本章将完成最常见、最有用的STL容器vector的设计与实现。我们将展示如何实现元素数量可变的容器,如何以参数形式指定容器的元素类型,以及如何处理越界错误。本章使用的技术依赖模板和异常,因此我们将介绍如何定义模板,并给出资源管理的基本技术,这些技术是正确使用异常的关键。
19.1 问题
在第18章结束时,我们的vector已经支持创建指定数量元素的vector、拷贝赋值和初始化、正确地释放内存,以及使用传统的下标语法访问元素(但是到目前为止仍然等价于固定大小的double数组)。
但是要达到我们期望的水平(基于使用标准库vector的经验),我们还需要解决三个问题:
- 如何改变
vector的大小(改变元素数量)? - 如何捕获和报告越界元素访问?
- 如何以参数形式指定元素类型?
即如何定义vector使得下面的操作是合法的:
vector<double> vd; // elements of type double
for (double d; cin>>d; )
vd.push_back(d); // grow vd to hold all the elements
vector<char> vc(100); // elements of type char
int n;
cin>>n;
vc.resize(n); // make vc have n elements
19.2 改变大小
标准库vector提供了三种改变大小的操作。对于
vector<double> v(n); // v.size()==n
有三种方式可以改变其大小:
v.resize(10); // v now has 10 elements
v.push_back(7); // add an element with the value 7 to the end of v, v.size() increases by 1
v = v2; // assign another vector; v is now a copy of v2, v.size() now equals v2.size()
标准库vector提供了更多改变大小的操作,例如erase()和insert(),但本章只考虑这三种。
19.2.1 表示
在实际中,我们通常会多次改变vector的大小。例如,我们很少见到只做一次push_back()。因此,vector会同时记录元素数量以及为“后续扩展”预留的“空闲空间”的数量:
class vector {
int sz; // number of elements
double* elem; // address of first element
int space; // number of elements plus "free space"/"slots" for new elements ("the current allocation")
public:
// ...
};
如下图所示:
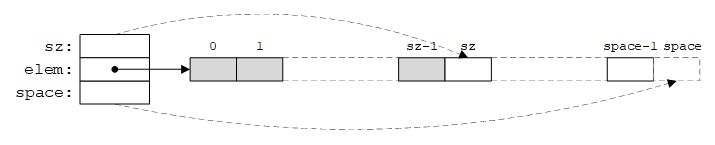
其中,[0, space)是elem的范围,[0, sz)是已有元素,[sz, space)是空闲位置。
默认构造函数(创建空向量)将整数成员置为0,指针成员置为nullptr:
vector() :sz(0), elem(nullptr), space(0) {}
19.2.2 reserve和capacity
改变大小的最基本操作是reserve(),该操作用于增加向量的容量(不改变元素个数)。
简单向量v3 - 改变大小
注意,我们并不初始化空闲空间中的元素,因为这是push_back()和resize()的工作。
和标准库一样,我们提供了成员函数capacity()来获取向量的容量space。也就是说,对于一个向量v,v.capacity() - v.size()(即space - sz)是在不重新分配空间的前提下可以通过push_back()添加的元素个数。
19.2.3 resize
有了reserve(),实现resize()是十分简单的。我们需要处理几种情况:
- new_size > capacity()
- size() < new_size ≤ capacity()
- new_size = size()
- new_size < size()
简单向量v3 - 改变大小
我们让reserve()来完成处理内存的复杂工作,循环将初始化新元素(如果有)。
虽然resize()没有显式地处理每一种情况,但可以验证所有情况均被正确地处理了:
旧的size() | 旧的capacity() | new_size | 新的size() | 新的capacity() |
|---|---|---|---|---|
| 10 | 16 | 20 | 20 | 20 |
| 10 | 16 | 15 | 15 | 16 |
| 10 | 16 | 10 | 10 | 16 |
| 10 | 16 | 5 | 5 | 16 |
注:如果new_size < 0,则resize()会使size() < 0。标准库vector::resize()的参数是无符号整数类型size_t,因此不存在这一问题。
19.2.4 push_back
有了reserve()之后,push_back()是非常简单的:
简单向量v3 - 改变大小
当没有空闲空间时,将分配的空间增加一倍。在实际中,这种策略被证明是一种非常好的选择,并且被标准库vector的大多数实现所采用。
注:这种策略使得向量的容量始终是2的幂。不发生扩容时push_back()的时间复杂度是O(1),发生扩容时是O(n) = O(2k),平摊到接下来2k-1次push_back()操作,使得每次操作的平均时间复杂度仍然是O(1)。
19.2.5 赋值
在向量赋值时,我们需要拷贝元素,但不需要考虑末尾的空闲空间。例如:
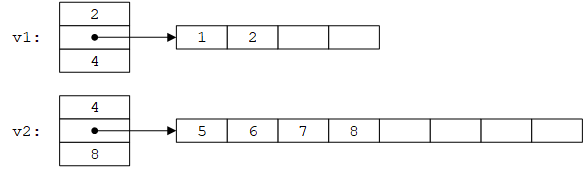
赋值v1=v2之后:
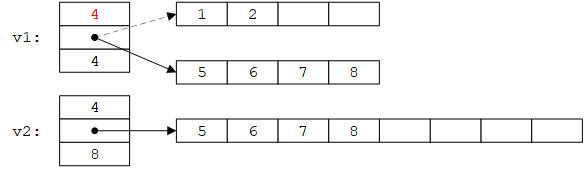
最简单的实现只需在原有拷贝赋值的基础上增加space = sz;即可。然而,如果v1的容量足以容纳v2的所有元素,就没有必要重新分配存储空间,只需要拷贝元素:
简单向量v3 - 改变大小
这里我们首先判断了自身赋值(例如v=v),这种情况下什么都不做。注意,判断this==&v和v.sz<=space只是为了优化,即使删除,代码仍然能够正确工作。
注意:拷贝构造函数需要相应修改,elem数组的大小必须和space保持一致,否则push_back()可能导致越界访问。
19.2.6 到目前为止我们的vector类
现在已经有了一个接近真实的double向量:
简单向量v3 - 改变大小
19.3 模板
我们不仅仅需要double向量,而是希望能够自由指定元素类型。例如:
vector<double>
vector<int>
vector<Month>
vector<Window*> // vector of pointers to Windows
vector<vector<Record>> // vector of vectors of Records
vector<char>
为此,我们必须知道如何定义模板。我们在4.6节就使用过模板,但到现在还没有定义过模板。
模板(template)是一种允许程序员使用类型或值参数化类或函数的机制,这些参数叫做模板参数(template parameter),具有模板参数的类叫做类模板(class template),具有模板参数的函数叫做函数模板(function template)。当我们提供具体类型或值作为参数时,编译器将生成一个特定的类或函数。
19.3.1 类型作为模板参数
我们希望将元素类型作为vector的参数,因此我们在vector类中将double替换为T,其中T是一个(类型)参数,可以被赋予double、int、string、vector<Record>和Window*之类的“值”。
在C++中,引入类型参数的语法是template<class T>或template<typename T>,其含义是“对于所有的类型T”。例如:
简单向量v3 - 改为模板
这里只是将19.2.6节的vector中的double替换为模板参数T(但对于实现类模板是不够的,见19.3.7节)。我们可以这样使用类模板vector:
vector<double> vd; // T is double
vector<int> vi; // T is int
vector<double*> vpd; // T is double*
vector<vector<int>> vvi; // T is vector<int>, in which T is int
注:
- 类模板的成员函数也被认为是模板,因此在类外定义时,必须使用
template声明模板参数,并与类的模板参数一致。 - 在类模板内声明/定义成员函数时,参数类型或返回类型出现自身类型时可以省略模板参数;如果在类外定义,参数类型可以省略模板参数,而返回类型和
::前不可省略。例如:
template<class T>
class A {
public:
A<T>& operator=(const A<T>& a);
};
template<class T>
A<T>& A<T>::operator=(const A<T>& a) {
return *this;
}
可简化为:
template<class T>
class A {
public:
A& operator=(const A& a);
};
template<class T>
A<T>& A<T>::operator=(const A& a) {
return *this;
}
当我们使用模板时,可以认为编译器用模板实参(template argument)(实际类型或值)替换模板参数生成了一个类或函数。对于vector<double>,编译器将会(大致)生成19.2.6节中的vector。
我们有时称类模板为类型生成器(type generator)。给定模板实参从类模板生成类或函数的过程叫做特化(specialization)或模板实例化(template instantiation)。例如,vector<double>叫做vector的一个特化。模板实例化发生在编译时或链接时,而不是运行时。
自然地,我们可以使用类模板的成员函数。例如:
void fct(vector<string>& v) {
int n = v.size();
v.push_back("Norah");
// ...
}
编译器会根据模板定义
template<class T> void vector<T>::push_back(const T& x) { /* ... */ };
生成函数
void vector<string>::push_back(const string& x) { /* ... */ }
19.3.2 泛型编程
在C++中,模板是泛型编程的基础。
泛型编程(generic programming):编写能够处理各种类型(作为参数)的代码,只要这些类型满足特定的语法和语义要求。
例如,vector的元素类型必须是可拷贝的(因为push_back()中的elem[sz] = x;是拷贝操作)。在第20和21章,我们将会看到要求参数支持算术运算的模板。
注:如果类C不可拷贝,则仍然可以定义vector<C> v,但v.push_back(c)编译失败;如果类C没有默认构造函数,则可以定义vector<C> v,但vector<C> v(5)编译失败。这些编译错误发生在模板实例化时,而不是编译模板本身的代码时,因为模板并不知道用户会提供什么样的实际类型。
依赖于显式模板参数的这种泛型编程通常叫做参数化多态(parametric polymorphism)。相比之下,从类层次结构和虚函数中获得的多态叫做专用多态(ad hoc polymorphism),而这种编程风格叫做面向对象编程。这两种编程风格都叫做“多态”的原因在于二者都依赖程序员通过一个单一的接口提供一个概念的多个版本。多态在希腊语中是“多种形状”(many shapes)的意思,是指你可以通过一个公共的接口操作很多不同的类型。在第16~19章Shape的例子中,我们可以通过Shape定义的接口访问多种形状(例如Text、Circle、Polygon等)。当我们使用vector时,我们通过vector模板定义的接口使用不同类型的vector(例如vector<int>、vector<double>和vector<Shape*>)。
面向对象编程和泛型编程最明显的差异是:使用泛型编程时,被调用函数的选择是在编译时决定的,而对于面向对象编程是在运行时决定的。例如:
void f(vector<string>& v, Shape& s) {
v.push_back(x); // put x into the vector v
s.draw(); // draw the shape s
}
对于v.push_back(x),编译器将根据v的元素类型调用对应的push_back();而对于s.draw(),编译器会间接地调用某个draw()函数(使用s的vtbl)。
总结:
- 泛型编程:由模板支持,依赖编译时解析。
- 面向对象编程:由类层次结构和虚函数支持,依赖运行时解析。
将二者结合是可能的也是有用的。例如:
void draw_all(vector<Shape*>& v) {
for (int i = 0; i < v.size(); ++i) v[i]–>draw();
}
这里,调用虚函数draw()是面向对象编程,而使用模板vector是泛型编程。
模板具有极大的灵活性、近似最优的性能等优点。然而,模板的主要问题在于声明和定义不能很好地分离。当编译使用模板的代码时,编译器通常要求模板在被使用的位置完全定义,包括所有成员函数及其调用的模板函数。因此,必须将模板的定义放在头文件中(无论成员函数在类内还是类外定义)。
注:下面是来自cppreference的解释:
The definition of a template must be visible at the point of implicit instantiation, which is why template libraries typically provide all template definitions in the headers.
19.3.3 概念
在编写模板时,有时需要对模板参数进行约束。例如:
template<class T> // requires T to be addable
T add(T a, T b) { return a + b; }
其中,函数模板add要求模板参数T必须支持+运算,但只是通过注释以文字的方式说明。如果使用模板add时给定的模板参数不支持+运算,将导致编译错误:
int i = add(1, 2); // OK, returns 3
double d = add(1.2, 3.4); // OK, returns 4.6
string s = add(string("abc"), string("def")); // OK, returns "abcdef"
const char* c = add("abc", "def"); // error: no operator+ for const char* and const char*
vector<int> v = add(vector<int>(), vector<int>()); // error: no operator+ for vector<int> and vector<int>
C++标准定义了一些常用的具名要求(named requirement),例如“可默认构造”(DefaultConstructible)、“可调用”(Callable)等,完整列表见Named Requirements - cppreference。但是具名要求仍然局限于自然语言描述。
C++20引入了一个新的语言特性——概念。概念(concept)是对模板参数的一组命名的约束/要求,是一种在编译时求值的类型断言,以编译器可理解的方式提供了一种模板参数检查机制。当模板参数不满足要求时,编译器将给出更加明确的错误信息。
例如,对于上面例子中“支持+运算”这一约束,可以定义概念Addable:
template<class T>
concept Addable = requires(T x) { x + x; };
其中,=后面的部分叫做requires表达式,{}中的一个或多个语句用于断言这些表达式是合法的,即能够编译通过(并不真正执行)。如果模板参数满足所有的要求,则requires表达式结果为true。
在定义模板时,可以像这样使用概念Addable:
template<class T> requires Addable<T>
T add(T a, T b) { return a + b; }
template<Addable T>
T add(T a, T b) { return a + b; }
这两种方式是等价的,意味着“要求模板参数T必须满足概念Addable”。其中,第一种方式中的requires Addable<T>叫做requires子句。
标准库头文件<concepts>定义了一组常用的概念。
注:C++11新增的标准库头文件<type_traits>也定义了一组用于断言模板参数是否满足特定要求的模板,与概念类似,但无法用在模板定义中。
19.3.4 容器和继承
将派生类对象的容器赋给基类对象的容器是错误的。例如:
vector<Shape> vs;
vector<Circle> vc;
vs = vc; // error: vector<Shape> required
void f(vector<Shape>&);
f(vc); // error: vector<Shape> required
因为将一个Circle对象push_back()到vector<Shape>中会发生截断(见14.2.4节)。
注:
Shape类禁止拷贝,因此将一个Shape对象push_back()到vector<Shape>中也是错误的。另外,Shape是抽象类,根本不能创建Shape对象,因此不能使用vector<Shape>的构造函数和resize()等操作。总之,对于vector<Shape>,除了声明一个空向量以外什么都不能做,因此使用这个类型是没有意义的。- 即使不存在抽象类和禁止拷贝问题,将
vector<Circle>赋给vector<Shape>仍然是非法的,因为拷贝赋值在拷贝元素时也会发生截断;将vector<Circle>赋给vector<Shape>&也是非法的,因为Circle对象比Shape对象大,在push_back()时会发生截断,元素位置是完全错位的:

使用指针再次尝试:
vector<Shape*> vps;
vector<Circle*> vpc;
vps = vpc; // error: vector<Shape*> required
void f(vector<Shape*>&);
f(vpc); // error: vector<Shape*> required
将vector<Circle*>赋给vector<Shape*>仍然是非法的。考虑f()可能会做什么:
void f(vector<Shape*>& v) {
v.push_back(new Rectangle(Point(0,0),Point(100,100)));
}
显然,我们可以将一个Rectangle*放入vector<Shape*>。但是,如果这个vector<Shape*>在其他地方被认为是一个vector<Circle*>,将会得到糟糕的、意外的结果。假设上面的例子能够编译通过,使用者认为通过vpc访问的一定是Circle对象,而实际上可能是一个Rectangle:
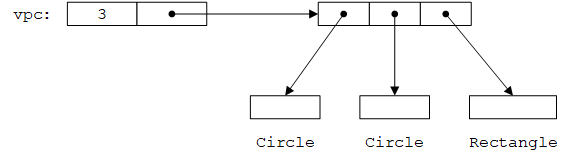
总之:对于任意模板C,“D是B”并不意味着“C<D>是C<B>”或“C<D*>是C<B*>”。
19.3.5 整数作为模板参数
除了类型,整数也可以作为模板参数。
下面考虑一个整数作为模板参数最常见的例子,元素个数在编译时已知的容器(数组):
简单数组
注:
- 模板参数是类型的一部分,因此
array<int, 5>和array<int, 10>是两种不同的类型。 - 由于
array的大小N在编译时是已知的,因此不需要使用自由存储,而是直接将elem成员声明为数组;相反,vector需要使用自由存储,elem成员只是一个指针。因此,array的元素是其本身的一部分,而vector的元素不是(见17.3.1节):sizeof(array<int, 100>) = 100 * sizeof(int) = 400sizeof(vector<int>(100)) = sizeof(int) + sizeof(int*) + sizeof(int) = 4 + 4 + 4 = 12(对于19.2.6节中的vector、32位系统)。
array支持列表初始化,是因为它只有一个数组类型的公有成员,见Aggregate initialization。array的默认构造函数、拷贝构造函数、拷贝赋值和析构函数都是由编译器自动生成的。由于elem是数组而不是指针,因此默认拷贝操作就是深拷贝,析构函数什么都不用做(内置数组本身不支持拷贝,但将其作为对象成员可以间接拷贝)。- 标准库提供了具有相同功能的
std::array,定义在头文件<array>中。
我们可以这样使用array:
array<double, 6> ad = {0.0, 1.1, 2.2, 3.3, 4.4, 5.5}; // initialize
void some_fct(int n) {
array<int, 4> loc = {0, 1, 2, 3};
array<char, n> oops; // error: the value of n not known to compiler
array<int, 4> loc2 = loc; // copy constructor
loc = loc2; // copy assignment
int x = loc[2]; // element access
loc[3] = 42;
// loc and loc2 automatically destroyed
}
显然,array非常简单,也不如vector强大。那么,为什么会有人希望使用array而不是vector呢?一种答案是“效率”。array的大小在编译时是已知的,因此编译器可以分配静态内存(对于全局对象)或栈内存(对于局部对象),而不是使用自由存储。
反过来,为什么不直接使用内置数组呢?如18.6节所述,内置数组很难用:不知道自身的大小,动不动就转换为指针,不能拷贝和赋值。而array不存在这些问题。例如:
double* p = ad; // error: no implicit conversion to pointer
double* q = ad.data(); // OK: explicit conversion
template<class C>
void printout(const C& c) { // function template
for (int i = 0; i < c.size(); ++i) cout << c[i] << '\n';
}
printout()对array和vector都可以调用,因为用到的接口(size()和[])对于二者是相同的。这是一个将泛型编程用于数据访问的简单例子,第20和21章将会详细介绍这种编程风格。
19.3.6 模板参数推导
对于类模板,当你创建特定类型的对象时需要指定模板参数。例如:
array<char, 1024> buf; // for buf, T is char and N is 1024
array<double, 10> b2; // for b2, T is double and N is 10
对于函数模板,编译器通常能够从函数参数中推断出模板参数(详见Template argument deduction)。例如:
template<class T, int N>
void fill(array<T, N>& a, const T& val) {
for (int i = 0; i < N; ++i) a[i] = val;
}
void f() {
fill(buf, 'x'); // for fill(), T is char and N is 1024 because that's what buf has
fill(b2, 0.0); // for fill(), T is double and N is 10 because that's what b2 has
}
fill(buf, 'x')是fill<char, 1024>(buf, 'x')的简写,fill(b2, 0.0)是fill<double, 10>(b2, 0.0)的简写。幸运的是,我们通常不必写得这么具体,编译器会自动为我们推断出来。
19.3.7 一般化vector类
当我们将“double向量”一般化为模板“T向量”时,并没有重新考虑push_back()、resize()和reserve()的实现。在19.2.2和19.2.3节中定义这些函数时做了一些假设,这些假设对double成立,但并不是对所有vector元素类型都成立:
- 如果
X没有默认值,如何处理vector<X>?(构造函数和resize()涉及使用默认值初始化,而double有默认值0.0) - 如何确保元素在用完后被销毁?(已经能够确保:拷贝赋值、移动赋值、析构函数和
reserve()使用delete[]释放数组时会自动调用每个元素的析构函数。但是如果要实现pop_back()、erase()等只删除元素、不释放数组的操作,则必须显式调用元素的析构函数。)
对于没有默认值的类型,可以增加一个参数,允许用户指定“默认值”:
void resize(int new_size, const T& v = T());
也就是说,使用T()作为默认值,除非用户指定了其他值(如果类型T没有默认值,则用户必须指定一个值,否则将编译失败)。例如:
vector<double> v1;
v1.resize(100); // add 100 copies of double(), that is, 0.0
v1.resize(200, 0.0); // add 100 copies of 0.0 - mentioning 0.0 is redundant
v1.resize(300, 1.0); // add 100 copies of 1.0
struct No_default {
No_default(int); // the only constructor for No_default
// ...
};
vector<No_default> v2(10); // error: tries to make 10 No_default()s
vector<No_default> v3;
v3.resize(100, No_default(2)); // add 100 copies of No_default(2)
v3.resize(200); // error: tries to add 100 No_default()s
但是,即使给构造函数和resize()增加了“默认值”参数,对于No_default仍然会报错。因为构造函数和reserve()中的 new[]会强制对所有元素进行初始化,而这对于没有默认值的类型是不可行的(见17.4.4节)。
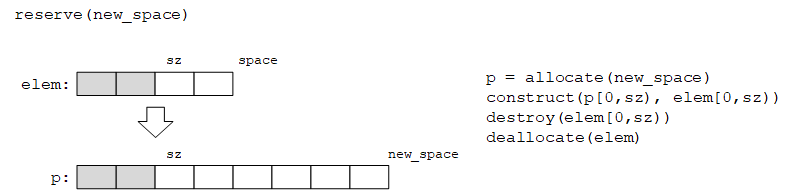
另一方面,空闲空间(即elem[sz:space))中的元素不需要初始化,因为它们不属于vector的有效范围,对其初始化会带来不必要的开销。我们需要一种同时包含已初始化数据和未初始化数据的数据结构(如下图所示)。作为vector的实现者,我们不得不面对这一问题。

基于以上两个原因,我们需要一种能够分配和操作未初始化内存的方法。C++标准库头文件<memory>提供了allocator类(分配器),能够提供未初始化内存。下面是其简化版本:
template<typename T>
class allocator {
public:
// ...
// allocate uninitialized storage for n objects of type T
T* allocate(int n) { return static_cast<T*>(operator new(n * sizeof(T))); }
// deallocate n objects of type T starting at p
void deallocate(T* p, int n) { operator delete(p, n * sizeof(T)); }
// construct a T with the value v in p
void construct(T* p, const T& v) { new(p) T(v); }
// destroy the T in p
void destroy(T* p) { p->~T(); }
};
这里列出了4个基本操作:
- 分配能够容纳n个
T类型对象(即n * sizeof(T)字节)的未初始化内存空间(不调用构造函数) - 在未初始化内存中构造一个
T类型对象 - 销毁一个
T类型对象,将其所在内存返回到未初始化状态 - 释放能够容纳n个
T类型对象的内存空间(不调用析构函数)
例如:
struct C {
C(int x) {}
~C() {}
};
void f() {
allocator<C> alloc;
int n = 3;
C* p = alloc.allocate(n);
for (int i = 0; i < n; ++i)
alloc.construct(p + i, i); // calls C(int)
for (int i = 0; i < n; ++i)
alloc.destroy(p + i); // calls ~C()
alloc.deallocate(p, n);
}
注:
- C++20将
allocator的construct()和destroy()函数移至allocator_traits类。 - 实际上
allocator::allocate()就是使用malloc()函数实现的,使用该函数代替allocator也能解决上述问题。使用allocator的另一个原因是:将内存分配/释放与对象构造/销毁分离,并抽象为接口,从而支持自定义内存管理策略,提供更好的灵活性。 - 除了
allocator外,标准库头文件<cstdlib>提供了malloc()函数,<new>提供了一组operator new和operator new[]函数,都能够分配未初始化内存。这些函数与new/new[]的区别和联系:new和new[]叫做new表达式(new expression),是语言级别的运算符;operator new和operator new[]叫做分配函数(allocation functions),是标准库头文件<new>中定义的一组库函数。new在分配内存后会调用构造函数来初始化对象,而operator new和malloc()只负责分配内存。new通过调用operator new分配内存,而operator new就是通过调用malloc()函数实现的。new(p) T(args...)这种特殊形式的new叫做Placement new,并不分配内存,而是在已分配的未初始化内存空间中(原地)构造对象(这是手动调用构造函数的唯一方法)。
- 下表总结了在自由存储上分配内存/初始化对象的各种方法:
| 方法 | 分配内存(字节) | 初始化对象(调用构造函数) |
|---|---|---|
new T(args...) | sizeof(T) | 是 |
new T[n]{...} | n * sizeof(T) | 是 |
new(p) T(args...) | 无 | 是 |
allocator<T>::allocate(n) | n * sizeof(T) | 否 |
allocator<T>::construct(p, args...) | 无 | 是 |
operator new(n) | n | 否 |
operator new(n, p) | 无 | 否 |
malloc(n) | n | 否 |
(回到正题)allocator正是我们实现vector<T>::reserve()所需要的。首先给vector增加一个模板参数A(用于支持自定义分配器):
template<class T, class A = allocator<T>>
class vector {
A alloc; // use allocate to handle memory for elements
// ...
};
注:与函数的默认参数一样,模板也支持默认参数,并且只需要在声明中写出。
vector中所有直接处理内存(使用new和delete)的成员函数都需要修改:
简单向量v3 - 使用allocator
在reserve()中,通过alloc.construct(&p[i], elem[i])拷贝旧元素时,间接调用了元素的拷贝构造函数(这意味着vector的元素类型必须是可拷贝构造的)。这里不能使用赋值 (p[i] = elem[i]),因为对于像string这样的类型,赋值假设目标对象是已初始化的,而p[i]是未初始化的。
在resize()中,将vector缩小时,还需要考虑多余元素的销毁。这里把析构函数看成将具有类型的对象变成“原始内存”。
注:
- 使用
allocator时,必须将内存分配/释放与对象构造/析构分开考虑,要想清楚内存空间是已初始化的还是未初始化的,应该对元素赋值还是构造,元素是否需要销毁等。 - 书中并未给出修改后的构造函数、拷贝操作和移动操作,而使用
allocator正确地实现这些操作并非易事。在纸上画出元素在内存中的示意图并写出伪代码会很有帮助。例如:
(1)reserve()
(2)resize()

(3)push_back()
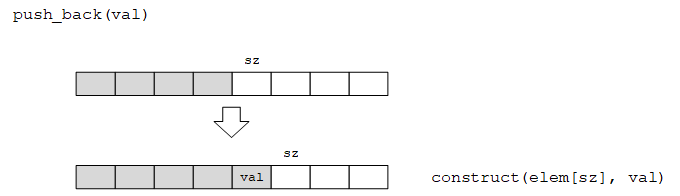
(4)构造函数
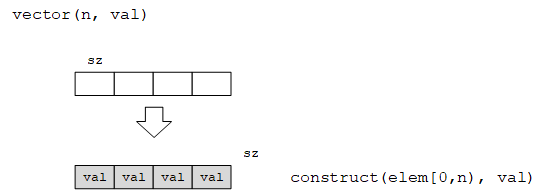
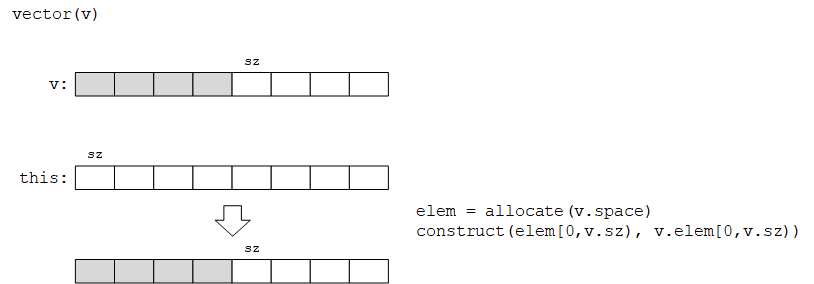
(5)拷贝构造
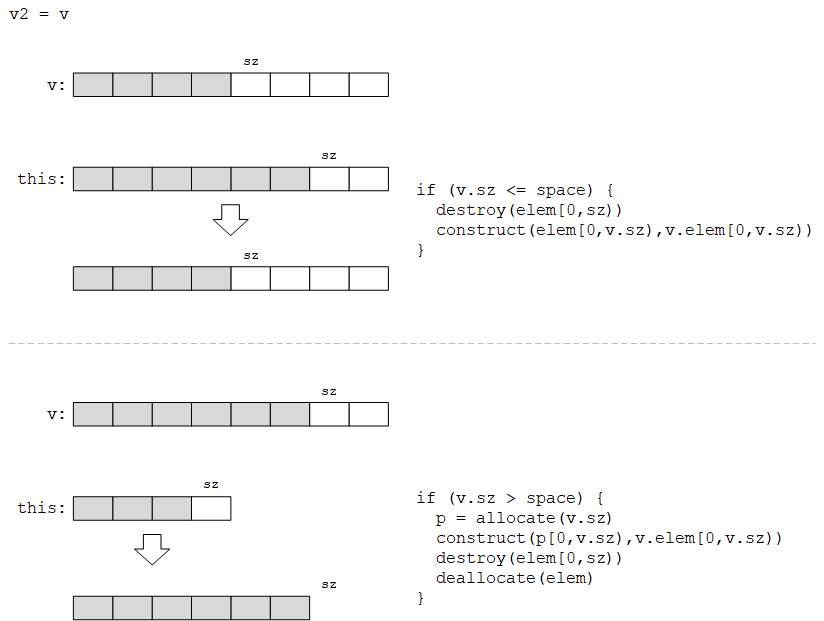
(6)拷贝赋值






![【读书笔记】《小王子》- [法] 安托万•德•圣埃克苏佩里 / [法国] 安东尼·德·圣-埃克苏佩里](https://img-blog.csdnimg.cn/9a6a3f8fd36e49dc90e1a3eb0c77fc8d.png#pic_center)
![【Java入门】-- Java基础详解之 [数组、冒泡排序]](https://img-blog.csdnimg.cn/ab4fbf404e044c9cabbdd8d7ab2329d7.png)