动手点关注

干货不迷路
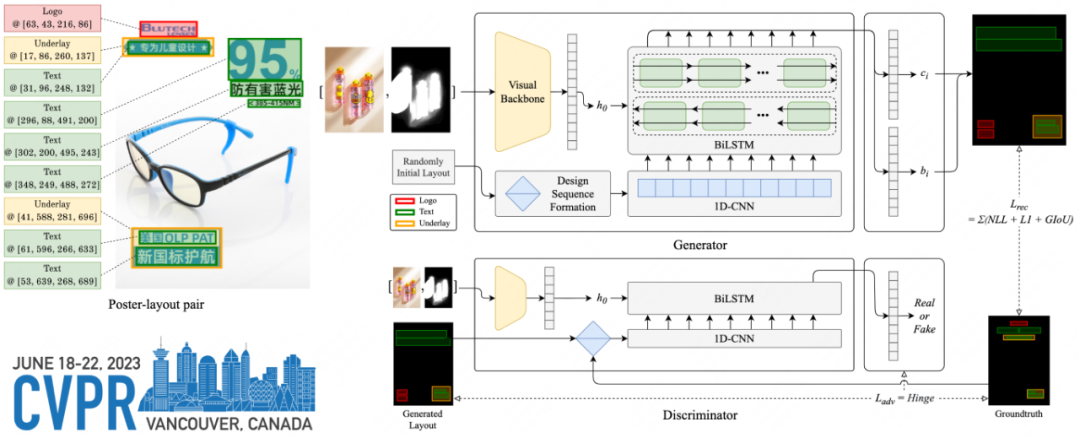
字节跳动与英伟达, 加州大学河滨分校联合发表的论文 《ByteTransformer: A High-Performance Transformer Boosted for Variable-Length》在第 37 届 IEEE 国际并行和分布式处理大会(IPDPS 2023)中,从 396 篇投稿中脱颖而出,荣获了最佳论文奖。该论文提出了字节跳动的 GPU transformer 推理库——ByteTransformer。针对自然语言处理常见的可变长输入,论文提出了一套优化算法,这些算法在保证运算正确性的前提下,成功避免了传统实现中的冗余运算,实现了端到端的推理过程的大幅优化。另外, 论文中还手动调优了 transformer 中的 multi-head attention, layer normalization, activation 等核心算子, 将 ByteTransformer 的推理性提升至业界领先水平。与 PyTorch, TensorFlow, NVIDIA FasterTransformer, Microsoft DeepSpeed-Inference 等知名的深度学习库相比,ByteTransformer 在可变长输入下最高实现131%的加速。论文代码已开源。
ByteTransformer: A High-Performance Transformer Boosted for Variable-Length Inputs ( https://arxiv.org/abs/2210.03052 )
IPDPS: 并行和分布式计算方向计算机系统领域的旗舰会议。该会议专注于分享并讨论并行计算,分布式计算,大规模数据处理以及高性能计算等相关领域的最新研究进展。参与的专家学者来自世界各地的顶尖研究机构和企业,共同探讨该领域的创新发展和前沿技术。
code: https://github.com/bytedance/ByteTransformer
transformer 变长文本 padding free
transformer 在自然语言处理(NLP)中被广泛使用,随着 BERT、GPT-3 等大型模型的出现和发展,transformer 模型的重要性变得越来越突出。这些大型模型通常具有超过一亿个参数,需要大量的计算资源和时间进行训练和推理。因此,优化 transformer 性能变得非常重要。
现有的一些深度学习框架,如 Tensorflow,PyTorch,TVM 以及 NVIDIA TensorRT 等,要求输入序列长度相同,才能利用批处理加速 transformer 计算。然而,在实际场景中,输入序列通常是变长的,而零填充会引入大量的额外计算开销。有一些方法在 kernel launch 前对具有相似 seqlen 的输入分组,以最小化 padding,但无法实现 padding free。字节跳动 AML 团队先前提出的“effective transformer” [4],通过对输入的重排列,实现了 QKV projection 和 MLP 的 padding free,但 self attention 部分仍然需要 padding。
为了解决这个问题,字节跳动 AML 团队提出了 ByteTransformer,它实现了变长输入的 padding free 计算,并且实现了全面的 kernel fusion 以进一步提高性能。
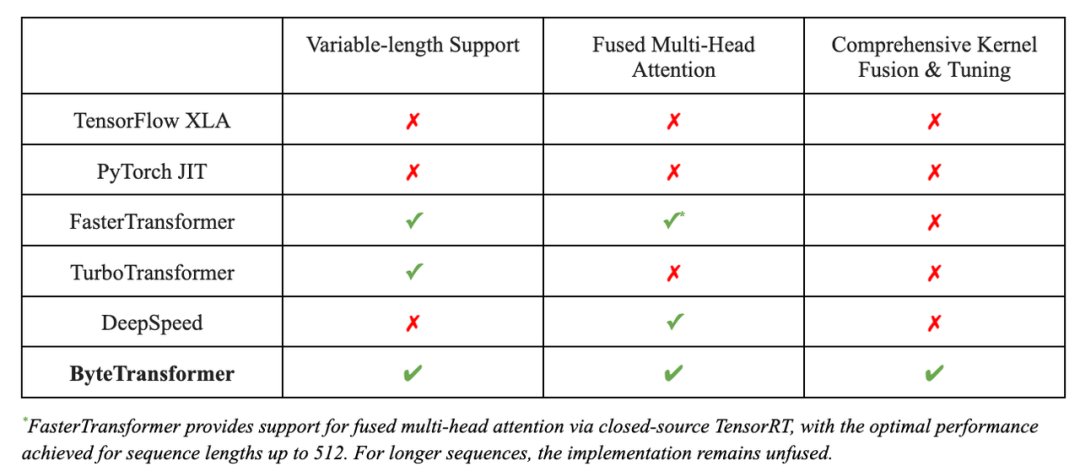
图一: ByteTransformer 与其他工作 feature 对比
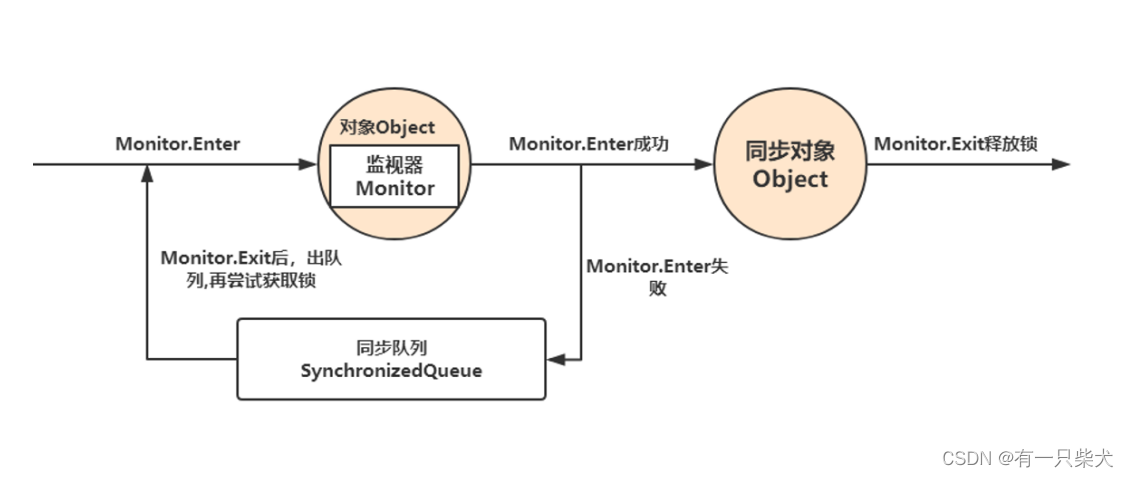
Remove padding 算法
这个算法源自字节跳动 AML 团队之前的工作 "effective transformer",在 NVIDIA 开源 FasterTransformer 中也有集成。ByteTransformer 同样使用该算法去除对 attention 外矩阵乘的额外计算。
算法步骤:
1)计算 attention mask 的前缀和,作为 offsets
2)根据 offsets 把输入张量从 [batch_size, seqlen, hidden_size] 重排列为 valid_seqlen, hidden_size] ,再参与后续的矩阵乘计算,实现 padding free
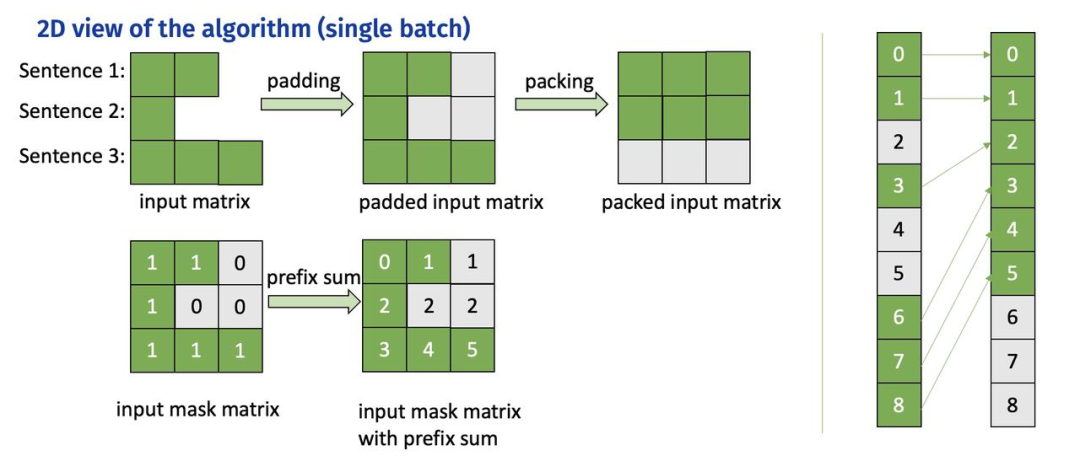
图二:Remove padding 算法过程
FMHA (Fused Multi-Head Attention)
为了优化 attention 部分的性能,ByteTransformer 中实现了 fused multi-head attention 算子。对于 seqlen 长度, 以 384 为界划分为两种实现方式:
对于短 seqlen, 因为可以把 QK 整行放在共享内存进行 softmax 操作, 通过手写 kernel 的方式实现, 矩阵乘通过调用 wmma 接口使用 TensorCore 保证高性能。
对于长 seqlen, 因为共享内存大小限制,不能在一个手写 kernel 中完成所有操作。基于高性能的 CUTLASS[5] grouped GEMM, 分成两个 gemm kernel 实现, 并把 add_bias, softmax 等操作 fused 到 GEMM kernel 中。
CUTLASS grouped GEMM
NVIDIA 开发的 grouped GEMM 可以在一个 kernel 中完成多个独立矩阵乘问题的计算,利用这个性质可以实现 Attention 中的 padding free。
Attention 中的两次矩阵乘操作,都可以拆解为
batch_size x head_num个独立的矩阵乘子问题。每个矩阵乘子问题,把问题大小传入到 grouped GEMM,其中 seqlen 传递真实的 valid seqlen 即可。
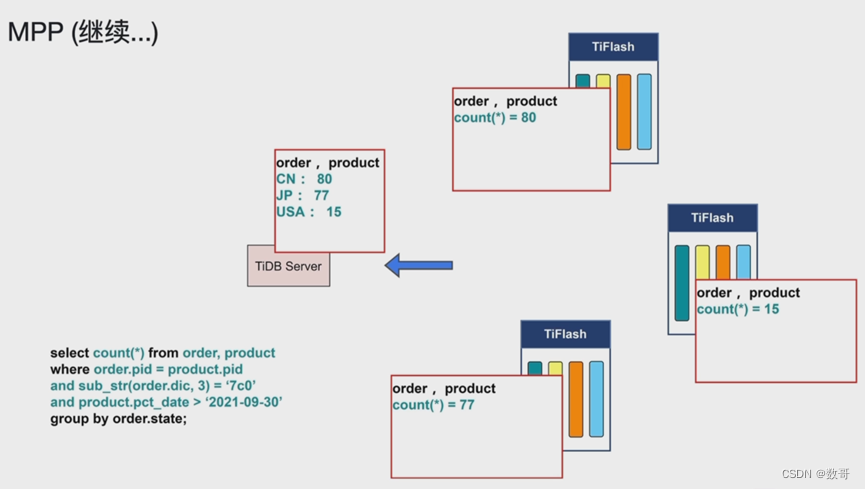
grouped GEMM 原理:kernel 中每个 threadblock (CTA) 固定 tiling size,每个矩阵乘子问题根据 problem size 和 tiling size,拆解为不同数量的待计算块,再把这些块平均分配到每个 threadblock 中进行计算。
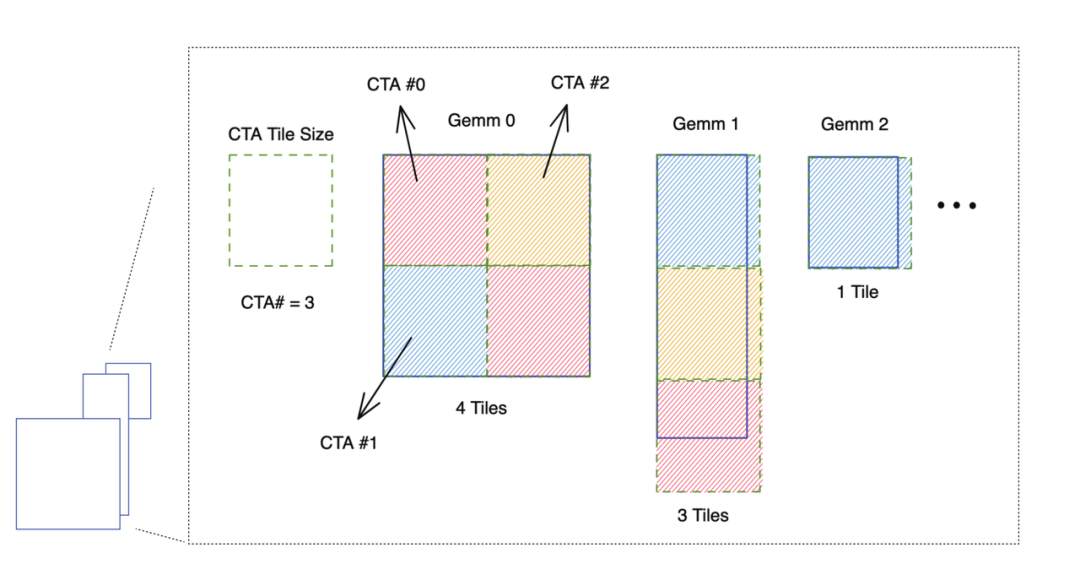
图三:grouped GEMM 原理示意图。每个子问题拆解为不同数量的块,再对这些块均匀分配,高效地实现单个 kernel 计算多个独立 GEMM 问题。
使用 grouped GEMM 实现 attention 时,由于子问题的数量 batch_size x head_num 通常较大,读取子问题参数会有不小的开销,因为从线程角度看,每个线程都需要遍历读取所有的子问题大小。
为了解决这个问题,ByteTransformer 对 grouped GEMM 中读取子问题参数进行了性能优化,使其可以忽略不计:
1)共享子问题参数。 对同一个输入,不同 head 的 valid seqlen 相同,problem size 也相同,通过共享使参数存储量从 batch_size x head_num 减少到 batch_size
2)warp prefetch. 原始实现中,每个 CUDA thread 依次读取所有的子问题 problem size,效率很低。改为一个 warp 内线程读取连续的 32 个子问题参数,然后通过 warp 内线程通信交换数据,每个线程的读取次数降低到 1/32
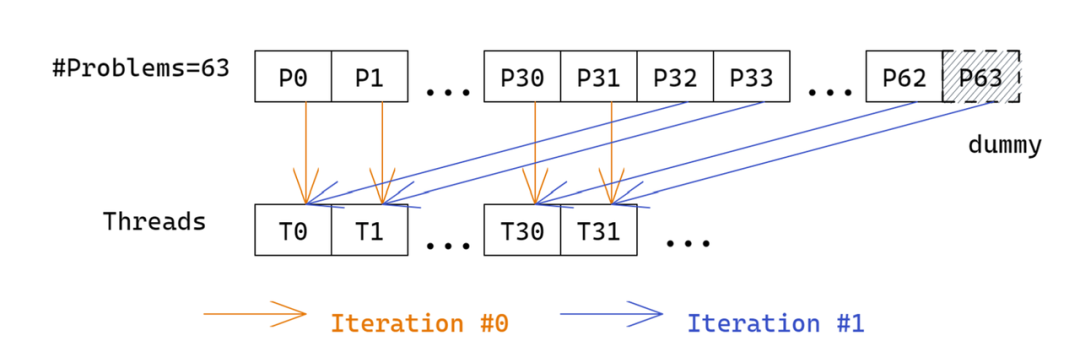
图四:warp prefetch 示意图。每个 iteration 一个 warp 读取 32 个子问题 size
softmax fusion
为了进一步提高性能,把 Q x K 之后的 softmax 也 fuse 到矩阵乘算子中,相比单独的 softmax kernel 节省了中间矩阵的访存操作。
因为 softmax 需要对整行数据做归约,但因为共享内存大小的限制,一个 threadblock 内不能容纳整行数据,同时 threadblock 间的通信很低效,所以不能仅在 Q x K 的 epilogue 中完成整个 softmax 的操作。把 softmax 拆分成三步计算,分别 fuse 到 Q x K 的 epilogue 中, QK x V 的 prologue 中,以及中间再添加一个轻量的 kernel 做规约。
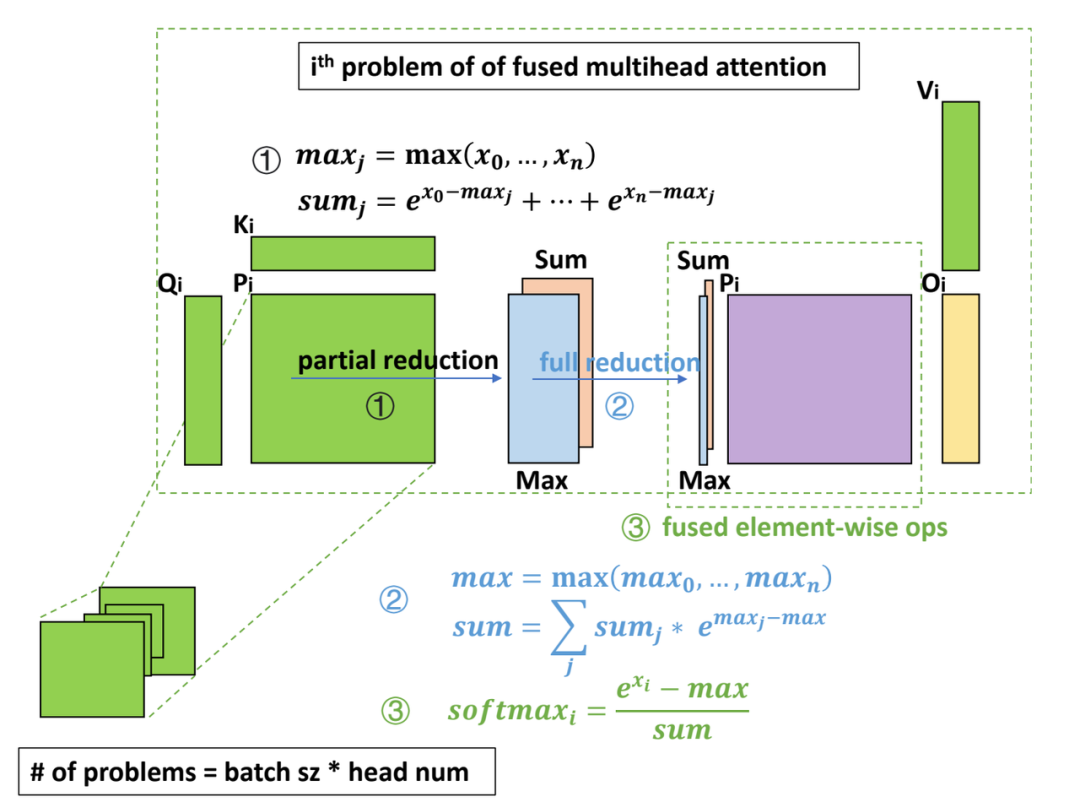
图五:softmax fusion 流程示意图。分为三步计算,大部分计算 fuse 到前后的 GEMM kernel 中
算法步骤:
1)partial reduction:Q x K 的 epilogue 中,每个 threadblock 内部规约,计算出 max 和 sum 两个值
2)full reduction:一个轻量级的 kernel,把每一行的 partial reduction 结果继续规约到整行的结果
3)element-wise op:修改了 CUTLASS 的代码,使其支持 prologue fusion,即在加载输入矩阵后,fuse 一些 element-wise 的操作。在 QK x V 的 prologue 中,读取当前行的规约结果,计算出 softmax 的最终结果,再参与后续的矩阵乘计算
性能数据
短 seqlen 手写 kernel 的性能
在 <= 384的短 seqlen 情况下,cuBLAS batch GEMM 相比 PyTorch MHA 性能提高 5 倍,而启用 zero padding 算法优化 softmax 后进一步提高 9% 的性能,ByteTransformer 的 MHA 把两个 batched GEMM 和中间的 softmax 完全 fuse 成一个 kernel,相比三种变体实现,平均加速分别为 617%、42% 和 30% 。

图六:手写 attention kernel 性能对比。注:cuBLAS + zero padding 指对 softmax 的 zero padding
长 seqlen CUTLASS kernel 的性能
在 448~1024 seqlen 下, cuBLAS batched GEMM 比 PyTorch 的 MHA 性能提高了3倍,同时对 softmax 的 zero padding,进一步提高了 17% 的性能,通过引入高性能的 CUTLASS grouped GEMM 以及 softmax fusion,ByteTransformer 的 fused MHA 比变体 MHA 实现的性能提高了451%,110% 和 79% 。
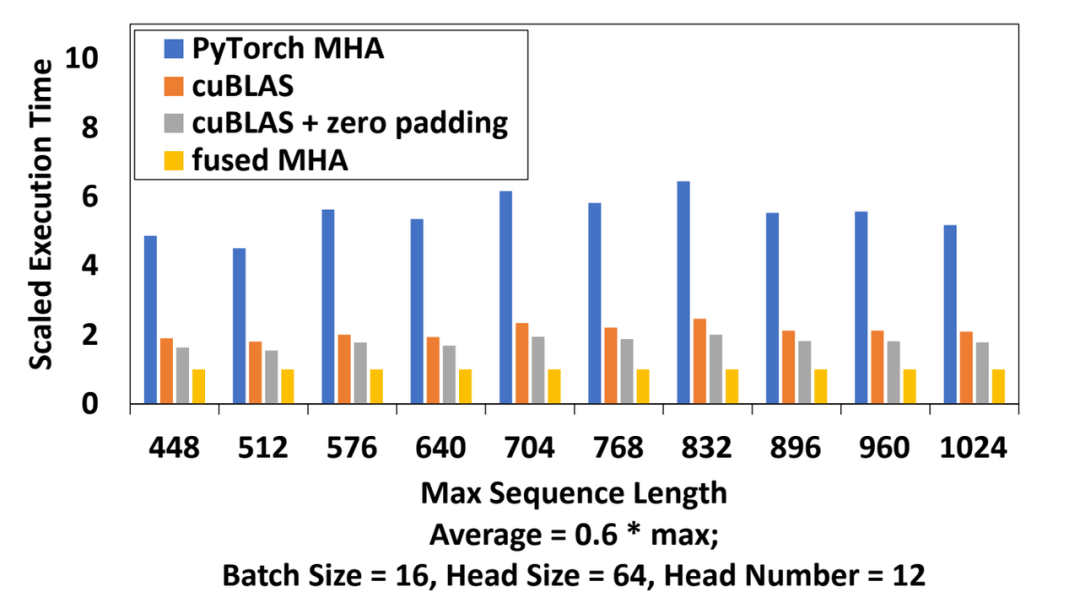
图七:长 seqlen CUTLASS FMHA 性能对比
全面的 kernel fusion
除矩阵乘和 attention 的优化外,ByteTransformer 还对一些小的操作进行了全面的 kernel fusion,通过减少显存访问和 kernel launch 的开销,可以获得更极致的性能。
add-bias & LayerNorm fusion
矩阵乘之后的 add-bias 和 LayerNorm 操作,通过手写 kernel 的方式做 fusion,这部分操作在 seqlen 为 256 和 1024 的情况下分别占 10% 和 6% 的延迟,fused kernel 可以优化 61% 的性能,对单层 BERT transformer 的性能提升 3.2% (平均 seqlen 128 - 1024 的情况)。
GEMM & add-bias & GELU fusion
通过 CUTLASS fuse epilogue 的方式,把矩阵乘后的 add-bias 操作和 GELU activation 操作 fuse 到矩阵乘 kernel 中。add-bias 和 GELU 在 seqlen 为 256 和 1024 的情况下占比耗时分别为 7% 和 5%。把 add-bias 和 GELU 融合 GEMM 可以完美隐藏这部分的访存延迟,进一步使单层 transformer 性能提升 3.8% 。
变种 transformer 支持
目前,字节跳动 AML 团队已经在 GitHub 上开源了 ByteTransformer 的标准 BERT 实现(https://github.com/bytedance/ByteTransformer)。除此之外,字节内部版本还支持了许多 transformer 变种,比如 Deberta, Roformer,T5 等等。代码实现易于拓展,并且上述各种优化手段也可以方便地应用到变种 transformer 中。
更多性能数据
与其他 transformer 实现的端到端性能对比
实验配置:标准 BERT transformer,head size = 64, head number = 12, layer = 12, 平均 valid seqlen = 0.6 * 最大 seqlen,使用 A100 GPU 进行测试。比较在 seqlen=64~1024,batch_size=1,8,16 情况下的性能表现。相比 PyTorch JIT, TensorFlow XLA, Tencent TurboTransformer, Microsoft DeepSpeed-Inference 和 NVIDIA FasterTransformer,分别平均加速 87%, 131%, 138%, 74% 和 55%
注:在论文投稿时,PyTorch 和 NVIDIA FasterTransformer 还没有集成 FlashAttention [6]
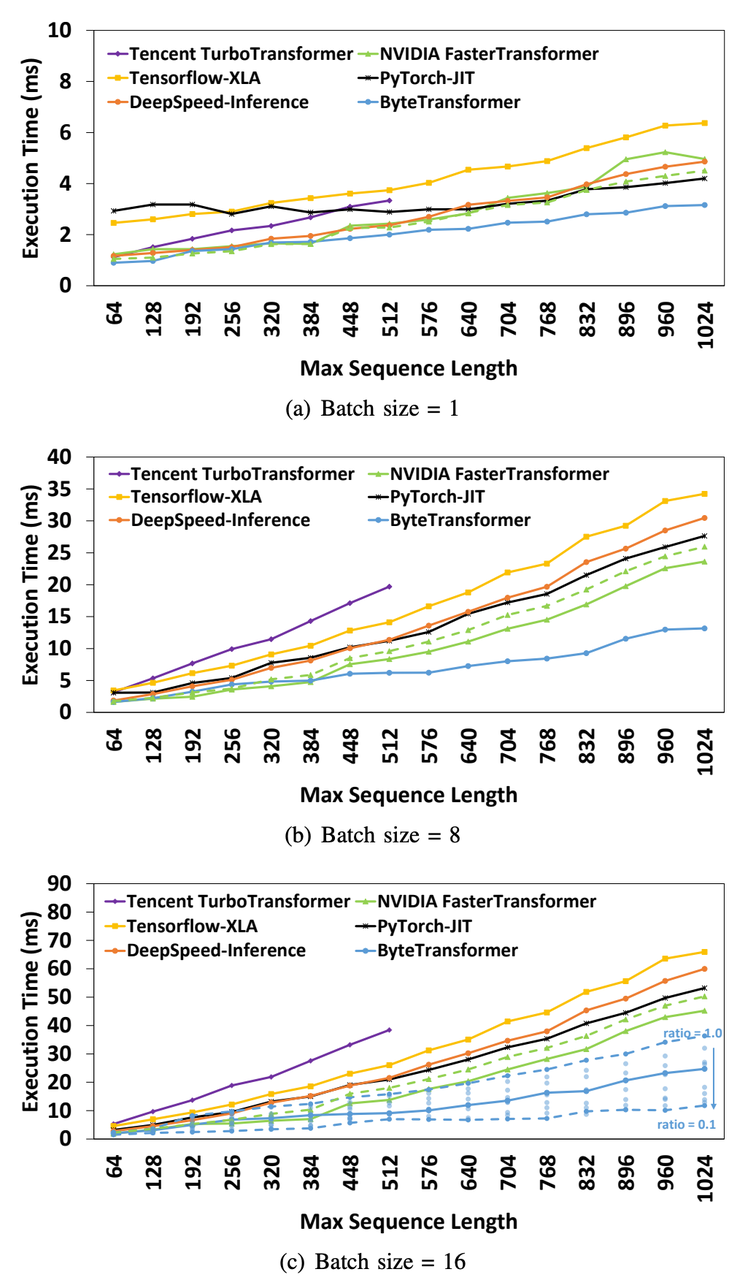
图八:各 transformer 实现的端到端性能对比
各优化手段影响拆解
与 ByteTransformer 自己的基线版本对比,开启各种优化后总体相对基线提升 60%。拆解各优化手段对性能的影响如下:
add-bias & LayerNorm fusion 可以提高性能 3.2%
将 add-bias & GELU fuse 到 GEMM epilogue 可以进一步提高 3.8%
引入 remove padding 算法,性能提高 24%
FMHA 额外提高 20%
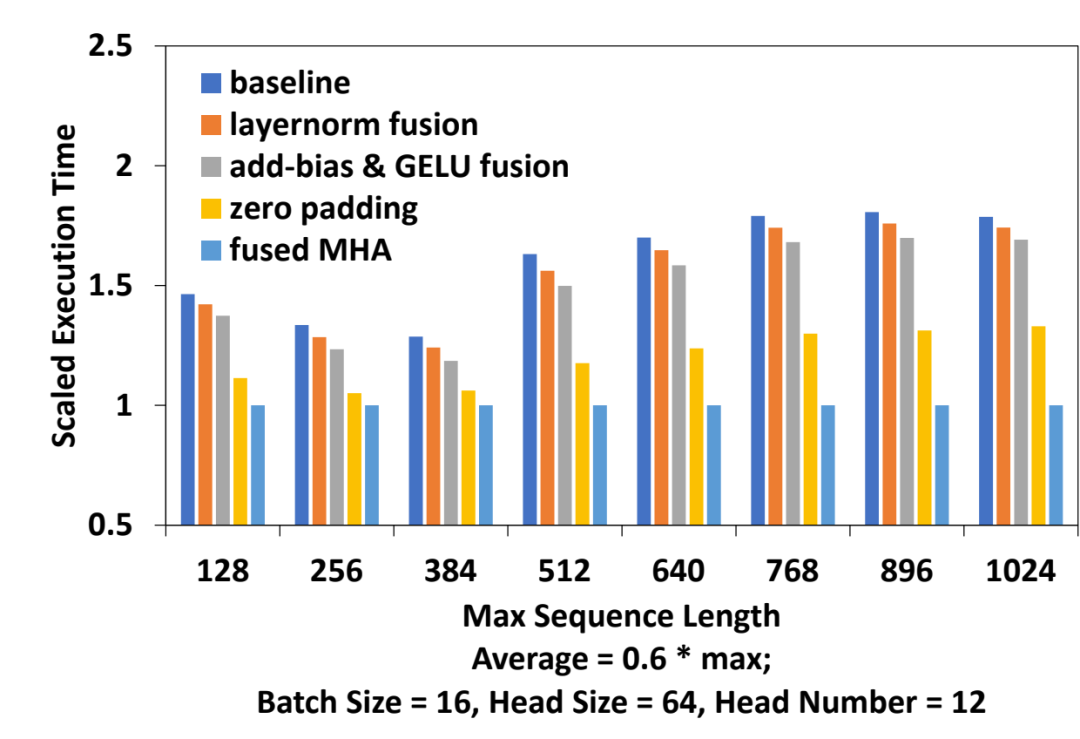
图九:各优化手段性能提升拆解
BERT-like 变种的性能对比
比较 ByteTransformer 在 ALBERT, DistilBERT 和 DeBERTa 这几种模型结构下与最先进的 DL 框架的性能表现。实验配置与标准 BERT 一致,平均 seqlen 为 0.6*最大 seqlen。
对于 ALBERT 和 DistilBERT,ByteTransformer 平均比 PyTorch、TensorFlow、Tencent TurboTransformer、DeepSpeed-Inference 和 NVIDIA FasterTransformer 分别快98%、158%、256%、93% 和 53%。对于 DeBERTa 模型,ByteTransformer 比PyTorch、TensorFlow 和 DeepSpeed 分别快 44%、243% 和 74%。

图十:BERT-like 变种的性能对比。部分数据点缺失是因为对应框架不支持或无法成功运行
结论
ByteTransformer 是一种高效的 transformer 实现,它通过一系列优化手段,实现了在 BERT transformer 上的高性能表现。对于变长文本输入,相比其他 transformer 实现,ByteTransformer 具有明显的优势,实验中平均加速可达 50% 以上。适用于加速自然语言处理任务,提高模型训练与推理的效率。同时,ByteTransformer 也为其他研究者提供了一种高效的 transformer 实现方式。其优化手段和性能表现对于实际应用具有重要意义。
字节跳动 AML 团队介绍
AML 是字节跳动公司的机器学习中台,为抖音/今日头条/西瓜视频等业务提供推荐/广告/CV/语音/NLP的训练和推理系统。为公司内业务部门提供强大的机器学习算力,并在这些业务的问题上研究一些具有通用性和创新性的算法。同时,也通过火山引擎将一些机器学习/推荐系统的核心能力提供给外部企业客户。
更多 AML 岗位火热招聘中,欢迎扫描下方二维码,了解详情,进行投递


引用:
[1] J. Fang, Y. Yu, C. Zhao, and J. Zhou, “Turbotransformers: an efficient gpu serving system for transformer models,” in Proceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, 2021, pp. 389–402.
[2] R. Y. Aminabadi, S. Rajbhandari, M. Zhang, A. A. Awan, C. Li, D. Li, E. Zheng, J. Rasley, S. Smith, O. Ruwase et al., “Deepspeed inference: Enabling efficient inference of transformer models at unprecedented scale,” arXiv preprint arXiv:2207.00032, 2022.
[3] NVIDIA, https://github.com/NVIDIA/FasterTransformer
[4] ByteDance https://github.com/bytedance/effective_transformer
[5] NVIDIA https://github.com/NVIDIA/cutlass
[6] T. Dao, D. Y. Fu, S. Ermon, A. Rudra, and C. Re, “Flashattention: Fast ´ and memory-efficient exact attention with io-awareness,” arXiv preprint arXiv:2205.14135, 2022.