Transformer与注意力机制
1. RNN基础
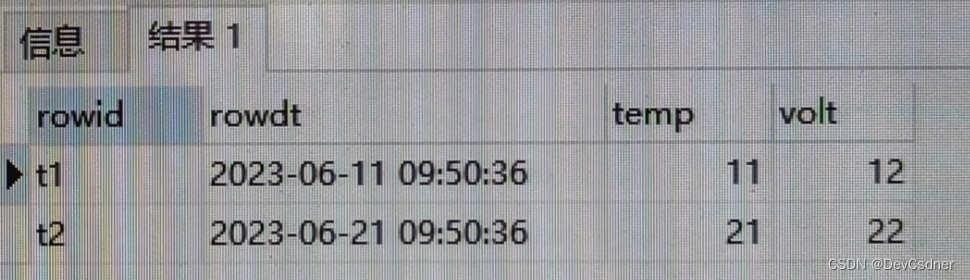
循环神经网络(RNN)是专门用来处理自然语言、金融信息等时序数据的一种神经网络。它的结构和运作方式如下图所示,基于马尔可夫决策模型。
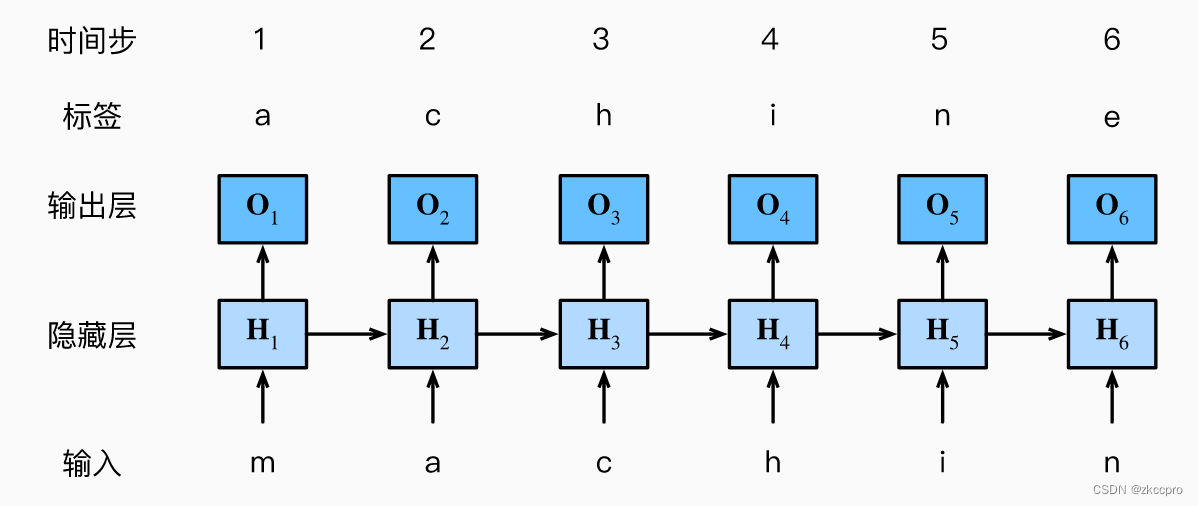
图1 循环神经网络的结构和运作方式
应该注意到以下几个性质:
-
RNN是串联处理输入数据的。(时序中靠后的输入依赖前面一个输入的隐层输出值)
-
RNN层数不固定,但总共只有3个参数组(输入参数、隐藏参数、输出参数),**各层之间共享权重。**其实这也好理解,因为时序序列中每一个输入输出的映射关系,应该与其在时序中所处的位置无关。所以RNN各层的权重应该共享,实际只训练了一层的参数。
-
RNN中的梯度消失:与CNN不同,RNN梯度消失是指:被时序输入中 较近距离输入主导,易被远距离输入忽略。
2. Transformer架构
 图2 Transformer架构
图2 Transformer架构
可以看到,整个Transformer是由n个编码器和n个解码器连接而成的。其中,每个编码器的输出可以给到所有解码器作为输入。Transformer在NLP领域取得了十分卓越的成果,因此2017年谷歌提出Transformer的论文题目为:“Attention ls All you Need”,这种略显狂妄的标题。
但Transformer在NLP领域的效果确实值得狂妄,而且不仅如此,2021年还有研究者把Transformer用于CV领域(ViT, Vision Transformer),在图像分类任务中取得了很不错的效果。
2.1 Embedding(嵌入层)
Embedding可以看成是时序数据的预处理,在NLP领域可通过word2vec等方式处理。比如说一段文本:[我爱你],有3个字符,Embedding时我们把每个字符都转换成一个512维的行向量。那么这段文本就可以被转换成一个 3行512列 的矩阵,那么这个矩阵就是嵌入层输出的结果。
2.2 位置编码
下图可以很好的看明白位置编码(position coding)的工作原理。对于[我爱你]这段文本,中的[爱]字:在Embedding中不是把它变成512维行向量了嘛,那么我们对这个Embedding中的每个行向量中每个元素应用如下公式,那么就会得到一个新的3行512列的位置编码矩阵。
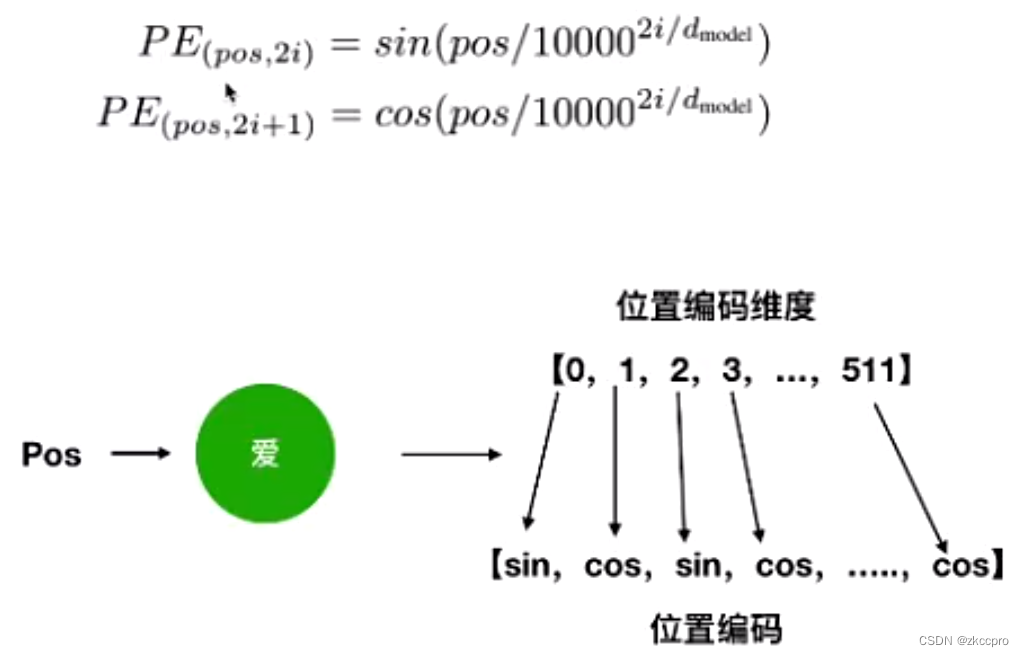
图3 位置编码公式
然后,把position coding和Embedding得到的两个同大小矩阵逐元素相加就能得到一个新的同大小矩阵。那么这个矩阵就是最终输入到Transformer中的数据。
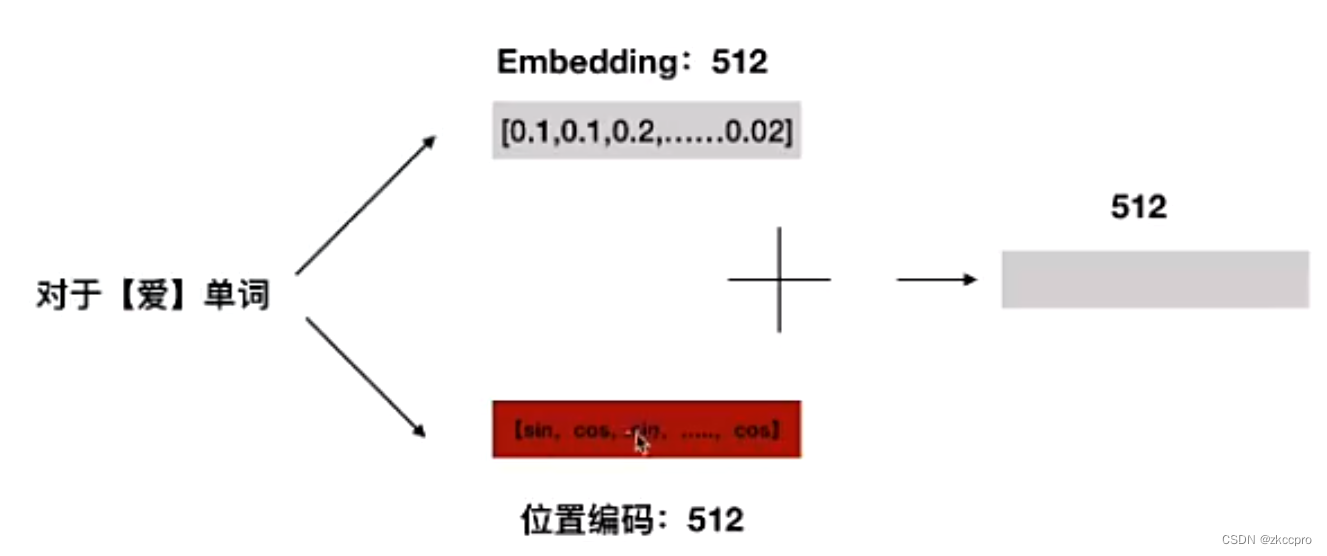
图4 位置编码与Embedding相加
为什么位置编码会有效呢?是因为序列中奇偶下标的单词交替使用正弦和余弦进行编码中隐含了单词之间的相对位置信息。(可以由三角函数性质推导得来)
2.3 自注意力机制
NLP领域提出了很多注意力机制,但这种注意力机制和CV领域之前SE那种注意力机制好像没什么关系。NLP注意力机制起到的作用就是CV中的卷积。
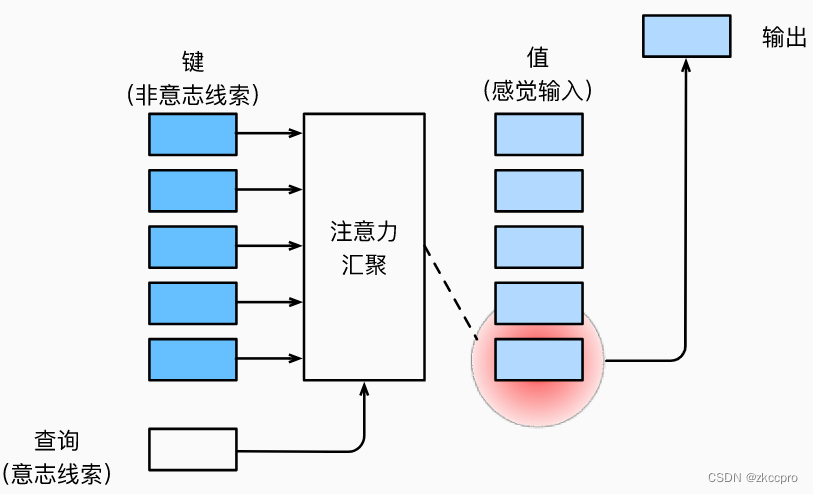
图5 NLP领域注意力机制架构
其中有几个概念需要弄懂:
- 查询:仿生注意力过程中的某些 自主性提示。(比如我【想】学习了,就会注意到书本)
- 键:仿生注意力过程中的 非自主性提示。(比如我突然发现有个东西【与众不同】)
- 值:仿生注意力过程中的 感官输入。(可以理解成信息进入大脑前的中间表示)
在Transformer中使用的自注意力模块中,以上3个东西都是根据权重训练得出的中间表示。(类比于CNN中卷积层之后的输出)
基于以上的架构,我们就可以理解Transformer中使用的自注意力机制是什么了:
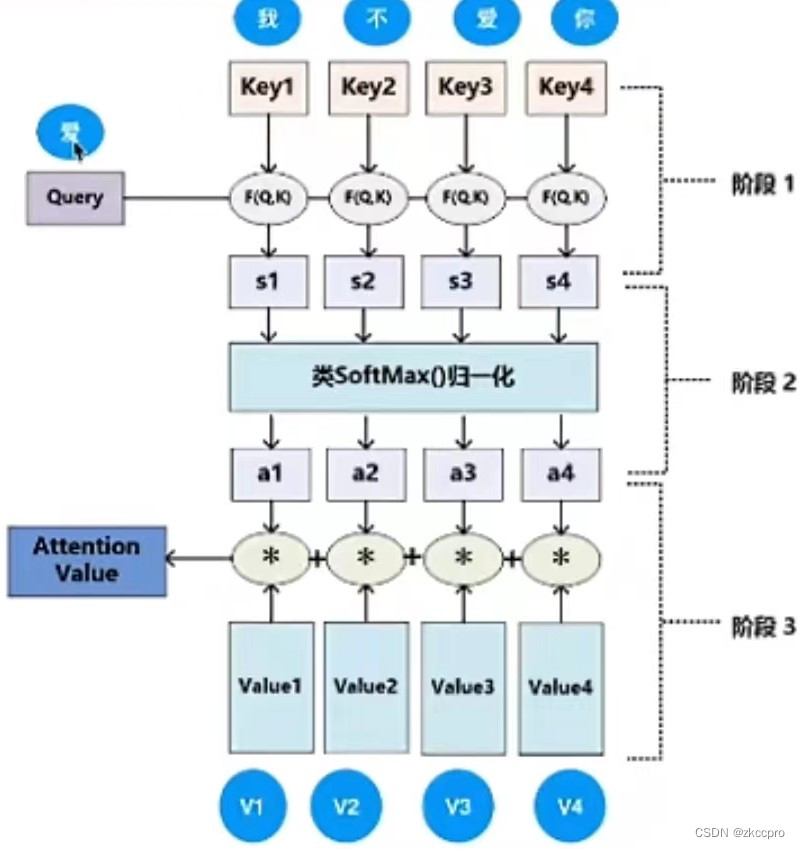
图6 注意力计算
图6解释了如下公式的计算过程:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
[
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
]
V
(1-1)
Attention(Q,K,V)=[softmax(\frac{QK^T}{\sqrt{d_k}})]V\tag{1-1}
Attention(Q,K,V)=[softmax(dkQKT)]V(1-1)
这个式子算出的值就是图6中蓝色框的Attention Value。式中Q、K、V 3个矩阵分别代表 查询、键 和 值。这3个矩阵是由输入矩阵(Embedding+position coding)和3个权重矩阵相乘得来的,如下图所示:
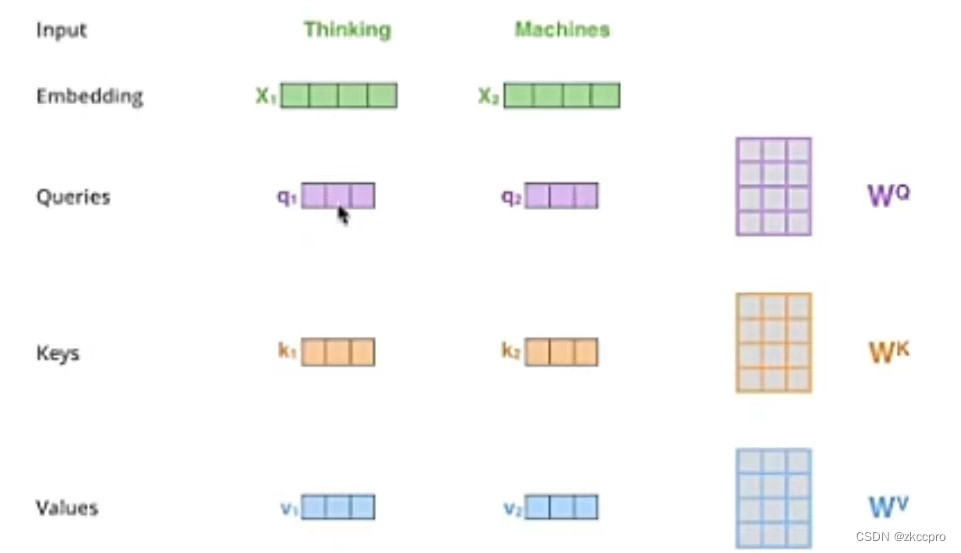
图7 Q、K、V 3个矩阵的计算过程
图中,Wq、Wk、Wv是参与训练的权重矩阵。当然了,实际输入不是一个单词向量,而是一个文本矩阵。那就在上图演示的基础上升级为矩阵乘法就完事了,也容易理解。
好的,至此应该清楚注意力机制的运作过程了,但Transformer用的是**【多头自注意力机制】**。啥意思呢?实际上也很好理解,就是图7中Wq、Wk、Wv矩阵不仅只有一套,而是有多套:[[Wq1, Wk1, Wv1],[Wq2, Wk2, Wv2]...[Wqn, Wkn, Wvn]]。每一套权重矩阵分别和输入矩阵相乘得到一组K、Q、V矩阵。如此,就可以得到多组K、Q、V矩阵:[[Q1, K1, V1],[Q2, K2, V2]...[Qn, Kn, Vn]],这n组KQV矩阵经过(1-1)的计算就可以得到多组Attention Value,我们称为[z1, z2, ..., zn]。
最后,多头注意力模块把这些[z1, z2, ..., zn]输出到下一环节。
2.4 残差和规范化的使用
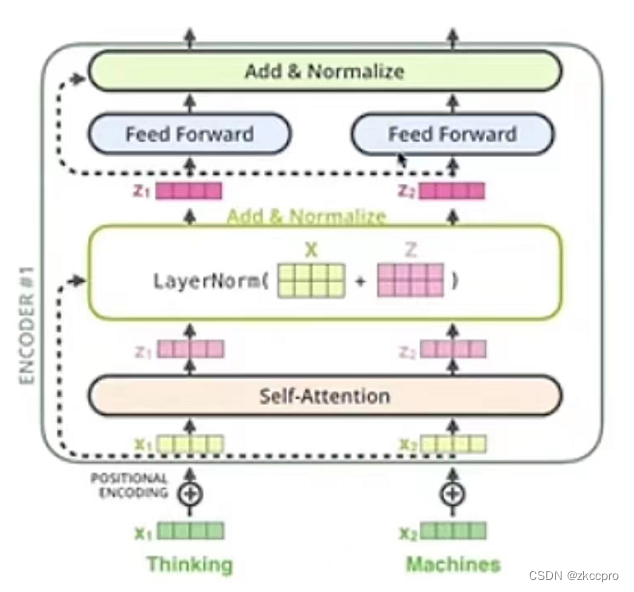
图8 编码器中的规范化块和残差块
这张图可以很好的说明多头注意力块、规范化块、前馈神经网络(MLP)之间的逻辑关系,解码器也是类似。
可以看到,图7中的虚线就是一个残差连接,残差连接后进行 层规范化(LayerNorm),层规范化 和 批规范化的区别见我之前另一篇文章。在CV领域 批规范化 在batch_size较大时可以取得一些效果(但也不一定),不过在NLP问题中是不可以使用 批规范化 的。为啥呢?因为数据的长度可能不一样,如果批规范化的话可能会导致类似于CV中batch_size过小而使用 批规范化 的问题。
3. ViT, Vision Transformer
Vision Transformer是2021年提出的一种用于CV任务的Transformer模型,其中完全不含卷积,把图像输入看成时序输入模型。经过试验在分类问题上也取得了不错的效果:
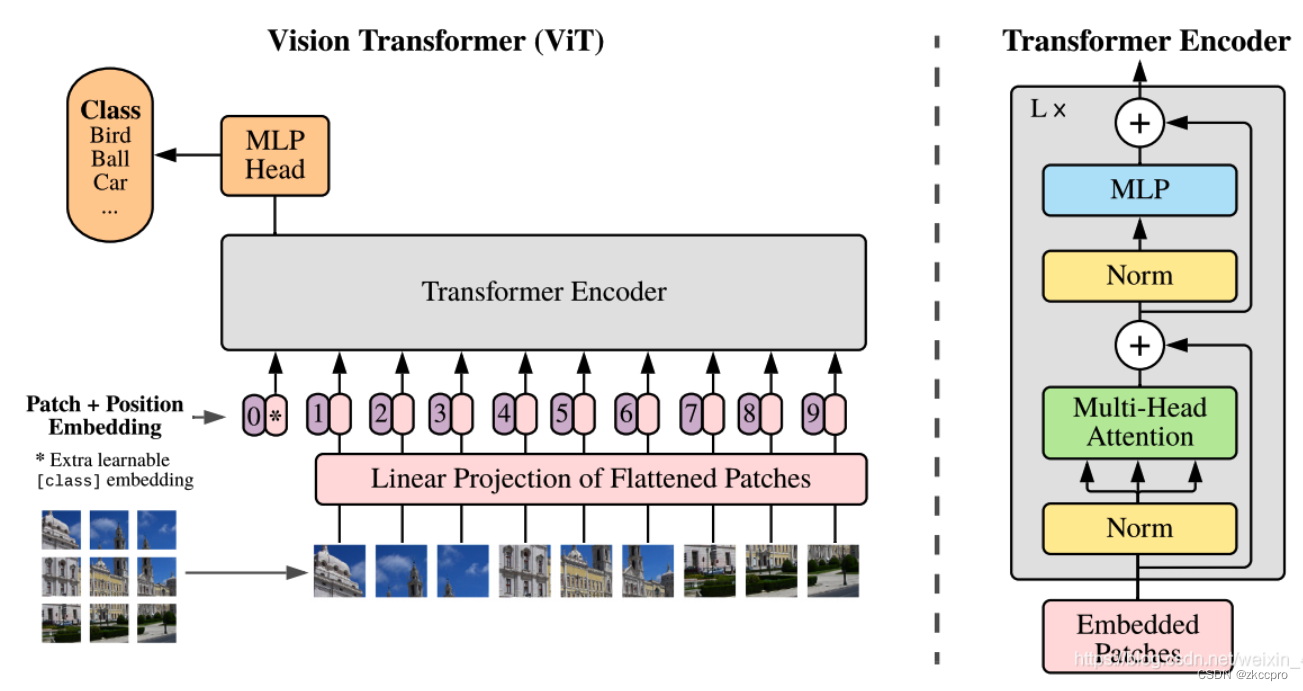
图9 ViT应用于CV分类任务
有这样几个特点可以注意一下:
- 把图像拆成若干小块,以序列化的形式输入模型。
- 不同于NLP Transformer中的position coding,这里的位置编码是可供网络学习的参数。
- ViT目前只用到了编码器部分,没用到解码器。