目录标题
- map容器的介绍
- pair的介绍
- map的构造函数
- insert函数
- make_pair函数
- find函数
- map的[ ]重载
- multimap
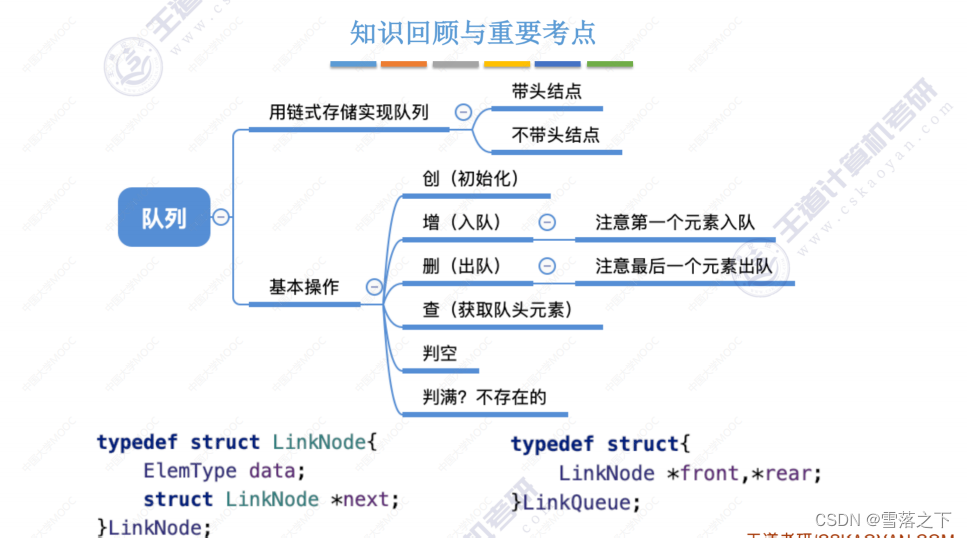
map容器的介绍
通过之前的学习想必大家对set容器的理解应该非常的深刻了,我们知道他的底层是一个k结构的搜索二叉树,可以对数据进行去重并排序,那么这里的map的底层就是一个kv结构的搜索二叉树,他在对数据进行去重和排序的同时还可以通过这个数据存储另外一个数据的内容,那么这另外一个数据就是这里的V,在前面的学习中我们将k和v分开定义,类型k创建一个变量,类型v创建一个变量,但是库中map的底层并不是通过来个变量来实现的kv结构而是通过一个pair来实现的。
pair的介绍
pair是struct定义的类模板,比如说下面的代码:
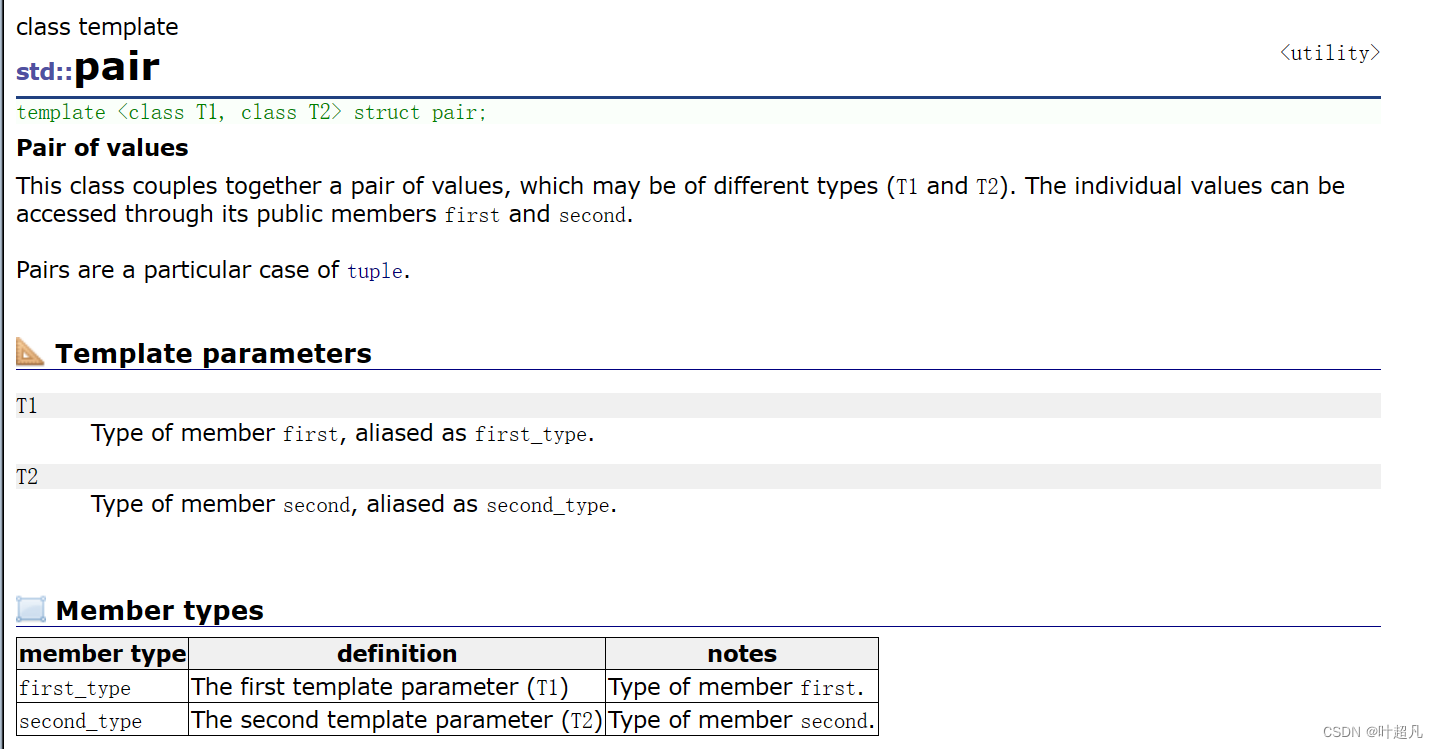
pair结构体里面含有两个变量分别为first和second,其中first表示的就是key,second表示的就是value,其次pair有三种不同形式的构造函数,比如说下面的图片:

第一种就是创建一个空pair,第二个就是pair的拷贝构造函数,第三个就是传递两个值来构造pair,其中第一个参数表示的就是pair种的first元素,第二个参数表示的就是pair种的second元素,比如说下面的代码:
void func7()
{
pair<int, int> tmp1;
pair<int, int> tmp2(10,20);
pair<int, string> tmp3(20, "hello");
pair<int, string> tmp4(tmp3);
cout << tmp2.first << ":" << tmp2.second << endl;
cout << tmp3.first << ":" << tmp3.second << endl;
cout << tmp4.first << ":" << tmp4.second << endl;
}
这段代码的运行结果如下:
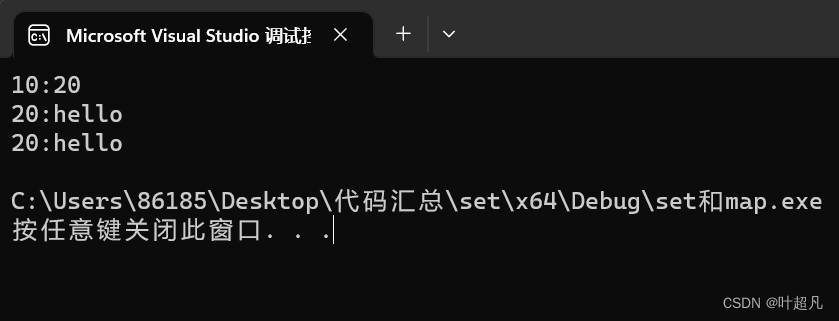
之前的二叉搜索树我们是分开定义的k和v,而现在我们把两个值通过pair组合到了一起来定义这样做的原因就是可以更加方便的管理容器的结构,比如说map中即存在k又存在v,而迭代器又是一个像指针一样的东西,对迭代器解引用可以拿到迭代器里面的数据,那对map的迭代器进行解引用得到的究竟是k还是v呢?对吧,c++是不支持一下子返回两个值的,所以就有了pair。
map的构造函数
首先来看看map的构造函数有哪些形式:
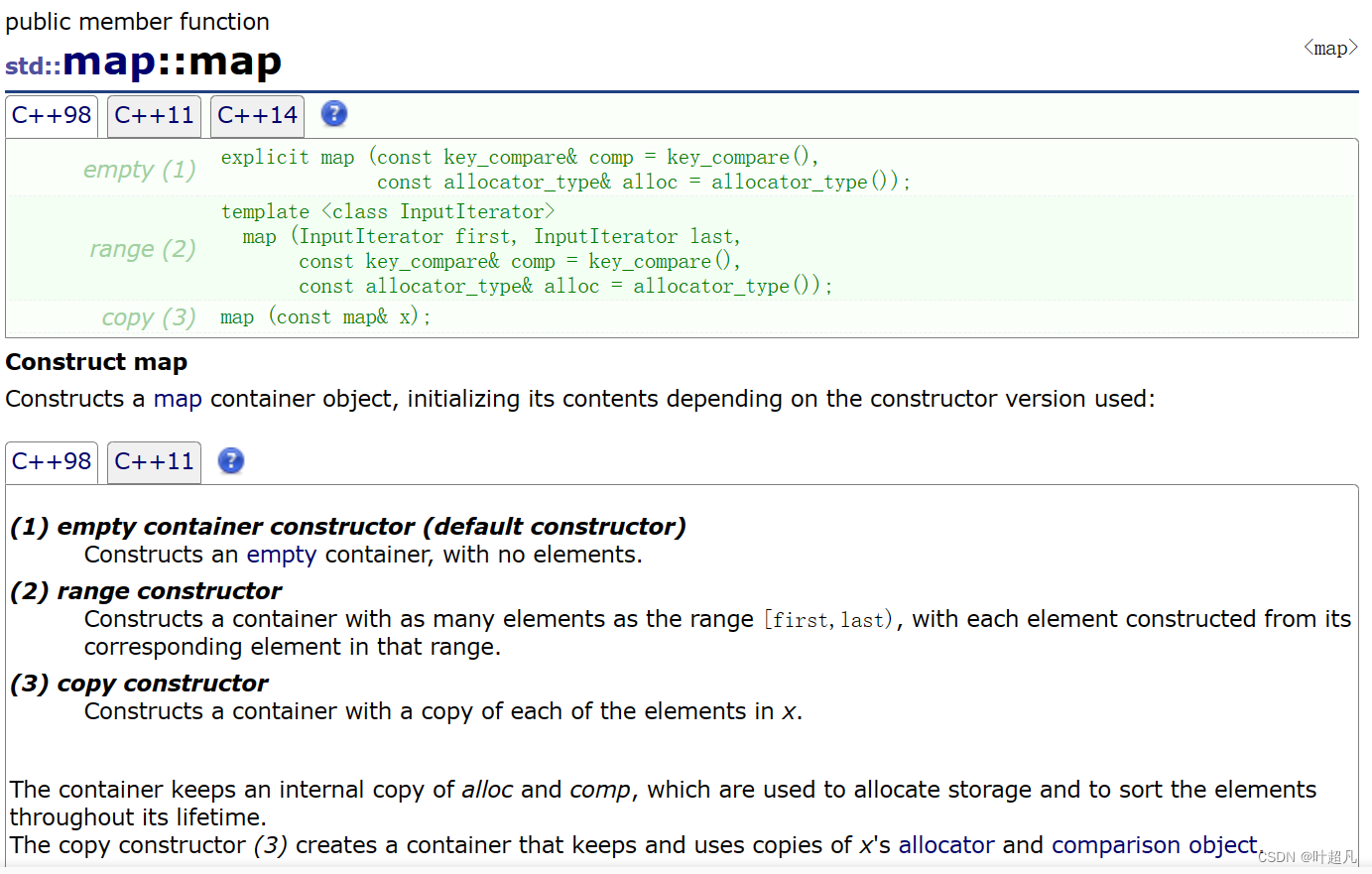
第一种就是构造一个空的map比如说下面的代码:
void func()
{
map<int, string> tmp1;
map<int, vector<int>> tmp2;
map<char, list<int>> tmp3;
}
那么这里就创建了三个不同kv结构的map,tmp1是根据int的值来查找对应的string数据,tmp2是根据int的值来查找对应的vector<int>的数据,tmp3则是根绝char的值来查找对应的list<int>的数据,那么这就是构造函数的第一种用法,第二种就是通过迭代器区间来进行初始化,将迭代器区间中的内容初始化到新创建的map容器里面,比如说下面的代码:
void func1()
{
map<int, string> m;
m.insert(pair<int, string>(10, "abcd"));
m.insert(pair<int, string>(9, "efg"));
m.insert(pair<int, string>(8, "hijkl"));
map<int, string> m1(m.begin(), m.end());
}
那么这种就是使用迭代器区间来进行初始化,通过调试就可以看到m1里面的内容和m是一摸一样的:
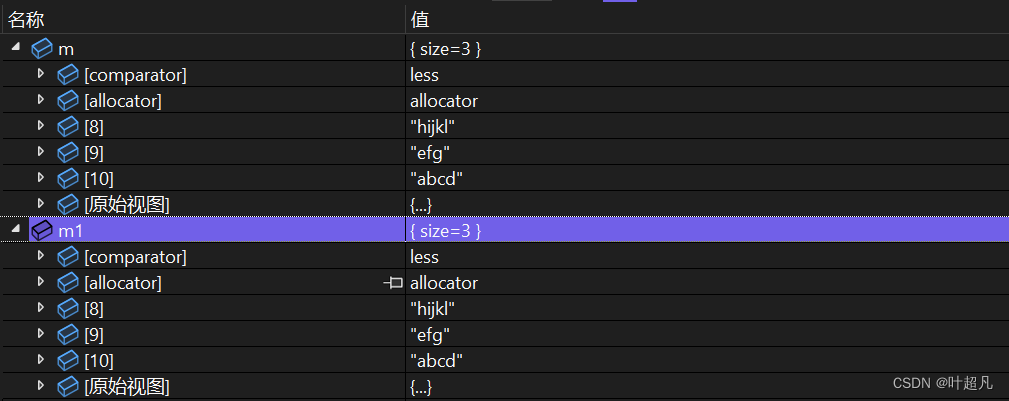
那么这就是迭代器区间的构造函数,当然这里的迭代器也可以是其他容器的迭代器,比如说下面的代码:
void func1()
{
vector<pair<int, string>> v;
v.push_back(pair<int, string>(1, "a"));
v.push_back(pair<int, string>(2, "b"));
v.push_back(pair<int, string>(3, "c"));
v.push_back(pair<int, string>(4, "d"));
v.push_back(pair<int, string>(5, "e"));
v.push_back(pair<int, string>(6, "f"));
vector<pair<int, string>>::iterator begin = v.begin() + 1;
vector<pair<int, string>>::iterator end = v.end() -1;
map<int, string> m(begin, end);
}
这里就将v中的部分数据拷贝到了容器里面,通过调试可以看到容器中的数据如下:
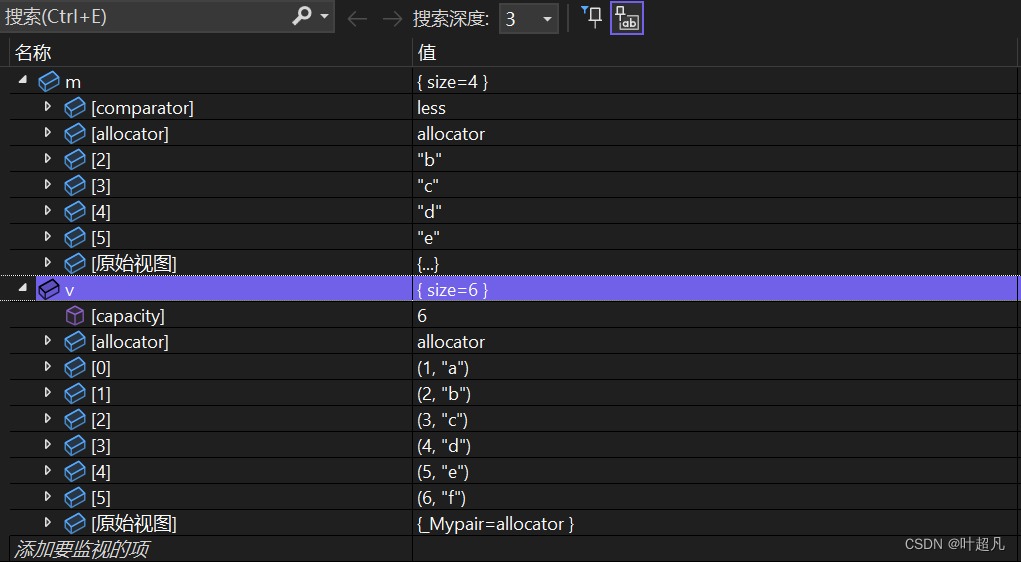
第三种就是拷贝构造,那么这里就不多解释,大家直接看看下面的代码:
void func1()
{
vector<pair<int, string>> v;
v.push_back(pair<int, string>(1, "a"));
v.push_back(pair<int, string>(2, "b"));
v.push_back(pair<int, string>(3, "c"));
v.push_back(pair<int, string>(4, "d"));
v.push_back(pair<int, string>(5, "e"));
v.push_back(pair<int, string>(6, "f"));
vector<pair<int, string>>::iterator begin = v.begin() + 1;
vector<pair<int, string>>::iterator end = v.end() -1;
map<int, string> m(begin, end);
map<int, string> m1(m);
}
通过调试可以看到这里容器的内容如下:
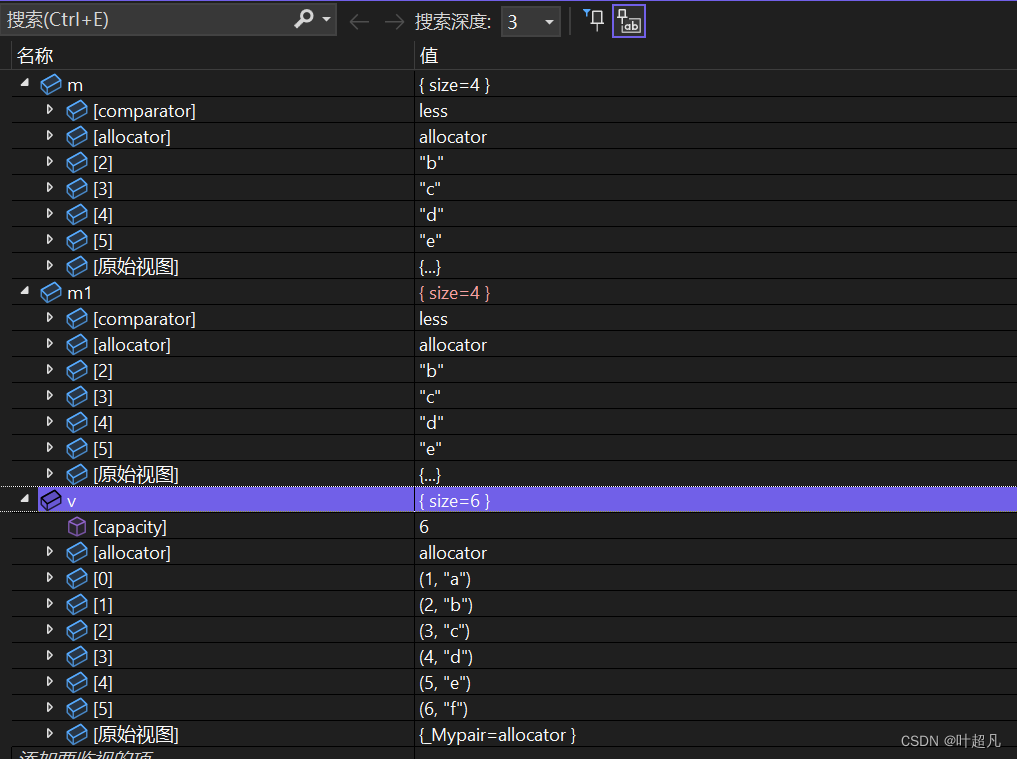
可以看到m1的数据内容和m的数据内容是一摸一样的,那么这就是第三种形式的构造函数。看到这里想必大家已经知道了map的构造函数的用法,那么接下来我们就来看看如何将数据插入的map容器里面。
insert函数
insert函数可以往map容器里面插入数据,我们来看看insert函数的介绍:

map的insert函数和set的insert函数几乎是一摸一样的,由于map也是基于搜索二叉树的结构,所以这里是不支持往map的尾部插入数据的所以map没有push_back函数,insert函数的第一种形式就是往容器里面插入value_type类型的数据,也就是往容器里面插入pair类型的数据,比如说下面的代码:
void func2()
{
map<int, string> m;
pair<int, string> p(1,"a");
m.insert(p);
m.insert(pair<int, string>(2, "b"));
}
第一种形式的返回值是pair类型,并且他的first是一个迭代器,second是一个bool类型,如果数据插入成功的话迭代器指向的是新开辟的空间并且sceond的值为true,如果原容器中存在相同的数据(这里的相同数据比较的是k不包括v)导致没有插入成功的话迭代器指向的是容器中已有的数据并且second的值为false,我们可以通过下面的代码来进行验证:
void func3()
{
map<int, string> m;
m.insert(pair<int, string>(1, "a"));
m.insert(pair<int, string>(2, "b"));
m.insert(pair<int, string>(3, "c"));
m.insert(pair<int, string>(4, "d"));
map<int, string> m1(m);
auto tmp = m1.insert(pair<int, string>(1, "b"));
if (tmp.second == true)
{
cout << "插入数据成功" << endl;
cout << "新插入的数据为:" << (*(tmp.first)).first << " : " << tmp.first->second << endl;
}
else
{
cout << "插入数据失败" << endl;
cout <<"已有的数据为" <<tmp.first->first<<" : " << tmp.first->second << endl;
}
tmp = m1.insert(pair<int, string>(5, "e"));
if (tmp.second == true)
{
cout << "插入数据成功" << endl;
cout << "新插入的数据为:" << tmp.first->first << " : " << tmp.first->second << endl;
}
else
{
cout << "插入数据失败" << endl;
cout << "已有的数据为" << tmp.first->first << " : " << tmp.first->second << endl;
}
}
这段代码的运行结果如下:
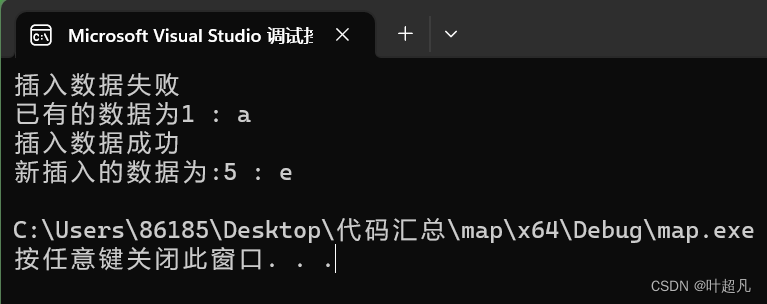
这里大家要注意的一点就是pair结构体是不支持流读取的但是他的所有数据都是公共的,所以不能直接对map的迭代器解引用并用cout打印里面的内容,而是通过first和second来读取pair里面的数据 ,那么这就是insert函数的第一种形式,第二种形式就是通过迭代器的指向,向指定位置插入数据,之前我们说过搜索二叉树每个节点都有很紧密的联系,往指定位置插入数据很可能会干扰这种联系使其不再是搜索二叉树,所以这种形式我们不建议使用,第三种形式就是迭代器区间插入,将迭代器区间里面的内容插入到容器里面,比如说下面的代码:
void func4()
{
map<int, string> m;
vector<pair<int, string>> v;
v.push_back(pair<int, string>(1, "a"));
v.push_back(pair<int, string>(2, "b"));
v.push_back(pair<int, string>(3, "c"));
v.push_back(pair<int, string>(4, "d"));
m.insert(v.begin(), v.end());
for (auto ch : m)
{
cout << ch.first << ":" << ch.second << endl;
}
}
那么上面的代码运行的结果就如下:
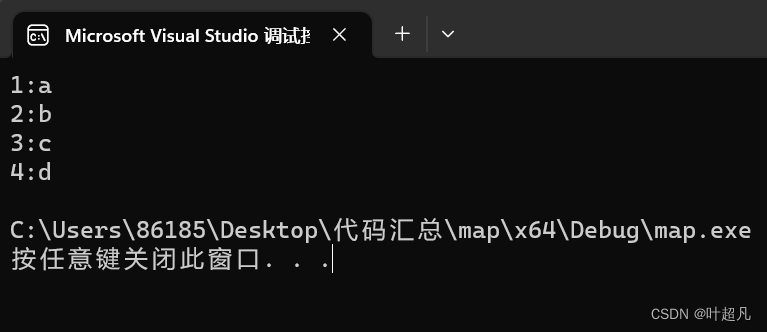
那么这就是insert函数的第三种形式。
make_pair函数
通过上面的例子大家可以应该知道了如何往容器里面插入数据,可是大家有没有发现一个现象好像每次插入数据都很麻烦对吧,有匿名对象还好点我们可以在传参的时候顺便创建一个对象,那没有匿名对象的话在插入数据之前还得创建一个一摸一样的pair对象,是不是就很麻烦对吧,所以就有了make_pair函数,我们来看看这个函数的介绍:

这个函数的作用就是根据我们传的参数类型自动创建pair对象,并且返回值也是相应的pair类型,make_pair的第一个参数就对应的是pair中的k,第二个参数就对应的是pair中的v,所以我们使用isnert函数的时候就可以这样:
void func5()
{
map<int, string> m;
m.insert(make_pair(1, "a"));
m.insert(make_pair(2, "b"));
m.insert(make_pair(3, "c"));
}
可以在一定程度上减少写代码的成本。
find函数
首先来看看find函数的介绍:
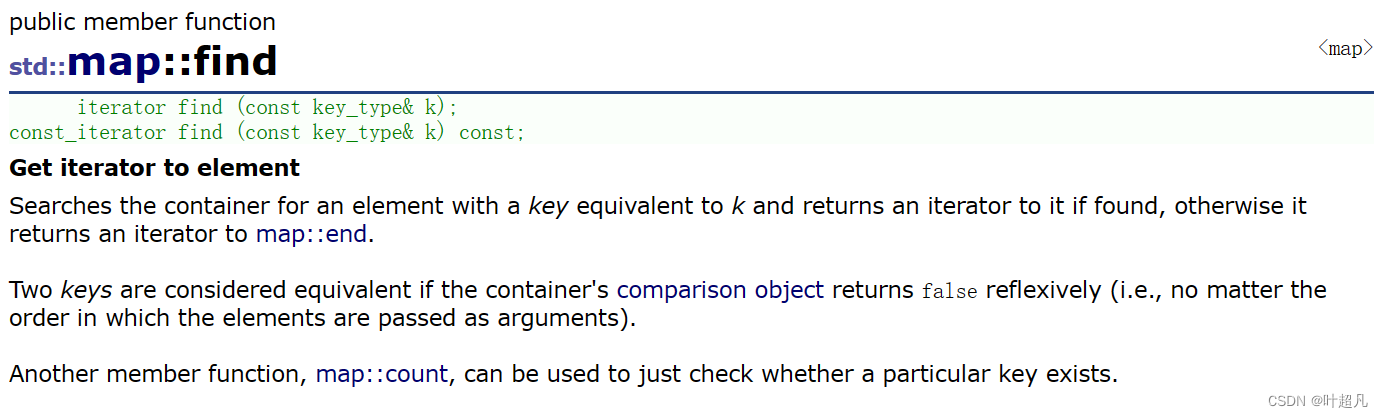
find函数找到数据之后就会返回一个指向该位置的迭代器,如果没有找到的话这个迭代器的值就为end,比如说下面的代码:
void func5()
{
map<int, string> m;
m.insert(make_pair(1, "a"));
m.insert(make_pair(2, "b"));
m.insert(make_pair(3, "c"));
auto it = m.find(2);
if (it != m.end())
{
cout << it->first << ":"<<it->second << endl;
}
else
{
cout << "该数据不存在" << endl;
}
}
这段代码的运行结果如下:
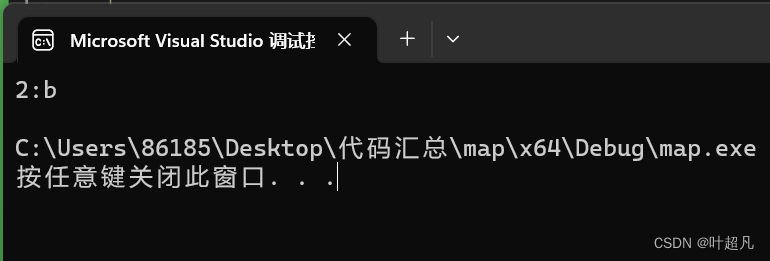
如果我们给这个find传递一个不存在的k值的话就会返回一个指向end的迭代器,比如说下面的代码:
void func5()
{
map<int, string> m;
m.insert(make_pair(1, "a"));
m.insert(make_pair(2, "b"));
m.insert(make_pair(3, "c"));
auto it = m.find(4);
if (it != m.end())
{
cout << it->first << ":"<<it->second << endl;
}
else
{
cout << "该数据不存在" << endl;
}
代码的运行结果如下:
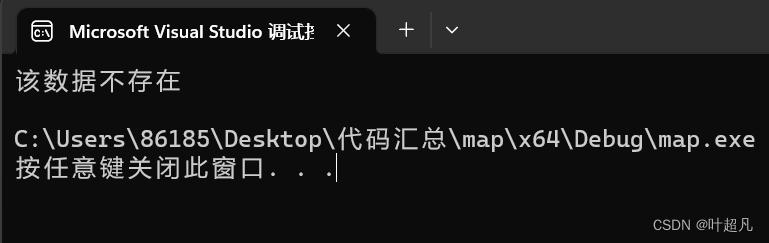
那么这就是find函数的用法。
map的[ ]重载
首先我们用map来实现一个统计一个数组中各种水果名字出现的次数,比如说下面的代码:
void func6()
{
string arr[] = { "苹果","苹果", "苹果", "苹果", "苹果",
"香蕉","香蕉", "香蕉", "香蕉", "香蕉",
"西瓜","西瓜", "西瓜", "梨子", "梨子" };
}
我们要对数组中出现的各种水果名进行统计并得到每个水果名出现的次数,那这里我们就可以创建一个map并以string类型的数据为k,以int类型的数据为v,然后用for循环遍历arr中的每个元素,并用find函数查找当前遍历的元素是否在map里面,如果在的话就对该数据的second进行++,如果不在的话往就往map里面插入一个数据,比如说下面的代码:
string arr[] = { "苹果","苹果", "苹果", "苹果", "苹果",
"香蕉","香蕉", "香蕉", "香蕉", "香蕉",
"西瓜","西瓜", "西瓜", "梨子", "梨子" };
map<string, int> m;
for (auto ch : arr)
{
auto it = m.find(ch);
if (it != m.end())//说明当前的元素在map里面
{
it->second++;
}
else//说明当前的元素不在map里面
{
m.insert(make_pair(ch, 1));
}
}
最后我们再使用范围for遍历一下map容器就可以达到我们的预期,比如说下面的代码:
void func6()
{
string arr[] = { "苹果","苹果", "苹果", "苹果", "苹果",
"香蕉","香蕉", "香蕉", "香蕉", "香蕉",
"西瓜","西瓜", "西瓜", "梨子", "梨子" };
map<string, int> m;
for (auto ch : arr)
{
auto it = m.find(ch);
if (it != m.end())//说明当前的元素在map里面
{
it->second++;
}
else//说明当前的元素不在map里面
{
m.insert(make_pair(ch, 1));
}
}
for (auto ch : m)
{
cout << ch.first << ":" << ch.second << endl;
}
}
那么代码的运行结果就如下:
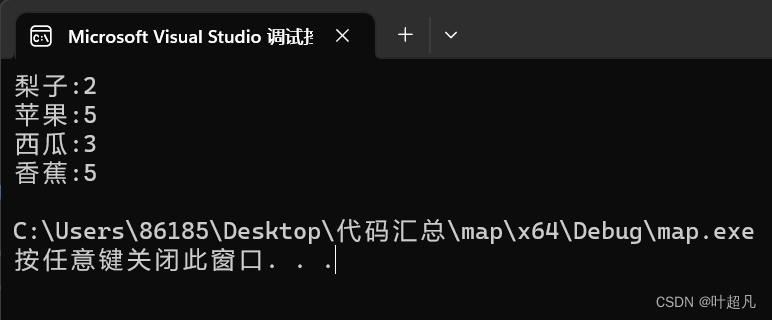
可以看到上面的代码符合我们的预期,但是这么写好像有那么点麻烦我们可以可以将其改进一下变成下面的形式也能达到我们的要求,比如说下面的代码:
void func6()
{
string arr[] = { "苹果","苹果", "苹果", "苹果", "苹果",
"香蕉","香蕉", "香蕉", "香蕉", "香蕉",
"西瓜","西瓜", "西瓜", "梨子", "梨子" };
map<string, int> m;
for (auto ch : arr)
{
m[ch]++;
}
for (auto ch : m)
{
cout << ch.first << ":" << ch.second << endl;
}
}
这段代码的运行结果如下:
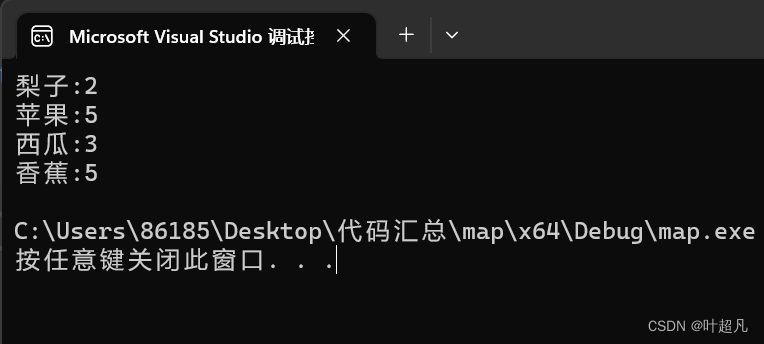
代码的运行结果是一样的,但是比上面的简单了许多,那这里的原理是什么呢?我们来看看map容器中对[ ]重载的介绍:
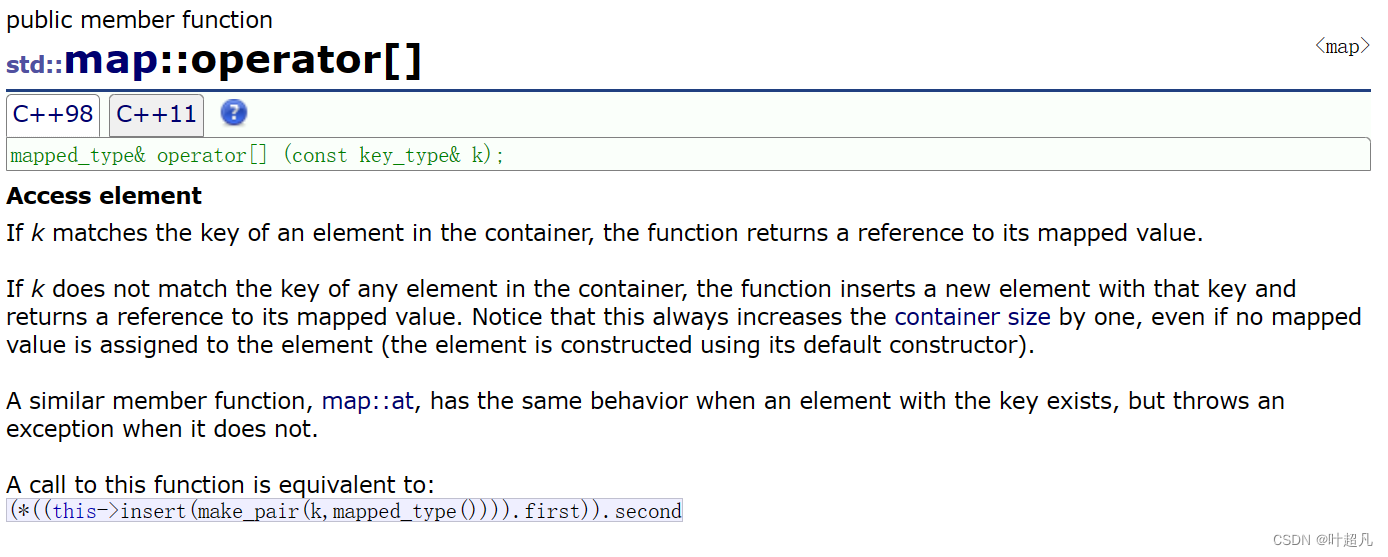
首先方括号重载的声明是这样的: mapped_type& operator[](const key_type&k) 接受的参数类型为key_type也就是我们平时说的Key,返回的数据类型为mapped_type也就是我们平时说的value,方括号重载执行的操作就是下面这样:return (*((this->insert(make_pair(k,mapped_type()))).first)).second;也就是说方括号本质上调用的是insert函数,给insert函数传递的参数为看,另外一个为v的默认构造函数,我们将insert函数去掉就变成了下面这个样子:return (*(返回值.first)).second;先拿到insert返回的pair然后取得第一个第一个元素并对其进行解引用,我们知道insert返回的是pair,该pair中的第一个元素为指向原有的或者新创建元素的迭代器,那么对这个迭代器解引用我们就可以拿到map容器中我们想要的数据,那么再去掉一层就变成这样:(*迭代器).second这里的迭代器是map的迭代器,所以对他解引用就可以map中的pair的数据,这里拿的是second就是v的数据,并将其返回所以我们就可以直接通过方括号来插入数据并对内部数据的value进行修改,这里可以对方括号进行一下简化变成下面这样大家就可以更好的理解:
v& operator[](const K& k)
{
pair<iterator,bool> ret =insert(make_pair(k,v()));
return ret.first->second;
//这里的迭代器指向的又是一个迭代器,并且是引用返回所以这里可以根据返回值来进行一下修改
}
所以map的方括号就会有这么一个特性:如果容器中不存在要查找的数据那么他会自动创建该数据并返回该数据的value,如果容器存在了就不会自动创建直接返回该数据的value。
multimap
multimap的允许数据冗余,但是它没有提供方括号的功能,因为方括号具备插入和查找的功能,这里有多个数据所以方括号不知道要返回哪一个,所以这里就不提供方括号,但是提供find函数,这个也是返回中序的第一个出现的要查找的元素。
multimap也可以用来统计次数比如说下面的代码:
void func7()
{
string arr[] = { "苹果","苹果", "苹果", "苹果", "苹果",
"香蕉","香蕉", "香蕉", "香蕉", "香蕉",
"西瓜","西瓜", "西瓜", "梨子", "梨子" };
multimap<string, int> m;
for (auto ch : arr)
{
auto it = m.find(ch);
if (it != m.end())//说明当前的元素在map里面
{
it->second++;
}
else//说明当前的元素不在map里面
{
m.insert(make_pair(ch, 1));
}
}
for (auto ch : m)
{
cout << ch.first << ":" << ch.second << endl;
}
multimap<string, string> m1;
m1.insert(make_pair("苹果", "香蕉"));
m1.insert(make_pair("苹果", "梨子"));
m1.insert(make_pair("苹果", "西瓜"));
for (auto ch : m1)
{
cout << ch.first << ":" << ch.second << endl;
}
}
这段代码的运行结果如下:
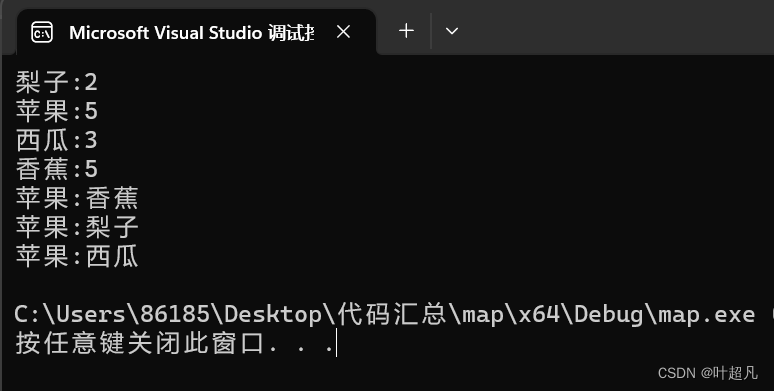
那么这就是multimap的用法,用的很少并且功能和map非常的相似,所以这里就不多说了。