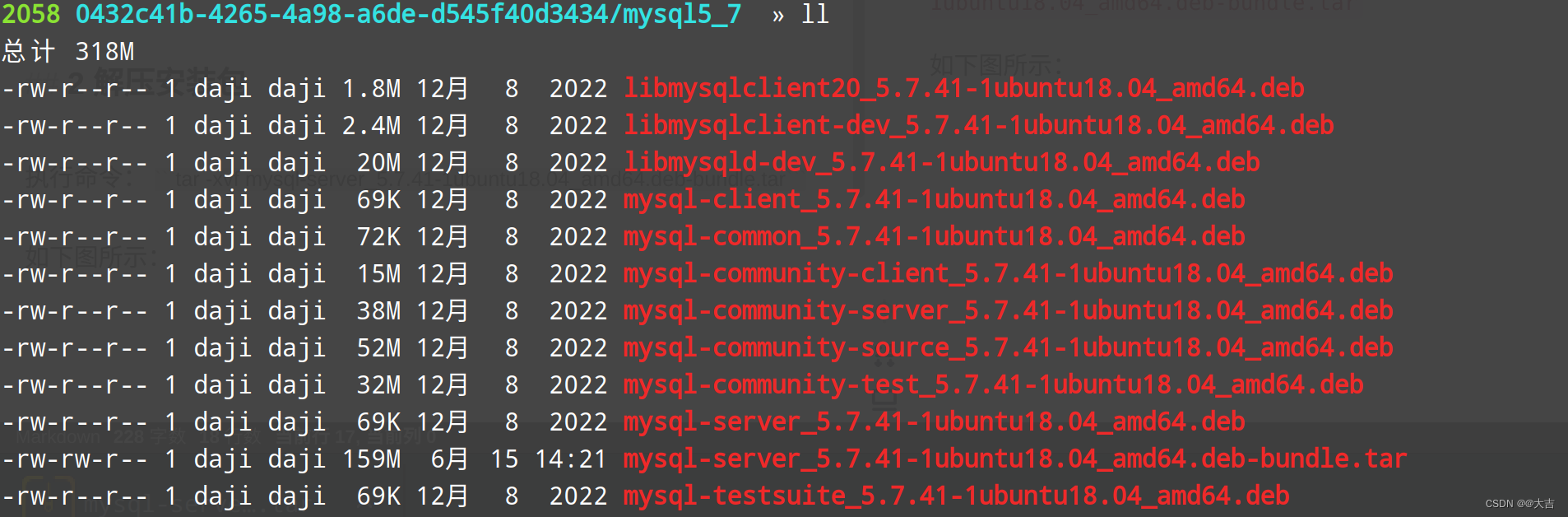
TALL论文笔记
- 0.论文来源
- 1摘要
- 2引言
- 3模型结构
- 3.1视觉编码器
- 3.2句子编码器
- 3.3模态融合
- 3.4时间定位回归网络
- 4训练
- 4.1损失函数
- 4.2采集训练样本
- 5 评估
- 5.1数据集
- 5.2评价指标
- 5.3实验结果
0.论文来源
- 2017 TALL
1摘要
- 问题描述:通过语言来对未修剪视频中动作的时间定位
- 当前的需要:
- 适当的文本和视频表示的设计,以允许动作和语言查询的跨模态匹配
- 能够从有限的尺寸的滑动窗口精确地定位动作所给定的特征。
- 贡献:提出了一种新的跨模态时间回归定位器(CTRL),以联合建模候选剪辑的文本查询和视频剪辑、输出对齐分数和动作边界回归结果。
2引言
传统的时间动作定位:
-
以滑动窗口的方式应用基于光流的方法或卷积神经网络训练的活动分类器。然后将查询映射到一个离散的标签。但是设计这样的标签空间使得对所有的活动进行查询而不丢失细节是比较难的。
-
或者将视觉特征和句子特征嵌入到一个公共空间,然而找不到合适的视觉模型来提取特征,并且实现高精度的预测开始/结束时间。
人们可以在不同的尺度上密集地采样滑动窗口但这样做不仅在计算上很昂贵,而且随着搜索空间的增加,使对齐任务也很难。或者通过学习回归的参数来调整时间边界,但这种方式由于活动具有时空体积,这可能会导致更多的背景噪声过去没有实现。
于是作者提出了 Cross-modal Temporal Regression Localizer (CTRL) 模型
具体贡献如下:
- 提出了一种新的通过自然语言(TALL)查询的时间活动定位问题
- 引入了一种有效的跨模态时间回归定位器(CTRL),它通过联合建模语言查询和视频剪辑来估计对齐分数和时间动作边界。
3模型结构
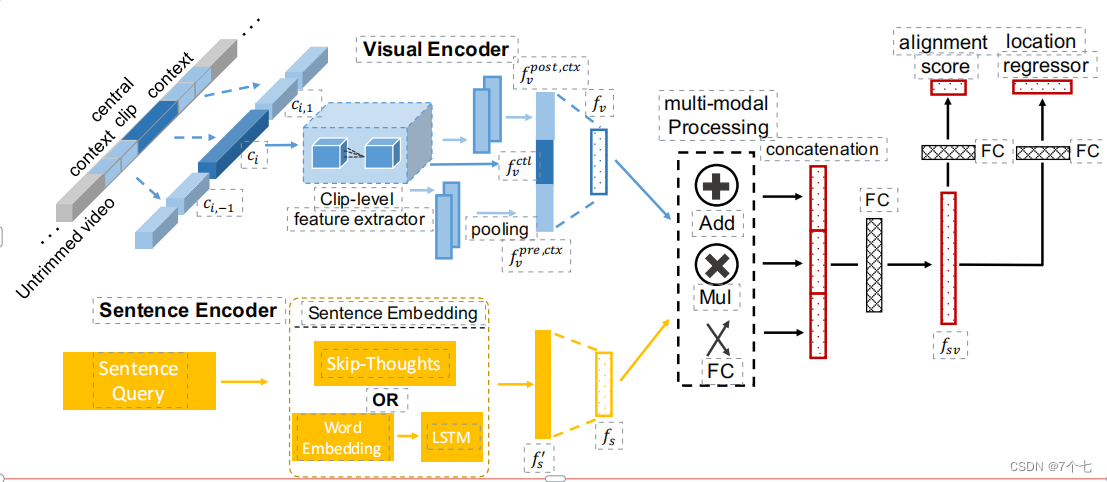
3.1视觉编码器
通过时间滑动窗口生成一组视频剪辑,将剪辑个上下文映射到一个特征向量。Ev用来提取剪辑级特征向量,其输入为nf帧,输出为维数为dv的向量。从每个剪辑(中央剪辑和上下文剪辑)中均匀地采样nf帧。对于上下文剪辑,我们使用池化层来计算预上下文特性:
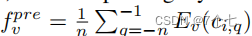
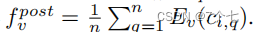
三者合并映射
3.2句子编码器
这篇文章是2017年发的,这里是用的2种方法编码
- LSTM
- Skip-thought
3.3模态融合
如模型图所示,用公式来说的话就是
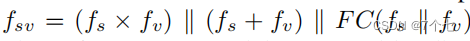
3.4时间定位回归网络
Fsv为输入,并有2个输出:
- alignment score
- 剪辑位置和回归偏移,设计了两种位置偏移表示:
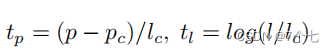
tc和tl分别是参数化的中心点偏移和长度偏移 ,p和l分别表示剪辑的中心坐标和剪辑的长度,变量p、pc用于预测剪辑和测试剪辑,l、lc也是一样。
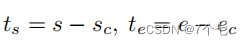
s和e分别表示剪辑的开始坐标和结束坐标
4训练
4.1损失函数
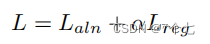
Laln用于视觉-语义对齐,Lreg用于剪辑位置回归,α是一个超参数,它控制着两个任务损失之间的平衡。对齐丢失鼓励对齐的剪辑句子对有正分数,而不对齐的句子对有负分数。
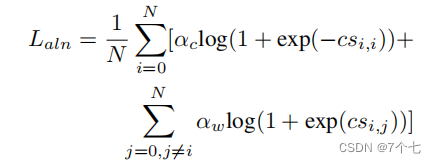
N为批处理大小,CSi,j为句子sj和视频剪辑ci之间的对齐得分,αc和αw是控制正(对齐)和负(不对齐)的剪辑句子对之间的权重的超参数。
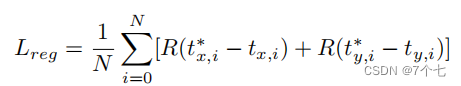
x和y表示p和l表示参数化偏移量,或s和e表示非参数化偏移量。R (t)为Smoth L1函数
4.2采集训练样本
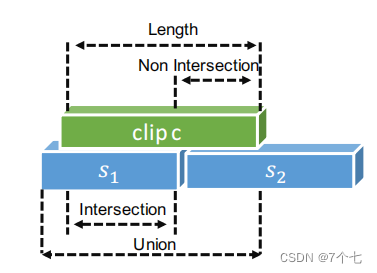
首先采用滑动的窗口对视频片段进行滑动,滑动窗口的大小分为[64,128,256,512]帧,测试的时候是128帧。每个训练样本都包含一个句子描述(sh,τh,τeh)和一个视频剪辑(ch、ts h、te h)正例的样本需要满足三个条件:1.视频片段与句子重叠的部分大于并集长度的50%。2.非重叠部分小于视频片段长的20%。3.一个滑动窗口只能描述一个句子。
5 评估
5.1数据集
TACoS
Charades-STA,这个是作者自己改进的数据集
5.2评价指标
R@n,IoU=m
5.3实验结果
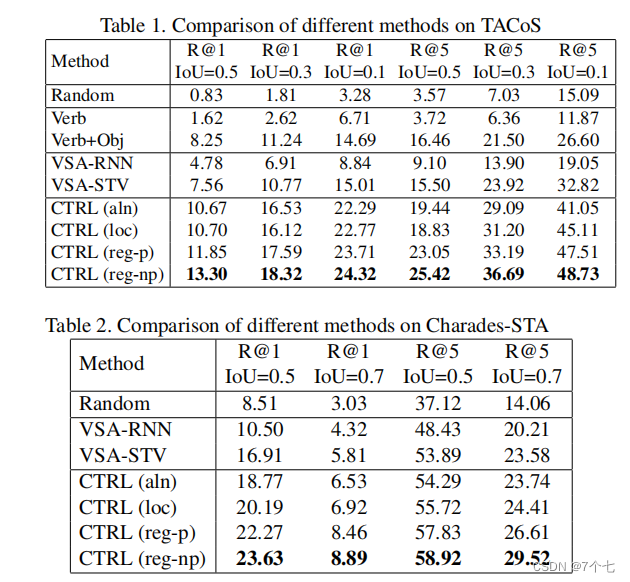
CTRL(aln):我们不使用回归,只用对齐损失Laln来训练CTRL。
CTRL(reg-p):用对齐损失Laln和参数化回归损失−训练CTRL
CTRL(reg-np):考虑上下文信息,CTRL用Laln对齐损失和非参数化回归损失进行训练。
CTRL(loc): 参考SCNN提出使用重叠损失来提高活动定位性能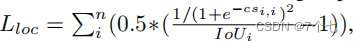
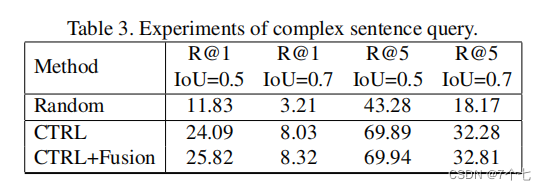
“CTRL”意味着我们只是简单地将整个复杂的句子输入到CTRL模型中。“CTRL+Fusion”是指我们将一个复杂查询中的每个句子分别输入到CTRL中,然后进行后期融合。