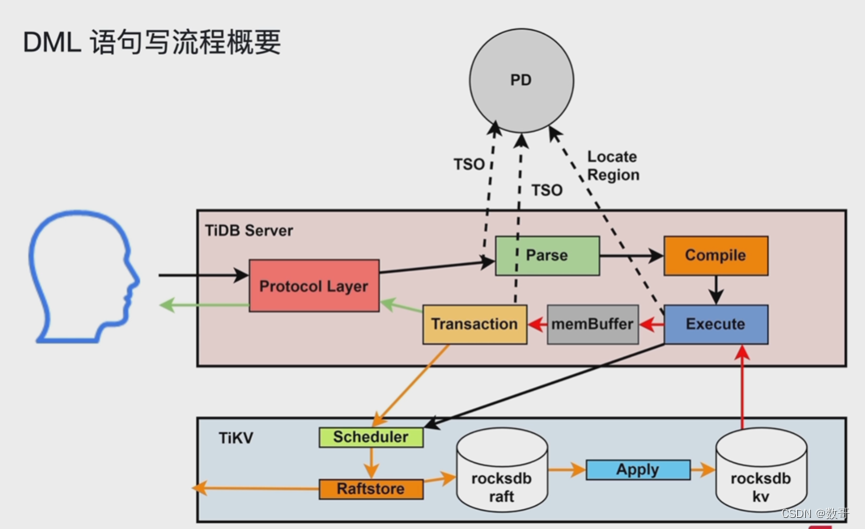
SQL 执行流程
- 读取的执行
- 写入的执行
- DDL的执行
- SQL运算
- SQL解析和编译
- SQL 层架构
- SQL 运算
- 分布式 SQL 运算
- SQL 层架构
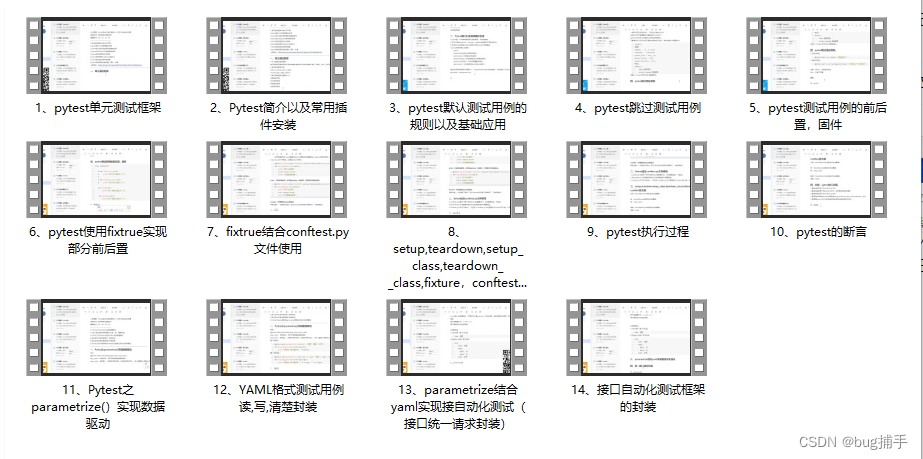
读取的执行
-
元数据的读取
执行器从information_schema当总获取表的元数据信息(table meta),元数据的信息从内存中读取就可以了,因为已经缓存到了information schema。 -
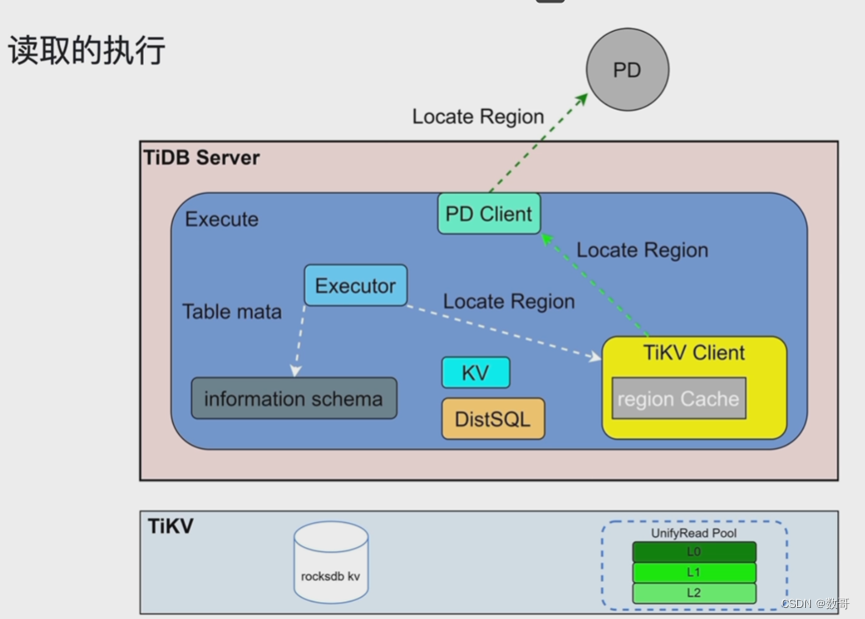
DistSQL
DistSQL:除了点查的语句,例如对多表(t1 t2)的关联查询,转成单表查询(select * from t1 where xx ) (select * from t2 where xx) 再做处理, 将简单SQL 下发到TiKV 。相当于将TikV 和复杂的SQL做个解耦合。 -
UnifyRead Pool
TiKV接收到这些SQL语句后,会首先构造快照对象(某个时间点的内容)。
这些简单SQL语句会都进入到UnifyRead Pool线程池。 (按优先级执行这些SQL) -
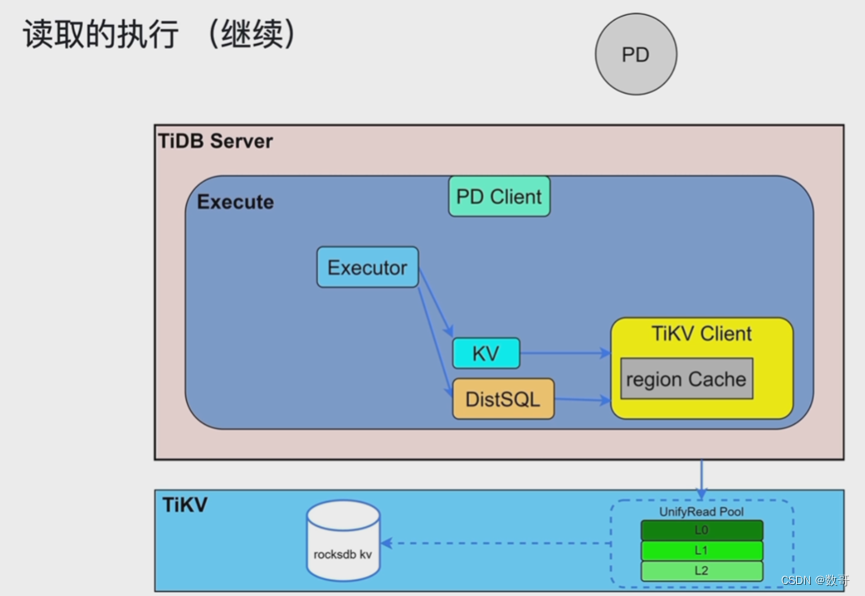
Rocksdb KV读取数据
然后按层次到Rocksdb kv数据读取。
注意一点: 这个region可能在不同的tikv上,所以可以并行查询,这就是为什么叫DistSQL

TiKV有算子下推的功能,把一些操作下推到TiKV中,执行计划当中可以看到是叫做cop task 。
当然有些操作,例如多表关联的数据汇总操作 还是在TiDB Server上 执行计划中可以看到是root task。
写入的执行
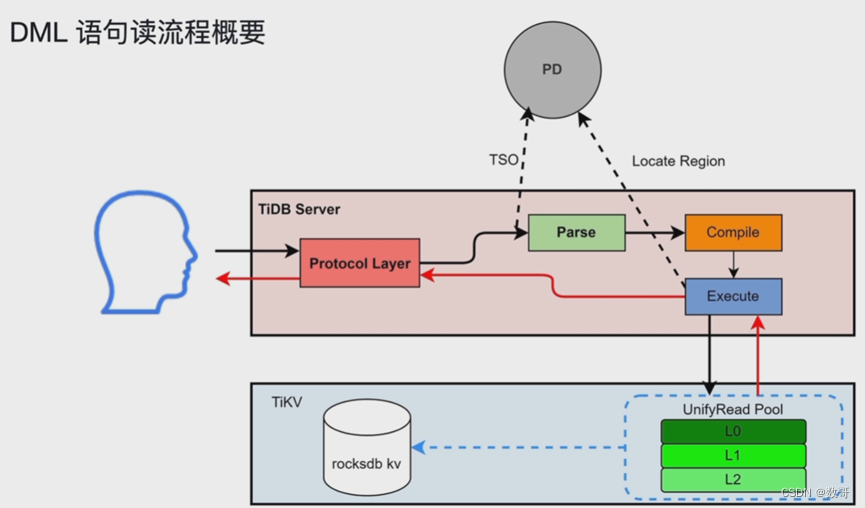
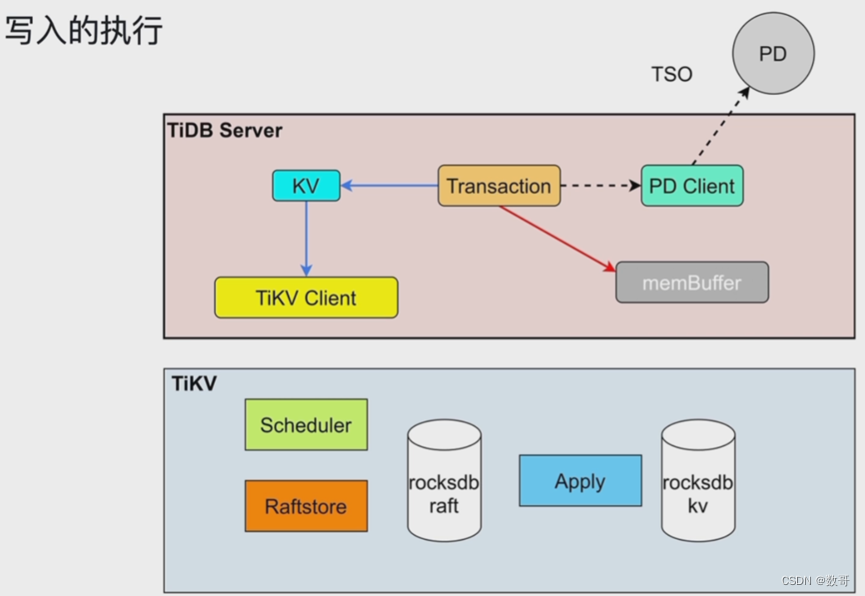
首先还是有读的操作,将处理的数据读入到memBuffer(有序的KV记录)
找到操作数据发起提交以后,开始进入到两阶段提交。
简单理解为:
一阶段:transaction (修改数据+加锁)
二阶段: commit (添加释放锁的记录+commit)
DDL的执行
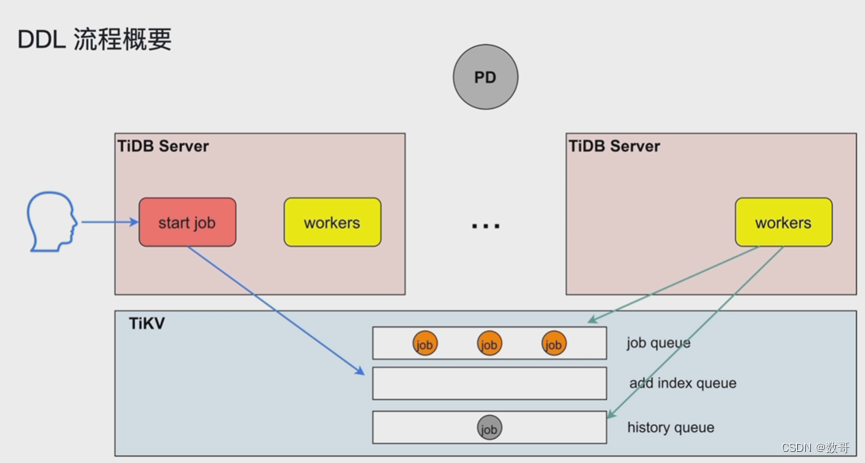
- TiDB Server发出的ddl语句,不一定是它执行,谁是owner 谁执行。
- 添加索引的语句放到 add index queue
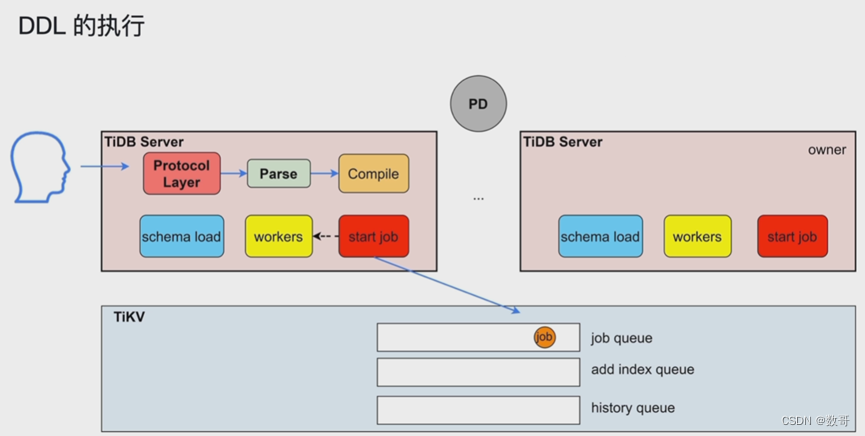
可以执行在线DDL 不会阻塞DML
同一时刻只能有一个TiDB工作(owner)
schema load: 负责将最新的对象加载进来。
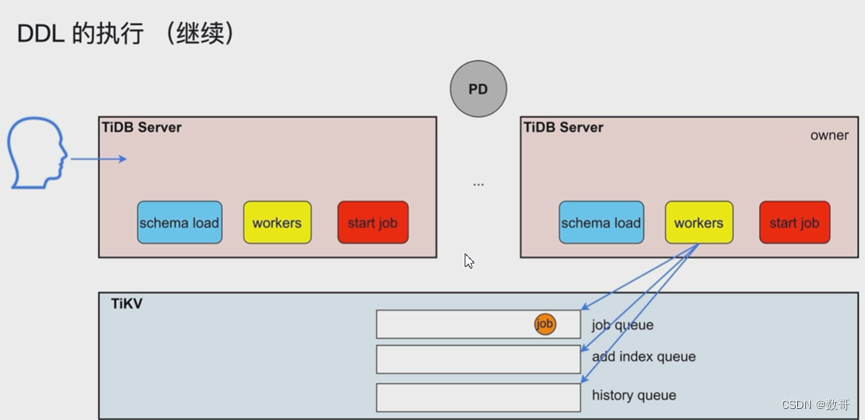
这个owner是轮询在TiDB Server上的
SQL运算
SQL解析和编译
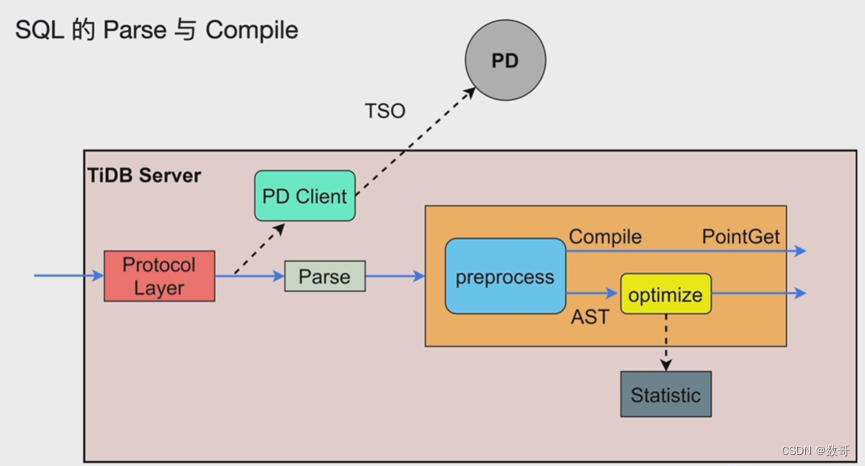
SQL解析和编译; AST语法树
optimize 包括:逻辑优化(例如子表查询转为连接查询)和物理优化(例如根据行数,判断是否使用索引等) 找到最优算子 生成 执行计划。
SQL 层架构
- TiDB 的 SQL 层,即 TiDB Server,负责将 SQL 翻译成 Key-Value 操作,将其转发给共⽤的分布式 Key-Value 存储层 TiKV,然后组装 TiKV 返回的结果,最终将查询结果返回给客户端。
- 这⼀层的节点都是⽆状态的,节点本身并不存储数据,节点之间完全对等。
SQL 运算
最简单的⽅案就是通过上⼀节所述的表数据与 Key-Value 的映射关系⽅案,将 SQL查询映射为对 KV 的查询,再通过 KV 接⼝获取对应的数据,最后执⾏各种计算。
⽐如 select count(*) from user where name = "TiDB" 这样⼀个 SQL 语句,它需要读取表中所有的数据,然后检查 name 字段是否是 TiDB ,如果是的话,则返回这⼀⾏。
具体流程如下:
- 构造出 Key Range:⼀个表中所有的 RowID 都在 [0, MaxInt64) 这个范围内,使⽤ 0 和 MaxInt64 根据⾏数据的 Key 编码规则,就能构造出⼀个[StartKey, EndKey) 的左闭右开区间。
- 扫描 Key Range:根据上⾯构造出的 Key Range,读取 TiKV 中的数据。
- 过滤数据:对于读到的每⼀⾏数据,计算 name = “TiDB” 这个表达式,如果为真,则向上返回这⼀⾏,否则丢弃这⼀⾏数据。
- 计算 Count() :对符合要求的每⼀⾏,累计到 Count() 的结果上⾯。
整个流程示意图如下:
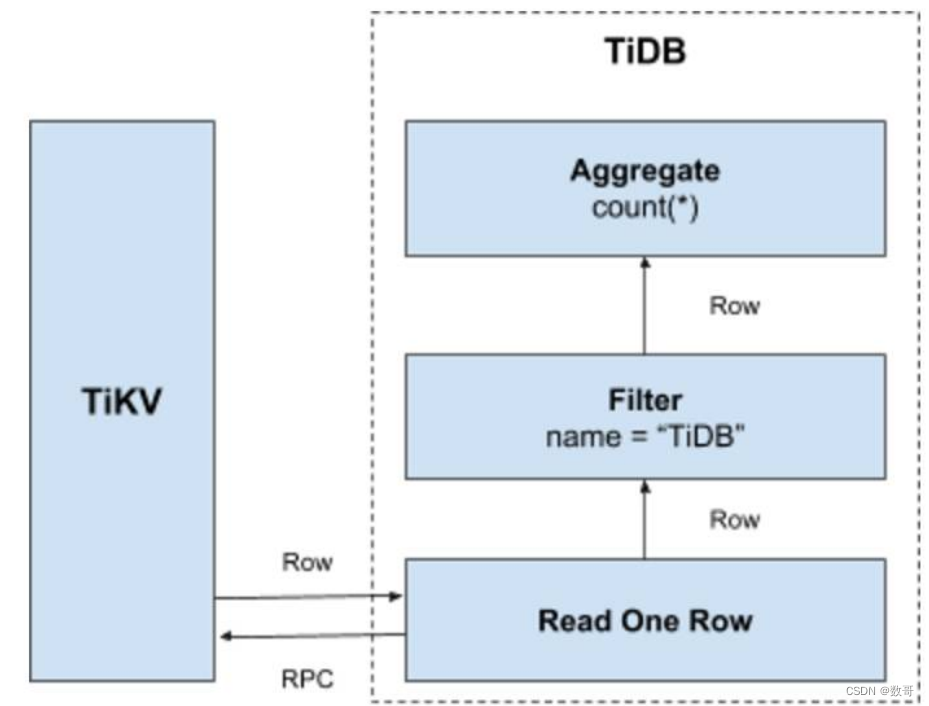
这个⽅案是直观且可⾏的,但是在分布式数据库的场景下有⼀些显⽽易⻅的问题:
- 在扫描数据的时候,每⼀⾏都要通过 KV 操作从 TiKV 中读取出来,⾄少有⼀次RPC 开销,如果需要扫描的数据很多,那么这个开销会⾮常⼤。
- 并不是所有的⾏都满⾜过滤条件 name = “TiDB” ,如果不满⾜条件,其实可以不读取出来。此查询只要求返回符合要求⾏的数量,不要求返回这些⾏的值。
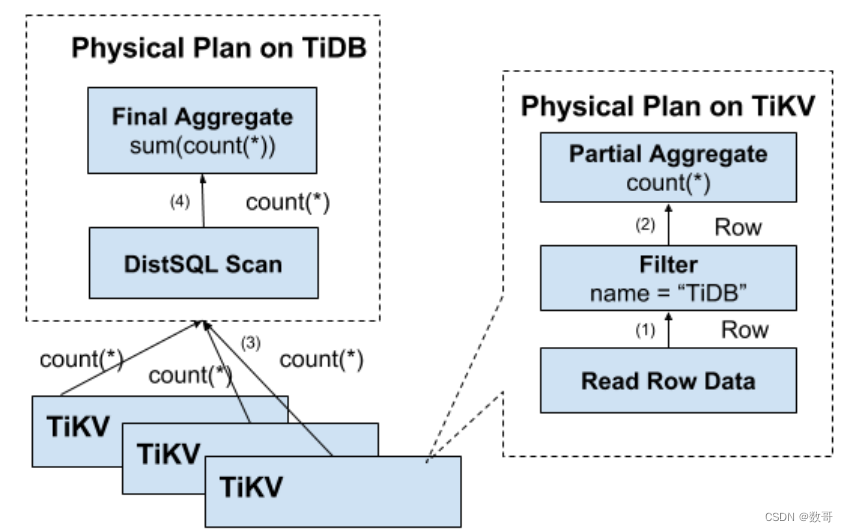
分布式 SQL 运算
为了解决上述问题,计算应该需要尽量靠近存储节点,以避免⼤量的 RPC 调⽤。⾸先,SQL 中的谓词条件 name = “TiDB” 应被下推到存储节点进⾏计算,这样只需要返回有效的⾏,避免⽆意义的⽹络传输。然后,聚合函数 Count() 也可以被下推到存储节点,进⾏预聚合,每个节点只需要返回⼀个 Count() 的结果即可,再由 SQL 层将各个节点返回的 Count(*) 的结果累加求和。
以下是数据逐层返回的示意图:
SQL 层架构
通过上⾯的例⼦,希望⼤家对 SQL 语句的处理有⼀个基本的了解。实际上 TiDB 的SQL 层要复杂得多,模块以及层次⾮常多,下图列出了重要的模块以及调⽤关系:
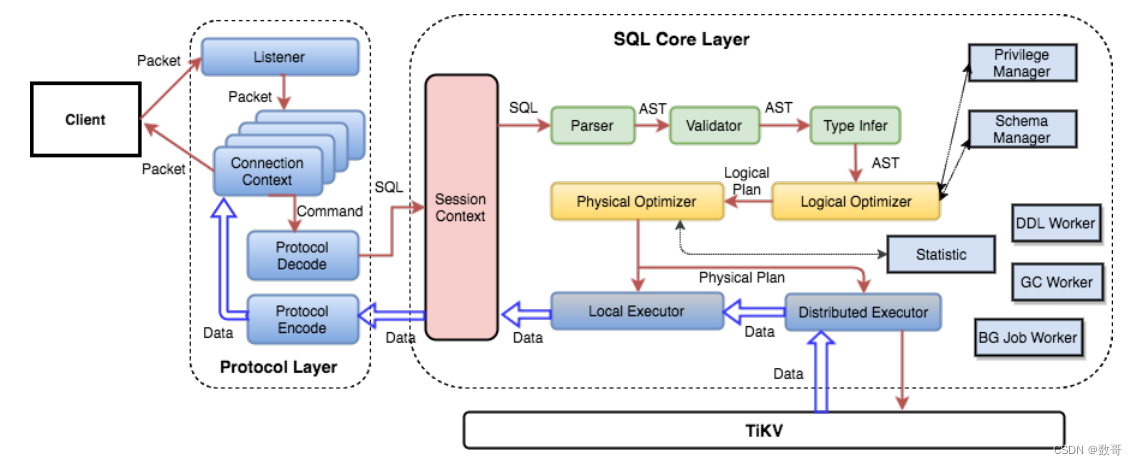
⽤户的 SQL 请求会直接或者通过 Load Balancer 发送到 TiDB Server,TiDB Server 会解析 MySQL Protocol Packet ,获取请求内容,对 SQL 进⾏语法解析和语义分析,制定和优化查询计划,执⾏查询计划并获取和处理数据。数据全部存储在 TiKV 集群中,所以在这个过程中 TiDB Server 需要和 TiKV 交互,获取数据。最后 TiDB Server 需要将查询结果返回给⽤户。