书接上文,从开源库中把代码下载到本地后,就可以在 IDE 中进行运行了。从 main 方法入手,可以看到 ProGuard 执行的第一步就是去解析参数。本文的内容主要分析源码中我们配置的规则解析的实现。
在上一篇文章末尾,在 IDE 中,添加了 @/Users/xxx/debug_proguard.pro 作为函数运行的入参,将配置文件的路径传递给 ProGuard 使用。先来看一下 Main 函数中的代码:
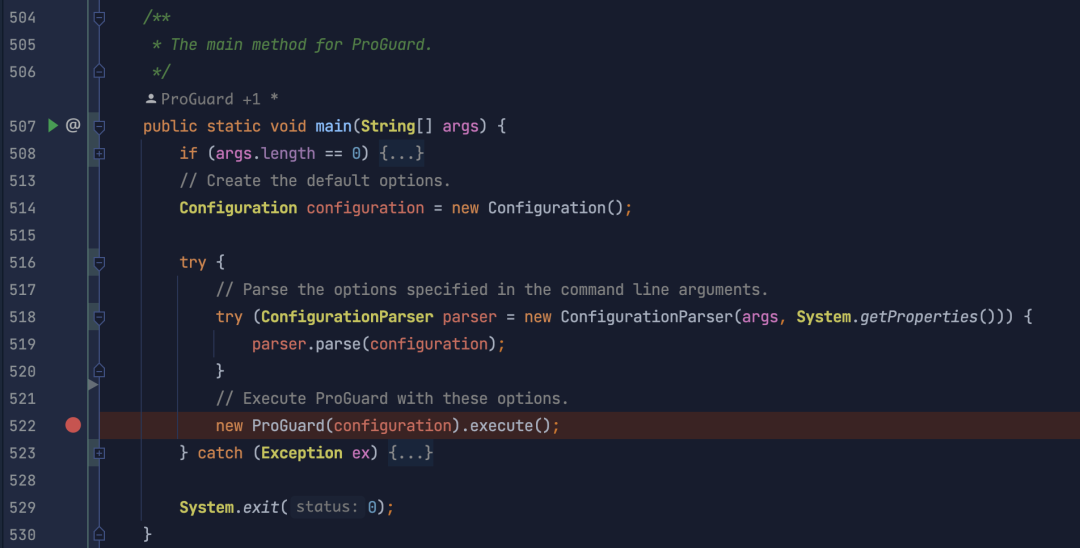
从这几行代码可以看出,ProGuard 的大体运行逻辑。在代码 518 行中,通过入参 args 和 系统属性配置 创建了一个配置解析器 ConfigurationParser ,随后调用其 parse 方法,解析传入的参数,并将结果放到 configuration 中,以供后续混淆逻辑使用。
try-with-resources 语法
在代码 518 行处,创建 ConfigurationParser 时,使用了 Java 1.7 中提供的 try-with-resources 语法。此语法可以帮助我们关闭流。举个例子,我们现在需要从一个文件中读取第一行内容。在 Java 1.7 之前,代码将会如下:
static String readFirstLineFromFile(String path) throws IOException {
FileReader fr = new FileReader(path);
BufferedReader br = new BufferedReader(fr);
try {
return br.readLine();
} finally {
br.close();
fr.close();
}
}从代码中可以看到,在 finally 代码块中,需要手动对 FileReader 、BufferedReader 进行关闭。而使用 try-with-resources 语法后,就无需手动调用 close 方法。示例代码如下:
static String readFirstLineFromFile(String path) throws IOException {
try (FileReader fr = new FileReader(path); BufferedReader br = new BufferedReader(fr)) {
return br.readLine();
}
}这样,代码能精简很多,close 也不会因为开发者的疏忽而被遗漏。
配置读取
为了更好地理解整个读取与解析的内容,我画了一个简单的流程图。在 ProGuard 中读取配置文件的逻辑中,会按照一个个单词 为单位进行读取,根据代码中的流程,绘制如下流程图,能够更好地理解代码内容。
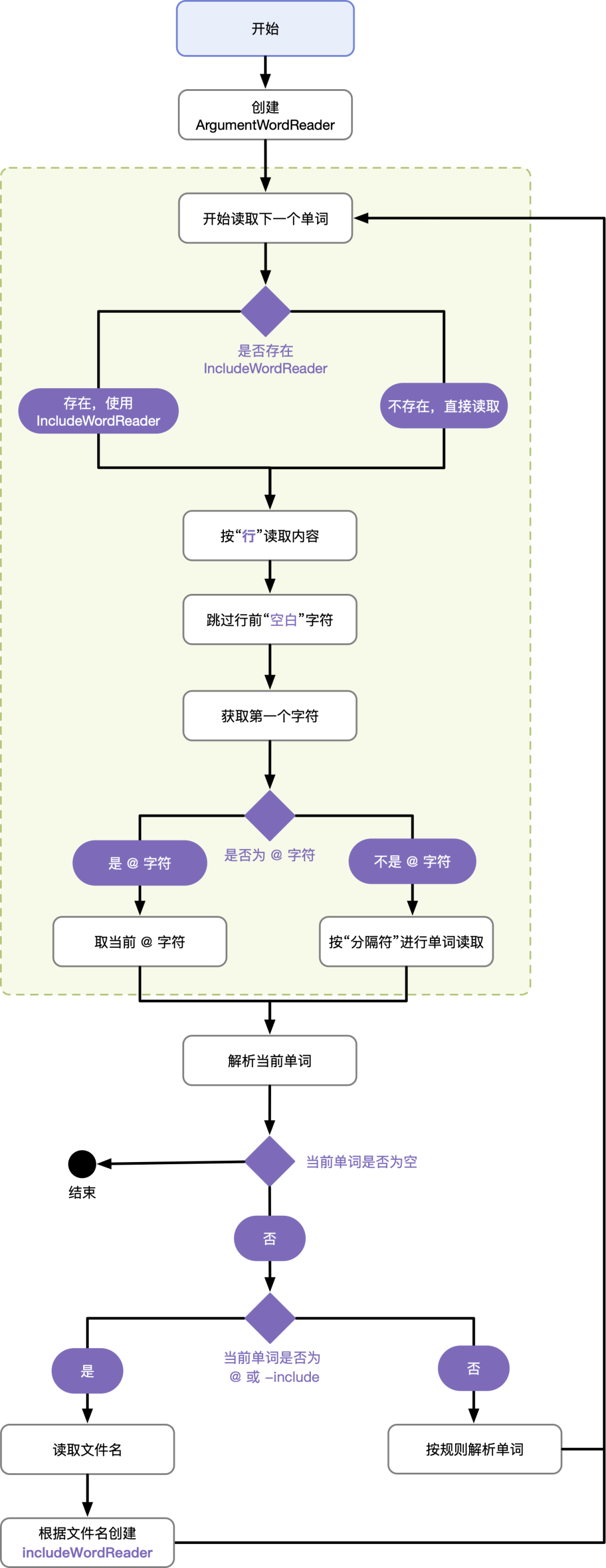
根据上面的流程图,在来看源码实现。首先是 ConfigurationParser 的构造方法,实现代码如下:
public ConfigurationParser(String[] args, Properties properties) throws IOException {
this(args, null, properties);
}
public ConfigurationParser(String[] args, File baseDir, Properties properties) throws IOException {
this(new ArgumentWordReader(args, baseDir), properties);
}
public ConfigurationParser(WordReader reader, Properties properties) throws IOException{
this.reader = reader;
this.properties = properties;
readNextWord();
}在构造方法中,使用入参中的 args 和 系统属性配置 创建了一个 ArgumentWordReader。顾名思义,它是用来读取运行代码时传入的程序参数的。
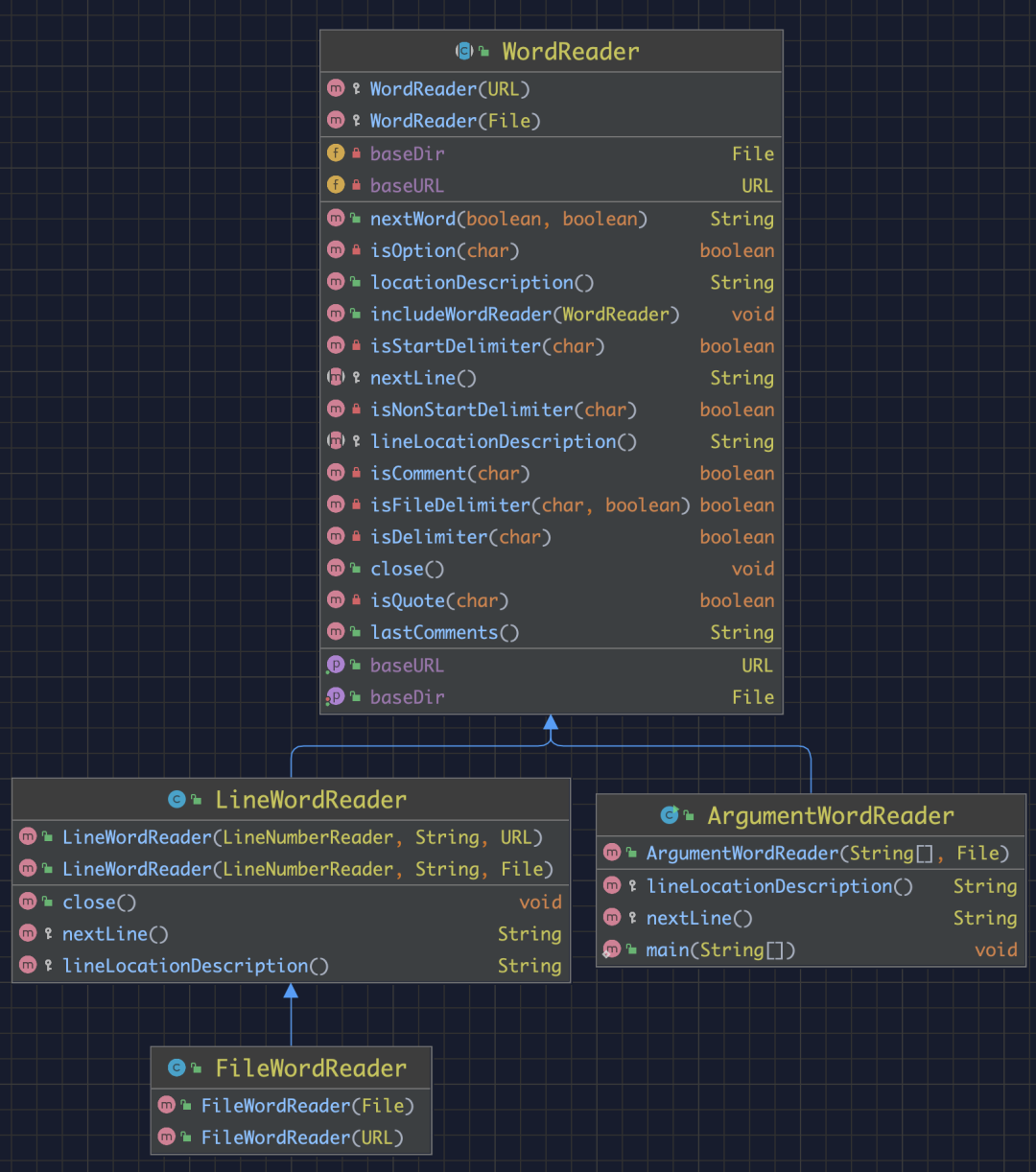
在 WordReader 的设计中,内容读取是按行读取的。在 LineWordReader 和 FileWordReader 中,直接使用 LineNumberReader 按行读取。而对于 ArgumentWordReader,实现逻辑会更简单一些,直接将前面提到的 args 数组中的每一个 String 作为一行字符串处理。
接下来,在看构造方法的最末尾:调用了 readNextWord() 方法,此为流程中开始读取下一个单词,也是为了获取第一个 「单词」。来看一下代码是如何实现的:
private void readNextWord() throws IOException {
readNextWord(false, false);
}
private void readNextWord(boolean isFileName, boolean expectSingleFile) throws IOException {
nextWord = reader.nextWord(isFileName, expectSingleFile);
}代码的逻辑里最终调用了 reader.nextWord,此处的 reader 就是刚才提到的 ArgumentWordReader。运行时会使用它去读取第一个「单词」。讲到这里,不由得让我想起了大学时编译原理中讲的 词法分析器。有感兴趣的同学可以去巩固一下《编译原理》。因为 ProGuard 定义的规则相对简单,所以此处的逻辑比一门编程语言简单许多。在运行代码时,只传了一个参数:@/Users/xxx/debug_proguard.pro。在解析时,它会作为一行直接进行处理。先来看一下代码:
public String nextWord(boolean isFileName, boolean expectSingleFile) throws IOException {
currentWord = null;
// 省略部分代码
while (currentLine == null || currentIndex == currentLineLength) {
// 读取有效的参数行
currentLine = nextLine();
}
// Find the word starting at the current index.
int startIndex = currentIndex;
int endIndex;
// 取第一个字符
char startChar = currentLine.charAt(startIndex);
// 省略部分代码
else if (isDelimiter(startChar)) {
// 如果是分格符,如 @, {, }, (, )等符号
endIndex = ++currentIndex;
}
else {
// 其它情况处理逻辑
}
// 截取,此处的 currentWord 就是解析出来的 @ 符号
currentWord = currentLine.substring(startIndex, endIndex);
return currentWord;
}
// 是否为分隔符,如果是,则返回 true
private boolean isDelimiter(char character) {
return isStartDelimiter(character) || isNonStartDelimiter(character);
}
private boolean isStartDelimiter(char character) {
return character == '@';
}
private boolean isNonStartDelimiter(char character) {
return character == '{' ||
character == '}' ||
character == '(' ||
character == ')' ||
character == ',' ||
character == ';' ||
character == File.pathSeparatorChar;
}在读取的过程中,首先将整行数据存储在 currentLine 中,当前此处为 @/Users/xxx/debug_proguard.pro,紧接着会从 currentLine 中取 第一个 字符,因为 @ 是分隔符,因此会将它作为第一个 「单词」。代码执行到这里,构造方法里面涉及的逻辑也执行结束,ConfigurationParser 创建完成。下一步就是调用 parse 方法,去执行解析操作,代码如下:
public void parse(Configuration configuration) throws ParseException, IOException {
while (nextWord != null) {
// 是 @ 或者是 -include 执行
if (ConfigurationConstants.AT_DIRECTIVE.startsWith(nextWord) || ConfigurationConstants.INCLUDE_DIRECTIVE.startsWith(nextWord))
configuration.lastModified = parseIncludeArgument(configuration.lastModified);
// 省略其它代码
}
}在 parse 方法中,会循环遍历所有的 「单词」,直到所有单词都处理完毕。现在只需要看 @ 的处理逻辑,在代码中,如果当前 「单词」为 @ 和 -include 时,会调用 parseIncludeArgument 去实现解析的逻辑。 @ 符号的定义是 以递归的方式从给定的文件中读取配置选项 , 从它的定义就可以看出来, parseIncludeArgument 会去解析 @ 后指的文件名称,并读取文件内容。
private long parseIncludeArgument(long lastModified) throws ParseException, IOException{
// 读取 @ 后面跟着的文件名
readNextWord("configuration file name", true, true, false);
URL url = null;
try {
// Check if the file name is a valid URL.
url = new URL(nextWord);
} catch (MalformedURLException ex) {
}
if (url != null) {
// 给当前 reader 设置一个 includeWordReader
reader.includeWordReader(new FileWordReader(url));
}
// 省略部分代码
readNextWord();
return lastModified;
}代码中可以看到,在执行时,首先会调用 readNextWord 去获取文件名。与前面 @ 获取类似,从 currentLine 中读取出剩下的部分,作为文件名称。获取到文件名称后,就会直接使用这个名称去创建一个 FileWordReader,用于读取此文件中的内容。当然,这里创建的 FileWordReader 还需要赋值给 ArgumentWordReader 的成员变量 includeWordReader。调用 ArgumentWordReader 的 nextWord 方法时,会先调用 includeWordReader.nextWord(xx, xx) 方法,以此来实现递归读取配置文件,实现 @ 符号所定义的功能,如前面的流程图所示。调用 includeWordReader 去获取下一个「单词」的逻辑如下:
if (includeWordReader != null) {
// 读取下一个字符
currentWord = includeWordReader.nextWord(isFileName, expectSingleFile);
if (currentWord != null) {
return currentWord;
}
// 读取完成后,将 reader 关掉,并且置空
includeWordReader.close();
includeWordReader = null;
}此处的 FileWordReader 和 ArgumentWordReader 的核心逻辑基本相似。在 FileWordReader 中,nextLine 方法从指定的文件中读取真实的数据行,而文件行读取使用的是 JDK 中的 LineNumberReader。逻辑不复杂,有兴趣的朋友可自行查阅原文。
配置解析
从文件中读取到配置信息后,需要解析当前的「单词」,并按照固定的逻辑进行处理。在前面的内容中,已经涉及到了配置解析。在 ProGuard 中,有许多配置和不同的规则,可以通过查看源代码来了解。在 ProGuard 中,配置规则分为多个类别。下面将从 输入/输出选项 和 -keep 选项 这两个部分进行分析,以点带面,了解 ProGuard 中配置解析的逻辑。
输入/输出选项
先来看 -injars 、-outjars 、-libraryjars 的实现,当读取到这几个单词时,解析的执行如下:

可以看到,这三个参数的解析,都是调用的 parseClassPathArgument 来实现的,且 -injars 和-outjars 都是放在 configuration.programJars 中的。 以 Android 的项目为例,编译结束时,会生成 R.jar 文件,以及一个 classes 文件夹,因此 -injars 的配置如下:
-injars /project_dir/build/intermediates/compile_r_class_jar/release/R.jar
-injars /project_dir/build/intermediates/javac/release/classes因此,在解析方法中,按文件路径读取下一个「单词」,然后添加到对应的 classpath 中即可。在源代码中,还会存在文件分割符等逻辑,直接上代码:
private ClassPath parseClassPathArgument(ClassPath classPath, boolean isOutput, boolean allowFeatureName) {
// 读取第一个文件路径
readNextWord("jar or directory name", true, false, false);
while (true) {
// 创建一个 ClassPathEntry
ClassPathEntry entry = new ClassPathEntry(file(nextWord), isOutput, featureName);
// 读取下一个单词,可能是文件分隔符,在 mac os 中为 :
readNextWord();
// …… 省略读取 filter 的代码 ……
// 将 ClassPathEntry 添加到 classpath 中
classPath.add(entry);
// 是否已经读取完成了? 如果只有一个文件名,如示例中的,就直接结束了。
if (configurationEnd()) {
return classPath;
}
// 如果不为 路径分隔符 ,直接抛异常
if (!nextWord.equals(System.getProperty("path.separator"))) {
throw new ParseException("Expecting class path separator '" + ConfigurationConstants.JAR_SEPARATOR_KEYWORD + "' before " + reader.locationDescription());
}
// 读取下一个文件路径
readNextWord("jar or directory name", true, false, false);
}
}-keep 选项
在写 ProGuard 规则中, keep 的规则是相对比较复杂的,根据个人的理解,将 keep 的解析规则用 EBNF 进行描述,如下所示,能够更好的理解其逻辑。

解析思路与 输入/输出选项 类似,先根据当前的单词判断是否为 keep_keywords ,代码如下:
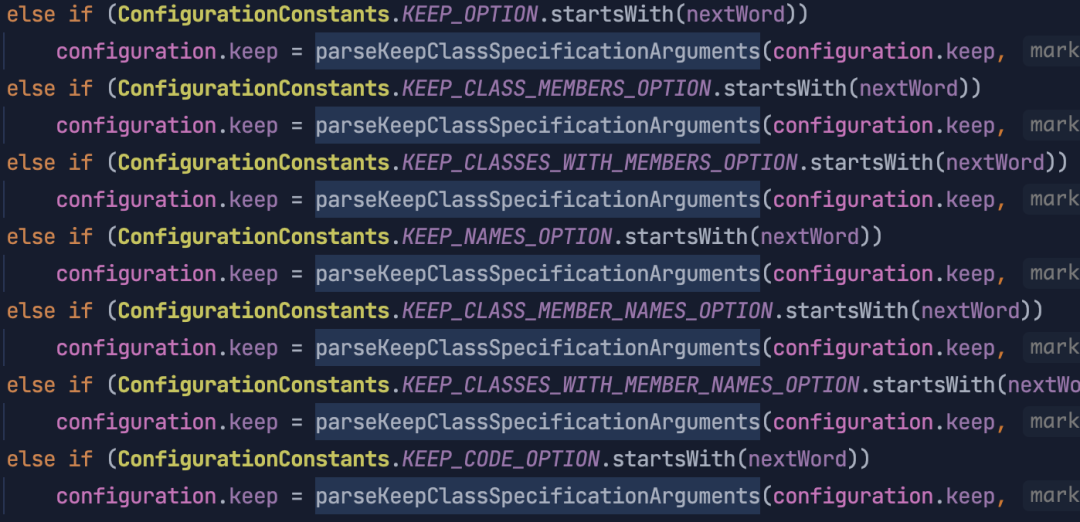
从代码中可以看到,所有 keep_keywords 的解析都调用到了 parseKeepClassSpecificationArguments 中,些方法的解析逻辑,与 EBNF 中描述的基本一致,先看代码执行的流程图:
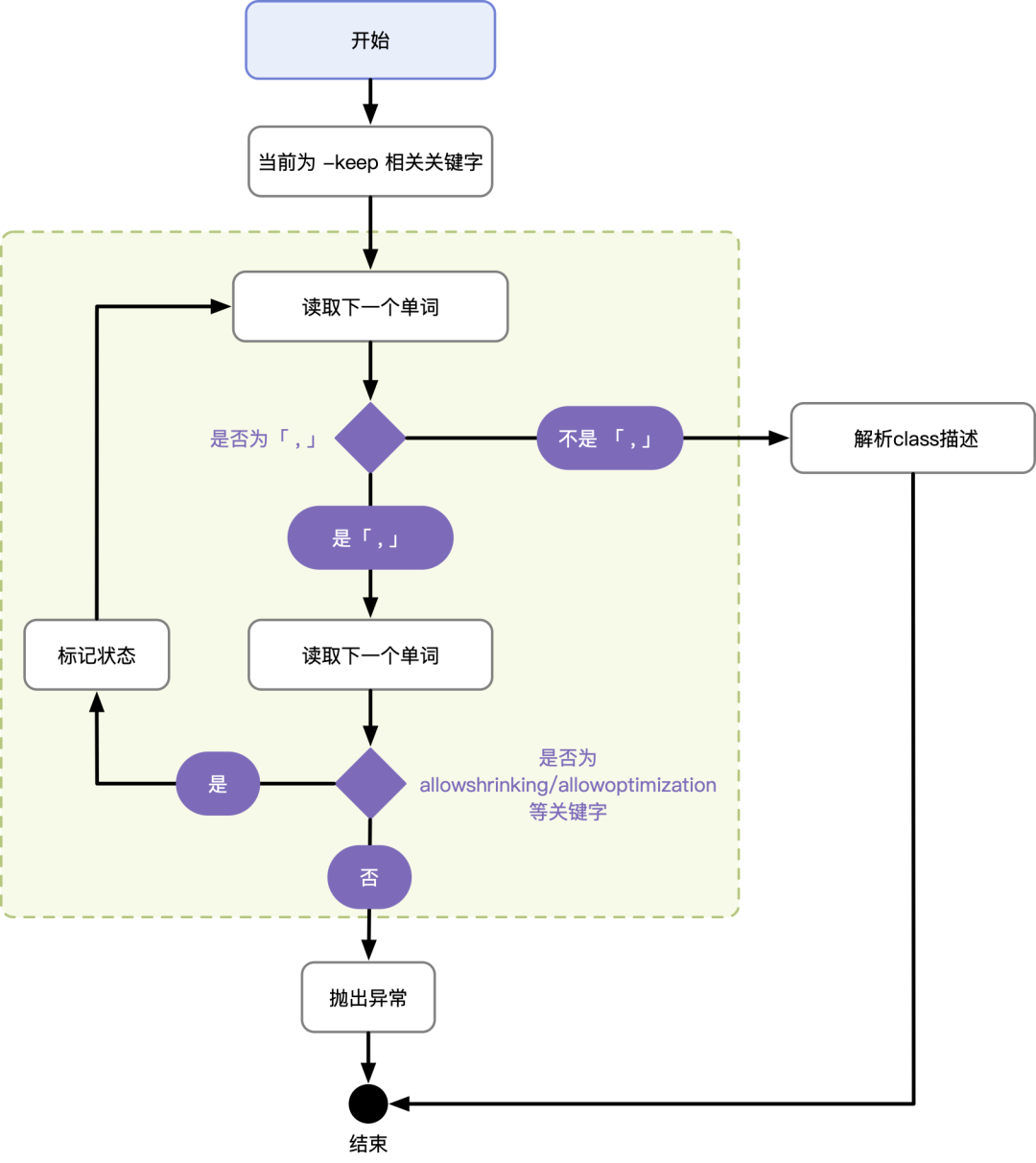
代码中实现逻辑与上述流程图一致, 源码如下:
while (true) {
// 1. 读取 -keep 后的单词,
// 例如配置规则为: -keep class com.example.MainClass
// 则此时读取的单词为 class
readNextWord("keyword ...", false, false, true);
// 2. 判断读了的单词是否为 「,」 号,如果是,后面会跟其它命令,
// 例如配置规则为:
// -keep, allowobfuscation class Test
// 此时 nextWord 的值就为 「,」
if (!ConfigurationConstants.ARGUMENT_SEPARATOR_KEYWORD.equals(nextWord)) {
// 如果不为 「,」 则直接退出循环
break;
}
// 3. 读取后面的 allowshrinking / allowoptimization / allowobfuscation 等
readNextWord("keyword '" + ConfigurationConstants.ALLOW_SHRINKING_SUBOPTION + "'");
// 4. 标记参数
if (ConfigurationConstants.ALLOW_SHRINKING_SUBOPTION.startsWith(nextWord)) {
allowShrinking = true;
} else if (ConfigurationConstants.ALLOW_OPTIMIZATION_SUBOPTION.startsWith(nextWord)) {
allowOptimization = true;
} else if (ConfigurationConstants.ALLOW_OBFUSCATION_SUBOPTION.startsWith(nextWord)) {
allowObfuscation = true;
} else {
throw new ParseException("Expecting keyword ...");
}
}
// 5. 解析配置规则后的 class_specification
ClassSpecification classSpecification = parseClassSpecificationArguments(false, true, false);有前面的 EBNF 描述以及流程图,代码逻辑看起来就会非常的简单。紧接着是解析 class_specification ,先来看一下它的 EBNF 描述,如下图所示:
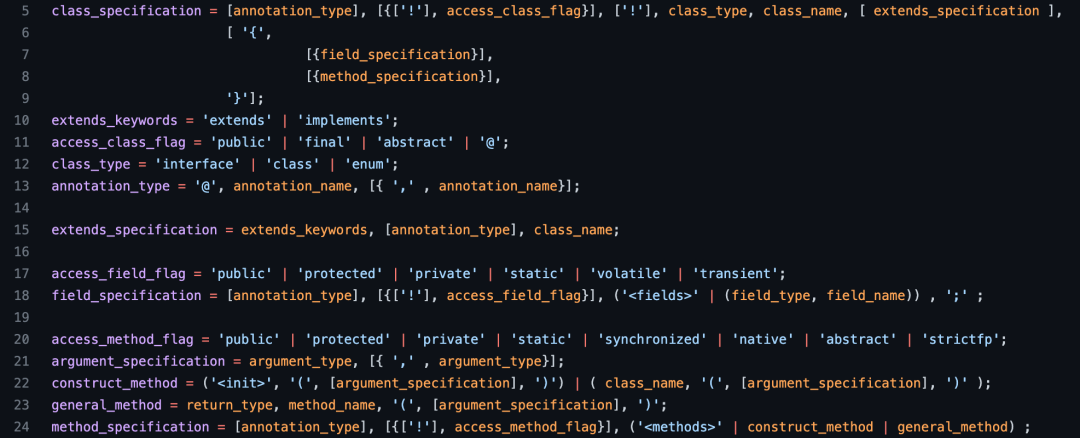
PS: 在 ProGuard 的使用文档中,也有描述 class_specification 的信息,但是并非是 EBNF 格式,有兴趣的同学可以看看: https://www.guardsquare.com/manual/configuration/usage#classspecification
根据 EBNF 的描述,就可以按照其描述规则进行解析。但上面的描述中,还有 annotation_name 、class_name 、method_name 、return_type 、argument_type、field_type 等标识符的描述并没有写出来。这里,写需要对他们进行简单的梳理。因为这个名称都是用来描述 Java 中相应的 类名 、方法名 、变量名 的信息,所以:
这些名称一定是符合 java 标识符的规则,即它们由数字(0~9)、字母(a~z 和 A~Z)以及
$和_组成,且第一个符号只能是字母、$或_中的一个。在
annotation_name、class_name、field_type等实际描述的是 Java 类名时,使用的是全路径信息,其中包含包名路径,因此名称会出现.这个符号 , 例如:com.example.Test、java.lang.Object在描述方法返回值(retrun_type)、方法参数(argument_type)或变量类型(field_type) 时,可能会有数组存在,所以
[]也可能会出现,例如:public java.lang.Object[] getList();在 ProGuard 规则中,名称还能使用通配符,其中包括
*、?、.、<n>、%
基于这些规则,先来看一下代码实现:
private void checkJavaIdentifier(String expectedDescription, boolean allowGenerics) throws ParseException {
if (!isJavaIdentifier(nextWord)) {
throw new ParseException("Expecting ...");
}
if (!allowGenerics && containsGenerics(nextWord)) {
throw new ParseException("Generics are not allowed (erased) in ..."));
}
}
public boolean isJavaIdentifier(String word) {
if (word.length() == 0) {
return false;
}
for (int index = 0; index < word.length(); index++) {
char c = word.charAt(index);
if (!(Character.isJavaIdentifierPart(c) || c == '.' ||
c == '[' || c == ']' || c == '<' || c == '>' || c == '-' ||
c == '!' || c == '*' || c == '?' || c == '%')) {
return false;
}
}
return true;
}看完标识符的匹配规则,在来看完整定义的 annotation_name、class_name 等名称的读取逻辑,在代码中,都会调用到 parseCommaSeparatedList 里面去,顾名思义,此方法会根据 , 解析一个列表出来,直接看代码:

代码中仅保留了关键代码,从注释中可以看到,拿到「单词」后,会先检查是否为一个合法标识符,如果符合,就添加到列表中去,并读取下一个「单词」,如果是 , 会继续上述逻辑进行添加,反之返回列表。
在回到上层的解析逻辑中来,根据 EBNF 的描述, 需要先判断是否有 annotation_type 和 access_flag, 这一块的逻辑如下:
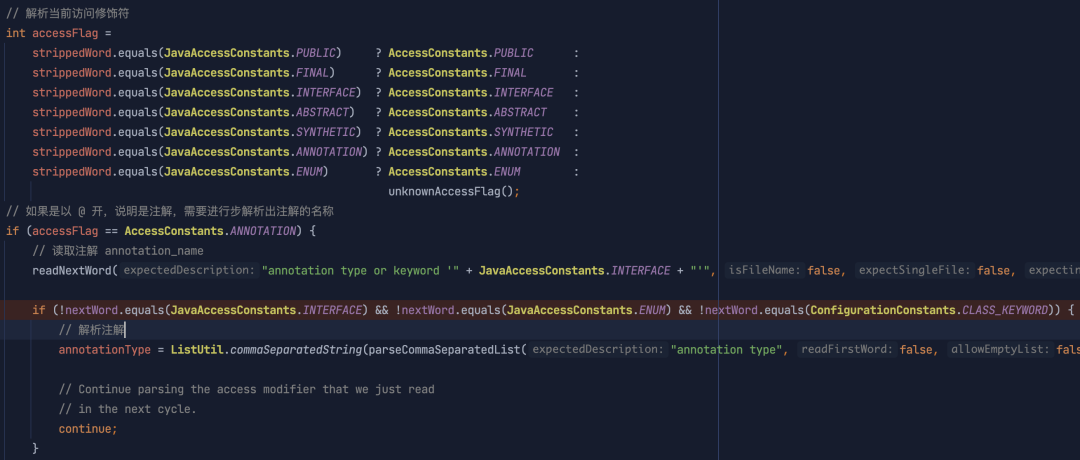
其中当解析到当前单词为 @ 时,会去解析 annotation_name 的列表, 并且重新用 , 拼接成一个字符串存储起来。 剩下的 access_flag 就简单多了,直接使用一个 int 型的值,按位将存起来就可以了,当然,我们还需要注意 ! ,因此,在存储的时候,会有两个变量:
if (!negated) {
requiredSetClassAccessFlags |= accessFlag;
} else {
requiredUnsetClassAccessFlags |= accessFlag;
}后面的 class_name 、extends 等逻辑读取就比较简单了,如下:
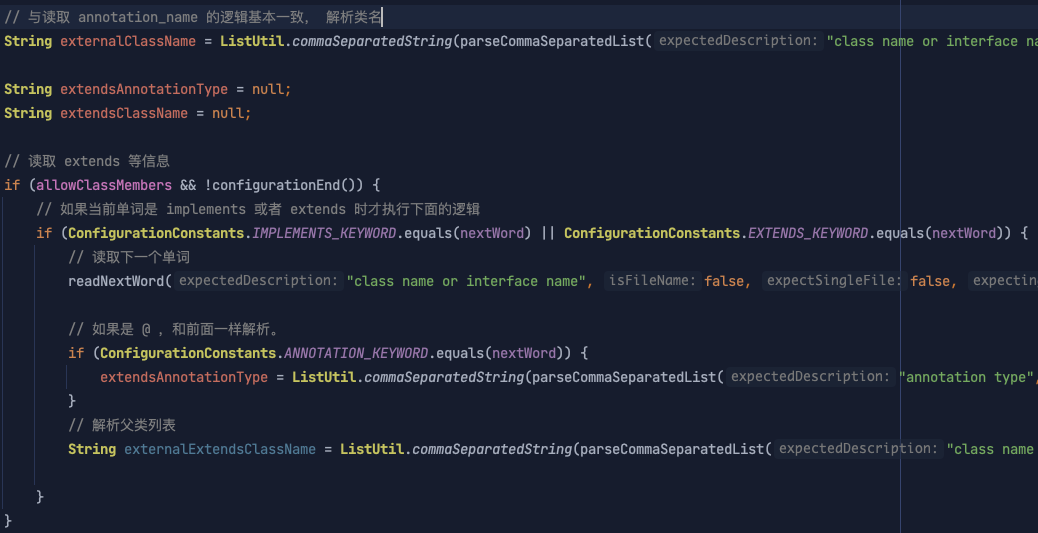
当父类相关信息解析完成后,下一步便是解析方法和变量相关的信息,也就是 EBNF 中描述 field_specification 和 method_specification 的内容。在 ProGuard 中,这两部份类容统一放到了 parseMemberSpecificationArguments 中去实现了,先来看一下代码逻辑:

剩下解析类成员的逻辑与前面类解析的逻辑相似,按照 EBNF 格式进行解析即可, 感兴趣的同学可以自行阅读源码。
结语
ProGuard 配置文件解析是非常重要的一部分内容,在 ProGuard 后续的执行逻辑中,会经常使用到本文中解析出来配置信息,可从官方文档详细了解一下各配置选项的作用级使用方法,以便能更好的理解后面的内容。在解析配置文件中,提到的 EBNF 是描述计算机编程语言的上下文无关文法的符号表示法,在编程语言开发中可能会经常遇到,此语法不复杂,可以去百科上读一读,相信你会有很多的收获。