数据集多 4 倍一般;
(2) 输入的文章比 table-to-text 数据集的线性化表格输入平均长 17 倍;
(3) 摘要可能比表格到文本更复杂,因为它需要阅读理解和识别文章的关键内容。

6.3 Low-data Setting
基于表到文本(§6.1)和摘要(§6.2)的结果,我们观察到前缀微调在训练样本数较少时具有相对优势。
为了构造低数据设置,我们对完整数据集进行子采样(E2E用于表到文本,XSUM用于摘要),以获得大小为{50,100,200,500}的小型数据集。
对于每个大小,我们采样5个不同的数据集,并平均超过2个训练随机种子。
因此,我们平均超过10个模型,以得到每个低数据设置的估计值。11
图3(右)显示,除了需要更少的参数外,在低数据状态下,前缀微调比微调的平均性能好2.9BLEU,但随着数据集大小的增加,差距会缩小。
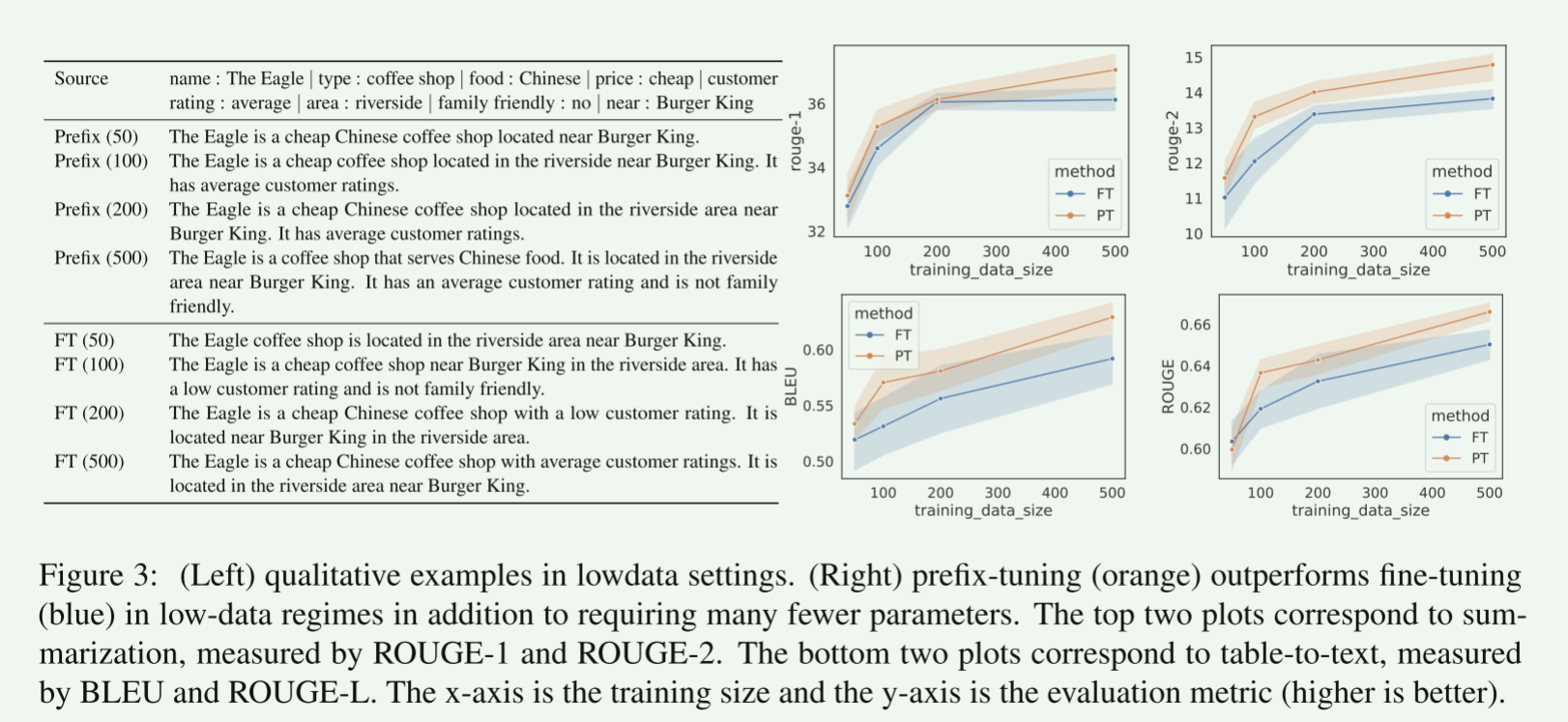
从质量上看,图3(左)显示了8个由前缀调优和微调模型在不同数据级别上训练生成的示例。
虽然这两种方法都倾向于在低数据状态下生成不足(丢失表内容),但前缀调优往往比微调更忠实。
例如,Finetuning(100,200)12错误地声称客户评级较低,而真实评级为平均,而前缀调优(100,200)生成一个忠实于表的描述。
6.4 Extrapolation
我们现在研究表到文本和摘要的不可见主题的外推性能。
为了构建外推设置,我们拆分了现有的数据集,以便训练和测试涵盖不同的主题。
对于表格到文本,WebNLG 数据集标有表格主题。
有训练和开发中出现的
9
9
9 个类别,表示为 SEEN 和仅在测试时出现的
5
5
5 个类别,表示为 UNSEEN。
因此,我们通过对 SEEN 类别进行训练和对 UNSEEN 类别进行测试来评估外推。
对于摘要,我们构造了两个外推数据 splits13:在
news-to-sports
\texttt{news-to-sports}
news-to-sports 中,我们训练新闻文章,测试体育文章。在
within-news
\texttt{within-news}
within-news 中,我们训练
{
\{
{world、UK、business
}
\}
} 新闻,并测试其余新闻类别(例如,健康、技术)。
在表到文本和摘要中,在所有度量下,前缀调整比微调具有更好的外推能力,如表3和表1(中间)的“U”列所示。
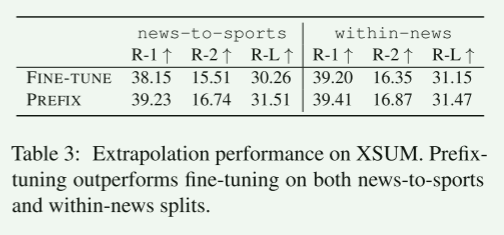
我们还发现适配器调优实现了良好的外推性能,与前缀调优相当,如表1所示。
这一共同趋势表明,保留LM参数确实对外推有积极的影响。
然而,这种收益的原因是一个悬而未决的问题,我们将在§8中进一步讨论。
7 Intrinsic Evaluation
我们比较了前缀调整的不同变体。
§7.1研究了前缀长度的影响。
§7.2只研究了嵌入层的调谐,这更类似于离散提示的调谐。
§7.3比较了前缀和内缀,后者在X和Y之间插入了可训练的激活。
§7.4研究了各种前缀初始化策略的影响。
7.1 Prefix Length
更长的前缀意味着更多的可训练参数,因此更有表现力。
图4显示,随着前缀长度增加到阈值(摘要为200,表到文本为10),性能会增加,然后性能会略有下降。14
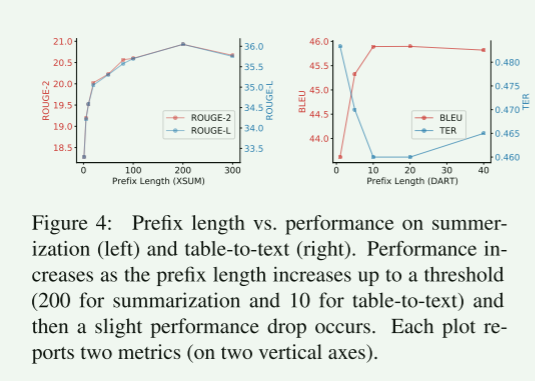
根据经验,较长的前缀对推理速度的影响可以忽略不计,因为整个前缀的注意力计算是在GPU上并行化的。
7.2 Full vs Embedding-only
回想一下§4.1,我们讨论了优化“虚拟令牌”的连续嵌入的选择。
我们实例化了这个想法,并称之为仅嵌入消融。
字嵌入是自由参数,上层激活层由Transformer计算。
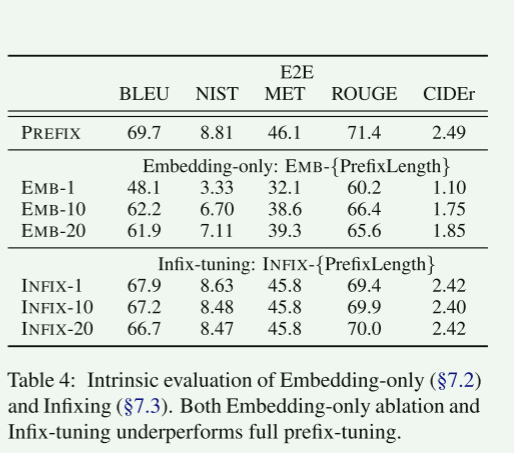
表4(顶部)显示,性能显著下降,这表明仅调优嵌入层并不能充分表达。
仅嵌入的消融限制了离散提示优化的性能(Shin et al.,2020),因为离散提示限制嵌入层精确匹配真实单词的嵌入。
因此,我们有一个不断增长的表达能力链:discrete prompting < embedding-only ablation < prefix-tuning。
7.3 Prefixing vs Infixing
我们还研究了序列中可训练激活的位置如何影响性能。
在前缀调整中,我们将它们放在开头
[
P
R
E
F
I
X
;
x
;
y
]
[\mathrm{PREFIX} ; x ; y]
[PREFIX;x;y]。
我们还可以将可训练的激活放在
x
x
x 和
y
y
y 之间(即
[
x
;
I
N
F
I
X
;
y
]
[x;\mathrm{INFIX};y]
[x;INFIX;y]),并将此称为中缀调整。
表4(底部)显示中缀调整略低于前缀调整。
我们认为这是因为前缀调整可以影响
x
x
x 和
y
y
y 的激活,而中缀调整只能影响
y
y
y 的激活。
7.4 Initialization
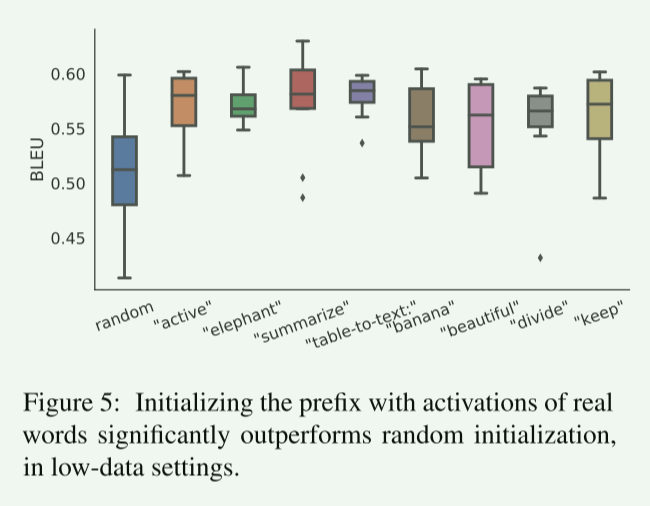
我们发现,在低数据设置中,前缀的初始化方式有很大的影响。
随机初始化导致高方差的低性能。
用实际单词激活初始化前缀可以显著提高生成效果,如图5所示。
特别是,使用任务相关词如“摘要”和“表到文本”初始化比任务无关词如“象”和“除”获得的性能稍好,但使用真实词仍优于随机词。
由于我们用LM计算的实词激活来初始化前缀,这种初始化策略与尽可能保留预先训练的LM是一致的。
8 Discussion
在这一节中,我们将讨论前缀调整的几个有利性质和一些开放的问题。
8.1 Personalization
正如我们在§1中提到的,当有大量任务需要独立训练时,前缀调优是有利的。
一个实用的设置是用户隐私(Shokri and Shmatikov,2015;McMahan et al.,2016)。
为了保护用户隐私,需要分离每个用户的数据,并为每个用户独立训练个性化模型。
因此,每个用户都可以看作是一个独立的任务。
如果有数百万用户,前缀调优可以扩展到此设置并保持模块化,通过添加或删除前缀来灵活地添加或删除用户,而不会造成交叉污染。
8.2 Batching Across Users
在相同的个性化设置下,PrefixTuning允许批处理不同用户的查询,即使它们有不同的前缀支持。
当多个用户用他们的输入查询一个云GPU设备时,将这些用户放在同一批中计算效率很高。
前缀调优保持共享LM不变; 因此,批处理需要一个简单的步骤,将个性化的前缀前置到用户输入,所有剩余的计算都是不变的。
相比之下,我们不能在适配器调优中批处理不同的用户,因为适配器调优在共享的转换器层之间有个性化的适配器。
8.3 Inductive Bias of Prefix-tuning
回想一下,微调会更新所有预先训练的参数,而前缀调优和适配器调优会保留这些参数。
由于语言模型是在通用语料库上进行预训练的,保留LM参数可能有助于将语言模型推广到训练过程中看不到的领域。
根据这一直觉,我们观察到前缀调优和适配器调优在外推设置中都有显著的性能增益(§6.4); 然而,这种收益的原因是一个悬而未决的问题。
虽然前缀调整和适配器调整都冻结了预先训练的参数,但它们调整了不同的参数集来影响变压器的激活层。
回想一下,前缀调整保持LM不变,并使用前缀和预先训练的注意力块来影响后续的激活; 适配器调优在LM层之间插入可训练模块,直接向激活添加剩余向量。
此外,我们观察到,与适配器调优相比,前缀调优需要的参数要少得多,同时保持了相当的性能。
我们认为参数效率的提高是因为前缀调优尽可能保持预训练LM的完整,因此比适配器调优更能利用LM。
Aghajanyan等人(2020)的同时工作。
利用intrinsic dimension证明了存在一个与全参数空间一样有效的低维重参数化微调。
这就解释了为什么只需更新少量参数就能获得下游任务的良好精度。
我们的工作表明,通过更新一个非常小的前缀可以获得良好的生成性能,从而呼应了这一发现。
9 Conclusion
我们提出了前缀调优,这是微调的一种轻量级替代方案,它为NLG任务添加了可训练的连续前缀。
我们发现,尽管学习的参数比微调少了1000倍,但前缀调优可以在完整的数据设置中保持相当的性能,并且在低数据设置和外推设置中都优于微调。
h i ( n ) h_i^{(n)} hi(n) 由键值对组成。在 GPT-2 中,每个键和值的维度是 1024 1024 1024。 ↩︎
在我们的初步实验中,GPT-2和BART在这种情况下失败;唯一的例外是GPT-3。 ↩︎
我们在初步实验中发现,直接优化前缀对学习率和初始化非常敏感。 ↩︎
P θ P_\theta Pθ 的维度为 ∣ P i d s ∣ × dim ( h i ) |\mathrm{P_{ids}}| \times \dim(h_i) ∣Pids∣×dim(hi) 而 P θ P_\theta Pθ 的维度为 ∣ P i d s ∣ × k |\mathrm{P_{ids}}| \times k ∣Pids∣×k,其中我们选择 k = 512 k=512 k=512 用于表到文本,选择 800 800 800 用于摘要。 M L P θ \mathrm{MLP}_\theta MLPθ 从维度 k k k 映射到 dim ( h i ) \dim(h_i) dim(hi)} ↩︎
与 \citet{lin-etal-2020-exploring} 相同的实现。 ↩︎
官方基准模型是在 v.1.0.0 上训练的,而发布数据集是 v1.1.1。 ↩︎
与自然语言话语相比,线性化表的格式不自然,这对预训练的 LM 来说可能具有挑战性。 ↩︎
我们没有包括 GPT-2 结果进行总结,因为在我们的初步实验中,微调 GPT-2 明显低于微调 BART XSUM.} ↩︎
E2E 为 250K,WebNLG 为 250K,DART 为 500K,而 GPT-2 参数为 345M。 ↩︎
WebNLG 中的 S、U、A 列分别代表 SEEN、UNSEEN 和 ALL; S ‾ E E N \underline{S}EEN SEEN 类别出现在训练时; U ‾ N S E E N \underline{U}NSEEN UNSEEN 类别仅在测试时出现; A ‾ L L \underline{A}LL ALL 是两者的组合。 ↩︎
我们还为每个训练集采样了一个dev split(开发大小 = 30% × \times × training size )对于每个训练集 。我们使用dev split来选择超参数并进行提前停止。 ↩︎
括号中的数字是指训练规模。 ↩︎
XSUM 数据集是从 BBC 新闻中提取的,我们根据它们的 URL 来识别每篇文章的主题。由于“新闻”和“体育”是文章最多的两个领域,我们创建了第一个训练/测试拆分。此外,“news”还有子域,例如“UK”、“world”和“technology”。因此,我们创建了第二个数据拆分,使用前 3 个新闻子域作为训练数据,其余作为测试数据。 ↩︎
比阈值长的前缀导致较低的训练损失,但测试性能略差,表明它们倾向于过度拟合训练数据。 ↩︎