- 📢博客主页:盾山狂热粉的博客_CSDN博客-C、C++语言,机器视觉领域博主
- 📢努力努力再努力嗷~~~✨
💡大纲
⭕如何将数据永久的存放到硬盘上
👉不要打开文件,然后直接关闭文件,会导致截断
一、如何操作文件
f = open("FishC.txt","w")
f.write("I Love Python\n") # 返回字符串长度
f.writelines(["I Love FishC\n","I Love my wife\n"])
f.close()
f = open("FishC.txt","r+") # 以追加的模式,可读可写
f.readable() # true
f.writable() # True
for each in f:
print(each)
f.read() # 读取是空字符串,因为文件指针在末尾EOF
f.tell()
f.seek(0) # 将文件指针移到开头
f.readline()
f.read()
f.write("I Love Wifi")
f.flush() # 不用关闭文档就能读取
f.truncate(29) # 截取到29
f.close()
二、pathlib --- 面向对象的文件系统路径
💡pathlib 是 Python3.4 之后新添加的模块,它可以让文件和路径操作变得快捷方便,完美代替 os.path 模块。
(一)模块概述
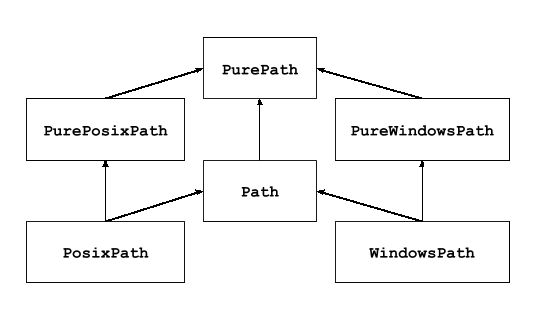
💡提供了用于表示文件系统路径的类
- 路径类
- 提供纯计算操作而不涉及 I/O 的 PurePath
- 从纯路径继承而来但提供 I/O 操作的 Path
(二)基本用法
1、导入模块
from pathlib import Path2、访问当前目录的路径:Path.cwd()
Path.cwd() # WindowsPath('c:/Users/13601/Desktop/My_Paper/Paper_Small')3、创建一个文件对象并添加文件名
p = Path('c:/Users/13601/Desktop/My_Paper/Paper_Small')
q = p / "FishC.txt"4、判断文件对象是不是文件夹/文件:文件对象.is_dir()/文件对象.is_file()
p.is_dir() # True
q.is_file() # True5、判断路径是否存在:文件对象.exists()
p.exists() # True
Path("c:/404").exists() # False6、获取目录路径的最后一部分:文件对象.name
p.name # 'Paper_Small'
q.name # 'FishC.txt'7、获取文件名:文件对象.stem
q.stem # 'FishC'8、获取文件后缀:文件对象.suffix
q.suffix # '.txt'9、获取父级目录 :文件对象.parent
p.parent # WindowsPath('c:/Users/13601/Desktop/My_Paper')
q.parent10、获取逻辑祖先路径构成的序列
ps = p.parents
for each in ps:
print(each)
'''
c:\Users\13601\Desktop\My_Paper
c:\Users\13601\Desktop
c:\Users\13601
c:\Users
c:\
'''
ps[0] # WindowsPath('c:/Users/13601/Desktop/My_Paper')11、将路径的各个组件拆分为元组:文件对象.parts
p.parts # ('c:\\', 'Users', '13601', 'Desktop', 'My_Paper', 'Paper_Small')12、查询文件或文件夹的信息:文件对象.stat()
p.stat()⭕相对路径与绝对路径
13、.表示当前目录,..表示上级目录
Path("./VMD_Source") # WindowsPath('VMD_Source')
Path("../VMD— python.txt") # WindowsPath('../VMD— python.txt') 上一级目录中的14、将相对路径转换为绝对路径:文件对象.resolve()
Path("./VMD_Source").resolve()
# WindowsPath('C:/Users/13601/Desktop/My_Paper/Paper_Small/VMD_Source')15、获取当前路径下所有子文件和子文件夹:文件对象.iterdir()
p.iterdir()
for each in p.iterdir():
print(each) # 获得所有的子文件/文件夹💡获取所有的子文件夹,并组成一个列表
[x for x in p.iterdir() if x.is_dir()]
'''
[WindowsPath('c:/Users/13601/Desktop/My_Paper/Paper_Small/.vscode'),
WindowsPath('c:/Users/13601/Desktop/My_Paper/Paper_Small/All_Paper_Read'),
WindowsPath('c:/Users/13601/Desktop/My_Paper/Paper_Small/pyswarm'),
WindowsPath('c:/Users/13601/Desktop/My_Paper/Paper_Small/VMD_Source'),
WindowsPath('c:/Users/13601/Desktop/My_Paper/Paper_Small/__pycache__'),
WindowsPath('c:/Users/13601/Desktop/My_Paper/Paper_Small/论文综述')]
'''16、创建文件夹/文件
💡 在一个文件对象p后面加 / 和想要创建的文件名得到文件对象n,然后调用n.mkdir()进行创建,得到的新文件夹就是在当前目录路径下的
👉如果想要创建的文件夹已经存在,再创建的话会报错,可以设置参数exist_ok=True
👉如果想要创建的文件夹有多个虚假的父级目录也会报错,可以设置参数parents=True
n = p/"FishC"
n.mkdir()
n.mkdir(exist_ok=True) # 重复创建不会报错
n = p/"FishC/A/B/C"
n.mkdir(parents=True,exist_ok=True)
# "C:\Users\13601\Desktop\My_Paper\Paper_Small\FishC\A\B\C" 直接创建虚假的父级目录n = n / "FishC.txt"
f = n.open('w')
f.write("I Love FishC.")
f.close()17、删除文件/文件夹:文件对象.unlink()/文件对象.parent.rmdir()
n.unlink() # 删除待删除文件夹里面的文件
n.parent.rmdir() # 删除n的父级文件夹18、查找文件:文件对象.glob(查找内容)
p = Path('.') # 访问当前目录
p.glob("*.txt") # 查找后缀为.txt的文件
list(p.glob("*.txt")) # [WindowsPath('FishC.txt')]
list(p.glob("*/*.pdf")) # 当前路径下的下一级目录中所有包含.pdf后缀的文件
list(p.glob("**/*.pdf")) # 查找当前目录以及该目录下的所有子目录三、with语句和上下文管理器
(一)文件的打开
💡首先需要知道文件打开的通用格式是什么
with open("文件路径", "文件打开模式", encoding = "操作文件的字符编码") as f:
"对文件进行相应的读写操作"👉文件路径:相对路径、绝对路径
👉文件打开模式:只读、只写、追加、可读可写、二进制模式、文本模式等(后续会详细说明)
👉字符编码:utf-8(万国码)、gbk(中文编码)
👉文件对应的读写操作就涉及到相关函数了(后续详细说)
👉f 是创建的文件对象吧(我理解为文件指针,指向打开的文件)
⚠️这是使用with块的原因是,with块在执行完毕后,自动对文件进行关闭操作
1、文件路径
👉如果文件与程序不在同一文件夹中,一般需要用到绝对路径来进行访问
👉程序与文件在同一文件夹,可简化成文件名,使用相对路径
2、打开模式
⚠️打开模式可以缺省,默认为只读模式
"r" :只读模式,如文件不存在,报错
"w":覆盖写模式,如文件不存在,则创建;如文件存在,则完全覆盖原文件
"x":创建写模式,如文件不存在,则创建;如文件存在,报错
"a":追加写模式,如文件不存在,则创建;如文件存在,则在原文件后追加内容
"b":二进制文件模式,不能单独使用,需要配合使用如"rb","wb","ab",该模式不需指定encoding
"t":文本文件模式,默认值,需配合使用 如"rt","wt","at",一般省略,简写成如"r","w","a"
"+":与"r","w","x","a"配合使用,设置为可读可写
💡二进制文件
# 图片:二进制文件,不需要字符编码
with open("test.jpg", "rb") as f:
print(len(f.readlines())) # 将每行列为列表计算长度3、字符编码
👉万国码(utf-8):包含全世界所有国家需要用到的字符
👉中文编码(gbk):解决中文编码问题
⚠️在windows系统下,如果缺省,则默认为gbk,并且不建议缺省encoding
⚠️解码模式要匹配

(二)文件的读取
1、读取整个内容---f.read() 读取数据的长度(单位:字节)
with open("测试文件_utf.txt", "r", encoding="utf-8") as f:
text = f.read()
print(text)2、逐行进行读取---f.readline()
with open("测试文件_gbk.txt", "r", encoding="gbk") as f:
for i in range(3): # 读取前三行
text = f.readline() # 每次只读取一行
print(text) # 这种方式会有两次换行,原文一次(如果文件中有换行的话),print自带一次
print(text, end="") # 保留原文的换行,使print()的换行不起作用3、读入所有行,以每行为元素形成一个列表---f.readlines()
with open("测试文件_gbk.txt", "r", encoding="gbk") as f:
text = f.readlines() # 注意每行末尾有换行符
print(text, end="") # 使print()的换行不起作用
'''
['临江仙·滚滚长江东逝水\n', '滚滚长江东逝水,浪花淘尽英雄。\n', '是非成败转头空。\n', '\n', '青山依旧在,几度夕阳红。\n', '白发渔樵江渚上,惯看秋月春风。\n', '一壶浊酒喜相逢。\n', '古今多少事,都付笑谈中。\n']
''' ⭕总结
- 文件比较大时,read()和readlines()占用内存过大,不建议使用
- readline用起来不是很方便
- 可以通过从迭代对象中取值的方式读取
with open("测试文件_gbk.txt", "r", encoding="gbk") as f:
for text in f: # f本身就是一个可迭代对象,每次迭代读取一行内容
print(text,end="") (三)文件的写入
1、向文件写入一个字符串或字节流(二进制)---f.write()
with open("测试文件.txt", "w", encoding="utf-8") as f:
f.write("啦啦啦啦啦啦\n") # 如需换行,末尾加换行符\n⚠️如果文件存在,新写入内容会覆盖掉原内容,一定要注意!!!
⚠️文件不存在则立刻创建一个
👉以追加"a" 的模式写入,在原文的末尾开始写入
with open("测试文件.txt", "a", encoding="utf-8") as f:
f.write("姑娘你别哭泣\n")
f.write("我俩还在一起\n")
f.write("今天的欢乐\n")
f.write("将是明天创痛的回忆\n")
2、将一个元素为字符串的列表整体写入文件---f.writelines()
⚠️与readlines()相对应
ls = ["春天刮着风", "秋天下着雨", "春风秋雨多少海誓山盟随风远去"] # 需要换行就加\n
with open("测试文件.txt", "w", encoding="utf-8") as f:
f.writelines(ls)
# 春天刮着风秋天下着雨春风秋雨多少海誓山盟随风远去(四)可读可写
💡对于文件的创建与否,仍然以未加+的打开模式为准
1、"r+"
如果文件名不存在,则报错
指针在开始,需要要把指针移到末尾才能开始写,否则会覆盖前面内容
⭕ 将指针移到末尾的方法
👉第一种:将文件内容全部读取一遍,这猴子那个方法很笨,不建议
for line in f:
print(line) # 全部读一遍后,指针到达结尾👉第二种:可以将指针移到末尾f.seek(偏移字节数,位置(0:开始;1:当前位置;2:结尾))
with open("测试文件.txt", "r+", encoding="gbk") as f:
f.seek(0,2)
text = ["啦啦啦啦啦,\n", "噜噜噜噜。\n"]
f.writelines(text)2、"w+"
若文件不存在,则创建
若文件存在,会立刻清空原内容!!!
with open("测试文件.txt", "w+", encoding="gbk") as f:
pass # 文件存在,清空原内容
with open("测试文件.txt", "w+", encoding="gbk") as f:
text = ["啦啦啦啦啦,\n", "噜噜噜噜。\n"]
f.writelines(text) # 写入新内容,指针在最后
f.seek(0,0) # 指针移到开始
print(f.read()) # 读取内容3、"a+"
若文件不存在,则创建
指针在末尾,添加新内容,不会清空原内容
with open("测试文件.txt", "a+", encoding="gbk") as f:
f.seek(0,0) # 因为是追加的形式,所以要把指针移到开始进行读取
print(f.read()) # 读取内容
with open("测试文件.txt", "a+", encoding="gbk") as f:
text = ["啦啦啦啦啦,\n", "噜噜噜噜。\n"]
f.writelines(text) # 指针在最后,追加新内容
f.seek(0,0) # 指针移到开始
print(f.read()) # 读取内容
(五)数据的存储与读取(了解即可)
💡两种数据存储结构csv和json
1、csv格式
👉由逗号将数据分开的字符序列,可以由excel打开
# 读取
with open("成绩单.csv", "r", encoding="gbk") as f:
ls = []
for line in f: # 逐行读取
ls.append(line.strip("\n").split(",")) # 去掉每行的换行符,然后用“,”进行分割
for res in ls:
print(res)
'''
['编号', '数学成绩', '语文成绩']
['1', '100', '98']
['2', '96', '99']
['3', '97', '95']
'''
# 写入
ls = [['编号', '数学成绩', '语文成绩'], ['1', '100', '98'], ['2', '96', '99'], ['3', '97', '95']]
with open("score.csv", "w", encoding="gbk") as f:
for row in ls:
f.write(",".join(row)+"\n") # 用逗号组合成字符串形式,末尾加换行符2、json格式
👉常用来存储字典类型
import json
scores = {"Petter":{"math":96 , "physics": 98},
"Paul":{"math":92 , "physics": 99},
"Mary":{"math":98 , "physics": 97}}
# 写入---dump()
with open("score.json", "w", encoding="utf-8") as f: # 写入整个对象
# indent 表示字符串换行+缩进 ensure_ascii=False 显示中文
json.dump(scores, f, indent=4, ensure_ascii=False)
# 读取---load()
with open("score.json", "r", encoding="utf-8") as f:
scores = json.load(f) # 加载整个对象
for k,v in scores.items():
print(k,v)
'''
Petter {'math': 96, 'physics': 98}
Paul {'math': 92, 'physics': 99}
Mary {'math': 98, 'physics': 97}
'''(六)将python对象序列化:pickle
💡将python对象转换为二进制字节流
import pickle
x,y,z = 1,2,3
s = "FishC"
l = ["小甲鱼",520,3.14]
d = {"one":1,"two":2}
with open("data.pkl",'wb') as f:
pickle.dump((x,y,z,s,l,d),f)import pickle
with open("data.pkl",'rb') as f:
x,y,z,s,l,d = pickle.load(f)
print(x,y,z,s,l,d,sep='\n')📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!