大家看到这篇文章,肯定会有疑问,难道本篇文章和上一篇文章不是一个意思嘛,这是来凑数的嘛……其实不然,如果各位读者仔细看,就会发现本篇文章和上一篇文章大有不同,这篇文章也是我一直以来想在上一篇文章基础上补充的文章。如果没看过我上一篇文章的,可以跳转这里:
(4条消息) 麻雀算法SSA,优化VMD,适应度函数为最小包络熵,包含MATLAB源代码,直接复制粘贴!_今天吃饺子的博客-CSDN博客![]() https://blog.csdn.net/woaipythonmeme/article/details/128785256?spm=1001.2014.3001.5501先说一下本文干了什么!
https://blog.csdn.net/woaipythonmeme/article/details/128785256?spm=1001.2014.3001.5501先说一下本文干了什么!
正如标题所讲,白鲸优化算法优化VMD参数,最小包络熵为适应度函数,提取最小包络熵对应的IMF分量,采集最佳IMF分量的9种时域指标,提取特征向量。如果我说的不清楚,大家可以参考这篇文献。
[1]杨森,王恒迪,崔永存,李畅,唐元超.基于改进AFSA的参数优化VMD和ELM的轴承故障诊断[J].组合机床与自动化加工技术,2023(04):67-70.
这里也浅浅的截个图,给大家看看他的主要思路,红线部分即是本篇文章做的事情。

这里我先简单说一下本篇文章与我写的上一篇文章的不同之处。这一段大家不想看的可以忽略哈,直接往下看就行(点这里)
- 本篇文章采用的是白鲸优化算法优化VMD参数,之所以选这个方法是因为:①这个算法比上一篇文章所用的麻雀优化算法要更加易于理解,评论区看到很多小伙伴,在用麻雀算法时候碰到了很多bug,用这个方法也是尽量避免bug;②白鲸优化算法是2022年提出的,距离今天还算比较新,大家在学习VMD优化的时候也可以学学这个新算法。
- 先说上一篇文章的思路是:首先采用麻雀优化算法对VMD参数进行优化,得到最佳的K值和α值,而依据就是最小包络熵。好的大家到这里都一目了然,也容易理解,但是再往下该怎么利用这个K值和α值呢?
- 这里目前作者知道的方法有两种:①将K值和α值回带,求出每个IMF分量的近似熵,用这个近似熵值构建特征向量;②再求最小包络熵的时候,把最小包络熵的索引值idx(也就是你分解得到的K个IMF分量中,到底哪个分量的包络熵最小?)作为函数输出,然后将K值,α值和这个索引值idx都回带,计算该索引值对应的IMF分量的峭度值,峰值,均值,裕度因子等等指标,从而构建特征向量。
- 两种方法各有千秋,最后机器学习模型的诊断结果都是很好的。两个方法都能找到参考文献。第一个方法,缺陷是没有完全用到这个包络熵,只是以包络熵为最小目标函数去优化VMD参数了而已,然后对每个IMF分量求了近似熵,而不单单是对最小包络熵对应的IMF分量求了近似熵,当然这样也就没法构成特征向量了哈!第二个方法是只让最小的包络熵对应的IMF分量当做当前数据的主要特征,然后求一些峰值,裕度因子,均值,方差等指标构建特征向量。
不知道讲到这里大家会不会蒙了哈。如果蒙了也不要紧,咱们直接看结果,看代码就ok啦,等看完代码再回来看以上解释。
接下来依旧是先上结果:

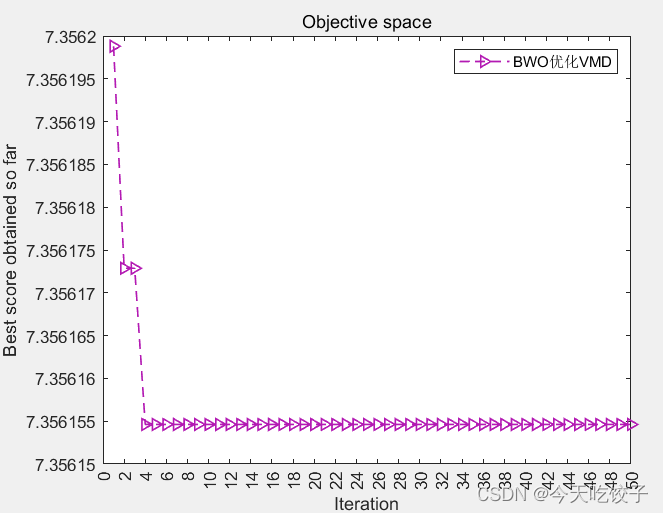
BWO-VMD迭代曲线图:

采用白鲸优化算法对VMD参数进行优化,设置参数如下:程序中种群个数是10个,迭代次数为50次,以上两幅图是以97.mat正常数据为例,最后得到了最佳的两个VMD参数值为:2500,10(这里多一句嘴哈,如果大家没有这个边界值的疑问,那下一段就直接忽略。
- 上一篇文章,大家很纠结这个值为啥在边界上呀,为啥和一些参考文献不一致啊,作者这里统一说一下,首先你要多试几次,然后要对不同的数据进行尝试,种群个数选成20也可以,增加搜索范围,如果说依旧是边界,那就把数据的采样点个数增加一下(下面会在程序中讲到数据点采样个数,我会标记出来))。总之,我现在不管是不是边界值,我最后的机器模型诊断效果不错,能够正确识别该故障,这个目的达到不就行了吗,各位读者,其他一些文献中提到的值,不一定就肯定是正确的(这里就不多说了哈,懂的都懂)。
- 下面也附上一张我换了数据的迭代图,此数据是105.mat大家可以看到,这个就不在边界上了哈!

-
接下来就是上代码啦,首先是数据处理代码,上文提到的修改采样点个数就是在这个代码中。
- 这个大家也可以看我另一篇文章,那篇文章有下载西储大学数据和数据处理脚本文件的方法。大家有数据的也可以直接复制该代码,与轴承数据放在同一文件夹下即可。(正所谓巧妇难为无米之炊,数据一定要先处理好哈!当然大家如果需要更多别的数据,我之后也会稍微整理一篇文章,当然也不收费的哦!经过几年的积累,作者这里还是多少有点数据的哈)。
(西储大学轴承数据处理--附MATLAB代码_今天吃饺子的博客-CSDN博客![]() https://blog.csdn.net/woaipythonmeme/article/details/131214489?spm=1001.2014.3001.5501
https://blog.csdn.net/woaipythonmeme/article/details/131214489?spm=1001.2014.3001.5501
clc;
clear;
addpath(genpath(pwd));
%DE是驱动端数据 FE是风扇端数据 BA是加速度数据 选择其中一个就行
load 97.mat %正常
load 105.mat %直径0.007英寸,转速为1797时的 内圈故障
load 118.mat %直径0.007,转速为1797时的 滚动体故障
load 130.mat %直径0.007,转速为1797时的 外圈故障
load 169.mat %直径0.014英寸,转速为1797时的 内圈故障
load 185.mat %直径0.014英寸,转速为1797时的 滚动体故障
load 197.mat %直径0.014英寸,转速为1797时的 外圈故障
load 209.mat %直径0.021英寸,转速为1797时的 内圈故障
load 222.mat %直径0.021英寸,转速为1797时的 滚动体故障
load 234.mat %直径0.021英寸,转速为1797时的 外圈故障
% 一共是10个状态,每个状态有120组样本,每个样本的数据量大小为:1×2048
w=1000; % w是滑动窗口的大小1000
s=2048; % 每个故障表示有2048个故障点
m = 120; %每种故障有120个样本
D0=[];
for i =1:m
D0 = [D0,X097_DE_time(1+w*(i-1):w*(i-1)+s)];
end
D0 = D0';
D1=[];
for i =1:m
D1 = [D1,X105_DE_time(1+w*(i-1):w*(i-1)+s)];
end
D1 = D1';
D2=[];
for i =1:m
D2 = [D2,X118_DE_time(1+w*(i-1):w*(i-1)+s)];
end
D2 = D2';
D3=[];
for i =1:m
D3 = [D3,X130_DE_time(1+w*(i-1):w*(i-1)+s)];
end
D3 = D3';
D4=[];
for i =1:m
D4 = [D4,X169_DE_time(1+w*(i-1):w*(i-1)+s)];
end
D4 = D4';
D5=[];
for i =1:m
D5 = [D5,X185_DE_time(1+w*(i-1):w*(i-1)+s)];
end
D5 = D5';
D6=[];
for i =1:m
D6 = [D6,X197_DE_time(1+w*(i-1):w*(i-1)+s)];
end
D6 = D6';
D7=[];
for i =1:m
D7 = [D7,X209_DE_time(1+w*(i-1):w*(i-1)+s)];
end
D7 = D7';
D8=[];
for i =1:m
D8 = [D8,X222_DE_time(1+w*(i-1):w*(i-1)+s)];
end
D8 = D8';
D9=[];
for i =1:m
D9 = [D9,X234_DE_time(1+w*(i-1):w*(i-1)+s)];
end
D9 = D9';
data = [D0;D1;D2;D3;D4;D5;D6;D7;D8;D9];
ceshi_data = data;
save data data
folder='测试数据汇总/'; %%定义变量
if exist(folder)==0 %%判断文件夹是否存在
mkdir(folder); %%不存在时候,创建文件夹
end
xlswrite('/测试数据汇总/转速1797_测试数据汇总.xlsx',ceshi_data);
dd = [];
for i = 0:size(data,1)/m-1
dd(1+m*i:m+m*i) = i+1;
end
zj = [dd;data'];
ceshi_data = zj';
xlswrite('/测试数据汇总/转速1797_测试数据汇总带标签.xlsx',ceshi_data);
rmpath(genpath(pwd))接下来是BWO-VMD优化和特征提取的主程序,大家运行的时候就运行这个文件即可!注意:这个代码中的注释大家一定要仔细观看!尤其是最后几行!
- 这个主文件只是对一种故障类型的VMD参数寻优和特征提取,想要提取其他类型故障的特征,需要手动改代码,改代码的方式我也已经写到备注里边了。之所以没写一个整体的大循环,是因为考虑到:①程序会执行相当慢,且大家需要记录每种故障对应的K值和α值,如果写个大循环,那大家就看不清楚每次执行的最佳K值与α值了②:第二点也非常重要啊!那就是作者有点懒了,这篇文章的每个字,都是我一个个敲出来,艾玛也,敲了俩小时了……整理真不容易,底部小卡片点个关注昂!别无他求了……
%% 以最小包络熵为目标函数,采用BWO算法优化VMD,求取VMD最佳的两个参数
clear all
clc
addpath(genpath(pwd))
load data
%设置PSOCHOA算法的参数
D=2; % 优化变量数目
lb=[100 3]; % 下限值,分别是a,k
ub=[2500 10]; % 上限值
T=50; % 最大迭代数目
N=10; % 种群规模
y=@Cost;
da = data(190,:); %特别要注意,这里选择的时候要一类一类的选,比方说我要提取第种一类别的特征向量,那这里就从1-120行之间随便选一行,(为什么是120呢,是指我在数据处理阶段,每一类故障收集了120个样本的意思)
%然后计算最佳的两个VMD参数,计算完了之后,将最佳的k值和α值带入特征提取函数中,对这一类的数据进行近似熵的特征提取
%如果我提取第二类故障,那就在121-240之间随机选一行。
[bwoBest_pos,bwoBest_score,Bestidx,BWO_curve] = BWO(y,lb,ub,D,N,T,da);
%画适应度函数图
figure
plot(1:T,BWO_curve,'Color',[0.7 0.1 0.7],'Marker','>','LineStyle','--','linewidth',1);
% plot(1:T,BWO_curve,'Color','r')
title('Objective space')
xlabel('Iteration');
set(gca,'xtick',0:2:T);
ylabel('Best score obtained so far');
legend('BWO优化VMD')
display(['The best solution obtained by PSOCHOA is : ', num2str(round(bwoBest_pos))]); %输出最佳位置
display(['The best optimal value of the objective funciton found by BWO is : ', num2str(bwoBest_score)]); %输出最佳适应度值
%% 以下为将最佳的a,k,idx带入VMD中,并进行近似熵特征提取
bbh = round(bwoBest_pos);%最佳位置取整
new_data1 = tezhengtiqu(bbh(1),bbh(2),Bestidx,data(1:120,:)); %将优化得到的两个参数和最小包络熵的索引值带回VMD中
save new_data1.mat new_data1 %将提取的特征向量保存为mat文件,方便概率神经网络的处理
%% 删除路径,以免被其他函数混淆
rmpath(genpath(pwd))
%当想要寻优第其他故障类型的时候,就需要大家将da=data(111,:),改成da=data(125,:),(随机的从121-240之间挑一个数,因为这个区间是同一类的故障,我们默认优化同一类故障数据得到的最佳IMF分量索引是一致的!)
%其次还需要改new_data = tezhengtiqu(bbh(1),bbh(2),idx,data(1:120,:));将data(1:120,:),改成data(121:240,:)
%save new_data2.mat new_data2 这里也改成data2
%就这样,大家一种类型一种类型的提取,一遍一遍记录每次得到的最佳K和α的值,一遍一遍的把特征变量存储起来就ok啦
由最后四行注释可以看出,如果你选了10种类型的故障进行诊断,那么!你就要执行10次这个主程序,而且每次都要改几个地方。最后你就可以总结出来一个类似这样的表格咯:
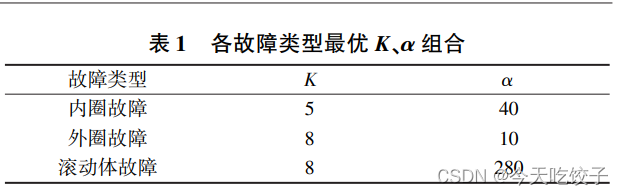
这可不是本文得到的表格啊,作者在这里只是告诉大家会得到这样一个最佳组合的表格,你写在论文里也更有说服力,是不是!
特征提取完了之后,以本篇文章为例,在数据处理阶段,一共选了10种故障类型,每种类型是120个故障样本。每个故障样本将来会被均值,方差,峰值,峭度,有效值,峰值因子,脉冲因子,波形因子,裕度因子九个指标代替。所以最终得到一个1200*9的数据,这就是得到的特征提取完的数据啦!然后大家可以拿着这个数据,送入各机器学习模型进行训练预测啦!
由于上一篇文章大家的运行会出现各种各样的问题,所以本次考虑给大家直接整理完整不收费的整个压缩包!
下方卡片回复关键词:VMD优化
欢迎大家评论区留言哦!