作者:Shane Connelly
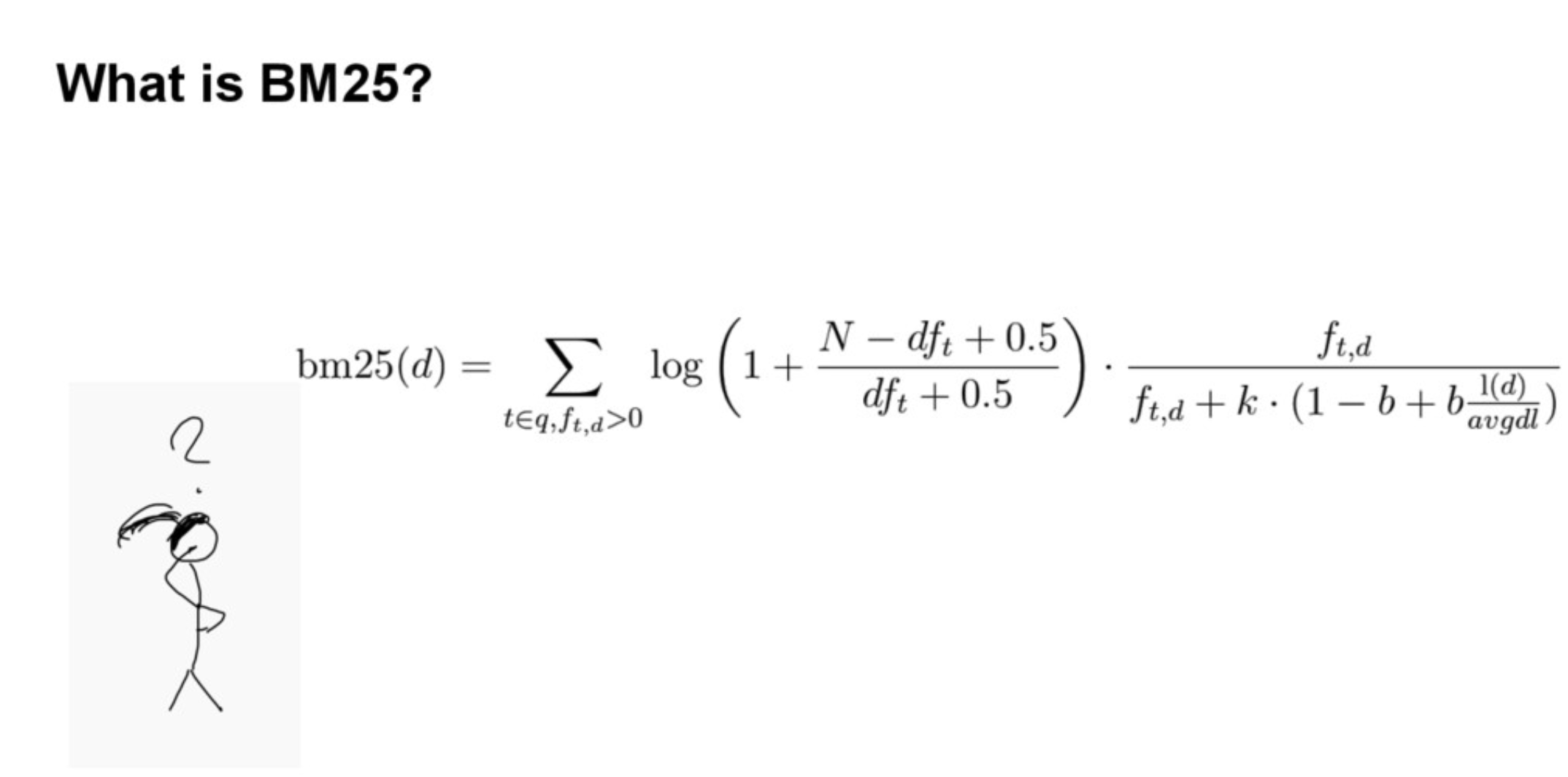
背景
在 Elasticsearch 5.0 中,我们切换到 Okapi BM25 作为我们的默认相似度算法,这是用于对与查询相关的结果进行评分的算法。 在本博客中,我不会过多地介绍 BM25 与替代措施,但如果你想了解 BM25 的理论依据,你可以继续观看 Elastic{ON} 2016 的 BM25 Demystified 演示文稿。相反,我 我将为你介绍(并希望揭开神秘面纱)BM25 的实际用法,包括介绍可用的参数以及影响评分的因素。
请记住,此博客主要与那些对文本文档进行评分的人有关。 也就是说,它真正专注于帮助我们的搜索用户。 如果你正在索引日志或指标并返回按某些明确的元数据/数字顺序(如时间戳)排序的结果,则此博客可能主要用于满足好奇心。
了解分片如何影响评分
因为我希望你在家里也能跟进,所以我们需要解决的第一件事就是了解超过 1 个分片如何影响评分,因为默认情况下 Elasticsearch 每个索引使用 5 个主分片(请注意这个在最新的版本里有变化)。 让我们从创建一个名为 people 的索引开始。 我在此处提供的设置将是默认设置(因此无需定义),但为了演示目的,我无论如何都会这样做。 我将在这里使用我的名字的变体(“Shane Connelly”),但如果你在家跟随,请随时将其替换为你选择的名字。
PUT people
{
"settings": {
"number_of_shards": 5,
"index": {
"similarity": {
"default": {
"type": "BM25"
}
}
}
}
}现在让我们添加一个文档,然后搜索它。 首先,我们只添加我的名字:
PUT /people/_doc/1
{
"title": "Shane"
}
GET /people/_search?filter_path=**.hits
{
"query": {
"match": {
"title": "Shane"
}
}
}上面搜索的结果为:
{
"hits": {
"hits": [
{
"_index": "people",
"_id": "1",
"_score": 0.2876821,
"_source": {
"title": "Shane"
}
}
]
}
}此时你得到 1 个命中,分数为 0.2876821。 我们稍后会深入探讨这个评分是如何得出的,但让我们先看看当我们添加更多带有我全名不同变体的文档时会发生什么。
PUT /people/_doc/2
{
"title": "Shane C"
}
PUT /people/_doc/3
{
"title": "Shane Connelly"
}
PUT /people/_doc/4
{
"title": "Shane P Connelly"
}现在再次进行相同的搜索:
GET /people/_search?filter_path=**.hits
{
"query": {
"match": {
"title": "Shane"
}
}
}上面搜索的结果为:
{
"hits": {
"hits": [
{
"_index": "people",
"_id": "3",
"_score": 0.2876821,
"_source": {
"title": "Shane Connelly"
}
},
{
"_index": "people",
"_id": "4",
"_score": 0.2876821,
"_source": {
"title": "Shane P Connelly"
}
},
{
"_index": "people",
"_id": "2",
"_score": 0.2876821,
"_source": {
"title": "Shane C"
}
},
{
"_index": "people",
"_id": "1",
"_score": 0.2876821,
"_source": {
"title": "Shane"
}
}
]
}
}此时,你确实应该有 4 个命中,但如果你看分数,你可能会摸不着头脑。 文档 1,2,3,4 的得分均为 0.2876821。我们通过如下的方式来查看各个分片的文档情况:
GET /_cat/shards/people?v上面述命令返回的结果为:
index shard prirep state docs store ip node
people 0 p STARTED 1 4.7kb 127.0.0.1 liuxgm.local
people 0 r UNASSIGNED
people 1 p STARTED 1 4.7kb 127.0.0.1 liuxgm.local
people 1 r UNASSIGNED
people 2 p STARTED 0 247b 127.0.0.1 liuxgm.local
people 2 r UNASSIGNED
people 3 p STARTED 1 4.6kb 127.0.0.1 liuxgm.local
people 3 r UNASSIGNED
people 4 p STARTED 1 4.6kb 127.0.0.1 liuxgm.local
people 4 r UNASSIGNED 从上面显示的结果中,我们可以看出来,每个分片含有一个文档。其中的一个分片没有文档。
我们删除之前的所有文档,并再次写入各个文档:
DELETE people
PUT people
{
"settings": {
"number_of_shards": 5,
"index": {
"similarity": {
"default": {
"type": "BM25"
}
}
}
}
}
PUT /people/_doc/2?routing=1
{
"title": "Shane C"
}
PUT /people/_doc/3
{
"title": "Shane Connelly"
}
PUT /people/_doc/4?routing=1
{
"title": "Shane P Connelly"
}
PUT /people/_doc/1
{
"title": "Shane"
}
在上面,我们有意识地通过 routing 把有些文档写入到同一个分片中。我们运行如下的命令来进行查看:
GET /_cat/shards/people?v上面的命令显示:
index shard prirep state docs store ip node
people 0 p STARTED 1 4.7kb 127.0.0.1 liuxgm.local
people 0 r UNASSIGNED
people 1 p STARTED 0 247b 127.0.0.1 liuxgm.local
people 1 r UNASSIGNED
people 2 p STARTED 0 247b 127.0.0.1 liuxgm.local
people 2 r UNASSIGNED
people 3 p STARTED 0 247b 127.0.0.1 liuxgm.local
people 3 r UNASSIGNED
people 4 p STARTED 3 9.7kb 127.0.0.1 liuxgm.local
people 4 r UNASSIGNED 如上所示,这次,我们看到有一个分片含有 3 个文档,有一个分片含有一个文档。其它的三个分片不含有任何的文档。我们再次进行同样的搜索:
GET /people/_search?filter_path=**.hits
{
"query": {
"match": {
"title": "Shane"
}
}
}上面的命令返回的结果为:
{
"hits": {
"hits": [
{
"_index": "people",
"_id": "3",
"_score": 0.2876821,
"_source": {
"title": "Shane Connelly"
}
},
{
"_index": "people",
"_id": "1",
"_score": 0.16786805,
"_source": {
"title": "Shane"
}
},
{
"_index": "people",
"_id": "2",
"_score": 0.13353139,
"_routing": "1",
"_source": {
"title": "Shane C"
}
},
{
"_index": "people",
"_id": "4",
"_score": 0.110856235,
"_routing": "1",
"_source": {
"title": "Shane P Connelly"
}
}
]
}
}这通常会让新用户望而却步。 文档 2 和 3 非常相似 —— 它们都有 2 个词并且都匹配“ shane”,但是文档 2 的分数要低得多。 您可能会开始假设 “C” 的评分与 “Connelly” 的评分有所不同,但实际上这与文档如何落入分片有关。
提醒一下,Elasticsearch 将文档写入到不同的分片(shards)之中,每个碎片保存数据的一个子集。 这意味着术语 “shane” 的总出现次数在这些不同的分片中是不同的,这就是最终导致这种情况下分数差异的原因。 默认情况下,Elasticsearch 以每个分片为基础计算分数。
人们开始只将几个文档加载到他们的索引中并问 “为什么文档 A 的分数比文档 B 高/低”,有时答案是用户的分片与文档的比例相对较高,因此分数是倾斜的跨越不同的分片。 有几种方法可以跨分片获得更一致的分数:
1)加载到索引中的文档越多,分片的术语统计数据就越规范化。 如果文档足够多,你可能不会注意到术语统计数据的细微差异,因此不会注意到每个分片中的得分。
2)你可以使用较低的分片数来减少术语频率的统计偏差。 例如,如果我们在索引设置中将 number_of_shards 设置为 1,我们就会得到非常不同的分数。 我们会看到文档 1 的得分为 0.13245322,文档 2 和 3 的得分各为 0.105360515,文档 4 的得分为 0.0874691。 拥有不同数量的主分片需要权衡取舍,这在我们的定量集群大小网络研讨会中进行了讨论。
{
"hits": {
"hits": [
{
"_index": "people",
"_id": "1",
"_score": 0.13245323,
"_source": {
"title": "Shane"
}
},
{
"_index": "people",
"_id": "2",
"_score": 0.10536051,
"_source": {
"title": "Shane C"
}
},
{
"_index": "people",
"_id": "3",
"_score": 0.10536051,
"_source": {
"title": "Shane Connelly"
}
},
{
"_index": "people",
"_id": "4",
"_score": 0.0874691,
"_source": {
"title": "Shane P Connelly"
}
}
]
}
}3)你可以将 ?search_type=dfs_query_then_fetch 添加到请求中,它首先收集分布式术语频率(DFS = 分布式频率搜索),然后使用这些计算分数。 事实上,这会返回与只有 1 个分片相同的分数。 看看使用和不使用 “search_type” 参数的结果有何不同:
GET /people/_doc/_search?search_type=dfs_query_then_fetch
{
"query": {
"match": {
"title": "Shane"
}
}
}这与设置 number_of_shards=1 相同。 然后你可能会问,“好吧,如果这会产生更准确的分数,为什么默认情况下不打开它?” 答案是它在处理过程中增加了一次额外的往返以收集所有统计数据,对于某些用例(评分准确性不如速度重要),这种往返是不必要的。 此外,如果分片中有足够的数据,统计数据可以变得非常接近,从而也不需要往返。 如果你有足够的数据, search_type=dfs_query_then_fetch 只有在分片之间的数据继续分布不均时才最需要,就像一些自定义路由的情况一样。
好的,现在我们了解了分片如何影响我们的评分(以及如何针对它进行调整)。 接下来,我们将研究 BM25 算法,看看不同的变量是如何发挥作用的。