好久没有更新文章了,在忙学校的事情时我还是比较怀念大家一直以来对我的关注和鼓励,接下来我会继续更新数据结构相关的文章,也请大家多多支持,十分感谢。正文来了:
首先说明一点,我在举例和比较时所使用的是链表中效率最高的带头双向循环链表,请大家注意。
链表与顺序表的区别
链表
优点:
- 在任意位置插入和删除数据时,效率为O(1)
- 可以按需申请和释放空间
缺点:
- 不支持下标的随机访问
顺序表
缺点:
- 在对靠近顺序表前面位置的数据进行插入和删除时需要进行挪动数据,效率非常低,近似可看为O(N)
- 开辟的空间用完时,需要进行扩容,在使用realloc函数进行扩容时会出现原地扩容和异地扩容,同时也会存在扩容的空间并没有完全占用,出现了空间浪费,在释放时也必须全部释放
优点:
- 在进行尾插尾删操作时效率确实不错
- 下标的随机访问也是顺序表非常重要也是非常好用的一点
计算机硬件的存储体系
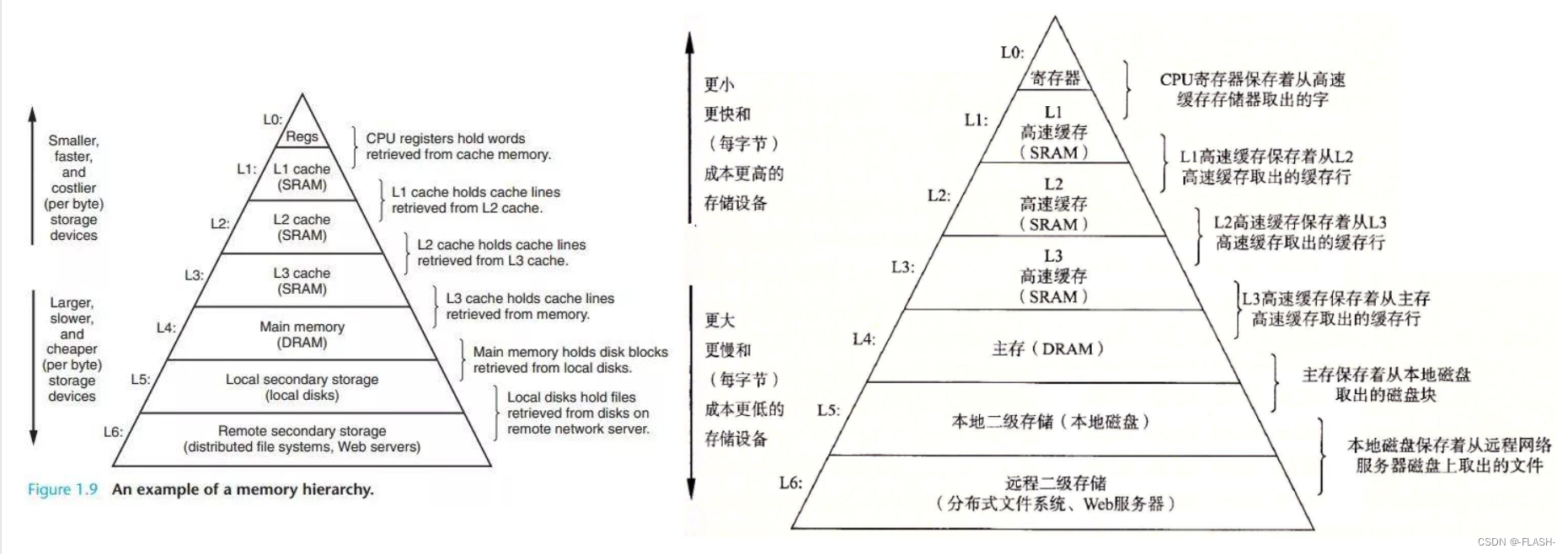
主存,也称内存,其特点是带电存储,在实际生活中,我们在撰写文章,编辑文件,写代码时都是内存在临时存储的,只有通过保存,才能将我们修改的文件永久保存在磁盘中。
我们在计算机上进行的一系列操作,都是通过CPU(中央处理器)来执行。CPU的速度是非常快的,因此计算机在进行一系列指令时,CPU都会根据数据大小来通过寄存器和三级高速缓存进行读取内存中数据来进行下一步操作。
若需要处理的数据过大,数据则会被放在三级高速缓存中,这里就衍生出 “缓存命中” 的问题:
- 先去看内存是否在缓存中,在就叫缓存命中,直接进行访问
- 若不在就不命中,则先加载数据到缓存,再访问
另外,CPU在三级高速缓中读取数据时,不会将数据一个字节一个字节的加载,而是加载一块数据,通常是一个CPU的字长。
因此再不那么频繁的插入和删除数据的情况下,顺序表的效率是要高于链表的。在频繁的插入和删除数据时,链表的效率虽然也不是很高,但也比顺序表强一些。
想要多了解CPU相关内容的朋友,可以移步陈皓前辈的这篇文章:与程序员相关的CPU缓存知识