一、RLHF微调三阶段
参考:https://huggingface.co/blog/rlhf
1)使用监督数据微调语言模型,和fine-tuning一致。

2)训练奖励模型
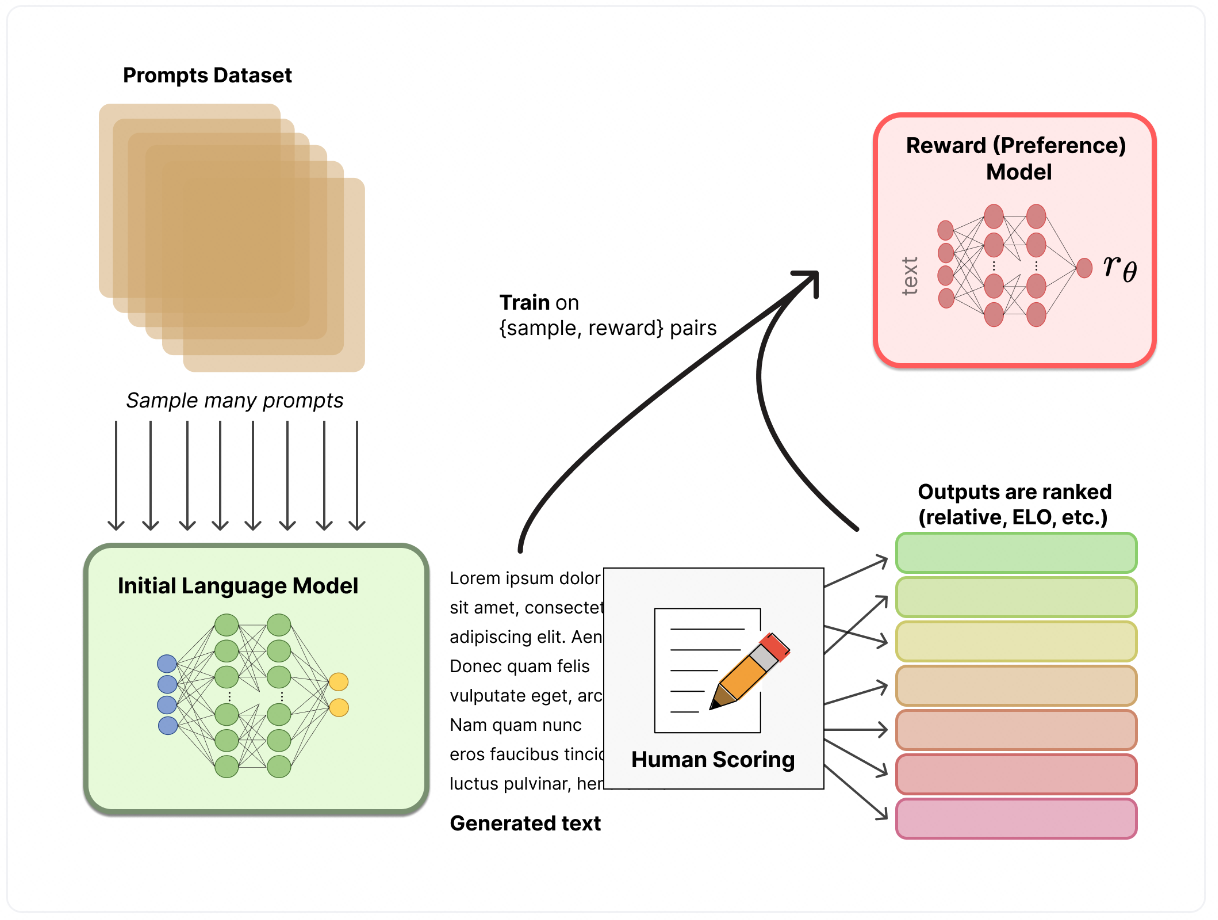
奖励模型是输入一个文本序列,模型给出符合人类偏好的奖励数值,这个奖励数值对于后面的强化学习训练非常重要。构建奖励模型的训练数据一般是同一个数据用不同的语言模型生成结果,然后人工打分。如果是训练自己领域的RLHF模型,也可以尝试用chatgpt打分,效果也不错。
3)训练RL模型
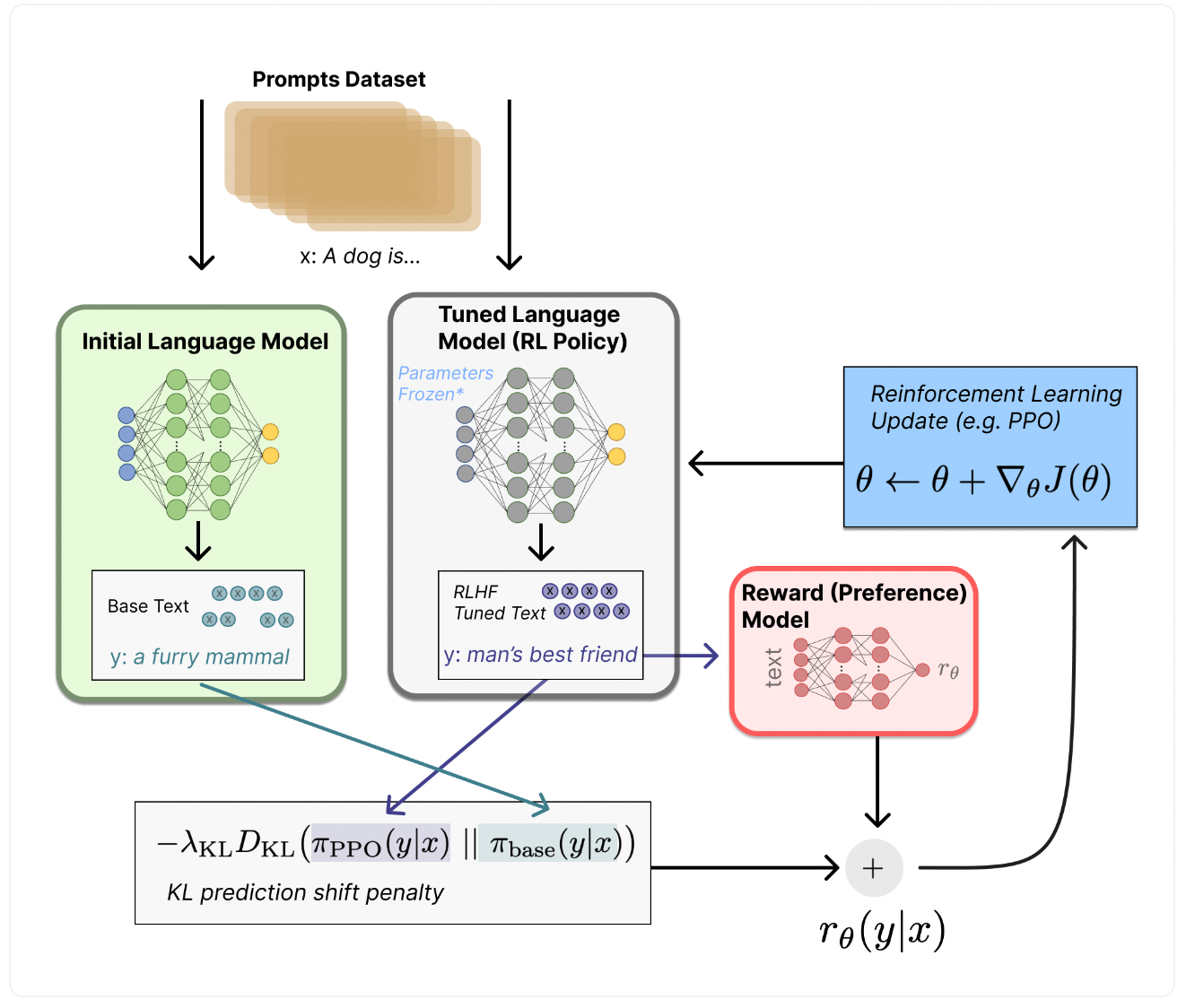
在训练强化学习模型时,需要搞清楚状态空间、动作空间、策略函数、价值函数这些东西,动作空间就是所有的token,状态空间就是输入的序列的分布,价值函数由第二步的奖励模型和策略约束结合,策略函数就是微调的大模型。
从上图可以看出,给定一个输入x,会生成两个文本y11和y22,一个来自于初始的模型,另一个来自于微调的模型,微调的模型生成的文本还会进入到奖励模型中打分输出rθ,而初始模型和微调的模型生成的结果会用KL散度约束它们的分布,确保模型不会太偏离原来的模型,并且能输出高质量的回复。
值得注意的是三个阶段的训练数据尽量是分布一致的,否则后面的训练会很不稳定。所以在第一步微调时不要一味地使用大量的训练数据(这一步的数据比较容易获得),尽量和后面两步的数据分布保持一致。
二:RLHF代码理解
以DeepSpeed-Chat的代码去理解RLHF的过程。https://github.com/microsoft/DeepSpeedExamples/tree/master/applications/DeepSpeed-Chat
DeepSpeed-Chat提供了RLHF三个阶段的训练代码,可以很方便地训练三个阶段,现在我们来一个一个阶段地来看。
1)数据集处理
首先从数据集的处理出发,去理解三个阶段的输入是什么样的数据?在training/utils/data/raw_datasets.py提供了多种开源数据集的读取方式,可以看到每个数据集都包含prompt(提问),chosen(正向回答),rejected(负向回答)。以其中某一个为例:
class DahoasRmstaticDataset(PromptRawDataset):
def __init__(self, output_path, seed, local_rank, dataset_name):
super().__init__(output_path, seed, local_rank, dataset_name)
self.dataset_name = "Dahoas/rm-static"
self.dataset_name_clean = "Dahoas_rm_static"
def get_train_data(self):
return self.raw_datasets["train"]
def get_eval_data(self):
return self.raw_datasets["test"]
def get_prompt(self, sample):
return sample['prompt']
def get_chosen(self, sample):
return sample['chosen']
def get_rejected(self, sample):
return sample['rejected']
def get_prompt_and_chosen(self, sample):
return sample['prompt'] + sample['chosen']
def get_prompt_and_rejected(self, sample):
return sample['prompt'] + sample['rejected']具体的数据处理在training/utils/data/data_utils.py中,下面的代码展示了三个阶段使用的输入是什么?在第一步,即监督微调大模型,使用prompt + chosen;在第二步,即训练奖励模型时,需要使用prompt + chosen 和 prompt + rejected;在第三步,即训练RL模型,只使用prompt。
if train_phase == 1:
for i, tmp_data in enumerate(current_dataset):
# tokenize the text
chosen_sentence = raw_dataset.get_prompt_and_chosen(
tmp_data) # the accept response
if chosen_sentence is not None:
chosen_sentence += end_of_conversation_token
chosen_token = tokenizer(chosen_sentence,
max_length=max_seq_len,
padding="max_length",
truncation=True,
return_tensors="pt")
chosen_token["input_ids"] = chosen_token["input_ids"].squeeze(
0)
chosen_token["attention_mask"] = chosen_token[
"attention_mask"].squeeze(0)
chosen_dataset.append(chosen_token)
elif train_phase == 2:
for i, tmp_data in enumerate(current_dataset):
# tokenize the text
chosen_sentence = raw_dataset.get_prompt_and_chosen(
tmp_data) # the accept response
reject_sentence = raw_dataset.get_prompt_and_rejected(
tmp_data) # the accept response
if chosen_sentence is not None and reject_sentence is not None:
chosen_sentence += end_of_conversation_token # the accept response
reject_sentence += end_of_conversation_token
chosen_token = tokenizer(chosen_sentence,
max_length=max_seq_len,
padding="max_length",
truncation=True,
return_tensors="pt")
reject_token = tokenizer(reject_sentence,
max_length=max_seq_len,
padding="max_length",
truncation=True,
return_tensors="pt")
chosen_token["input_ids"] = chosen_token["input_ids"]
chosen_token["attention_mask"] = chosen_token["attention_mask"]
chosen_dataset.append(chosen_token)
reject_token["input_ids"] = reject_token["input_ids"]
reject_token["attention_mask"] = reject_token["attention_mask"]
reject_dataset.append(reject_token)
elif train_phase == 3:
for i, tmp_data in enumerate(current_dataset):
# tokenize the text
prompt = raw_dataset.get_prompt(tmp_data)
if prompt is not None:
prompt_token = tokenizer(prompt, return_tensors="pt")
prompt_token["input_ids"] = prompt_token["input_ids"]
prompt_token["attention_mask"] = prompt_token["attention_mask"]
for key_word in ["input_ids", "attention_mask"]:
length = prompt_token[key_word].size()[-1]
if length > max_seq_len:
y = prompt_token[key_word].squeeze(0)[length -
(max_seq_len -
1):].flip(0)
else:
y = prompt_token[key_word].squeeze(0).flip(0)
prompt_token[key_word] = y
prompt_dataset.append(prompt_token)2)监督数据微调大模型
代码在training/step1_supervised_finetuning文件夹下,文件夹下的traning_scripts提供了单GPU,多GPU,多机器的训练脚本。监督数据微调没有什么值得说的,和我们常用的微调方式一致,可以选择一个开源的模型,比如facebook/opt-1.3b,微调时可以选择lora和offload微调。
3)训练奖励模型
代码在training/step2_reward_model_finetuning文件夹下,奖励模型可以选择一个较小的模型,如opt-350M,在chosen和rejected这种样本对上训练。奖励模型的代码实现在training/utils/model/reward_model.py中。reward model的输出类似于回归任务,将大模型的输出,然后经过N ✖️ 1 的线性层,得到一个batch size ✖️ seq len ✖️ 1的输出。在训练过程中,使用到的loss是二元交叉熵,确保每个prompt 的 chosen分数都是要大于rejected。
loss += -torch.log(torch.sigmoid(c_truncated_reward - r_truncated_reward)).mean()
上面的代码中c_truncated_reward 和 r_truncated_reward 即给定一个prompt,对应的chosen和rejected获得的分数,而且是chosen 和 rejected所有token的分数差值。注意在这里因为chosen和rejected的长度不一致,而且还有padding的部分,所以c_truncated_reward和r_truncated_reward要做阶段,主要是截取chosen_id和rejected_id不等的部分出来,去除共同padding的部分。
4)训练强化学习模型
代码在training/step3_rlhf_finetuning文件夹下,在第三步我们需要两个模型,一个是第一步训练好的SFT模型,另一个是第二步训练好的reward模型。接下来看下强化学习模型训练的步骤:
1)初始化rlhf engine,在代码training/step3_rlhf_finetuning/main.py中
rlhf_engine = DeepSpeedRLHFEngine(
actor_model_name_or_path=args.actor_model_name_or_path,
critic_model_name_or_path=args.critic_model_name_or_path,
tokenizer=tokenizer,
num_total_iters=num_total_iters,
args=args)rlhf_engine中会包含4个模型对象:self.actor: sft模型,可训练,作为策略模型;self.ref: sft模型,不可训练,只做前向推断,用于约束self.actor生成结果的向量分布;self.critic:reward模型,可训练,价值模型,用于对生成的每个动作打分;self.reward:reward 模型,不可训练,用于计算整个序列的奖励值。
2)初始化ppo训练器,在代码training/step3_rlhf_finetuning/main.py中
ppo_trainer = DeepSpeedPPOTrainerUnsupervised if unsupervised_training_enabled else DeepSpeedPPOTrainer
trainer = ppo_trainer(rlhf_engine, args)3)生成PPO的训练样本,在代码training/step3_rlhf_finetuning/main.py中
out = trainer.generate_experience(prompts)
exp_dataset = exp_mini_dataset.add(out)4)训练PPO模型,在代码training/step3_rlhf_finetuning/main.py中
for ppo_ep in range(args.ppo_epochs):
for i, (exp_data, unsup_data) in enumerate(
zip(exp_dataset, unsup_dataset)):
actor_loss, critic_loss = trainer.train_rlhf(exp_data) 回过头来再看rlhf_engine和ppo_trainer的实现逻辑。
rlhf_engine的实现在training/step3_rlhf_finetuning/rlhf_engine.py中,主要是初始化了几个模型对象
self.actor = self._init_actor(
actor_model_name_or_path=actor_model_name_or_path)
self.ref = self._init_ref(
actor_model_name_or_path=actor_model_name_or_path)
self.actor_ema = None
if self.args.enable_ema:
self.actor_ema = self._init_ema(
actor_model_name_or_path=actor_model_name_or_path)
self.critic = self._init_critic(
critic_model_name_or_path=critic_model_name_or_path)
self.reward = self._init_reward(
critic_model_name_or_path=critic_model_name_or_path)ppo_trainer的具体代码在training/step3_rlhf_finetuning/ppo_trainer.py中,由于对强化学习不是很熟悉,只能简单地描述下整个逻辑:
1)输入prompt,使用self.actor生成对应的answer,并拼接成一个完整的seq,这其实是一个采样的过程,类似于强化学习中生成一条完整的状态-动作序列。动作即生成的token,状态时生成token的前缀输入。
with torch.no_grad():
seq = self.actor_model.module.generate(prompts,
max_length=max_min_length,
min_length=max_min_length)2)基于当前 T 时刻的网络参数,生成完整的状态-动作序列,奖励值。
with torch.no_grad():
output = self.actor_model(seq, attention_mask=attention_mask)
output_ref = self.ref_model(seq, attention_mask=attention_mask)
reward_score = self.reward_model.forward_value(
seq, attention_mask,
prompt_length=self.prompt_length)['chosen_end_scores'].detach(
)
values = self.critic_model.forward_value(
seq, attention_mask, return_value_only=True).detach()[:, :-1]
logits = output.logits
logits_ref = output_ref.logits
return {
'prompts': prompts,
'logprobs': gather_log_probs(logits[:, :-1, :], seq[:, 1:]),
'ref_logprobs': gather_log_probs(logits_ref[:, :-1, :], seq[:,
1:]),
'value': values,
'rewards': reward_score,
'input_ids': seq,
"attention_mask": attention_mask
}3)训练PPO模型,所有的核心训练逻辑都在这里。
def train_rlhf(self, inputs):
# train the rlhf mode here
### process the old outputs
prompts = inputs['prompts']
log_probs = inputs['logprobs']
ref_log_probs = inputs['ref_logprobs']
reward_score = inputs['rewards']
values = inputs['value']
attention_mask = inputs['attention_mask']
seq = inputs['input_ids']
start = prompts.size()[-1] - 1
action_mask = attention_mask[:, 1:]
old_values = values
with torch.no_grad():
# 1、计算生成的每个token的奖励值
old_rewards = self.compute_rewards(prompts, log_probs,
ref_log_probs, reward_score,
action_mask)
# 2、计算价值,价值不等于奖励值,价值是考虑到未来的,奖励值只考虑当下
advantages, returns = self.get_advantages_and_returns(
old_values, old_rewards, start)
### process the new outputs
batch = {'input_ids': seq, "attention_mask": attention_mask}
actor_prob = self.actor_model(**batch, use_cache=False).logits
actor_log_prob = gather_log_probs(actor_prob[:, :-1, :], seq[:, 1:])
# 3、计算actor网络的loss,并更新网络参数
actor_loss = self.actor_loss_fn(actor_log_prob[:, start:],
log_probs[:, start:], advantages,
action_mask[:, start:])
self.actor_model.backward(actor_loss)
self.actor_model.step()
value = self.critic_model.forward_value(**batch,
return_value_only=True,
use_cache=False)[:, :-1]
# 4、计算critic网络的loss,并更新网络参数
critic_loss = self.critic_loss_fn(value[:, start:], old_values[:,
start:],
returns, action_mask[:, start:])
self.critic_model.backward(critic_loss)
self.critic_model.step()
return actor_loss, critic_loss因为这一部分的内容比较多,我们再细分来描述:
3.1)计算每个时刻(沿着序列的方向定义时刻)的奖励值,即给定前缀输入,生成当前token时对应的奖励值,奖励值由两部分组成,一是完整的序列奖励,由self.reward输出的,二是self.actor和self.ref输出的token向量的KL散度值。具体的代码:
def compute_rewards(self, prompts, log_probs, ref_log_probs, reward_score,
action_mask):
kl_divergence_estimate = -self.kl_ctl * (log_probs - ref_log_probs)
rewards = kl_divergence_estimate
start = prompts.shape[1] - 1
ends = start + action_mask[:, start:].sum(1)
reward_clip = torch.clamp(reward_score, -self.clip_reward_value,
self.clip_reward_value)
batch_size = log_probs.shape[0]
for j in range(batch_size):
rewards[j, start:ends[j]][-1] += reward_clip[j]
return rewards3.2)计算每个时刻的价值,actor的价值采用TD误差。在这里要指明价值不等于奖励值,奖励值只取决于当前时刻的状态和动作,而价值是考虑到了未来的情况的。所以价值的计算如下:核心是下面的delta的计算,除了考虑到当前的时刻的奖励值,还考虑到了未来时刻的输出的奖励值nextvalues(只不过这里的奖励值是由critic网络直接输出的每个token对应的分数)。下面的函数输出了两个值,一个是advantages,用于更新actor。二是returns,这是我们的目标Q值,用于后面更新critic。
def get_advantages_and_returns(self, values, rewards, start):
# Adopted from https://github.com/CarperAI/trlx/blob/main/trlx/models/modeling_ppo.py#L134
lastgaelam = 0
advantages_reversed = []
length = rewards.size()[-1]
for t in reversed(range(start, length)):
nextvalues = values[:, t + 1] if t < length - 1 else 0.0
delta = rewards[:, t] + self.gamma * nextvalues - values[:, t] # TD误差
lastgaelam = delta + self.gamma * self.lam * lastgaelam
advantages_reversed.append(lastgaelam)
advantages = torch.stack(advantages_reversed[::-1], dim=1)
returns = advantages + values[:, start:] # Q值
return advantages.detach(), returns3.3)计算actor的loss,其实在这里有一个目标actor和当前actor的概念,下面函数中old_logprobs是由目标actor输出的,logprobs是由当前actor输出的,ppo算法中actor的loss是使用当前actor输出的概率和目标actor输出的概率的比值来约束的,转换成log后就是logprobs - old_logprobs。
def actor_loss_fn(self, logprobs, old_logprobs, advantages, mask):
## policy gradient loss
log_ratio = (logprobs - old_logprobs) * mask # 当前策略和上一策略的比值
ratio = torch.exp(log_ratio)
pg_loss1 = -advantages * ratio
pg_loss2 = -advantages * torch.clamp(ratio, 1.0 - self.cliprange,
1.0 + self.cliprange)
pg_loss = torch.sum(torch.max(pg_loss1, pg_loss2) * mask) / mask.sum()
return pg_loss3.4)计算critic的loss,在这里一样有一个目标critic和当前cirtic的概念,用当前cirtic输出的value减去目标Q值(也就是上面计算得到的returns)再求平方,所以是使用了当前critic的Q值和目标critic的Q值的均方误差作为critic的loss。
def critic_loss_fn(self, values, old_values, returns, mask):
## value loss
values_clipped = torch.clamp(
values,
old_values - self.cliprange_value,
old_values + self.cliprange_value,
)
vf_loss1 = (values - returns)**2 # 当前critic和目标critic的Q值的均方误差
vf_loss2 = (values_clipped - returns)**2
vf_loss = 0.5 * torch.sum(
torch.max(vf_loss1, vf_loss2) * mask) / mask.sum()
return vf_loss在上面3.3)和3.4)提到了目标actor和目标critic,但在代码里并没有创建这两个变量,这里其实和PPO的训练方式有关,首先是利用T时刻的actor和critic生成状态-动作序列和价值,奖励等并存储下来。在训练PPO时会使用生成的状态-动作去重新输出价值、奖励等值并更新actor和critic参数,所以并没有显示构造目标actor和目标critic,但是存储了它们产生的结果。存储的这部分数据会不断地更新,保证目标actor和critic和当前的actor和critic的参数不会有太大的差别,更新的逻辑在training/utils/data/data_utils.py中的MiniDataset类中。
所以强化学习模型的训练流程就是两步,一是先生成目标actor和critic的值作为对比的数据,二是训练actor和critic模型,将代码简化,其实就是training/step3_rlhf_finetuning/main.py中下面的代码段:
for epoch in range(args.num_train_epochs):
....
for step, (batch_prompt, batch_unsupervised) in enumerate(
zip(prompt_train_dataloader, unsupervised_train_dataloader)):
...
# 生成训练强化学习模型的数据
out = trainer.generate_experience(prompts)
exp_dataset = exp_mini_dataset.add(out)
if exp_dataset is not None:
...
# 训练强化学习模型
for ppo_ep in range(args.ppo_epochs):
for i, (exp_data, unsup_data) in enumerate(
zip(exp_dataset, unsup_dataset)):
actor_loss, critic_loss = trainer.train_rlhf(exp_data)
actor_loss_sum += actor_loss.item()
critic_loss_sum += critic_loss.item()
average_reward += exp_data["rewards"].mean()