骨干网络
骨干网络(backbone network)顾名思义,是深度学习中最核心的网络组成。本文按时间顺序,简要介绍几种影响重大的backbone设计思路,我们或许可以从窥探前人的设计思路中获得启发和灵感。
1.1 AlexNet, 2012
这是2012年提出的世界上第一种深度神经网络,它率先打破了CV领域特征工程的垄断地位,以巨大优势赢得了当年ImagNet比赛。
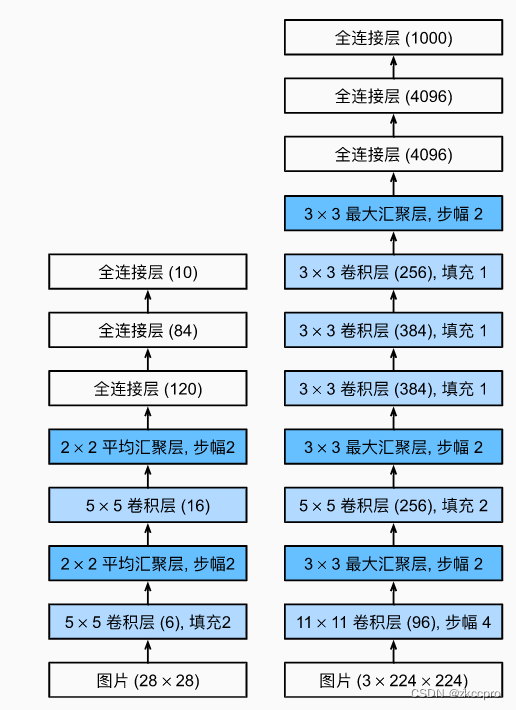
图1 LeNet(左)与AlexNet(右)网络结构
乍一看,和LeNet比好像也没啥特别的,,就是层数多了。但还有一些著名的细节技术方案在AlexNet第一次被提出或使用:
- 第一次采用ReLU替代sigmod作为激活函数,可以降低运算量、避免梯度消失。
- 在最后的全连接层使用Dropout以控制模型复杂度。
- 训练时采用大量的数据增强(翻转、裁剪、变色)以提高模型鲁棒性,减少过拟合。
最后,附上AlexNet的pytorch实现:
import torch
from torch import nn
net = nn.Sequential(
# 这里,我们使用一个11*11的更大窗口来捕捉对象。
# 同时,步幅为4,以减少输出的高度和宽度。
# 另外,输出通道的数目远大于LeNet
nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 使用三个连续的卷积层和较小的卷积窗口。
# 除了最后的卷积层,输出通道的数量进一步增加。
# 在前两个卷积层之后,汇聚层不用于减少输入的高度和宽度
nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Flatten(),
# 这里,全连接层的输出数量是LeNet中的好几倍。使用dropout层来减轻过拟合
nn.Linear(6400, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
# 最后是输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000
nn.Linear(4096, 10))
1.2 VGG, 2014
VGG是2014年由牛津大学提出的,它最大的改进和贡献在于以【块】为基本单位进行骨干网设计。这确实很大程度上影响了后来网络设计的思路。
VGG的提出者发现:深度卷积神经网络的基本组成无非是:
- 卷积层
- 激活函数
- 池化层
那好,我把这仨东西作为一个块,用这个块来堆积成网络:
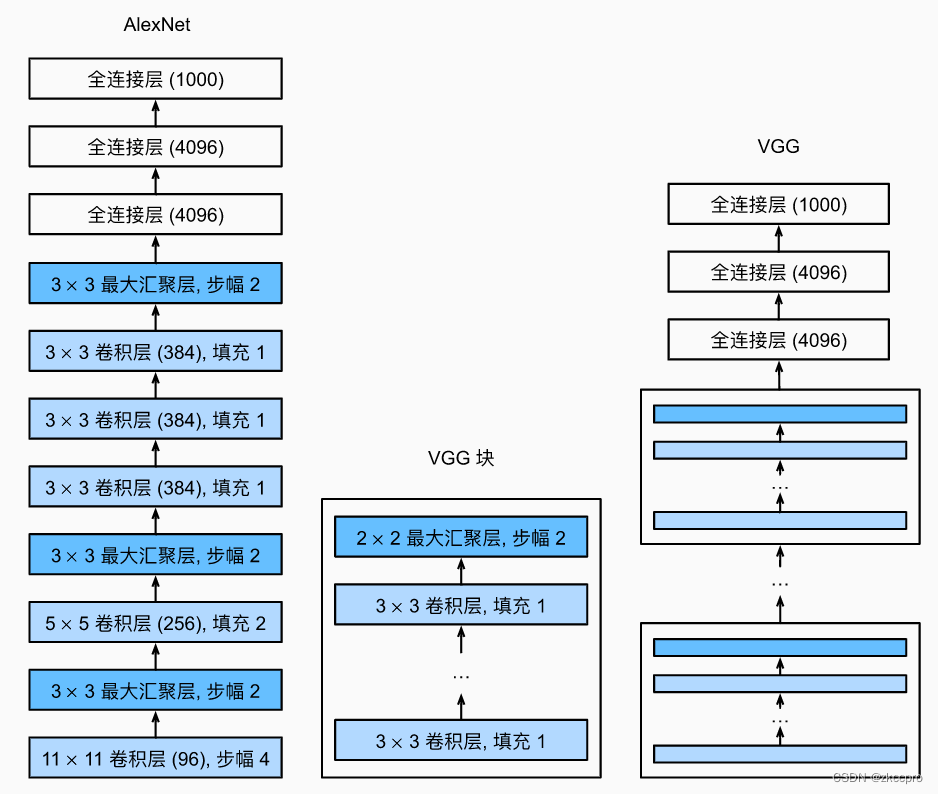
图2 AlexNet与VGG
数一数上图(右)有几层(卷积层+全连接层)?有n层我们就管这个网络叫VGG-n(比如VGG-11、VGG-19…)
1.3 GoogLeNet, 2014
VGG网络只是提出了一种规范化的深度学习网络设计思路,但确实没啥新东西出现。同样是2014年的GoogLeNet在ImageNet比赛中大获全胜,也提出了一种更有效的 Inception block:
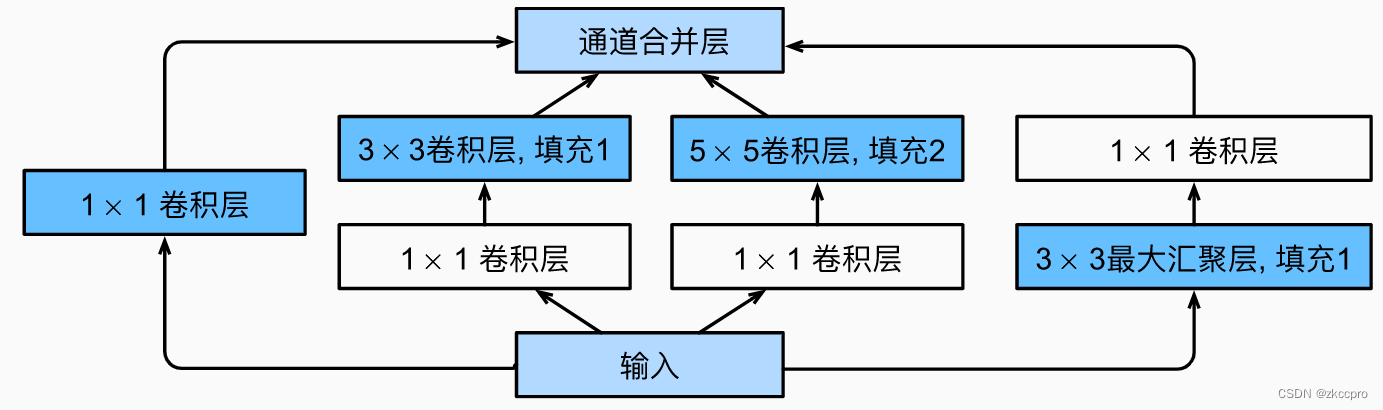
图3 Inception block
说白了这东西就是由很多不同尺寸的卷积核并联起来…以让网络自己决定到底该使用哪一种尺寸的卷积核更多一些…看起来很简单的设计,但更有效就是硬道理。
进一步地,GoogLeNet用了Inception块作为骨干网的基础组成,GoogLeNet的整体结构如下:
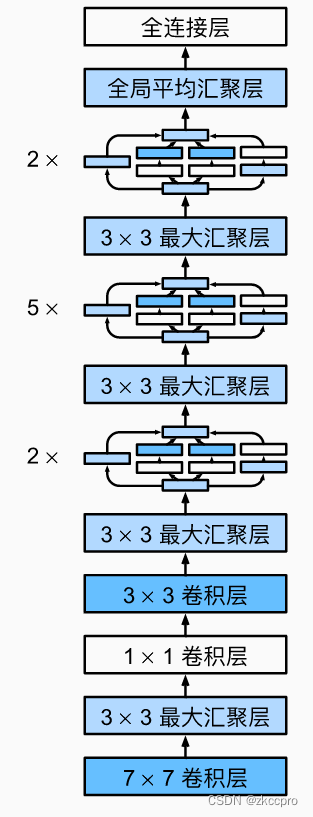
图4 GoogLeNet结构
最后,附上Inception块的pytorch实现:
import torch
from torch import nn
from torch.nn import functional as F
class Inception(nn.Module):
# c1--c4是每条路径的输出通道数
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
super(Inception, self).__init__(**kwargs)
# 线路1,单1x1卷积层
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
# 线路2,1x1卷积层后接3x3卷积层
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 线路3,1x1卷积层后接5x5卷积层
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4,3x3最大汇聚层后接1x1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
# 在通道维度上连结输出
return torch.cat((p1, p2, p3, p4), dim=1)
1.4 ResNet, 2016
ResNet可以说是里程碑式的骨干网络结构,它在2016年由何凯明、孙剑等人提出。(十分遗憾的是孙剑在2022年去世)
ResNet的提出基于这样一个【观察】:AlexNet之后,深度学习领域形成了一个信念:网络层数越深,效果越好。但[resnet]中却发现并不是这样,当网络层深达到一定程度之后,学习效果反而开始下降了,这怎么可能呢?
[resnet]中给出了自己的【分析】:你说,当n层网络能学习到一个东西的时候,那n+1层网络能不能学到这个东西?直观来说一定可以啊,因为如果n层都能办到,那只需n+1层做一个【恒等映射】不就行了吗???怎么会造成学习效果下降呢????所以上面的观察现象很奇怪,神经网络不是可以拟合任何复杂的线性、非线性函数吗?怎么连最简单的恒等映射都实现不了呢?????
紧接着,[resnet]给出了自己的【猜想】:神经网络发展到现在,或许是能拟合世界上最复杂的非线性函数,但也正因为此,它连最简单的恒等映射就是实现不了…那既然如此,我让它能实现恒等映射不就完了吗?
于是,[resnet]提出了一种【解决方案】:用残差块 提供给 层 恒等映射的能力。
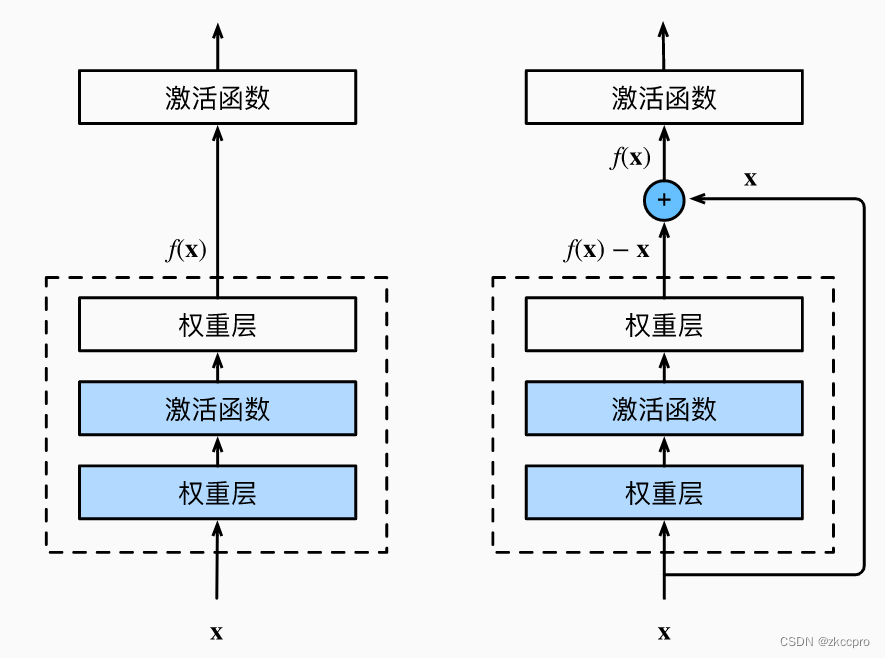
图5 正常块(左)与残差块(右)
同样,结构简洁明了,效果拔群,残差神经网络在今天(2022年)仍然是最受欢迎的骨干网方案之一。不近如此,它的设计思路也启发了后续的很多设计,还是非常伟大的。
而且其中的论文思路:【观察】、【分析】、【猜想】、【解决方案】也非常值得我们学习。
ResNet结构和其他骨干网类似,堆积残差块即可:
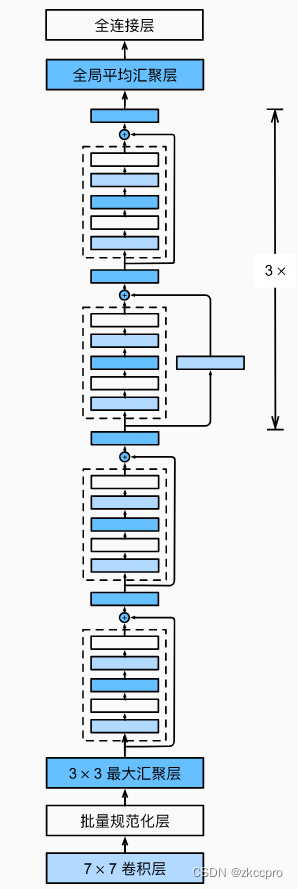
图6 ResNet结构
不仅如此,在[resnet]的工作中,还有一些细节改进:
- 提出并使用warmup训练策略。
- 在残差块中,每个卷积层后都使用了BatchNorm。(但BN不是[resnet]提出的)
- 还提出了一种瓶颈模块(Bottleneck Block)以降低参数量
下面附上残差块和瓶颈块具体实现,实现时还是有一些细节需要注意的:
# 网络模块接口
class BlockInterface(nn.Module):
# 参数:输入通道数,输出通道数,是否开启BN,是否开启Dropout
def __init__(self, input_channels, output_channels,
BN=True, Dropout=False):
super().__init__()
self.input_channels = input_channels
self.output_channels = output_channels
self.BN = BN
self.Dropout = Dropout
def forward(self, x):
pass
# 残差模块
# 参数量:input*output*3*3+output*output*3*3+input*output
class ResidualBlock(BlockInterface):
def __init__(self, input_channels, output_channels,
BN=True, Dropout=False):
super().__init__(input_channels, output_channels,
BN=BN, Dropout=Dropout)
self.conv1 = nn.Sequential(
nn.Conv2d(input_channels, output_channels, kernel_size=3, padding=1).to(globalParam.device),
nn.BatchNorm2d(output_channels).to(globalParam.device),
nn.ReLU()
) if self.BN == True else nn.Sequential(
nn.Conv2d(input_channels, output_channels, kernel_size=3, padding=1).to(globalParam.device),
nn.ReLU()
)
self.conv2 = nn.Sequential(
nn.Conv2d(output_channels, output_channels, kernel_size=3, padding=1).to(globalParam.device),
nn.BatchNorm2d(output_channels).to(globalParam.device)
) if self.BN == True else nn.Sequential(
nn.Conv2d(input_channels, output_channels, kernel_size=3, padding=1).to(globalParam.device),
nn.ReLU()
)
# 旁路卷积,卷积核为1,控制通道改变,只对输入各像素产生整体线性变化
self.conv_side = nn.Conv2d(input_channels, output_channels, kernel_size=1).to(globalParam.device)
def forward(self, x):
y = self.conv1(x)
y = self.conv2(y)
if self.input_channels != self.output_channels:
x = self.conv_side(x)
return F.relu(x + y)
# 瓶颈模块
# 参数量:input*low+low*low*3*3+low*output+(input*output)
# 输出通道不为1,为1时考虑用residual block
class BottleneckBlock(BlockInterface):
def __init__(self, input_channels, output_channels,
BN=True, Dropout=False):
super().__init__(input_channels, output_channels,
BN=BN, Dropout=Dropout)
low_channels = output_channels // 4 # 默认low_channels是output_channels的四分之一
self.conv1 = nn.Sequential(
nn.Conv2d(input_channels, low_channels, kernel_size=1).to(globalParam.device),
nn.BatchNorm2d(low_channels).to(globalParam.device),
nn.ReLU()
) if self.BN == True else nn.Sequential(
nn.Conv2d(input_channels, low_channels, kernel_size=1).to(globalParam.device),
nn.ReLU()
)
self.conv2 = nn.Sequential(
nn.Conv2d(low_channels, low_channels, kernel_size=3, padding=1).to(globalParam.device),
nn.BatchNorm2d(low_channels).to(globalParam.device),
nn.ReLU()
) if self.BN == True else nn.Sequential(
nn.Conv2d(low_channels, low_channels, kernel_size=3, padding=1).to(globalParam.device),
nn.ReLU()
)
self.conv3 = nn.Sequential(
nn.Conv2d(low_channels, output_channels, kernel_size=1).to(globalParam.device),
nn.BatchNorm2d(output_channels).to(globalParam.device),
) if self.BN == True else nn.Sequential(
nn.Conv2d(low_channels, output_channels, kernel_size=1).to(globalParam.device),
)
# 旁路卷积,卷积核为1,控制通道改变,只对输入各像素产生整体线性变化
self.conv_side = nn.Conv2d(input_channels, output_channels, kernel_size=1).to(globalParam.device)
def forward(self, x):
y = self.conv1(x)
y = self.conv2(y)
y = self.conv3(y)
if self.input_channels != self.output_channels:
x = self.conv_side(x)
return F.relu(x + y)
1.5 DenseNet, 2017
DenseNet(稠密连接网络)就是一种受到ResNet启发而设计的网络结构。其主题思想和ResNet一致的,但有两点区别:
- 跨层连接使用cat(通道叠加)而不是简单地相加
- 稠密连接,套娃连接…
- 由于使用cat增大了通道数,所以还得使用过渡层适当减小通道数。
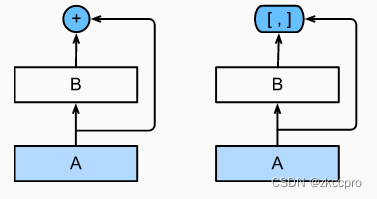
图7 稠密块的通道叠加
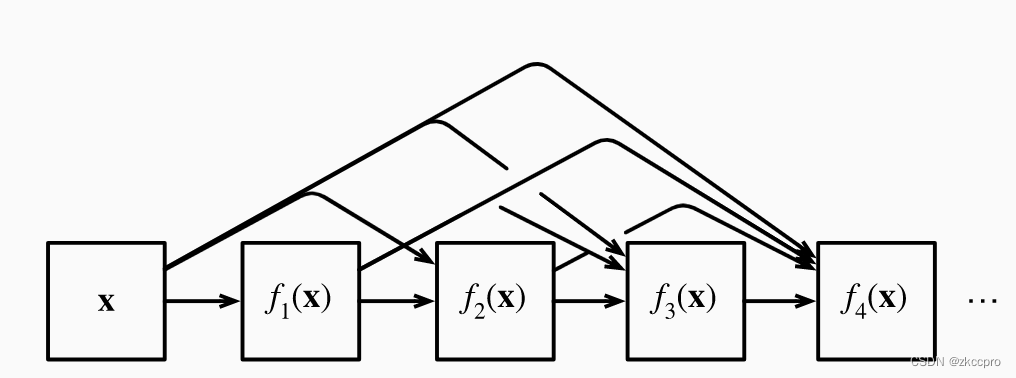
图8 稠密连接示意
附上稠密块、过渡块以及DesNet整体模型的pytorch实现:
import torch
from torch import nn
def conv_block(input_channels, num_channels):
return nn.Sequential(
nn.BatchNorm2d(input_channels), nn.ReLU(),
nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1))
# 稠密块
class DenseBlock(nn.Module):
def __init__(self, num_convs, input_channels, num_channels):
super(DenseBlock, self).__init__()
layer = []
for i in range(num_convs):
layer.append(conv_block(
num_channels * i + input_channels, num_channels))
self.net = nn.Sequential(*layer)
def forward(self, X):
for blk in self.net:
Y = blk(X)
# 连接通道维度上每个块的输入和输出
X = torch.cat((X, Y), dim=1)
return X
# 过渡层
def transition_block(input_channels, num_channels):
return nn.Sequential(
nn.BatchNorm2d(input_channels), nn.ReLU(),
nn.Conv2d(input_channels, num_channels, kernel_size=1),
nn.AvgPool2d(kernel_size=2, stride=2))
# DenseNet整体实现
# num_channels为当前的通道数
num_channels, growth_rate = 64, 32
num_convs_in_dense_blocks = [4, 4, 4, 4]
blks = []
for i, num_convs in enumerate(num_convs_in_dense_blocks):
blks.append(DenseBlock(num_convs, num_channels, growth_rate))
# 上一个稠密块的输出通道数
num_channels += num_convs * growth_rate
# 在稠密块之间添加一个转换层,使通道数量减半
if i != len(num_convs_in_dense_blocks) - 1:
blks.append(transition_block(num_channels, num_channels // 2))
num_channels = num_channels // 2
densenet = nn.Sequential(
b1, *blks,
nn.BatchNorm2d(num_channels), nn.ReLU(),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(num_channels, 10))